- 《Range Loss for Deep Face Recognition with Long-tail》
2016,Xiao Zhang et al. Range Loss
参考代码:https://github.com/Charrin/RangeLoss-Caffe
引言:
作者首先提出了现在数据库中普遍存在的问题,就是数据存在长尾分布的情况。
考虑到现实世界数据长尾分布的存在,大而均匀的分布数据通常难以收集。
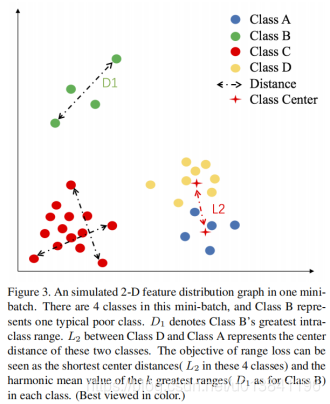
对于人脸数据库而言,长尾分布主要表现在很多的identity含有较少的图片数量,如图所示:
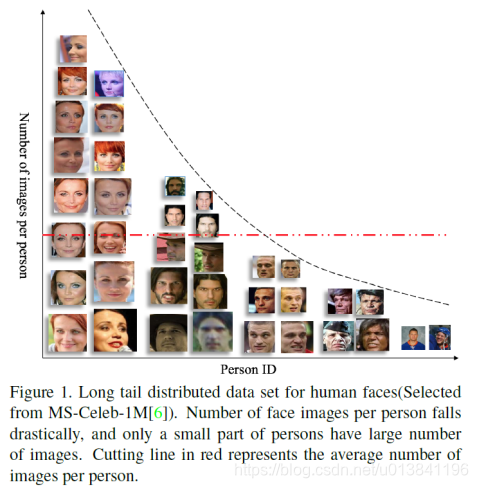
经验大量实验和分析表明,样本数越多的类对特征学习过程的影响越大,尾部数据对模型整体特征提取能力被削弱。与现有的大多数解决问题的方法相比,即:通过简单地裁剪均匀分布的尾部数据来解决这个问题。本文提出了一种新的损失函数,称为Range Loss,可以有效地利用训练过程中的整个长尾数据。Range Loss的优化目标是在一类中k个最大范围的调和平均值和一个batch中最短的类间距离。
经过大量实验验证,所提出方法不仅证明了克服长尾效应的有效性,而且表明该方法具有良好的泛化能力。
实验:长尾数据对识别影响
作者考虑到人脸数据库存在长尾分布的情况,为了能够分析出长尾分布对识别的影响,所以作者先做了几组对比实验。
1.重构数据集同长尾分布
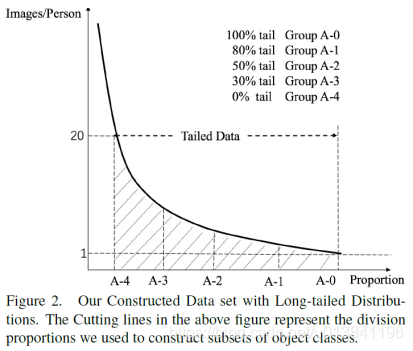
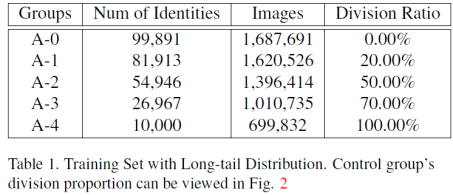
2.训练数据量统计
3.VGG网络同softmax训练长尾数据对LFW的影响
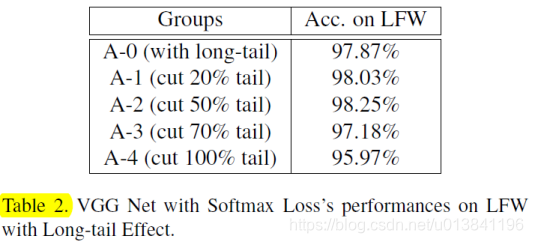
实验结果可以看出来,当截取50%的tail部分的时候,识别率达到最高。随着截取的百分比变化的时候,识别的结果也有所变化,足以看出来tail对识别的影响还是比较大的。
4.为了进一步看看long tail对识别率的影响
作者不单单选取softmax作为最后的目标函数,还加上了contrastive loss和 triplet loss。实验结果如图所示。
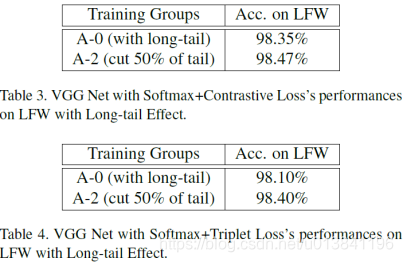
从上图的结果中可以看出截取50%的tail对实验的识别率有着一定的提升。为了能够解决或者说是减少这种长尾分布带来的影响,作者提出了range loss。range loss所要带来的影响其实和centerloss很类似,就是减小类内距,增大类间距。不同的是,range loss还有一个目的是减小tail部分数据(poor class)对识别率的影响。
损失函数:Range Loss
应该考虑如何利用不平衡数据。
设计Range Loss的目的概括为:
1.Range Loss应该能够加强训练过程中尾部数据的影响,以防止样本少的类别被样本多的类别所淹没。
2.Range Loss应该惩罚那些样本少的类别带来的稀疏样本的分布。
3.同时,扩大类间距离。
range loss的损失函数如下:
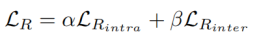
其中,α和β表示权重参数
1)
表示惩罚每个类的最大调和范围的类内损失:
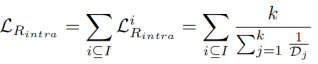
其中,I表示mini-batch;
表示第j类的最大距离。
e.g.:第j类的最大距离
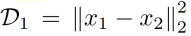
总损失是每个类中第k个最大范围的调和平均值。经验表明K=2带来了良好的性能。
2)
表示类间损失:
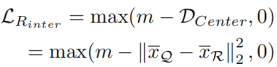
其中,
是类中心之间的最短距离,定义为该类中所有输出特征的算术平均值。
在mini-batch中,Q类中心和R类中心之间的距离是所有类中心的最短距离。
m表示一个超参数,作为最大优化间隔。
3)最终损失函数可以表述为(和softmax loss相结合):
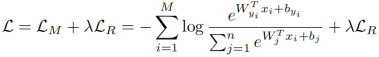
range loss的直观解释:
作者在这利用的是调和平均值来解决的类内距离的,其中k的值,作者按照经验设置为2。值得一提的是,调和平均值特别受到极值的影响。
整体算法流程如图所示:

Range loss对mini-batch设置:
根据作者的经验,最好构造这样一个小批量,其中包含多个类和每个类中相同数量的样本。例如,作者在实验中将mini-batch大小设置为32,在一批中设置4个不同的身份,每个身份含有8个图像。对于那些小网络,通常将批大小设置为256,一批中有16个身份,每个身份含有16个图像。
实验结果
作者在LFW和YTF数据库上在VGG网络的基础上加上了range loss分别进行了实验,实验结果如图所示。
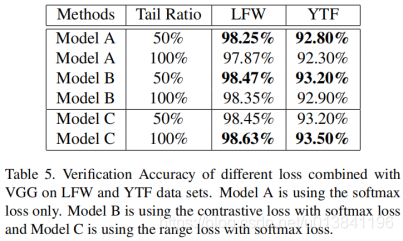
从实验的结果中可以看出,利用了range loss之后不截取tail的识别率明显高于截取了50%的结果。这说明了,range loss减少了poor class对识别率的影响。
为了能够说明range loss的普遍适应性,作者在ResNet上也进行了实验,实验的结果如图所示。
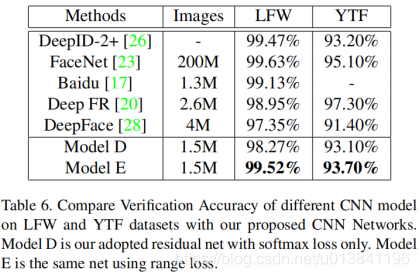
其中model D 是仅利用softmax loss,model E是利用softmax loss和range loss的联合损失。
总结:
Range loss同时约束类内紧凑类间分离,类内紧凑约束为每个类最小化两个最大类内距离,类间分离约束为每次都计算每个类别中心,并使类中心距离最小的两个类别距离大于margin m。
参考:https://blog.csdn.net/u011732139/article/details/79862202