本文讲解计算机如何处理图像进行分类的,这里我们以CNN(卷积神经网络)对汪汪图片进行分类为例!
1:问题空间

当计算机看到一张图像(输入一张图像)时,它看的是一大堆像素值。根据图片的分辨率和尺寸,它将看到一个 32 x 32 x 3 的数组(3 指代的是 RGB 值)。为了讲清楚这一点,假设我们有一张 JPG 格式的 480 x 480 大小的彩色图片,那么它对应的数组就有 480 x 480 x 3 个元素。其中每个数字的值从 0 到 255 不等,其描述了对应那一点的像素灰度。当我们人类对图像进行分类时,这些数字毫无用处,可它们却是计算机可获得的唯一输入。其中的思想是:当你提供给计算机这一数组后,它将输出描述该图像属于某一特定分类的概率的数字(比如:80% 是猫、15% 是狗、5% 是鸟)。
3:我们想要计算机做什么
4:生物学联系
5:结构
6.1:第一层——数学部分
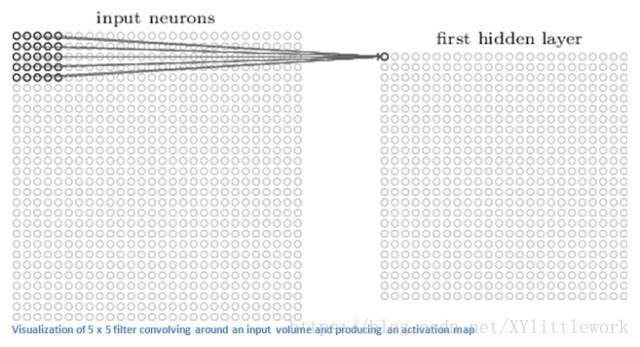
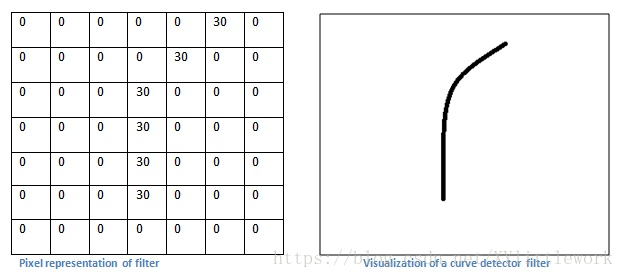
回到数学角度来看这一过程。当我们将过滤器置于输入内容的左上角时,它将计算过滤器和这一区域像素值之间的点积。拿一张需要分类的照片为例,将过滤器放在它的左上角。
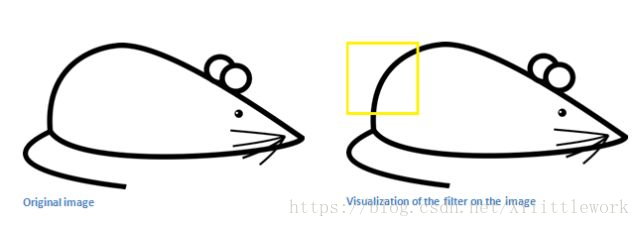
切记,我们要做的是将过滤器与图像的原始像素值相乘。

上图中,左边的图表示感受野的可视化,右图表示感受野的像素表示*过滤器的像素表示。
简单来说,如果输入图像上某个形状看起来很像过滤器表示的曲线,那么所有点积加在一起将会得出一个很大的值!让我们看看移动过滤器时会发生什么。

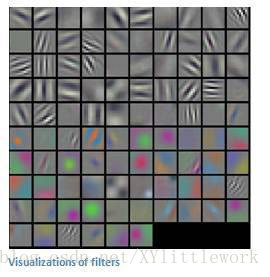
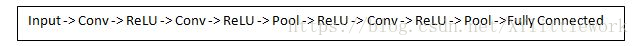
即:输入-卷积-ReLU-卷积-ReLU-池化-ReLU-卷积-ReLU-池化-全连接
我们稍后再来讨论关键的最后一层,先回顾一下学到了哪些。我们讨论了过滤器是如何在第一个卷积层检测特征的。它们检测边缘和曲线一类的低级特征。正如想象的那样,为了预测出图片内容的分类,网络需要识别更高级的特征,例如手、爪子与耳朵的区别。第一个卷积层的输出将会是一个 28 x 28 x 3 的数组(假设我们采用三个 5 x 5 x 3 的过滤器)。当我们进入另一卷积层时,第一个卷积层的输出便是第二个卷积层的输入。解释这一点有些困难。第一层的输入是原始图像,而第二卷积层的输入正是第一层输出的激活映射。也就是说,这一层的输入大体描绘了低级特征在原始图片中的位置。在此基础上再采用一组过滤器(让它通过第 2 个卷积层),输出将是表示了更高级的特征的激活映射。这类特征可以是半圆(曲线和直线的组合)或四边形(几条直线的组合)。随着进入网络越深和经过更多卷积层后,你将得到更为复杂特征的激活映射。在网络的最后,可能会有一些过滤器会在看到手写笔迹或粉红物体等时激活。有趣的是,越深入网络,过滤器的感受野越大,意味着它们能够处理更大范围的原始输入内容(或者说它们可以对更大区域的像素空间产生反应)。
8:完全连接层
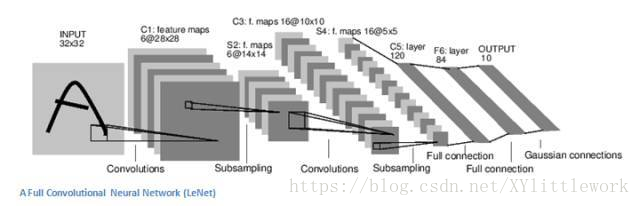
9:训练
下面是神经网络中的一个我尚未提及但却最为重要的部分。阅读过程中你可能会提出许多问题。第一卷积层中的滤波器是如何知道寻找边缘与曲线的?完全连接层怎么知道观察哪些激活图?每一层级的滤波器如何知道需要哪些值?计算机通过一个名为反向传播的训练过程来调整过滤器值(或权重)。
在探讨反向传播之前,我们首先必须回顾一下神经网络工作起来需要什么。在我们刚出生的时候,大脑一无所知。我们不晓得猫啊狗啊鸟啊都是些什么东西。与之类似的是 CNN 刚开始的时候,权重或过滤器值都是随机的。滤波器不知道要去寻找边缘和曲线。更高层的过滤器值也不知道要去寻找爪子和鸟喙。不过随着年岁的增长,父母和老师向我们介绍各式各样的图片并且一一作出标记。CNN 经历的便是一个介绍图片与分类标记的训练过程。在深入探讨之前,先设定一个训练集,在这里有上千张狗、猫、鸟的图片,每一张都依照内容被标记。下面回到反向传播的问题上来。
反向传播可分为四部分,分别是前向传导、损失函数、后向传导,以及权重更新。在前向传导中,选择一张 32×32×3 的数组训练图像并让它通过整个网络。在第一个训练样例上,由于所有的权重或者过滤器值都是随机初始化的,输出可能会是 [.1 .1 .1 .1 .1 .1 .1 .1 .1 .1],即一个不偏向任何数字的输出。一个有着这样权重的网络无法寻找低级特征,或者说是不能做出任何合理的分类。接下来是反向传播的损失函数部分。切记我们现在使用的是既有图像又有标记的训练数据。假设输入的第一张训练图片为 3,标签将会是 [0 0 0 1 0 0 0 0 0 0]。损失函数有许多种定义方法,常见的一种是 MSE (均方误差)。
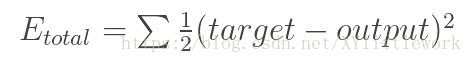


学习速率是一个由程序员决定的参数。高学习速率意味着权重更新的动作更大,因此可能该模式将花费更少的时间收敛到最优权重。然而,学习速率过高会导致跳动过大,不够准确以致于达不到最优点。

总的来说,前向传导、损失函数、后向传导、以及参数更新被称为一个学习周期。对每一训练图片,程序将重复固定数目的周期过程。一旦完成了最后训练样本上的参数更新,网络有望得到足够好的训练,以便层级中的权重得到正确调整。
10:测试
最后,为了检验 CNN 能否工作,我们准备不同的另一组图片与标记集(不能在训练和测试中使用相同的!)并让它们通过这个 CNN。我们将输出与实际情况(ground truth )相比较,看看网络是否有效!
11:CNN中的步幅和填充
好了,现在来看一下我们的卷积神经网络。还记得过滤器、感受野和卷积吗?很好。现在,要改变每一层的行为,有两个主要参数是我们可以调整的。选择了过滤器的尺寸以后,我们还需要选择步幅(stride)和填充(padding)。
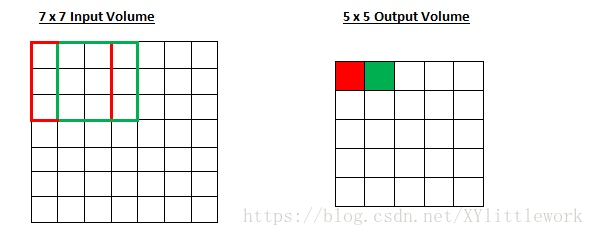
步幅控制着过滤器围绕输入内容进行卷积计算的方式。在第一部分我们举的例子中,过滤器通过每次移动一个单元的方式对输入内容进行卷积。过滤器移动的距离就是步幅。在那个例子中,步幅被默认设置为1。步幅的设置通常要确保输出内容是一个整数而非分数。让我们看一个例子。想象一个 7 x 7 的输入图像,一个 3 x 3 过滤器(简单起见不考虑第三个维度),步幅为 1。这是一种惯常的情况。
还是老一套,对吧?看你能不能试着猜出如果步幅增加到 2,输出内容会怎么样。
所以,正如你能想到的,感受野移动了两个单元,输出内容同样也会减小。注意,如果试图把我们的步幅设置成 3,那我们就会难以调节间距并确保感受野与输入图像匹配。正常情况下,程序员如果想让接受域重叠得更少并且想要更小的空间维度(spatial dimensions)时,他们会增加步幅。
现在让我们看一下填充(padding)。在此之前,想象一个场景:当你把 5 x 5 x 3 的过滤器用在 32 x 32 x 3 的输入上时,会发生什么?输出的大小会是 28 x 28 x 3。注意,这里空间维度减小了。如果我们继续用卷积层,尺寸减小的速度就会超过我们的期望。在网络的早期层中,我们想要尽可能多地保留原始输入内容的信息,这样我们就能提取出那些低层的特征。比如说我们想要应用同样的卷积层,但又想让输出量维持为 32 x 32 x 3 。为做到这点,我们可以对这个层应用大小为 2 的零填充(zero padding)。零填充在输入内容的边界周围补充零。如果我们用两个零填充,就会得到一个 36 x 36 x 3 的输入卷。
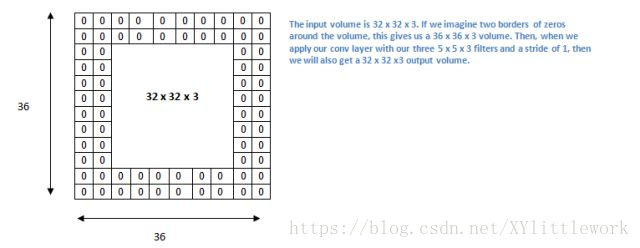
如果我们在输入内容的周围应用两次零填充,那么输入量就为 32×32×3。然后,当我们应用带有 3 个 5×5×3 的过滤器,以 1 的步幅进行处理时,我们也可以得到一个 32×32×3 的输出。
如果你的步幅为 1,而且把零填充设置为
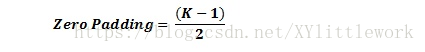
K 是过滤器尺寸,那么输入和输出内容就总能保持一致的空间维度。
计算任意给定卷积层的输出的大小的公式是
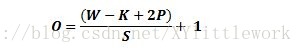
其中 O 是输出尺寸,K 是过滤器尺寸,P 是填充,S 是步幅。
12:选择超参数
13:ReLU(修正线性单元)层
14:池化层
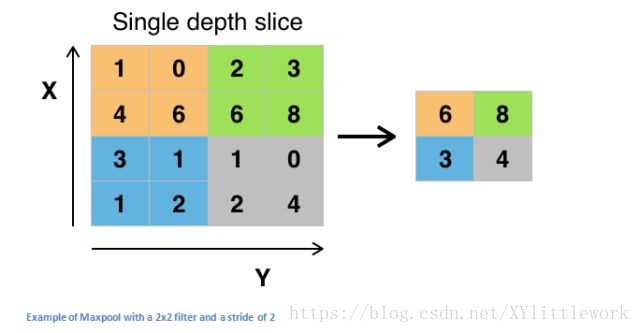
池化层还有其他选择,比如平均池化(average pooling)和 L2-norm 池化 。这一层背后的直观推理是:一旦我们知道了原始输入(这里会有一个高激活值)中一个特定的特征,它与其它特征的相对位置就比它的绝对位置更重要。可想而知,这一层大幅减小了输入卷的空间维度(长度和宽度改变了,但深度没变)。这到达了两个主要目的。第一个是权重参数的数目减少到了75%,因此降低了计算成本。第二是它可以控制过拟合(overfitting)。这个术语是指一个模型与训练样本太过匹配了,以至于用于验证和检测组时无法产生出好的结果。出现过拟合的表现是一个模型在训练集能达到 100% 或 99% 的准确度,而在测试数据上却只有50%。
15:Dropout层
16:网络层中的网络
网络层中的网络指的是一个使用了 1 x 1 尺寸的过滤器的卷积层。现在,匆匆一瞥,你或许会好奇为何这种感受野大于它们所映射空间的网络层竟然会有帮助。然而,我们必须谨记 1x1 的卷积层跨越了特定深度,所以我们可以设想一个1 x 1 x N 的卷积层,此处 N 代表该层应用的过滤器数量。该层有效地使用 N 维数组元素依次相乘的乘法,此时 N 代表的是该层的输入的深度。
17:分类、定位、检测、分割
本系列第一部分使用的案例中,我们观察了图像分类任务。这个过程是:获取输入图片,输出一套分类的类数(class number)。然而当我们执行类似目标定位的任务时,我们要做的不只是生成一个类标签,而是生成一个描述图片中物体suo所在位置的边界框。

我们也有目标检测的任务,这需要图片上所有目标的定位任务都已完成。因此,你将获得多个边界框和多个类标签。最终,我们将执行目标分割的任务:我们需要输出类标签的同时输出图片中每个目标的轮廓,如下图。

18:CNN之迁移学习
如今,深度学习领域一个常见的误解在于没有谷歌那样的巨量数据,你将没有希望创建一个有效的深度学习模型。尽管数据是创建网络中至关重要的部分,迁移学习的思路将帮助我们降低数据需求。迁移学习指的是利用预训练模型(神经网络的权重和参数都已经被其他人利用更大规模的数据集训练好了)并用自己的数据集将模型「微调」的过程。这种思路中预训练模型扮演着特征提取器的角色。你将移除网络的最后一层并用你自有的分类器置换(取决于你的问题空间)。然后冻结其他所有层的权重并正常训练该网络(冻结这些层意味着在梯度下降/最优化过程中保持权值不变)。
让我们探讨一下为什么做这项工作。比如说我们正在讨论的这个预训练模型是在 ImageNet (一个包含一千多个分类,一千四百万张图像的数据集)上训练的 。当我们思考神经网络的较低层时,我们知道它们将检测类似曲线和边缘这样的特征。现在,除非你有一个极为独特的问题空间和数据集,你的神经网络也会检测曲线和边缘这些特征。相比通过随机初始化权重训练整个网络,我们可以利用预训练模型的权重(并冻结)聚焦于更重要的层(更高层)进行训练。如果你的数据集不同于 ImageNet 这样的数据集,你必须训练更多的层级而只冻结一些低层的网络。
19:数据增强
本文讲解计算机如何处理图像进行分类的,这里我们以CNN(卷积神经网络)对汪汪图片进行分类为例!
1:问题空间
当计算机看到一张图像(输入一张图像)时,它看的是一大堆像素值。根据图片的分辨率和尺寸,它将看到一个 32 x 32 x 3 的数组(3 指代的是 RGB 值)。为了讲清楚这一点,假设我们有一张 JPG 格式的 480 x 480 大小的彩色图片,那么它对应的数组就有 480 x 480 x 3 个元素。其中每个数字的值从 0 到 255 不等,其描述了对应那一点的像素灰度。当我们人类对图像进行分类时,这些数字毫无用处,可它们却是计算机可获得的唯一输入。其中的思想是:当你提供给计算机这一数组后,它将输出描述该图像属于某一特定分类的概率的数字(比如:80% 是猫、15% 是狗、5% 是鸟)。
3:我们想要计算机做什么
4:生物学联系
5:结构
6.1:第一层——数学部分
回到数学角度来看这一过程。当我们将过滤器置于输入内容的左上角时,它将计算过滤器和这一区域像素值之间的点积。拿一张需要分类的照片为例,将过滤器放在它的左上角。
切记,我们要做的是将过滤器与图像的原始像素值相乘。
上图中,左边的图表示感受野的可视化,右图表示感受野的像素表示*过滤器的像素表示。
简单来说,如果输入图像上某个形状看起来很像过滤器表示的曲线,那么所有点积加在一起将会得出一个很大的值!让我们看看移动过滤器时会发生什么。
即:输入-卷积-ReLU-卷积-ReLU-池化-ReLU-卷积-ReLU-池化-全连接
我们稍后再来讨论关键的最后一层,先回顾一下学到了哪些。我们讨论了过滤器是如何在第一个卷积层检测特征的。它们检测边缘和曲线一类的低级特征。正如想象的那样,为了预测出图片内容的分类,网络需要识别更高级的特征,例如手、爪子与耳朵的区别。第一个卷积层的输出将会是一个 28 x 28 x 3 的数组(假设我们采用三个 5 x 5 x 3 的过滤器)。当我们进入另一卷积层时,第一个卷积层的输出便是第二个卷积层的输入。解释这一点有些困难。第一层的输入是原始图像,而第二卷积层的输入正是第一层输出的激活映射。也就是说,这一层的输入大体描绘了低级特征在原始图片中的位置。在此基础上再采用一组过滤器(让它通过第 2 个卷积层),输出将是表示了更高级的特征的激活映射。这类特征可以是半圆(曲线和直线的组合)或四边形(几条直线的组合)。随着进入网络越深和经过更多卷积层后,你将得到更为复杂特征的激活映射。在网络的最后,可能会有一些过滤器会在看到手写笔迹或粉红物体等时激活。有趣的是,越深入网络,过滤器的感受野越大,意味着它们能够处理更大范围的原始输入内容(或者说它们可以对更大区域的像素空间产生反应)。
8:完全连接层
9:训练
下面是神经网络中的一个我尚未提及但却最为重要的部分。阅读过程中你可能会提出许多问题。第一卷积层中的滤波器是如何知道寻找边缘与曲线的?完全连接层怎么知道观察哪些激活图?每一层级的滤波器如何知道需要哪些值?计算机通过一个名为反向传播的训练过程来调整过滤器值(或权重)。
在探讨反向传播之前,我们首先必须回顾一下神经网络工作起来需要什么。在我们刚出生的时候,大脑一无所知。我们不晓得猫啊狗啊鸟啊都是些什么东西。与之类似的是 CNN 刚开始的时候,权重或过滤器值都是随机的。滤波器不知道要去寻找边缘和曲线。更高层的过滤器值也不知道要去寻找爪子和鸟喙。不过随着年岁的增长,父母和老师向我们介绍各式各样的图片并且一一作出标记。CNN 经历的便是一个介绍图片与分类标记的训练过程。在深入探讨之前,先设定一个训练集,在这里有上千张狗、猫、鸟的图片,每一张都依照内容被标记。下面回到反向传播的问题上来。
反向传播可分为四部分,分别是前向传导、损失函数、后向传导,以及权重更新。在前向传导中,选择一张 32×32×3 的数组训练图像并让它通过整个网络。在第一个训练样例上,由于所有的权重或者过滤器值都是随机初始化的,输出可能会是 [.1 .1 .1 .1 .1 .1 .1 .1 .1 .1],即一个不偏向任何数字的输出。一个有着这样权重的网络无法寻找低级特征,或者说是不能做出任何合理的分类。接下来是反向传播的损失函数部分。切记我们现在使用的是既有图像又有标记的训练数据。假设输入的第一张训练图片为 3,标签将会是 [0 0 0 1 0 0 0 0 0 0]。损失函数有许多种定义方法,常见的一种是 MSE (均方误差)。
学习速率是一个由程序员决定的参数。高学习速率意味着权重更新的动作更大,因此可能该模式将花费更少的时间收敛到最优权重。然而,学习速率过高会导致跳动过大,不够准确以致于达不到最优点。
总的来说,前向传导、损失函数、后向传导、以及参数更新被称为一个学习周期。对每一训练图片,程序将重复固定数目的周期过程。一旦完成了最后训练样本上的参数更新,网络有望得到足够好的训练,以便层级中的权重得到正确调整。
10:测试
最后,为了检验 CNN 能否工作,我们准备不同的另一组图片与标记集(不能在训练和测试中使用相同的!)并让它们通过这个 CNN。我们将输出与实际情况(ground truth )相比较,看看网络是否有效!
11:CNN中的步幅和填充
好了,现在来看一下我们的卷积神经网络。还记得过滤器、感受野和卷积吗?很好。现在,要改变每一层的行为,有两个主要参数是我们可以调整的。选择了过滤器的尺寸以后,我们还需要选择步幅(stride)和填充(padding)。
步幅控制着过滤器围绕输入内容进行卷积计算的方式。在第一部分我们举的例子中,过滤器通过每次移动一个单元的方式对输入内容进行卷积。过滤器移动的距离就是步幅。在那个例子中,步幅被默认设置为1。步幅的设置通常要确保输出内容是一个整数而非分数。让我们看一个例子。想象一个 7 x 7 的输入图像,一个 3 x 3 过滤器(简单起见不考虑第三个维度),步幅为 1。这是一种惯常的情况。
还是老一套,对吧?看你能不能试着猜出如果步幅增加到 2,输出内容会怎么样。
所以,正如你能想到的,感受野移动了两个单元,输出内容同样也会减小。注意,如果试图把我们的步幅设置成 3,那我们就会难以调节间距并确保感受野与输入图像匹配。正常情况下,程序员如果想让接受域重叠得更少并且想要更小的空间维度(spatial dimensions)时,他们会增加步幅。
现在让我们看一下填充(padding)。在此之前,想象一个场景:当你把 5 x 5 x 3 的过滤器用在 32 x 32 x 3 的输入上时,会发生什么?输出的大小会是 28 x 28 x 3。注意,这里空间维度减小了。如果我们继续用卷积层,尺寸减小的速度就会超过我们的期望。在网络的早期层中,我们想要尽可能多地保留原始输入内容的信息,这样我们就能提取出那些低层的特征。比如说我们想要应用同样的卷积层,但又想让输出量维持为 32 x 32 x 3 。为做到这点,我们可以对这个层应用大小为 2 的零填充(zero padding)。零填充在输入内容的边界周围补充零。如果我们用两个零填充,就会得到一个 36 x 36 x 3 的输入卷。
如果我们在输入内容的周围应用两次零填充,那么输入量就为 32×32×3。然后,当我们应用带有 3 个 5×5×3 的过滤器,以 1 的步幅进行处理时,我们也可以得到一个 32×32×3 的输出。
如果你的步幅为 1,而且把零填充设置为
K 是过滤器尺寸,那么输入和输出内容就总能保持一致的空间维度。
计算任意给定卷积层的输出的大小的公式是
其中 O 是输出尺寸,K 是过滤器尺寸,P 是填充,S 是步幅。
12:选择超参数
13:ReLU(修正线性单元)层
14:池化层
池化层还有其他选择,比如平均池化(average pooling)和 L2-norm 池化 。这一层背后的直观推理是:一旦我们知道了原始输入(这里会有一个高激活值)中一个特定的特征,它与其它特征的相对位置就比它的绝对位置更重要。可想而知,这一层大幅减小了输入卷的空间维度(长度和宽度改变了,但深度没变)。这到达了两个主要目的。第一个是权重参数的数目减少到了75%,因此降低了计算成本。第二是它可以控制过拟合(overfitting)。这个术语是指一个模型与训练样本太过匹配了,以至于用于验证和检测组时无法产生出好的结果。出现过拟合的表现是一个模型在训练集能达到 100% 或 99% 的准确度,而在测试数据上却只有50%。
15:Dropout层
16:网络层中的网络
网络层中的网络指的是一个使用了 1 x 1 尺寸的过滤器的卷积层。现在,匆匆一瞥,你或许会好奇为何这种感受野大于它们所映射空间的网络层竟然会有帮助。然而,我们必须谨记 1x1 的卷积层跨越了特定深度,所以我们可以设想一个1 x 1 x N 的卷积层,此处 N 代表该层应用的过滤器数量。该层有效地使用 N 维数组元素依次相乘的乘法,此时 N 代表的是该层的输入的深度。
17:分类、定位、检测、分割
本系列第一部分使用的案例中,我们观察了图像分类任务。这个过程是:获取输入图片,输出一套分类的类数(class number)。然而当我们执行类似目标定位的任务时,我们要做的不只是生成一个类标签,而是生成一个描述图片中物体suo所在位置的边界框。
我们也有目标检测的任务,这需要图片上所有目标的定位任务都已完成。因此,你将获得多个边界框和多个类标签。最终,我们将执行目标分割的任务:我们需要输出类标签的同时输出图片中每个目标的轮廓,如下图。
18:CNN之迁移学习
如今,深度学习领域一个常见的误解在于没有谷歌那样的巨量数据,你将没有希望创建一个有效的深度学习模型。尽管数据是创建网络中至关重要的部分,迁移学习的思路将帮助我们降低数据需求。迁移学习指的是利用预训练模型(神经网络的权重和参数都已经被其他人利用更大规模的数据集训练好了)并用自己的数据集将模型「微调」的过程。这种思路中预训练模型扮演着特征提取器的角色。你将移除网络的最后一层并用你自有的分类器置换(取决于你的问题空间)。然后冻结其他所有层的权重并正常训练该网络(冻结这些层意味着在梯度下降/最优化过程中保持权值不变)。
让我们探讨一下为什么做这项工作。比如说我们正在讨论的这个预训练模型是在 ImageNet (一个包含一千多个分类,一千四百万张图像的数据集)上训练的 。当我们思考神经网络的较低层时,我们知道它们将检测类似曲线和边缘这样的特征。现在,除非你有一个极为独特的问题空间和数据集,你的神经网络也会检测曲线和边缘这些特征。相比通过随机初始化权重训练整个网络,我们可以利用预训练模型的权重(并冻结)聚焦于更重要的层(更高层)进行训练。如果你的数据集不同于 ImageNet 这样的数据集,你必须训练更多的层级而只冻结一些低层的网络。
19:数据增强