目标检测算法R-CNN详解
R-CNN框架
R-CNN框架出自UC Berkeley发表在CVPR 2014年的论文Rich feature hierarchies for accurate object detection and semantic segmentation。
论文中两个关键点:一是我们把高容量的卷积神经网络特征应用在为了定位和分割物体的自下而上的region proposals。二是当标签训练数据稀缺的时候,作为辅助任务的监督预训练,以及紧跟的特定区域的微调(domain-specific fine-tuning),能够产生巨大的性能提升。因为我们把region proposals与CNNs结合,所以我们称之为R-CNN方法,也即Regions with CNN features,区域的CNN特征。具体框架的实现用到了caffe工具 。
下图给出了R-CNN的框架:
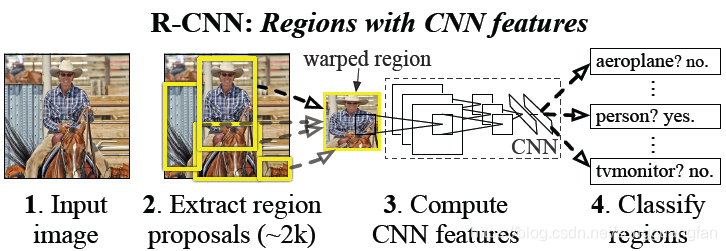
图中的步骤如下:
(1) 输入一张图片。
(2) 用selective search方法提取2000个左右的自底向上的候选区域(这里称之为region proposals)。
(3) 用Alexnet去提取每一个proposal特征。
(4) 用线性SVMs去分类每个proposal。
模型中CNN和SVM需要进行训练。对CNN进行了预训练和微调。用 ILSVRC 2012年的数据集对CNN模型进行预训练,这个可以学到大规模数据集的基本特征,由此获得的参数作为CNN模型初始化参数。论文中为了对R-CNN模型进行测试,作者将模型应用在VOC的比赛中。于是作者将VOC比赛用的数据拿来读R-CNN进行微调。由于VOC比赛是20个类别的分类任务,故将最后一个分类层变为21个输出(额外增加一个“背景”类)。每次训练从候选集中取32个正样本、96个负样本(背景)进行微调,其中IoU超50%认为是正样本,否则为负样本。。预训练得到的参数作为微调的初始化参数。对SVM进行训练,IoU超30%认为是正样本,否则为负样本。IoU是proposal(候选框)和ground truth(真实目标)的重叠率。这里选择50%和30%的原因是由作者实验测出在该数据下效果比较好。
Graph-Based Image Segmentation方法介绍
通常在对一张图片进行识别之前需要对图片中的信息进行切割。如果图像中存在多个目标对象,算法需要先对可能存在的目标进行定位,定位之后再对每个潜在对象进行分类识别。Selective Search方法主要是提取出可能存在的目标对象区域。
图像(Image)包含的信息非常的丰富,其中的物体(Object)有不同的形状(shape)、尺寸(scale)、颜色(color)、纹理(texture),要想从图像中识别出一个物体非常的难,还要找到物体在图像中的位置,这样就更难了。如下示例:

图a:桌子上有很多杂物,要识别桌子就要包含桌子上的物品。这表明物体之间有层次关系。
图b:通过纹理能识别猫,但是要区分两只猫需要通过颜色,即纹理相同,颜色可能不同。
图c:通过纹理可以识别变色龙,但是颜色却无法区分,即颜色相同,纹理可能不同。
图d:车轮和车体颜色纹理均不同,但是车是一个整体,即颜色、纹理可能都不同。
最传统的目标位置检索方法是穷举法,主要是基于穷举搜索(Exhaustive Search),选择一个滑动窗口(window)扫描整张图像(image),改变窗口的大小,继续扫描整张图像。显然这种做法是比较“原始的”,改变窗口大小,扫描整张图像,这样做会产生大量的候选框,往往比较费时费力。如下图示:

2004年Felzenszwalb在论文Efficient Graph-Based Image Segmentation提出了一种新的策略。该算法是基于图的贪心聚类算法,实现简单,速度比较快,精度也还行。算法比较简单,计算步骤如下:
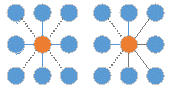
Step1:设两个像素点间的相似度。对于孤立的两个像素点,所不同的是颜色,自然就用颜色的距离来衡量两点的相似性,本文中是使用RGB的距离,即S= 。因为是基于图的贪心聚类,所以在计算相似度时只需计算相邻像素点的相似度。如图所示:计算其8领域或4领域的S值。
Step2: 设两个像素点i、j间的Sij值为一条连接边,则将这个边集按升序排列,即该集合越往后排列,像素点越不相似。
Step3: 从第一条边e1开始,依次遍历每一条边。初始时,认定每一个像素点都是一个独立的区域,并赋予每个区域一个区域ID号(可以是1~N,只要ID号不同即可)。
Step4: 对当前选择的边ei进行判断。设其所连接的顶点为(Vi,Vj)。如果满足下面两个条件,则将这两个顶点合并成一个区域。
条件1:不属于同一个区域即ID (Vi) != ID (Vj);
条件2:Sij值不大于二者内部的相似度阈值即S<=min(Ci,Cj)。则执行Step5,否则选择下一条边进入Step4。
Step5: 区域合并操作,更新阈值和区域ID号。
更新标号:将ID(Vi)、ID(Vj)统一成ID(Vj) if ID(Vj)像素点数量多于ID(Vi),否则相反。
更新阈值:Sij+k/(num(ID(Vi)+ID(Vj))),k是初始化参数值。num表示像素点的数量。然后选择下一条边执行Step4。
下图展示了Graph-Based Image Segmentation方法的效果:

Selective Search方法介绍
Selective Search方法是R-CNN框架中用到的主要方法。该方法综合了蛮力搜索(exhaustive search)和分割(segmentation)的方法,最早发表在IJCV2012上。选择性搜索意在找出可能的目标位置来进行物体的识别。与传统的单一策略相比,选择性搜索提供了多种策略,并且与蛮力搜索相比,大幅度降低搜索空间,让算法可以用到更好的识别目标。
Selective Search中用到的两个策略:
- 算法采用了图像分割(Image Segmentation)以及使用一种层次分组算法(Hierarchical Grouping Algorithm)有效地解决了不同尺度问题。
- 使用颜色(color)、纹理(texture)、大小(size)等多种策略对(1策略中分割好的)区域(region)进行合并。
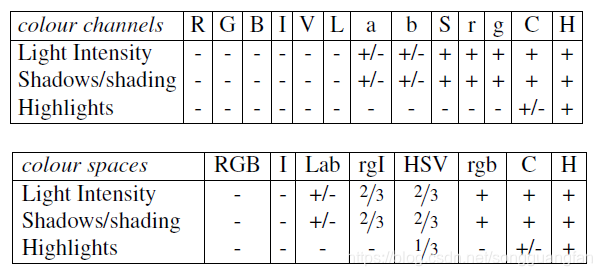
如果考虑到不同的场景和光照影响。可以将我们的算法应用在不同的色彩空间上。作者采用了8中不同的颜色方式,主要是为了考虑场景以及光照条件等。这个策略主要应用于图像分割算法中原始区域的生成。主要使用的颜色空间有:(1)RGB,(2)灰度I,(3)Lab,(4)rgI(归一化的rg通道加上灰度),(5)HSV,(6)rgb(归一化的RGB),(7)C ,(8)H(HSV的H通道)
下图给出了不同色彩空间的特性:
两个不同区域的相似度计算,为了考虑图像信息的多样性,我们引入多种相似度概念。 - 颜色相似度 Scolour(ri,rj):
对每个区域,我们都可以得到一个一维的颜色分布直方图。直方图一共有25个区间,区域i的颜色分布直方图为
,如果有3个颜色通道,则n=75。还要用L1范式进行归一化处理。那么Scolor(ri,rj)= ,当i和j合并成t时,区域t的颜色分布直方图可以通过下面的式子进行计算:
其中:t的size计算公式为:size(rt)=size(ri)+size(rj)
- 纹理相似度Stexture(ri,rj):
这里纹理采用的是SIFT-Like特征。具体做法是对每个颜色通道的8个不同方向计算方差σ=1的高斯滤波,每个方向上取10个空间的直方图。 如果有3个颜色通道,n=240=8310,同理得到的纹理直方图需要用L1范式归一化。
区域合并后特征提取方法和上文一致。 - 尺度相似度Ssize(ri,rj):
这里的大小是指区域中包含像素点的个数。使用大小的相似度计算,主要是为了尽量让小的区域先合并:
size(im)表示整个图片的像素个数。
- 填充相似度Sfill(ri,rj):
这里主要是为了衡量两个区域是否更加“吻合”,其指标是合并后的区域的Bounding Box(能够框住区域的最小矩形(没有旋转))越小,其吻合度越高。其计算方式:
BBij指包含i,j区域的最小外包盒区域。Sfill (ri,rj)鼓励有相交或者有包含关系的区域先合并。 - 最终相似度计算
计算公式:
,其中ai∈{0,1}
给出上述两个区域的相似度概念后,就按如下算法流程进行聚类操作。每次聚类都产生一个候选目标区域(可以通过Bounding box将其框出)。
Selective Search方法流程如下图示:

当区域进行结合之后,特征可以从之前的特征中直接提取而不需要重复计算。另外每次都会得到一个新的目标可能存在的矩形框。这一步实际上还是穷举法。Selective Search方法最终效果如图示:

Bounding Box Regression介绍
包围盒回归是针对“定位任务”而额外采取的一个操作。此时分类已经结束,并有了初步的定位。这里进行bb盒回归就是对bb盒进行一些微调,使得定位更加准确。效果如下图示:
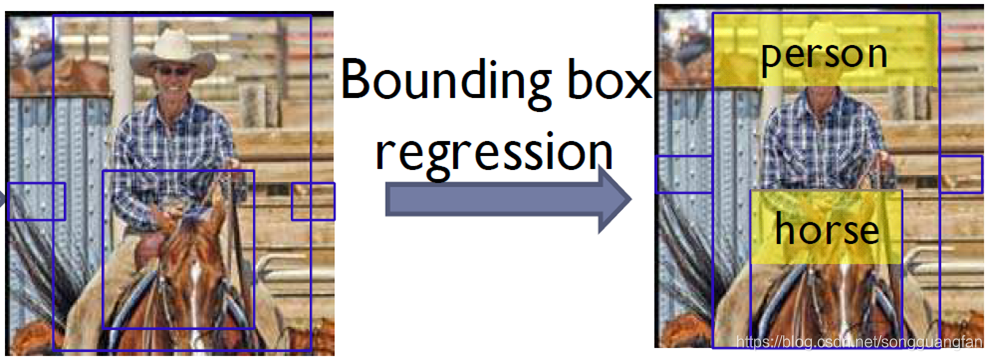
bb盒回归思想:假设每个proposal有以下四个参数(Px、Py、Pw、Ph),分别代表bb盒的中心点坐标和宽高。设真实目标框的对应参数为(Gx、Gy、Gw、Gh)。定义一组变换,使得输入的bb盒P经过该组变换之后可以转换成G。论文给出了四个方程如下图示,其中dx、dy、dw、dh是参数表达式。训练阶段我们就是要估计出dx、dy、dw、dh。
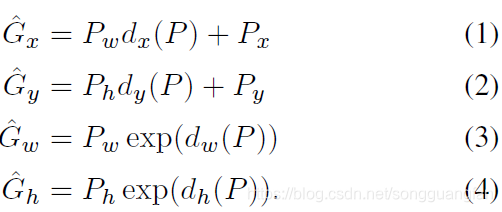
参数表达式:dx、dy、dw、dh的定义如下: 。W是我们要求的参数向量,Φ5§表示proposal的第5池化层之后的特征向量。于是求d★转换成求W★,此时方程的数量多于未知数的数量。显然我们可以使用最小二乘法。论文中使用的是优化后的正则化最小二乘法(学名:岭回归法)。
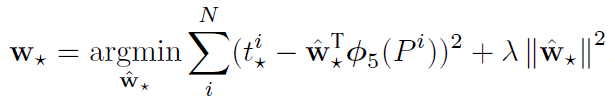
套用公式:
其中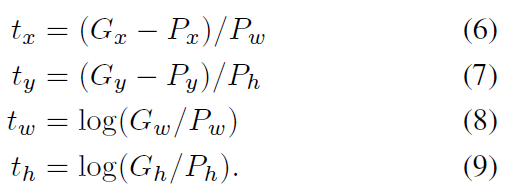
训练阶段, λ=1000。样本选择IoU(P、G)>=0.6。
下图展示了针对VOC比赛定位任务,使用BB盒回归和不使用BB盒回归的RCNN算法效果:

