一)简介
继2014年的R-CNN之后,Ross Girshick在15年推出Fast RCNN,构思精巧,流程更为紧凑,大幅提升了目标检测的速度。与R-CNN相比,Fast R-CNN训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒,在PASCAL VOC 2007上的准确率却相差无几,约在66%-67%之间。
二)Fast R-CNN介绍
2.1)SPPNet简介
在介绍Fast R-CNN之前,右有必要先介绍SPPNet原理。SPPNet的全称是Spatial Pyramid Pooling Convolutional Nerworks,即“空间金字塔池化卷积网络”。SPPNet的主要作用是,将CNN的输入从固定尺寸,改进为任意尺寸。其方法是,在普通的CNN结构中加入了ROI池化层,从而使得网络的输入图像可以是任意尺寸的,输出则不变,如下图所示。
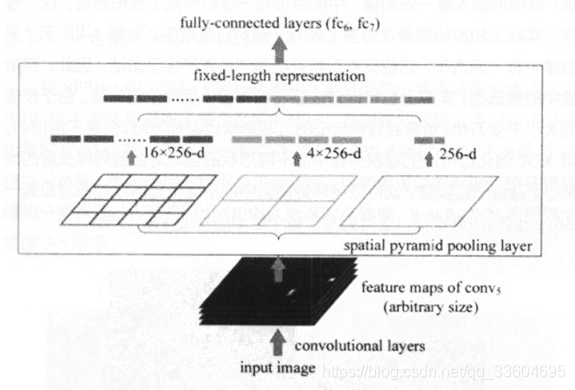
我们假设卷积层输出的宽度为w,高度为h,通道为c。通常卷积层的通道数c不会改变,可视为一个常数;而w、h会随着输入图像尺寸的变化而变化,可视为两个变量。以上图中的ROI池化层为例,它首先把卷积层分为4x4的网络,每个网格的宽是w/4,高度是h/4,通道数仍为c。当不能整出时需要取整。接着对每个网络中的每个通道取最大值,即对每个网格内的特征做最大值池化,最终形成了16c维的特征。接着再把网络分为2x2的网格,同样的方法提取特征,提出特征长度为4c。同理把网络再划分为1x1,提取特征的长度就是1c。将这三次提取的特征进行拼接,我们就得到了16c+4c+1c=21c维度的特征。很显然这个特征与卷积层的宽w、高h无关,因此我们说ROI池化层,可以将任意宽度、高度的卷积特征转换为固定长度的向量。
**如何将ROI池化运用到目标检测中呢?**网络的输入是一张图像,中间经过若干卷积层形成卷积特征,这个卷积特征实际上和原始图像再位置上是有一定对应关系的。因此原始图像中的候选框,实际上也可以对应到卷积特征中对应位置的框。基于此,我们可以把卷积特征中的不同形状的区域对应到固定长度的向量特征。综上,就能够将原始图像中不同长宽的候选区域都分别对应到固定长度的向量特征,这就完成了各个区域的特征提取工作。
R-CNN和SPPNet的不同在于,R-CNN需要对每个候选区域计算卷积,而SPPNet只需要计算一次,因此SPPNet的效率要高的多。
两者的相同点在于,它们都遵循提取候选框、提取特征、SVM分类几个步骤。
2.2)Fast R-CNN
Fast R-CNN相比于SSPNet更进一步的是,不再使用SVM作为分类器,而是使用神经网络进行分类。这样就可以同时训练特征提取网络和分类网络,从而取得更高的效率和准确度。
Fast R-CNN的结构如下图所示。
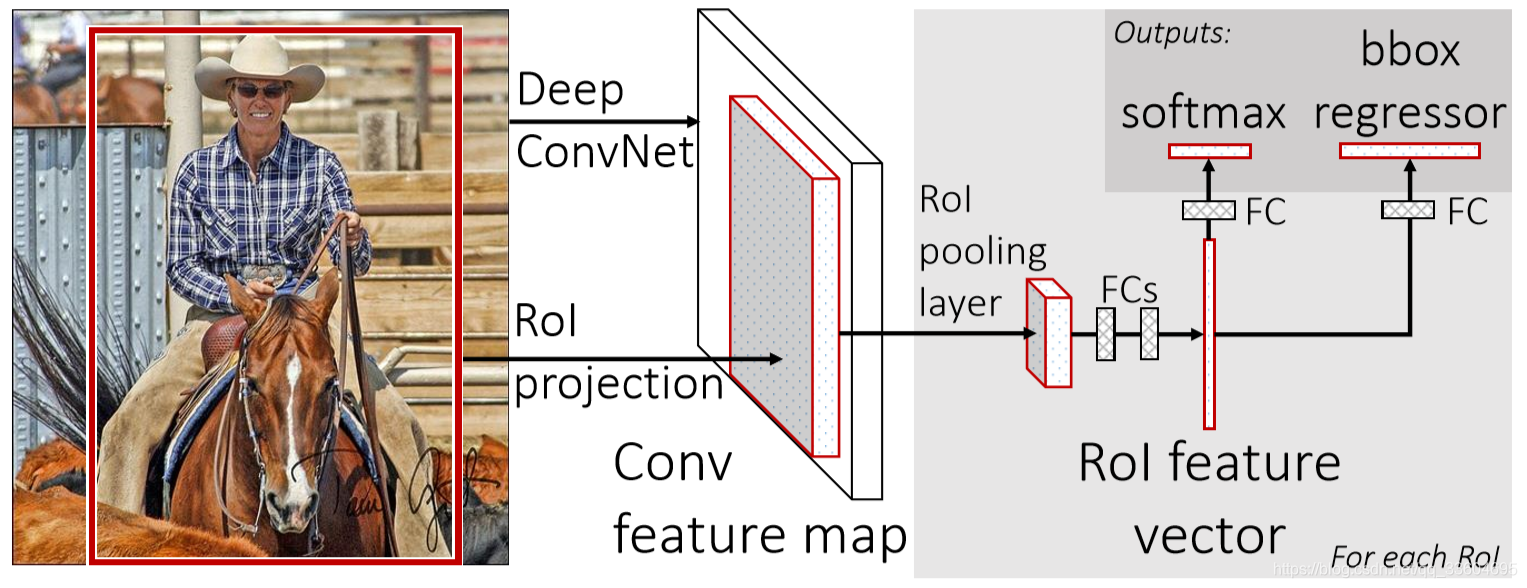
Fast R-CNN的前半部分与SPPNet做法一样,用Slective Search在原始图像中生成约2000候选区域,并把它们整体输入到全卷积的网络中,在最后一个卷积层上对每个ROI求映射关系,并用一个ROI池化层来统一到相同的大小。然后经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量:第一个是分类,使用softmax,第二个是每一类的bounding box回归。
关于分类,假设要在图像中检测K类物体,那么最终的输出应该是K+1类,因为还需要一个“背景”类,针对该区域无目标物体的情况。
框回归实际上要做的是对原始候选框进行某种程度上的“校准”。因为使用Selective Search获取的候选框会存在一定的偏差。设候选框的四个参数为(x,y,w,h),其中(x,y)代表框左上角顶点的坐标位置,(w,h)代表框的宽度和高度。而实际包容目标物体框的参数为(x’,y’,w’,h’),框回归就是要学习参数((x’-x)/w, (y’-y)/h, ln(w’/w), ln(h’/h) )。其中,x’-x)/w, (y’-y)/h表示无尺度无关的平移量,而ln(w’/w), ln(h’/h) 表示与尺度无关的缩放量。
Fast R-CNN与SPPNet最大区别就在于,不再使用SVM进行分类,而是使用一个网络同时完成了特征提取、类别判断、框回归三项工作。
参考:https://blog.csdn.net/shenxiaolu1984/article/details/51036677