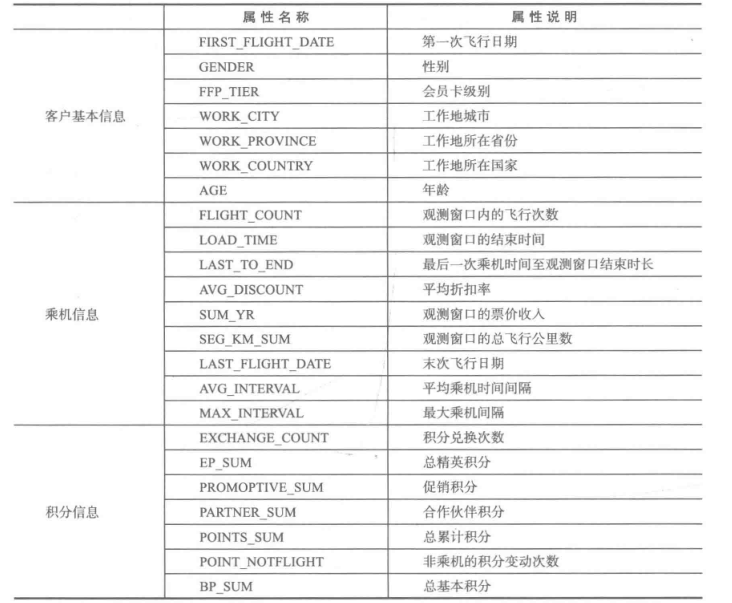
针对用户群体的特征做分群分析,也有点类似RFM模型一样,不过可选的指标比只选择RFM三个指标更多,这里用的数据是航空公司用户的数据,数据指标包括
下面上代码:
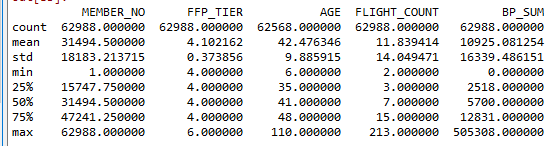
import pandas as pd data = pd.read_csv('air_data.csv') #数据的一些基本情况 data.describe()
#数据空值情况,会发现一些属性的空值比较多 data.isnull().sum().sort_values(ascending = False).head(10)
空值最多的几个列如下: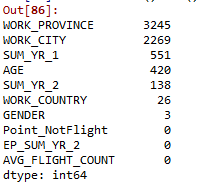
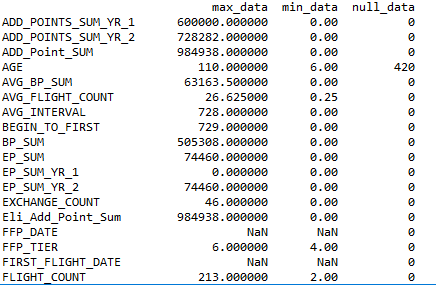
#查找每列数据的空值数量,最大值,最小值情况 max_data = data.max() min_data = data.min() null_data = data.isnull().sum() data_count = pd.DataFrame({'max_data':max_data,'min_data':min_data,'null_data':null_data})

#做数据清洗 #丢弃票价为空值的的数据 data = data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] #data.dropna(subset=['SUM_YR_2','SUM_YR_1']) #只选择票价不为0,或者折扣 index1 = data['SUM_YR_1'] != 0 index2 = data['SUM_YR_2'] != 0 index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) data = data[index1|index2|index3]
#计算LRFMC五个指标 data['FFP_DATE'] = pd.to_datetime(data['FFP_DATE']) data['LOAD_TIME'] = pd.to_datetime(data['LOAD_TIME']) data['L'] = data['LOAD_TIME'] - data['FFP_DATE'] data['R'] = data['LAST_TO_END'] data['F'] = data['FLIGHT_COUNT'] data['M'] = data['SEG_KM_SUM'] data['C'] = data['avg_discount']
finall_data = data.loc[:,['L','R','F','M','C']] finall_data['L'] = finall_data['L'].dt.days #转换成天 #标准化 finall_data = (finall_data - finall_data.mean(axis=0))/finall_data.std() #聚类分析 from sklearn.cluster import KMeans model = KMeans(n_clusters=5) model.fit(finall_data) model.cluster_centers_ model.labels_ finall_data['label'] = model.labels_ center = pd.DataFrame(center,columns=finall_data.columns[:-1])
最后几类用户几个指标的分布如下,可以有针对性的做营销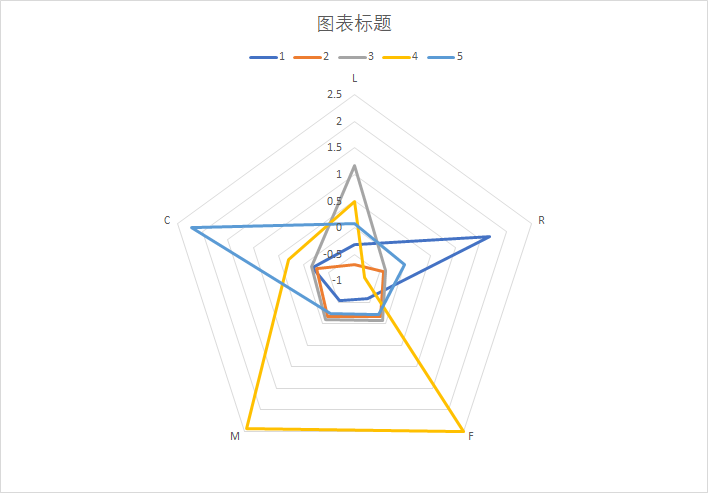
针对用户群体的特征做分群分析,也有点类似RFM模型一样,不过可选的指标比只选择RFM三个指标更多,这里用的数据是航空公司用户的数据,数据指标包括
下面上代码:
import pandas as pd data = pd.read_csv('air_data.csv') #数据的一些基本情况 data.describe()
#数据空值情况,会发现一些属性的空值比较多 data.isnull().sum().sort_values(ascending = False).head(10)
空值最多的几个列如下:
#查找每列数据的空值数量,最大值,最小值情况 max_data = data.max() min_data = data.min() null_data = data.isnull().sum() data_count = pd.DataFrame({'max_data':max_data,'min_data':min_data,'null_data':null_data})
#做数据清洗 #丢弃票价为空值的的数据 data = data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] #data.dropna(subset=['SUM_YR_2','SUM_YR_1']) #只选择票价不为0,或者折扣 index1 = data['SUM_YR_1'] != 0 index2 = data['SUM_YR_2'] != 0 index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) data = data[index1|index2|index3]
#计算LRFMC五个指标 data['FFP_DATE'] = pd.to_datetime(data['FFP_DATE']) data['LOAD_TIME'] = pd.to_datetime(data['LOAD_TIME']) data['L'] = data['LOAD_TIME'] - data['FFP_DATE'] data['R'] = data['LAST_TO_END'] data['F'] = data['FLIGHT_COUNT'] data['M'] = data['SEG_KM_SUM'] data['C'] = data['avg_discount']
finall_data = data.loc[:,['L','R','F','M','C']] finall_data['L'] = finall_data['L'].dt.days #转换成天 #标准化 finall_data = (finall_data - finall_data.mean(axis=0))/finall_data.std() #聚类分析 from sklearn.cluster import KMeans model = KMeans(n_clusters=5) model.fit(finall_data) model.cluster_centers_ model.labels_ finall_data['label'] = model.labels_ center = pd.DataFrame(center,columns=finall_data.columns[:-1])
最后几类用户几个指标的分布如下,可以有针对性的做营销