这篇paper主要解决长期依赖问题,因为卷积网络中使用的卷积3*3比较小,只能捕捉到局部信息,如果捕捉长期依赖信息需要多次重复,效率低。主要思想是计算某一位置的所有映射相应,选取最高的响应(我们的非局部操作将位置处的响应计算为所有位置处的特征的加权和)。

如上图所示,位置xi的响应由所有位置xj的特征的加权平均值计算(这里仅显示最高的加权平均值)。在我们的模型计算的这个例子中,请注意它如何将第一帧中的球与最后两帧中的球联系起来。箭头指向的点就是算法认为和箭尾的点关联度最高的一些点。可以看出,对于视频分类任务,人物的动作、球的位置等点的信息之间是有依赖关系的,而这种依赖关系被Non-local层很好的捕捉到了。更多的例子在论文中。
我们要找的就是这种映射关系。
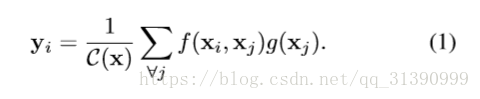
以图像为背景来说的话,i,j 是像素坐标,x,y 是输入和输出信息。j 的取值范围是任意的坐标(就是所有选取的帧中的任意位置)。C(x) 是一个归一化常数。f(.) 是用来构建 i,j 点处信息关联的二输入函数。一元函数g计算输入信号在位置j的表示。
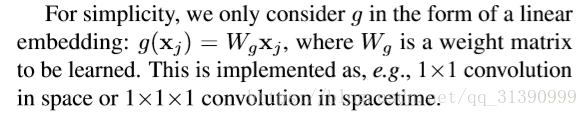
g函数比较容易,简单的线性函数,相当于1*1卷积或1*1*1卷积,比较难的是找f函数,论文中提到了多种f函数,实践证明函数选取不敏感。
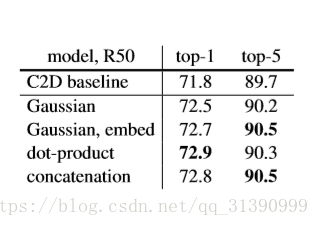




最后使用残差网络,得到以下结构。

总的结构图从别人处copy过来(自己写的太丑了)其中在过程中将维度减为512最后在输出阶段又还原到1024维,减少了计算量。
原文链接:原文链接
一些训练信息:网络先在imagenet上训练,然后使用视频微调。数据从视频中采样连续的64帧,再从这64帧中间隔取32帧作为数据集;空域上随机从[256,320]上截取一块224X224大小的区域。训练时,每个GPU上放8段视频,一次用8块GPU,一个minibatch是64个clips,迭代40万次。值得注意的是他们在微调网络时激活了BN层,而ResNet训练时BN是关闭的。因为他们使用BN减少了过拟合。在Non-local layer中,只有在最后一个1X1X1层的后面使用了BN,并且将BN的初始化参数设为0,从而保证网络的初始行为和预训练的网络一样。inference时,从一个视频里取10段分别做前向,再将结果做softmax后再取平均。
另外一点值得注意的地方是实验结果 放在浅层好,高层提升作用下降。
