本文有些观点和比喻仅代表作者本人,请谨慎阅读。。。
为什么是Dropout
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象(类似于结构力学中的超静定问题,举这个栗子是因为作者的专业是工程力学。当然了不保证栗子的准确性。。。)。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
什么是Dropout
关于Dropout的来源,网上说的很详尽,这里我们不再赘述,有兴趣的朋友可以自行查阅,我们这里仅对Dropout的过程做一个简单说明。
我们知道,典型的神经网络其训练流程是将输入通过网络进行正向传导,然后将误差进行反向传播。Dropout就是针对这一过程之中,随机地删除隐藏层的部分单元,进行上述过程。
综合而言,上述过程可以分步骤为:
随机删除网络中的一些隐藏神经元,保持输入输出神经元不变;
将输入通过修改后的网络进行前向传播,然后将误差通过修改后的网络进行反向传播;
对于另外一批的训练样本,重复上述操作.
我们可以用下面的图像来形象的表述一下这个过程:
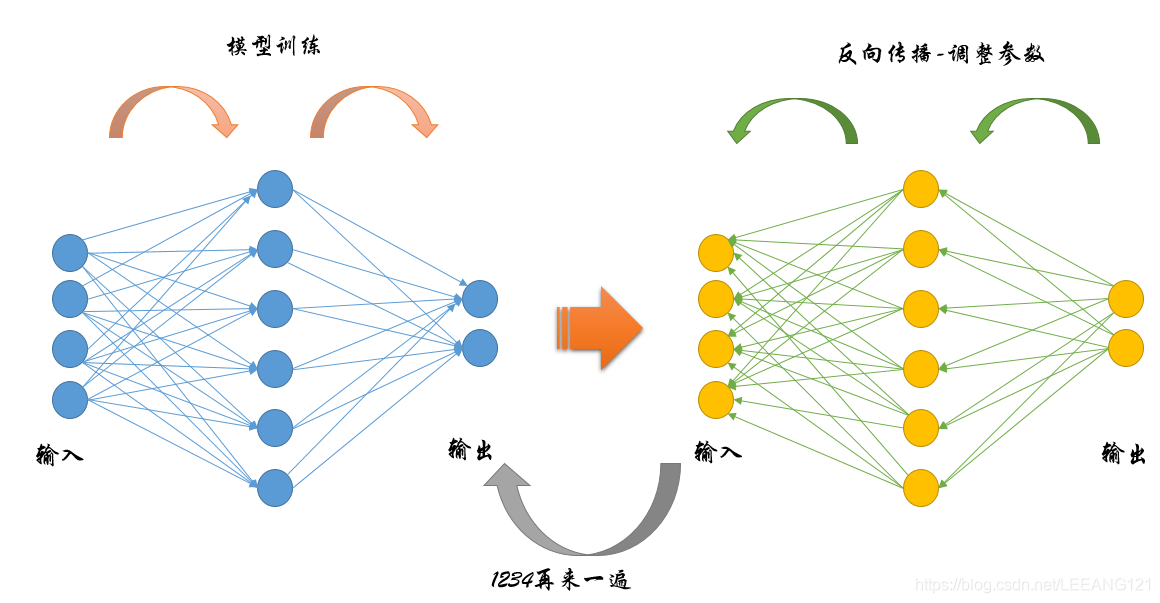
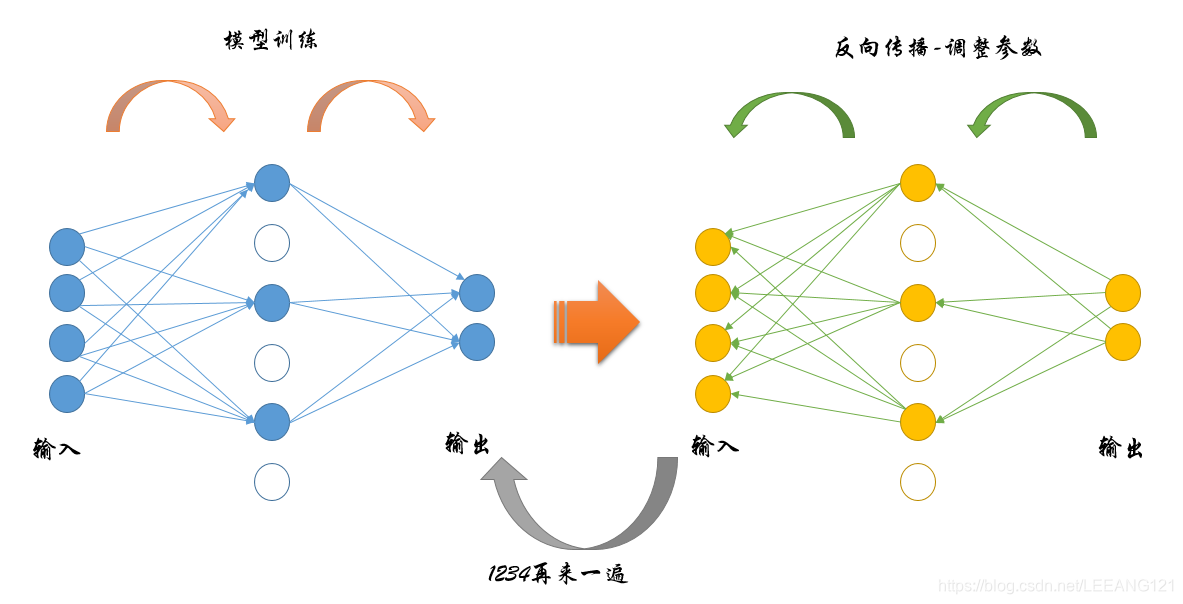
上面第一幅图是传统的神经网络工作流程:
1,数据从最左端输入
2,经过与权重相乘并求和传递给隐藏层
3,隐藏层与权重相乘并求和传递给输出
4,对输出求损失
5,从输出端开始逐步更新权重参数
6利用新的权重参数,从最左端开始,从新开始步骤1-5
上面第二幅图是引入了Dropout之后的计算过程,我们可以发现,整个流程完全一模一样,但是由于中间隐藏层被随机抽掉了一部分,因此每次计算过程中的参数数量明显下降(注意,总的参数不变,只是每一次参与计算的变少了。因为被抽掉的部分神经元并不是永久性的消逝,只是不参与这一轮的计算而已。)
为什么Dropout可以解决过拟合问题
前方高能
下面这幅图是作者根据各位大牛对Dropout的说明,按照自己理解画的图,对于图的正确性不做保证,不管你信不信,反正我是信了。请各位谨慎看图。。。(哈哈哈。。。)
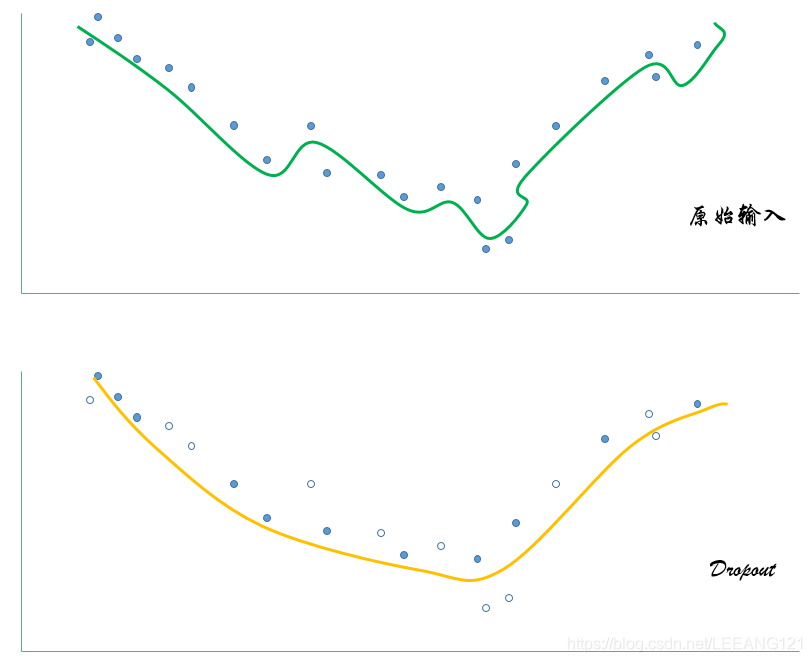
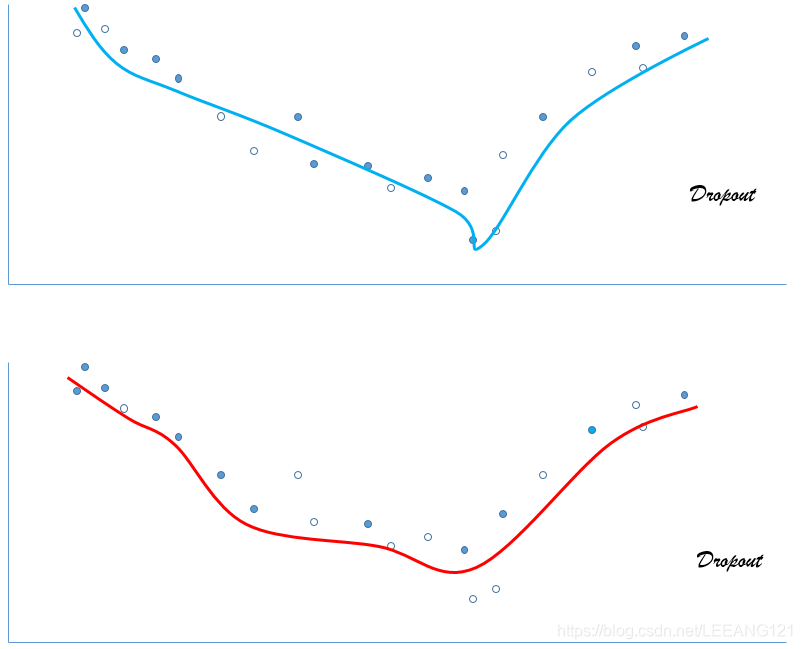

如上图所示,当数据量不足够而参数足够多时,模型很容易产生过拟合,但是我们对其中的特征值进行随机摘除后(暂时不用,我们暂时扔掉的是隐藏层的神经元,可以等效看做是随机扔掉了一部分输入的特征值),曲线的特征明显减弱,当我们对模型训练多次之后,再将输出的曲线进行一个取平均的操作,得到的结果泛化性会得到极大提高。
Dropout的数学解释
Dropout的具体工作流程上面已经详细的介绍过了,但是具体怎么让某些神经元以一定的概率停止工作(就是被删除掉)?
下面,我们具体讲解一下Dropout一些公式推导:
在训练模型阶段无可避免的,在训练网络的每个单元都要添加一道概率流程。

Dropout的缩放问题
大家看文章的时候会发现,文献里面提到当我们使用了Dropout后,还要对最后的权重进行一个rescale,也就是要对权重进行一个倍数的扩大。但是为什么要这么做,貌似找不到一个合适的解释。不知道是不是这个问题太弱智,大佬们不屑于解释。总之这个问题会困扰很多问题少年,比如作者。
这里作者还是决定按照自己的理解对此做一个强行解释,(如果大佬发现有错误,还请多多指教)
前方高能
Dropout的目的是解决模型过拟合的问题;
Dropout的方法是随机拿掉一些隐藏单元。
这里我们先来看一下本来的神经网络的输出是怎么来的:
输出就是每一个输入
乘以对应的权重
加上偏置量
再乘以一个激活函数得到。
现在,我们为了提高模型的泛化性,随机的关闭一些隐藏层的神经元。
可是最终我们进行预测的时候,是所有的隐藏层都参与计算。这样一来得到的结果势必比隐藏了部分单元的结果要大,为了保持模型的输出和输入规模不变,我们必须乘以一个系数。
具体公式推导可以
参考文献https://blog.csdn.net/fu6543210/article/details/84450890
参考文献https://blog.csdn.net/fu6543210/article/details/84450890