一、numpy常用函数
1、读取矩阵文件和保存二维数组
矩阵文件:由若干行若干列的数据项组成,每行数据的项数必须相等,每列数据项的类型必须相同,而且数据项之间有明确的分隔符。比如列数据类型相同的CSV文件。
numpy.loadtxt(fname, dtype=<class ‘float’>, comments=’#’, delimiter=None, converters=None, skiprows=0,
usecols=None, unpack=False, ndmin=0, encoding=‘bytes’)
- fname:文件相对或者绝对路径
- dtype:数据类型
- comments:跳过的注释行,默认注释符为‘#’
- delimiter:分隔符
- converters:字典,键为加载的哪一列,值为转换函数。可以在函数中进行一些操作,比如将 ‘01-01-1970’ 变成 ‘1970-01-01’,
- skiprows:跳过的行数
- usecols:选择的列的集合,比如你只要(2, 4) 第三列和第五列的数据
- unpack:是否按列展开
- ndmin:不清楚有什么用
- encoding:编码格式
numpy.savetxt(fname, X, fmt=’%.18e’, delimiter=’ ‘, newline=’\n’, header=’’, footer=’’, comments=’# ',
encoding=None)
- X:要保存的数据数组
- fmt:保存数据格式
- newline:行分隔符
- header:感觉没什么用
- footer:感觉没什么用
代码示例:txt.py
2、算术平均值
avg = numpy.mean(样本数组)
解释:也就是经常说的平均数,作用是当样本数足够的条件下对真值的无偏估计
3、加权平均值
numpy.average(样本数组,weights=权重数组)
样本:S = [s1, s2,…, sn]
权重:W = [w1, w2, …, wn]
加权平均值:(s1w1 + s2w2 + … +snwn)/(w1 + w2 + … wn)
解释:权重并不是确定的一组值,根据实际情况的不同,会选择不同的权重。比如最常用的时间作为权重,而算数平均值则是权重相等的加权平均值
4、最值
numpy.max(样本数组) —数组最大值
numpy.min(数组) —最小值
numpy.argmax(数组) —最大值的索引
numpy.argmin(数组) —最小值的索引
numpy.maximum(数组1,数组2) —数组1和数组2对应元素的最大值组成的新数组
numpy.minimum(数组1,数组2) —数组1和数组2对应元素的最小值组成的新数组
numpy.ptp(数组) —最大值减去最小值
补充:还有numpy.nanmax()、numpy.nanmin()、numpy.nanargmax()、numpy.nanargmin(),功能同上,忽略数组中的numpy.nan值
5、中位值
numpy.median(数组)
通用公式:(a[(L-1)/2] + a[L/2]) / 2 , a为数组,L为数组长度
6、标准差
numpy.std(数组,ddof=非自由度(默认0))
样本:S = [s1, s2, …, sn]
均值:m = (s1+s2+…+sn)/n
离差:D = [d1, d2, …, dn],di = si - m
离差方:Q = [q1, q2, …, qn], qi = di ^ 2
(总体)方差:v = (q1 + q2 + … + qn)/n
(总体)标准差:std = sqrt(v)
(样本)方差:v’ = (q1 + q2 + … + qn)/(n-1)
(样本)标准差:std’ = sqrt(v’)
ddof不给值时,返回的是总体标准差,ddof=1,返回的是样本标准差。不过当样本足够大的时候,二者的区别其实可以忽略了。
7、插曲
新数组 = numpy.apply_along_axis(处理函数,轴向,多维数组)
功能:将多维数组某一个轴的数据作为参数给处理函数,并将处理函数的返回值添加到新数组,处理函数一般是聚合函数,用于计算轴向的数据和、平均值、最大值等
示例代码:axis.py
8、一维卷积
c = numpy.convolve(a, b, 卷积类型)
- a:被卷积数组
- b:卷积核数组
- 卷积类型:完全卷积(full)、同维卷积(same)、有效卷积(valid)
假设:a = [1 2 3 4 5], b = [6 7 8]
先将b倒序变成[8 7 6], 然后:
完全卷积(full)结果:[6 19 40 61 82 67 40]
同维卷积(same)结果:[19 40 61 82 67],和被卷积数组长度相同的卷积
有效卷积(valid)结果:[40 61 82],不补0时的卷积
补充:这里只举出离散域的卷积计算,不去讨论数学中的连续域的情况。
示例代码:convolve.py
二维卷积请参照:https://blog.csdn.net/hs_hss/article/details/75676202 (有个小错误,看评论,不过写的还不错,反正我看懂了)
9、线性模型
1)线性预测
线性假设:假设第n+1个值是前n个值的线性组合
例子:
有一组数据[a b c d e f g]
假设第4个值是前3个值的线性组合,即
Aa + Bb + Cc = d
Ab + Bc + Cd = e
Ac + Bd + Ce = f , A、B、C为常量
这样我们就可以求出ABC的值,然后预测g = Ad + Be +Cf
对比一下实际的g,看看假设成不成立(一个值其实并不能说明什么,这里只是举例)
2)线性拟合
在实际应用中,即使数据间存在线性关系,但预测出的值与实际值还是有偏差,于是就需要找到参数可以使得总偏差最小,而最小二乘法就是解决这种问题的
假设实际输出为yn, 预测输出为yn’
y1 = kx1 + b
y2 = kx2 + b
…
yn = kxn + b
则偏差是:
y1 - y1’
y2 - y2’
…
yn - yn’
为了去除符号的影响,一般取偏差的平方
得到总偏差:E = (y1 - y1’)^2 + (y2 - y2’) ^2 + …+(yn - yn’) ^2
将yn = kxn + b代入E得到关于k、b的函数,接下来就是数学中找到合适的k、b使得E取得极小值。这就是最小二乘法的思想。
numpy中计算最小二乘法的函数:
numpy.linalg.lstsq(a,b)[0] 返回的就是k和b,其中:
a
[[x1 1]
[x2 1]
…
[xn 1]]
b [y1’ y2’ … yn’]
10、裁剪 压缩 累乘
ndarray.clip(min=,max=)
返回新数组,将大于max或小于min的值设置为max或min
ndarray.compress(条件)
返回新数组,仅包含满足条件的元素
ndarray.prod()
返回数组元素累乘的结果
ndarray.cumprod()
返回数组中各元素累乘的过程
11、相关性
a = [a1, a2, …, an]
b = [b1, b2, …, bn]
均值:
ma = (a1 + a2 +…+ an)/n, 即 a.mean()
mb = (b1 + b2 +…+ bn)/n, 即 b.mean()
离差:
da = a - ma
db = b - mb
方差:
va = (da * da).sum()
vb = (db * db).sum()
标准差:
sa = sqrt(va)
sb = sqrt(vb)
协方差:
cab = (da * db).sum()
方差矩阵:
[[va cab]
[cba vb]]
标准差矩阵:
[[sa x sa sa x sb]
.[sb x sa sb x sb]]
相关性矩阵:
[[ va/(sa x sa) ca/(sa x sb)]
.[ cb/(sb x sa) vb/(sb x sb)]]
相关性矩阵的主对角线值都为1, 表示样本与其自身是最强的正相关,辅对角线的元素为相关系数,值介于[-1, 1],正负表示相关性的方向,大小表示相关性的强弱
numpy的函数
numpy.cov(a, b) 返回方差矩阵
numpy.corrcoef(a, b) 返回相关性矩阵
12、多项式拟合
f(x) = p0x^n + p1x ^n-1 + …pn
和线性拟合一样
实际输出:
y1 = f(x1) ,y2 = f(x2), …, ym = f(xm)
预测输出:
y1’, y2’, …, yn’
总偏差E = (y1 - y1’) ^2 + (y2-y2’) ^2 + … + (yn-yn’) ^2,这是一个关于系数p(p0, p1, …, pn)的函数,同样取当E取得极小值时的p
x = [x1, x2, …, xn], y = [y1, y2, …, yn]
numpy函数
numpy.polyfit(x, y, 多项式的次数) 返回值为p
numpy.polyval(p, x) 返回值为y
numpy.polyder( p) 返回值为导函数的系数
numpy.roots( p) 多项式方程的根
最后三个方法并没有给定多项式的次数,那么它是认为几次多项式函数呢?答案:p.size - 1。所以记得没有的项以0填充
13、符号数组
numpy.sign(数组)
将数组中大于0的元素设为1,小于0的元素设为-1,等于0的还是0,返回值为这样的数组
14、标量函数矢量化
矢量函数 = numpy.vectorize(标量函数)
将只能接受和返回标量的函数改造成可以接受和返回ndarray数组
15、矩阵
numpy.matrix(二维数组,copy=True) 创建矩阵类型,默认复制一份数据,copy改为False则和mat类似
numpy.mat(二维数组或字符串) 创建矩阵对象,数据共享
numpy.bmat(拼接描述字符串) 拼接矩阵,字符串为包含若干矩阵变量名的字符串
矩阵乘法: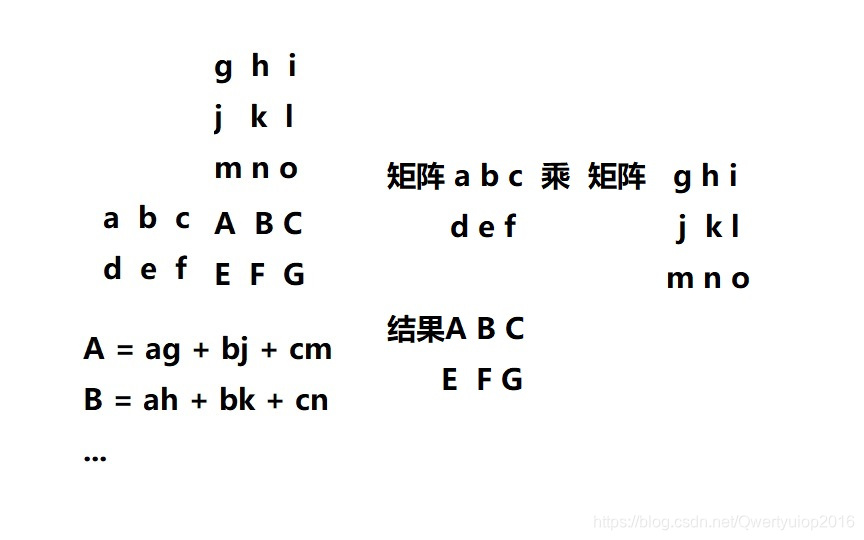
示例代码:mat.py
16、通用函数
1)numpy.frompyfunc(被封装函数,参数个数,返回值个数)
通用函数的本质就是一个ufunc类的实例化对象,在该对象的内部又封装了另一个函数,且该对象可被当做函数调用,而实际被调用的是其内部封装的函数。
说实话,看完这个解释表示不知道你在说什么。但看完别人示例代码的时候发现,额,原来就是在标量函数矢量化上加了一层闭包。其实一般也不会去自己创建通用函数,只会使用内部的已经创建好的。
代码请看:ufunc.py
2)求和通用函数:add
numpy.add(a,b) # 相对于 a + b
numpy.add.reduce(a) # 各元素求和,即a.sum()
numpy.add.accumulate(a) # 记录求和过程,即a.cumsum()
numpy.add.reduceat(a,索引序列) # 分段求和
np.add.outer(a,b) # 计算外和
不懂请看示例代码:add.py
3)除法通用函数
numpy.divide(a, b) 即 a/b
numpy.true_divide(a, b) 即 a/b
numpy.floor_divide(a, b) 即 a//b
numpy.ceil(a) 天花板取整
示例代码:div.py
4)模运算通用函数
numpy.remainder(a, b) 即a%b
numpy.mod(a, b) 即a%b
numpy.fmod 截断除余数
二、numpy子模块
1、线性代数(linalg)
1)矩阵求逆
如果一个n阶方阵A与另一个n阶方阵B的乘积是一个单位阵,则成A与B互为逆矩阵记做:A = B-1
numpy.linalg.inv(A),仅限于方阵,狭义逆矩阵
numpy.linalg.pinv(A),不仅限于方阵,广义逆矩阵,即A.I(这是大写的i)
提示:A可以是列表,数组或者矩阵类型,但只有矩阵有I属性
2)求解线性方程组
numpy.linalg.lstsq(a, b)[0]
numpy.linalg.solve(a, b)
解释:其实第一种是通过最小二乘法的方式求解,第二个才是解线性方程组的专用函数。
假设有方程组:
1x + -2y + 1z = 0
0x + 2y + -8z = 8
-4x + 5y + 9z = -9
其中a :
[[1 -2 1]
[0 2 -8]
[-4 5 9]]
b = [0 8 -9]
3)特征值和特征向量
对于n阶方阵A,如果存在数a和非零n维列向量x,满足Ax=ax,则称a是矩阵A的一个特征值,x是矩阵A属于特征值a的特征向量
numpy.linalg.eig(A) 返回值为a,x
4)奇异值分解
将矩阵M分解为U、S和V三个因子矩阵的乘积,即M=USV,其中U和V是正交矩阵,即UU ^T=E、VV ^T=E,S被称为M的奇异值矩阵,其非主对角线上的元素均为0,主对角线上的元素称为矩阵M的奇异值
numpy.linalg.svd(M,full_matrices=False)
5)行列式
np.linalg.det(A) 行列式的值

补充:行列式其实是一个值,至于这个值有什么实际意义就不清楚了,等什么时候用到再说吧。
2.快速傅里叶变换模块(fft)
傅里叶定理:任何一个周期函数总可以被分解为若干不同振幅、频率和相位的正弦函数的叠加
非周期函数可被视为周期无穷大的周期函数,傅里叶级数变成傅里叶积分。在工程上,从这些连续的频率中再选取离散的频率采样,得到离散化的频率序列,这就是离散傅里叶形式
import numpy.fft as nf
nf.fftfreq(时间域离散样本的个数,时间域离散样本的间隔)
nf.fft(时间域离散样本)
nf.ifft(频率域离散样本)
算了,没看懂,也不知道有什么用,搬两个概念就溜了。
3、随机数模块
1)二项分布
二项:非黑即白
numpy.random.binomial(n, p, size)
返回由size个随机数组成的数组,其中每个随机数来自n次尝试中成功次数,每次尝试成功的概率为p。
猜硬币游戏,初始筹码1000,每轮猜9次硬币,猜对5次及以上为赢,筹码加1,否则为输,筹码减1,进行10000轮
n=9
p=0.5
size=10000
2)超几何分布
numpy.random.hypergeometric(ngood, nbad, nsample, size)
返回由size个随机数组成的数组,其中每个随机数来自随机抽取的nsample个样本中的好样本的个数,总样本空间由ngood个好样本和nbad个坏样本组成。
摸小球游戏,将25个红色小球和1个绿色小球放在一起,每轮摸出3个小球,若全是红色小球,加1分,否则扣6分,进行100轮,
ngood = 25
nbad = 1
nsample = 3
size = 100
3)标准正态分布
numpy.random.normal(平均值(0), 标准差(1), size=样本数)
返回由size个服从标准正态分布的随机数组成的数组
4、排序相关
间接排序:以样本下标而非样本本身来表示排序的结果
关联排序:对被排序序列中值相同的元素,参考另一个序列的升序条件决定其顺序
numpy.lexsort((参考序列,待排序列)) # 间接关联排序,得到的是索引数组
numpy.sort_complex(复数数组) # 先按实部排序,相同则按虚部排序,返回的是排序数组
numpy.searchsorted(原数组, 待插入数组) #原数组是有序数组,插入后原数组依旧有序,实际并未插入,只是返回插入的索引数组,
numpy.insert(原数组,插入索引数组,待插入数组) # 返回插入后的数组,一般和上面那个配合使用
示例代码:sort.py