1.xgboost 的特征重要性计算
Xgboost 根据结构分数的增益情况计算出来选择哪个特征作为分割点,而某个特征的重要性 就是它在所有树中出现的次数之和.
2.xgboost 特征并行化怎么做的
决策树的学习最耗时的一个步骤就是对特征值进行排序,在进行节点分裂时需要计算每个特 征的增益,最终选增益大的特征做分裂,各个特征的增益计算就可开启多线程进行.而且可以采用 并行化的近似直方图算法进行节点分裂.
3.xgboost 和 lightgbm 的区别和适用场景
(1)xgboost 采用的是 level-wise 的分裂策略,而 lightGBM 采用了 leaf-wise 的策略,区别是 xgboost 对每一层所有节点做无差别分裂,可能有些节点的增益非常小,对结果 影响不大,但是 xgboost 也进行了分裂,带来了务必要的开销. leaft-wise 的做法是在当前所 有叶子节点中选择分裂收益最大的节点进行分裂,如此递归进行,很明显 leaf-wise 这种做法容 易过拟合,因为容易陷入比较高的深度中,因此需要对最大深度做限制,从而避免过拟合.
(2)lightgbm 使用了基于 histogram 的决策树算法,这一点不同与 xgboost 中的 exact 算 法,histogram 算法在内存和计算代价上都有不小优势.1)内存上优势:很明显,直方图算法 的内存消耗为(#data* #features * 1Bytes)(因为对特征分桶后只需保存特征离散化之后的值), 而 xgboost 的 exact 算法内存消耗为:(2 * #data * #features* 4Bytes),因为 xgboost 既要 保存原始 feature 的值,也要保存这个值的顺序索引,这些值需要 32 位的浮点数来保存.2)计 算上的优势,预排序算法在选择好分裂特征计算分裂收益时需要遍历所有样本的特征值,时间为 (#data),而直方图算法只需要遍历桶就行了,时间为(#bin)
(3)直方图做差加速,一个子节点的直方图可以通过父节点的直方图减去兄弟节点的直方图 得到,从而加速计算.
(4)lightgbm 支持直接输入 categorical 的 feature,在对离散特征分裂时,每个取值都 当作一个桶,分裂时的增益算的是”是否属于某个 category“的 gain.类似于 one-hot 编码.
(5)xgboost 在每一层都动态构建直方图,因为 xgboost 的直方图算法不是针对某个特定的 feature,而是所有 feature 共享一个直方图(每个样本的权重是二阶导),所以每一层都要重新构 建直方图,而 lightgbm 中对每个特征都有一个直方图,所以构建一次直方图就够了. 其适用场景根据实际项目和两种算法的优点进行选择.
4.HMM 隐马尔可夫模型的参数估计方法是?
期望最大化(Expectation-Maximum,EM)算法
5.如何防止过拟合?
1.早停法;2.l1 和 l2 正则化;3.神经网络的 dropout;4.决策树剪枝;5.SVM 的松弛变量;6.集成学习
6.Focal Loss 介绍一下
Focal loss 主要是为了解决 one-stage 目标检测中正负样本比例严重失衡的问题.该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘. 损失函数形式:Focal loss 是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:
![]()
![]() 是经过激活函数的输出,所以在 0-1 之间.可见普通的交叉熵对于正样本而言,输出概率 越大损失越小.对于负样本而言,输出概率越小则损失越小.此时的损失函数在大量简单样本的 迭代过程中比较缓慢且可能无法优化至最优.
是经过激活函数的输出,所以在 0-1 之间.可见普通的交叉熵对于正样本而言,输出概率 越大损失越小.对于负样本而言,输出概率越小则损失越小.此时的损失函数在大量简单样本的 迭代过程中比较缓慢且可能无法优化至最优.


首先在原有的基础上加了一个因子,其中 gamma>0 使得减少易分类样本的损失.使得更关注于困难的,错分的样本.
例如 gamma 为 2,对于正类样本而言,预测结果为 0.95 肯定是简单样本,所以(1-0.95) 的 gamma 次方就会很小,这时损失函数值就变得更小.而预测概率为 0.3 的样本其损失相对很大. 对于负类样本而言同样,预测 0.1 的结果应当远比预测 0.7 的样本损失值要小得多.对于预测概 率为 0.5 时,损失只减少了 0.25 倍,所以更加关注于这种难以区分的样本.这样减少了简单样 本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效.
此外,加入平衡因子 alpha,用来平衡正负样本本身的比例不均:
![]()
只添加 alpha 虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题
lambda 调节简单样本权重降低的速率,当 lambda 为 0 时即为交叉熵损失函数,当 lambda 增加时,调整因子的影响也在增加.实验发现 lambda 为 2 是最优.
7.正负样本不平衡的解决办法?评价指标的参考价值?
好的指标:ROC 和 AUC,F 值,G-Mean;不好的指标:Precision,Recall
8.迁移学习
迁移学习就是把之前训练好的模型直接拿来用,可以充分利用之前数据信息,而且能够避免自己实验数据量较小等问题.简单来讲就是给模型做初始化,初始化的数据来自于训练好的模型.
9.数据不平衡怎么办?
使用正确的评估标准,当数据不平衡时可以采用精度,调用度,F1 得分,MCC,AUC 等评估指标.
重新采样数据集,如欠采样和过采样.欠采样通过减少冗余类的大小来平衡数据集.当数据量不足时采用过采样,尝试通过增加稀有样本的数量来平衡数据集,通过使用重复,自举,SMOTE 等方法生成新的样本.
以正确的方式使用 K-fold 交叉验证,组合不同的重采样数据集,对多数类进行聚类
10.AUC 的理解
Auc 体现出容忍样本倾斜的能力,只反应模型对正负样本排序能力的强弱,而其直观含以上 是任意取一个正样本和负样本,正样本的得分大于负样本的概率.
11.AUC 的计算公式
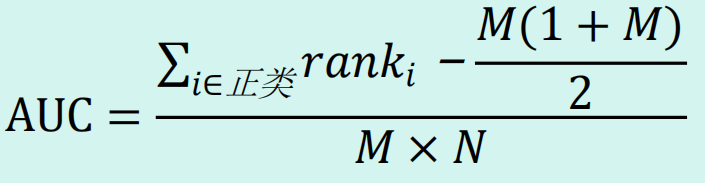
M 为正样本数,N 为负样本数.Rank 的值代表能够产生前大后小这样的组合数,但是其中包含了(正,正)的情况,所以要减去正例的个数所以可得上述公式.
12.特征选择怎么做
特征选择是一个重要的数据预处理过程,主要有两个原因:一是减少特征数量,降维,使模 型泛化能力更强,减少过拟合;二是增强对特征和特征值之间的理解.
常见的特征选择方式:
1),去除方差较小的特征
2),正则化.L1 正则化能够生成稀疏的模型.L2 正则化的表现更加稳定,由于有用的特征 往往对应系数非零.
3),随机森林,对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常 采用的是方差或者最小二乘拟合.一般不需要 feature engineering,调参等繁琐的步骤.它的 两个主要问题,1 是重要的特征有可能得分很低(关联特征问题),2 是这种方法对特征变量类 别多的特征越有利(偏向问题).
4),稳定性选择.是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回 归,SVM 或其他类似的方法.它的主要思想是在不同的数据子集和特征子集上运行特征选择算法, 不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为 重要特征的次数除以它所在的子集被测试的次数).理想情况下,重要特征的得分会接近 100%.稍微弱一点的特征得分会是非 0 的数,而最无用的特征得分将会接近于 0.
13.MXNet 和 Tensorflow 的区别
MXNet 有两个主要的进程 server 和 worker,worker 之间不能进行通信,只能通过 server 互 相影响.Tensorflow 有worker,server,client 三种进程,worker 是可以相互通信的,可以根据 op 的依赖关系主动收发数据.MXNet 常用来做数据并行,每个 GPU 设备上包含了计算图中所有的 op,而 Tensorflow 可以由用户指定op 的放置,一般情况下一个 GPU 设备负责某个和几个 op 的训练任务.
14.Tensorflow 的工作原理
Tensorflow 是用数据流图来进行数值计算的,而数据流图是描述有向图的数值计算过程.在 有向图中,节点表示为数学运算,边表示传输多维数据,节点也可以被分配到计算设备上从而并行 的执行操作.
15.Tensorflow 中 interactivesession 和 session 的区别
Tf. Interactivesession()默认自己就是用户要操作的会话,而 tf.Session()没有这个默认, 所以 eval()启动计算时需要指明使用的是哪个会话.
