神经网络中的几种权重初始化方法
在深度学习中,对神经网络的权重进行初始化(weight initialization)对模型的收敛速度和性能的提升有着重要的影响。
在神经网络在计算过程中需要对权重参数w不断的迭代更新,已达到较好的性能效果。但在训练的过程中,会遇到梯度消失和梯度爆炸等现象。因此,一个好的初始化权重能够对这两个问题有很好的帮助,并且,初始化权重能够有利于模型性能的提升,以及增快收敛速度。
1.是否可以将权重初始化为0
答案是不可能的,如果所有的参数都为0,那么神经元的输出都将会相同,那么在BP的时候同一层的神经元学到的东西相同,gradient相同,weight update也相同。
2.pre-training
pre-training是早期训练神经网络的有效初始化方法:
-
pre-training阶段,将神经网络中的每一层取出,构造一个auto-encoder做训练,使得输入层和输出层保持一致。在这一过程中,参数得以更新,形成初始值
-
fine-tuning阶段,将pre-train过的每一层放回神经网络,利用pre-train阶段得到的参数初始值和训练数据对模型进行整体调整。在这一过程中,参数进一步被更新,形成最终模型。
随着数据量的增加以及activation function的发展,pre-training的概念已经渐渐发生变化。目前,从零开始训练神经网络时我们也很少采用auto-encoder进行pre-training,而是直奔主题做模型训练。不想从零开始训练神经网络时,我们往往选择一个已经训练好的在任务A上的模型(称为pre-trained model),将其放在任务B上做模型调整(称为fine-tuning)。
3.random initialization
随机初始化是很多人目前经常使用的方法,然而这是有弊端的,一旦随机分布选择不当,就会导致网络优化陷入困境。代码如下:
def initialize_parameters_random(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3) # This seed makes sure your "random" numbers will be the as ours
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1])*0.01
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
return parameters下图给出了每一层输出值分布的直方图。

随机初始化的缺点,np.random.randn()其实是一个均值为0,方差为1的高斯分布中采样。当神经网络的层数增多时,会发现越往后面的层的激活函数(使用tanH)的输出值几乎都接近于0。
4.Xavier initialization
Xavier initialization是 Glorot 等人为了解决随机初始化的问题提出来的另一种初始化方法,他们的思想倒也简单,就是尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于0。代码如下:
def initialize_parameters_he(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3)
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(1 / layers_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
return parametersXavier initialization后每层的激活函数输出值的分布:
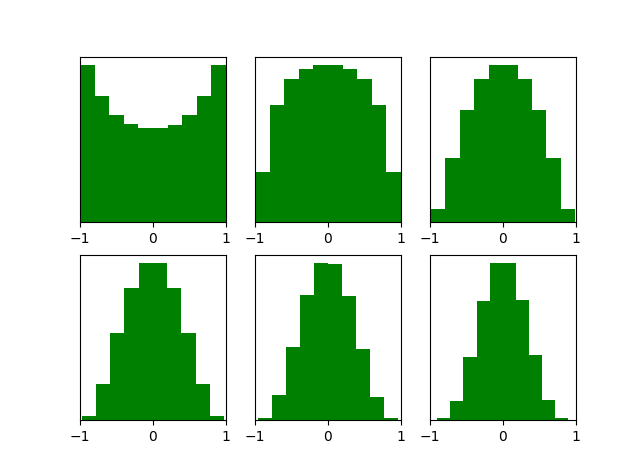
能够看出,深层的激活函数输出值还是非常漂亮的服从标准高斯分布。虽然Xavier initialization能够很好的 tanH 激活函数,但是对于目前神经网络中最常用的ReLU激活函数,还是无能能力,请看下图:
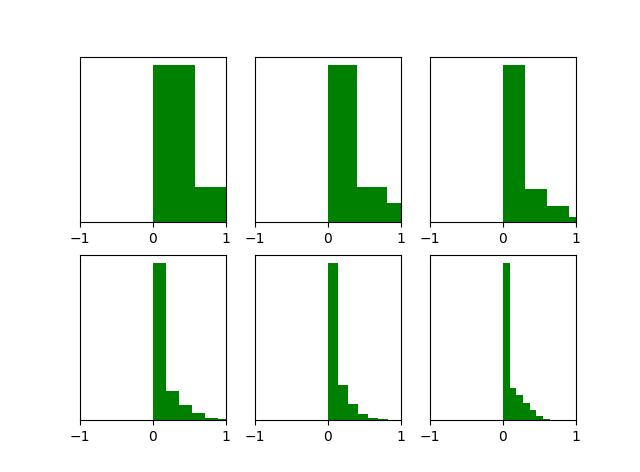
当达到5,6层后几乎又开始趋向于0,更深层的话很明显又会趋向于0。
4.He initialization
一种针对ReLU的初始化方法,一般称作 He initialization。
def initialize_parameters_he(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3)
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(2 / layers_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
return parameters当隐藏层使用ReLU时,激活函数的输出值的分布情况:
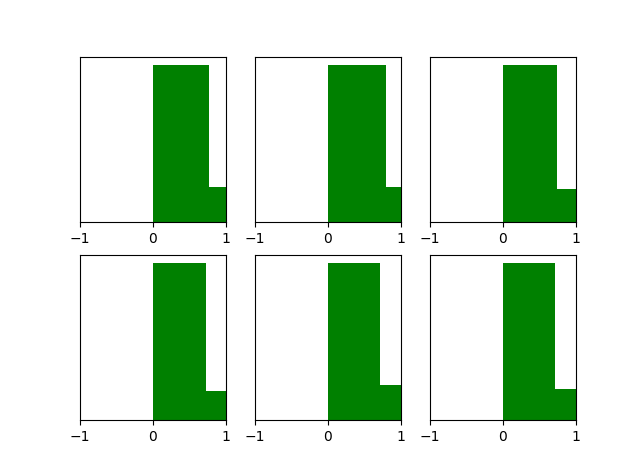
效果是比Xavier initialization好很多。
参考链接:
https://blog.csdn.net/u012328159/article/details/80025785
