一、 主要研究内容
信息检索是用户进行信息查询和获取的主要方式,是查找信息的方法和手段。狭义的信息检索仅指信息查询。即用户根据需要,采用一定的方法,借助检索工具,从信息集合中找出所需要信息的查找过程。广义的信息检索是信息按一定的方式进行加工、整理、组织部存储起来,再根据信息用户特定的需要将相关信息准确的查找出来的过程。
搜索引擎一般流程如下:
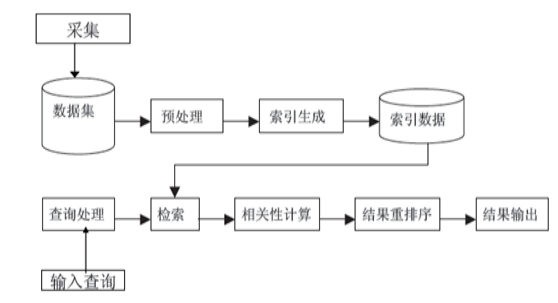
图一
从检索后面都属于检索模型的范畴。
搜索结果排序是搜索引擎最核心的部分,很大程度度上决定了搜索引擎的质量好坏及用户满意度。实际搜索结果排序的因子有很多,但最主要的两个因素是用户查询和网页内容的相关度,以及网页链接情况。这里主要介绍网页内容和用户查询相关的内容。判断网页内容是否与用户査询相关,这依赖于搜索引擎所来用的检索模型。检索模型是搜索引擎的理论基础,为量化相关性提供了一种数学模型,是对查询词和文档之间进行相似度计算的框架和方法。其本质就是相关度建模。
检索有文件检索、数据库检索、信息检索等,常用的是数据库检索和信息检索。信息检索任务是对索引结果进行相关性排序。影响结果排序的因素有相似度、网页质量、用户偏好等等。
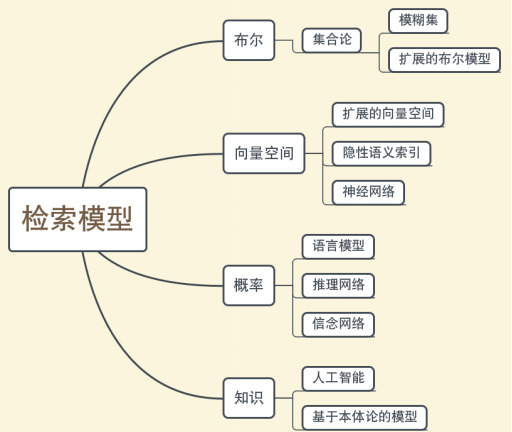
检索模型一般有布尔模型、向量空间模型、概率模型、知识模型。
信息检索模型四元组[D, Q, F,R(qi,dj)]
D: 文档集的机内表示
Q: 用户需求的机内表示
F: 文档表示、查询表示和它们之间的关系的模型框架(Frame)
R(qi,dj): 给query qi和document dj评分
图二
常用的检索算法有根据余弦相似度进行检索,Jaccard系数,海灵格-巴塔恰亚距离和BM25相关性评分。
(1)余弦(cosine)相似度,用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。适合word2vec模型向量化的数据。
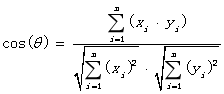
(2)Jaccard(杰卡德)相似性系数,主要用于计算符号度量或布尔值度量的样本间的相似度。若样本间的特征属性由符号和布尔值标识,无法衡量差异具体值的大小,只能获得“是否相同”这样一种结果,而Jaccard系数关心的是样本间共同具有的特征。适合词集模型向量化的数据。

(3)海灵格-巴塔恰亚(Hellinger-Bhattacharya)距离(HB距离),也称为海灵格距离或巴塔恰亚距离。巴塔恰亚距离有巴塔恰亚(A. Bhattacharya)提取,用于测量两个离散或连续概率分布之间的相似度。海灵格(E. Hellinger)在 1909 年提出了海灵格积分,用于计算海灵格距离。总的来说,海灵格-巴塔恰亚距离是一个 f 散度(f-divergence),f 散度在概率论中定义为函数 Dƒ(P||D),可用于测量 P 和 Q 概率分布之间的差异。有多种 f 散度的实例,包括 KL 散度和 HB 距离。请记住,KL 散度不是一个距离度量,因为它不符合将距离测量值作为度量所需的四个条件。对于连续和离散的概率分布,均可以计算 HB 距离。在例子中,将会使用基于 TF-IDF 的向量作为文档的概率分布。该分布为离散分布,因为对于特定的特征项有特定的 TF-IDF 值,即数值不连续。海灵格-巴塔恰亚距离的数学定义为:
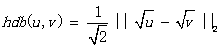
其中 hdb(u,v) 表示文档向量 u 和 v 之间的海灵格-巴塔恰亚距离,并且它等于向量的平方根差的欧几里得或 L2 范数除以 2 的平方根。
(4)BM25算法,通常用来作搜索相关性平分。对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
在本次实验中我们主要实现BM25算法来对检索文本。
二、 成员分工
1.库妍 16130130216 主要研究内容分析
2.罗晓青 16130130207 实验方案
3.长孙盼盼 16130130209 编码分析
三、 实验方案
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:

其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
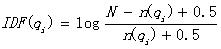
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:

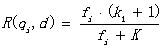
其中,q1,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
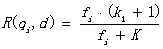
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
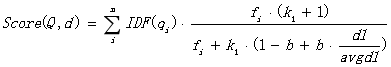
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
四、 实验结果
实验结果如下分析:

使用”,”,”。”,“?”,“!”,“;”,’\r’和’\n’对这段话划分文档,可将其划分为12个文档。
给定Query为['自然语言', '计算机科学', '领域', '人工智能', '领域'],它与每个文档的相关性为:
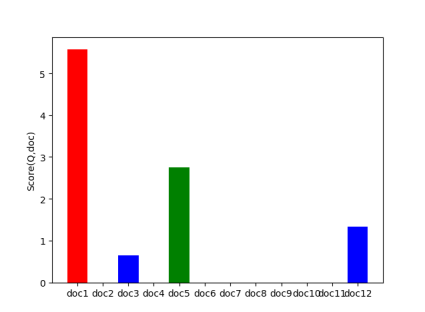
由上图可以看出,该Query和第一个文档的相关性最高。
其它的输出结果为:
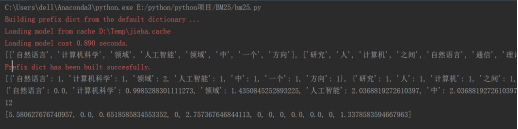
可见,通过计算idf的值,就可以得出相关度。idf为0,可以形象的理解为这个文档不出现这个词语。然后对idf的值进行加权求和就可以算出
通过多次不同文本实验测试,我们发现,bm25适用于在文档包含查询词的情况下,或者说查询词精确命中文档的前提下,如何计算相似度,如何对内容进行排序。
它的缺点也很明显,就是检索模型只能处理 Query 与 Document 有重合词的情况,无法处理词语的语义相关性。
举个例子,有一个query:这集最突出的女人是谁?
在Document集合中document1的内容为:[这集最突出的男人为胡歌];document2的内容为:[女人能最突出的只是一小部分]。显然document1和document2中都包含[突出]、[这集]、[人]等词语。但是document3的内容可能是:[最众所周知的女人是haha]。很显然与当前Query能最好匹配的应该是document3,可是document3中却没有一个词是与query中的词相同的(即所说的没有“精确命中”),此时就无法应用BM25检索模型。
对于bm25算法代码的理解,在代码中如下注释。
附件:bm25.py
1 import math 2 import jieba 3 import utils 4 import matplotlib.pyplot as plt 5 # 测试文本 6 text = ''' 7 自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。 8 它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。 9 自然语言处理是一门融语言学、计算机科学、数学于一体的科学。 10 因此,这一领域的研究将涉及自然语言,即人们日常使用的语言, 11 所以它与语言学的研究有着密切的联系,但又有重要的区别。 12 自然语言处理并不是一般地研究自然语言, 13 而在于研制能有效地实现自然语言通信的计算机系统, 14 特别是其中的软件系统。因而它是计算机科学的一部分。 15 ''' 16 17 class BM25(object): 18 19 def __init__(self, docs): 20 # 记录文档的数目 21 self.D = len(docs) 22 # 记录文档的平均长度 23 self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D 24 self.docs = docs 25 # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数 26 self.f = [] 27 # 存储每个词及出现了该词的文档数量,也是一个字典结构 28 self.df = {} 29 self.idf = {} # 存储每个词的idf值 30 self.k1 = 1.5 # 设置参数值 31 self.b = 0.75 32 self.init() 33 34 def init(self): 35 for doc in self.docs: 36 tmp = {} # 字典 37 for word in doc: 38 tmp[word] = tmp.get(word, 0) + 1 39 # 0表示当所查找的单词不存在时,返回默认值0,存储每个文档中每个词的出现次数 40 self.f.append(tmp) 41 for k in tmp.keys(): 42 self.df[k] = self.df.get(k, 0) + 1 43 # 计算每个词出现该词的文档数量 44 for k, v in self.df.items(): 45 self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5) 46 47 #计算每个语素的权重 48 def sim(self, doc, index): 49 # 计算Query 50 score = 0 51 for word in doc: 52 if word not in self.f[index]: 53 # 如果该单词没有在该文档中出现过 54 continue 55 d = len(self.docs[index]) 56 # d为第index个文档的长度 57 score += (self.idf[word]*self.f[index][word]*(self.k1+1) / (self.f[index][word]+self.k1*(1-self.b+self.b*d/self.avgdl))) 58 return score 59 60 def simall(self, doc): 61 # 计算Query分别对每个文档的相关性 62 scores = [] 63 for index in range(self.D): 64 score = self.sim(doc, index) 65 # 计算Query对第index个文档的相关性 66 scores.append(score) 67 return scores 68 69 if __name__ == '__main__': 70 sents = utils.get_sentences(text) 71 doc = [] 72 for sent in sents: 73 words = list(jieba.cut(sent)) 74 # 实现分词操作 75 words = utils.filter_stop(words) 76 # 过滤掉停用词 77 doc.append(words) 78 print(doc) 79 s = BM25(doc) 80 # 得到一个新的对象 81 print(s.f) 82 print(s.idf) 83 print(s.D) 84 num_list = s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域']) 85 print(num_list) 86 name_list = ["doc1", 'doc2', 'doc3', 'doc4', 'doc5', 'doc6', 'doc7', 'doc8', 'doc9', 'doc10', 'doc11', 'doc12'] 87 plt.bar(range(len(num_list)), num_list, color='rgb',tick_label=name_list) 88 plt.ylabel("Score(Q,doc)") 89 plt.show()
utils.py
1 import os 2 import re 3 import codecs 4 5 stop_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'stop_words.txt') 6 # 连接两个文件名地址 7 8 stop = set() 9 fr = codecs.open(stop_path, 'r', 'utf-8-sig') 10 for word in fr: 11 stop.add(word.strip()) 12 fr.close() 13 re_zh = re.compile('([\u4E00-\u9FA5]+)') 14 15 def filter_stop(words): 16 # 过滤掉停用词 17 return list(filter(lambda x: x not in stop, words)) 18 19 def get_sentences(doc): 20 # 用来得到文档 21 line_break = re.compile('[\r\n]') 22 delimiter = re.compile('[,。?!;]') 23 # 划分文档 24 sentences = [] 25 for line in line_break.split(doc): 26 line = line.strip() 27 if not line: 28 continue 29 for sent in delimiter.split(line): 30 sent = sent.strip() 31 if not sent: 32 continue 33 sentences.append(sent) 34 return sentences
其中stop_words.txt用来存放停用词。
