
Autor | Der Stein, der wie ein Traum schwebt
Führung
Mit der breiten Anwendung der Echtzeit-Computing-Technologie in Big Data wurde die Aktualität von Daten stark verbessert, in tatsächlichen Anwendungsszenarien werden sie jedoch neben der Aktualität auch mit höheren technischen Anforderungen konfrontiert.
Dieses Papier kombiniert die Erforschung und Praxis der Echtzeit-Berechnung von Wasserstandstechnologie im integrierten Flow-Batch-Data Warehouse und konzentriert sich auf das Konzept der Wasserstandstechnologie und verwandte theoretische Praktiken, insbesondere die Eigenschaften, Grenzdefinition und Anwendung des Wasserstands in der Realität -Zeit-Rechensysteme, und konzentriert sich schließlich auf die Beschreibung. Ein verbessertes Design und die Implementierung eines genauen Wasserstands werden vorgestellt. Die technische Architektur ist derzeit in Baidus tatsächlichen Geschäftsszenarien ausgereift und stabil, und ich möchte sie gerne mit Ihnen teilen, in der Hoffnung, dass sie für alle ein Referenzwert ist.
Der Volltext umfasst 7118 Wörter und die erwartete Lesezeit beträgt 18 Minuten.
01 Betriebswirtschaftlicher Hintergrund
Um die Effizienz der Produktentwicklung, der Strategieiteration, der Datenanalyse und der operativen Entscheidungsfindung zu verbessern, haben Unternehmen immer höhere Anforderungen an die Aktualität der Daten.
Obwohl wir den Aufbau eines Echtzeit-Data Warehouse auf Basis von Echtzeit-Computing sehr früh realisiert haben, kann es das Offline-Data Warehouse noch immer nicht ersetzen.Die Kosten für die Entwicklung und Wartung einer Reihe von Echtzeit- und Offline-Data Warehouses sind hoch. und das Wichtigste ist, dass das Kaliber des Unternehmens nicht zu 100% ausgerichtet werden kann. Daher haben wir uns verpflichtet, ein integriertes Stream-Batch-Data Warehouse aufzubauen, das nicht nur die Gesamteffizienz der Datenverarbeitung beschleunigen, sondern auch sicherstellen kann, dass die Daten so zuverlässig wie Offline-Daten sind und Geschäftsszenarien zu 100 % unterstützen können um eine allgemeine Kostensenkung und Effizienzsteigerung zu erreichen.
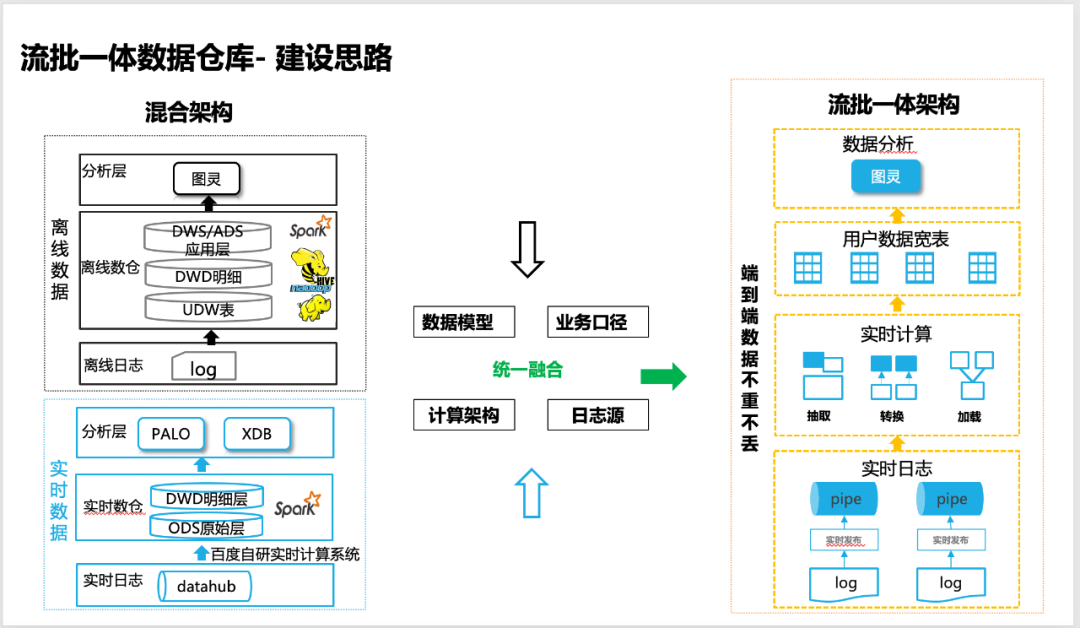
△Die Idee, ein Stream-Batch-integriertes Data Warehouse zu erstellen
02 Technische Schwierigkeiten des Stream-Batch Integrated Data Warehouse
Um das integrierte End-to-End-Streaming- und Batch-Data-Warehouse als Echtzeit-Computing-System der zugrunde liegenden technischen Architektur zu realisieren, steht es vor vielen technischen Schwierigkeiten und Herausforderungen:
1. Die End-to-End-Daten werden strengstens nicht wiederholt oder gehen verloren, um die Integrität der Daten zu gewährleisten;
2. Das Echtzeit-Datenfenster und das Offline-Datenfenster, einschließlich der Daten, sind ausgerichtet (99,9 % ~ 99,99 %) ;
3. Die Echtzeitberechnung muss eine genaue Fensterberechnung unterstützen, um die genaue Wirkung der Echtzeit-Anti-Cheating-Strategie sicherzustellen;
4. Das Echtzeit-Computersystem ist in die interne Big-Data-Ökologie von Baidu integriert, und es gibt eine tatsächliche Praxis des groß angelegten stabilen Online-Betriebs.
Die oben genannten Punkte 2 und 3 erfordern alle einen äußerst zuverlässigen Wasserstandsmechanismus, um Fortschrittsbewusstsein und eine genaue Segmentierung von Echtzeitdaten sicherzustellen.
Daher teilt dieser Artikel mit Ihnen die Erforschung und praktische Erfahrung des genauen Wasserstands im integrierten Stream-Batch-Data Warehouse.
03 Aktueller Stand Wasserstandskonzept und allgemeine Umsetzung
3.1 Notwendigkeit eines Wasserspiegels
Bevor das Konzept des Wasserzeichens eingeführt wird, müssen zwei Konzepte eingefügt werden:
-
Ereigniszeit, die Zeit, zu der das Ereignis aufgetreten ist. Wir verstehen darunter im Allgemeinen den Zeitpunkt, an dem das tatsächliche Verhalten des Benutzers aufgetreten ist, und entsprechen insbesondere dem Zeitstempel, an dem das Benutzerverhalten im Protokoll aufgetreten ist.
-
Bearbeitungszeit, Datenverarbeitungszeit. Wir verstehen darunter im Allgemeinen die Zeit, in der das System Daten verarbeitet.
Was ist die spezifische Verwendung des Wasserzeichens?
Im eigentlichen Echtzeit-Datenverarbeitungsprozess sind die Daten unbegrenzt (Unbounded), sodass Window Computing auf Basis von Window oder anderen ähnlichen Szenarien einem praktischen Problem gegenübersteht:
Woher wissen Sie, dass die Daten in einem bestimmten Fenster vollständig sind? Wann kann window compute() ausgelöst werden?
In den meisten Fällen verwenden wir die Ereigniszeit, um Fensterberechnungen (oder Datenpartitionsaufteilung und Offline-Ausrichtung) auszulösen. Die tatsächliche Situation ist jedoch, dass Echtzeitprotokolle immer unterschiedliche Verzögerungsgrade aufweisen (in den Stadien der Protokollerfassung, Protokollübertragung und Protokollverarbeitung), d auftreten (das heißt, die Daten erscheinen in der falschen Reihenfolge). In diesem Fall ist der Watermark-Mechanismus notwendig, um die Integrität der Daten zu gewährleisten.
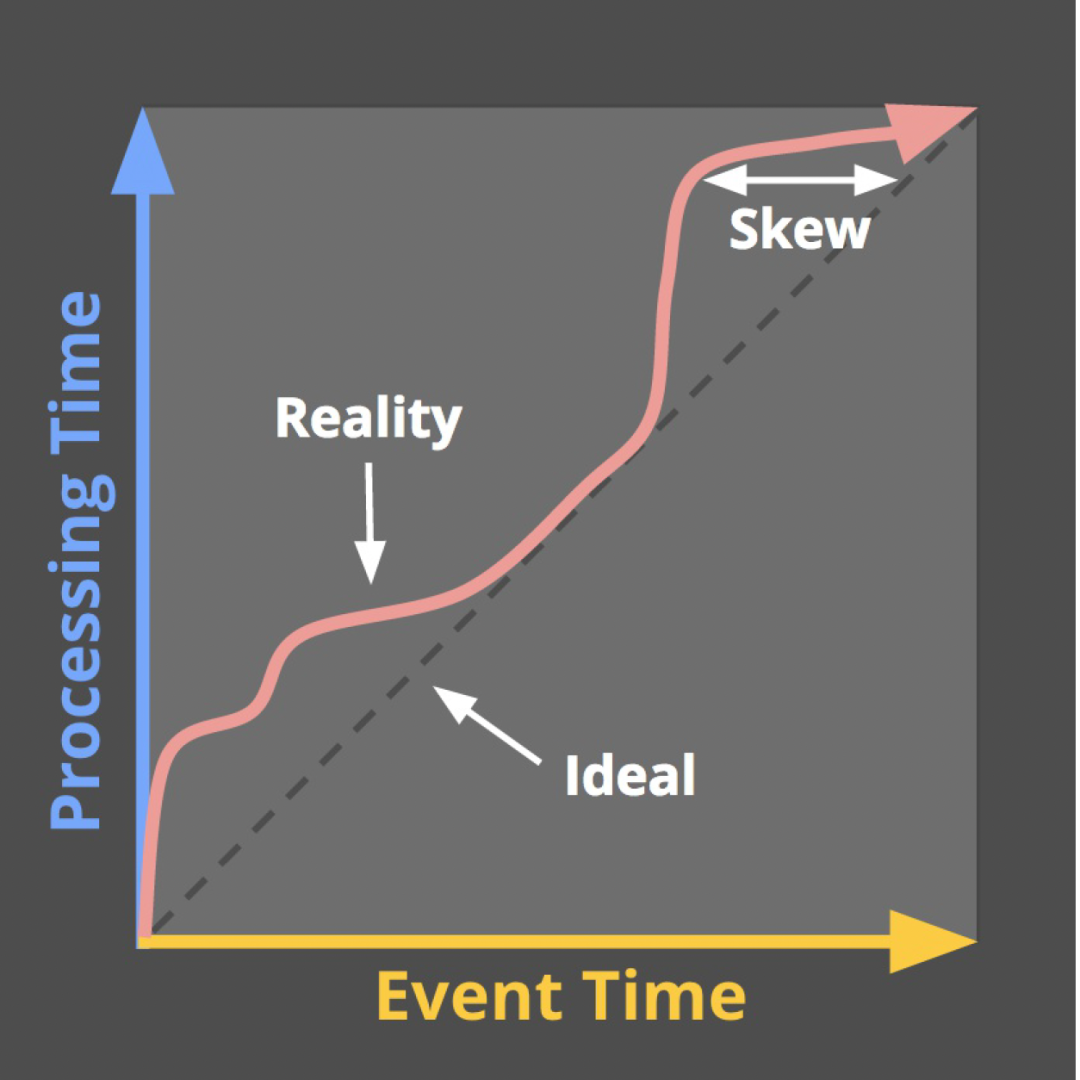 △ Neigungsphänomen des Wasserspiegels
△ Neigungsphänomen des Wasserspiegels
3.2 Definition und Eigenschaften des Wasserspiegels
Die Definition von Wasserzeichen (Watermark) ist derzeit in der Branche nicht einheitlich. Kombiniert mit der Definition im Buch ** Streaming Systems ** (Autor ist das Google Dataflow R&D Team) halte ich es persönlich für treffender:
Das Wasserzeichen ist ein monoton steigender Zeitstempel der ältesten noch nicht vollendeten Arbeit.
Aus der Definition können wir die beiden grundlegenden Eigenschaften des Wasserspiegels zusammenfassen:
-
Der Wasserstand steigt kontinuierlich (kein Umtausch)
-
Der Wasserstand ist ein Zeitstempel
Wie berechnet man jedoch im eigentlichen Produktionssystem den Wasserstand und was ist der tatsächliche Effekt? In Kombination mit verschiedenen Echtzeit-Computersystemen in der Industrie ist die Unterstützung für Wasserstände immer noch anders.
3.3 Aktueller Wasserstand und Herausforderungen
In den aktuellen Echtzeit-Computing-Systemen der Branche wie Apache Flink (eine Open-Source-Implementierung von Google Dataflow) und Apache Spark (nur beschränkt auf das Structured Streaming-Framework) unterstützen sie alle Wasserstände. Das Folgende ist das beliebteste Apache Flink in der Community Listen Sie den Implementierungsmechanismus für den Wasserstand auf:

Der Implementierungsmechanismus und die Auswirkung des oben genannten Wasserstands, im Falle einer großen Fläche mit verzögerter Protokollübertragung an der Protokollquelle, wird der Wasserstand jedoch immer noch aktualisiert (neue und alte Daten werden außer der Reihe übertragen) und Voraus, was zu unvollständigen Daten im entsprechenden Fenster und einer ungenauen Fensterberechnung führt. Daher haben wir innerhalb von Baidu einen verbesserten und relativ genauen Wasserstandsmechanismus untersucht, der auf dem Protokollerfassungs- und -übertragungssystem und dem Echtzeit-Computersystem basiert, um sicherzustellen, dass Echtzeitdaten im Fenster berechnet werden und die Daten landen (Senke auf AFS /Hive) und andere Anwendungsszenarien Als nächstes besteht das Problem der Integrität der Fensterdaten darin, die Anforderungen zur Realisierung des Stream-Batch-integrierten Data Warehouse zu erfüllen.
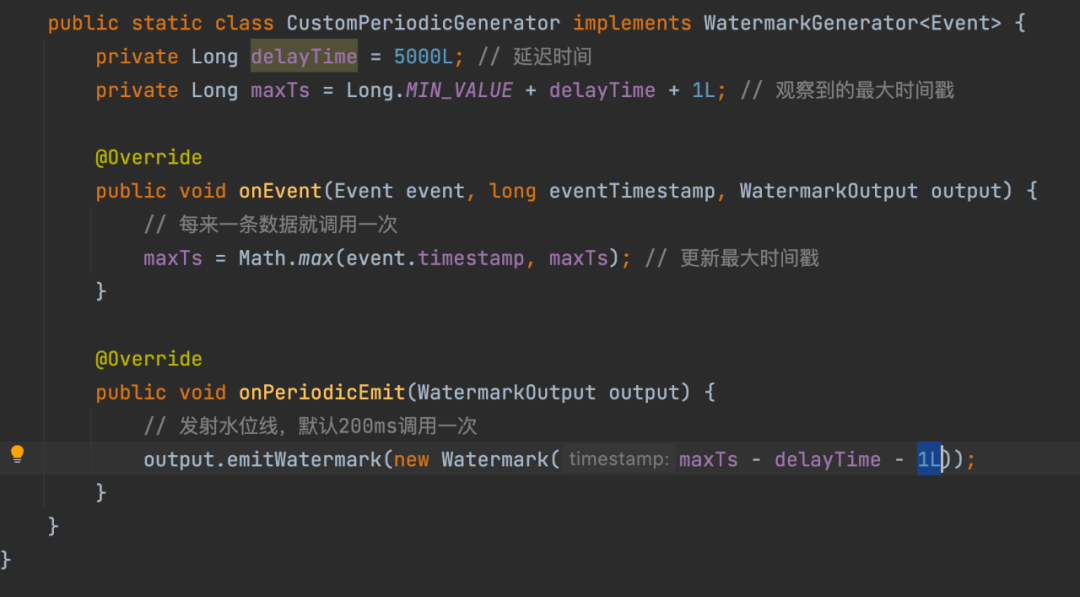
△Flink-Strategie zur Wasserstandsgenerierung
GEEK-TALK
04 Design und Anwendung des globalen Wasserspiegels
4.1 Gestaltung des zentralen Wasserstandsmanagements
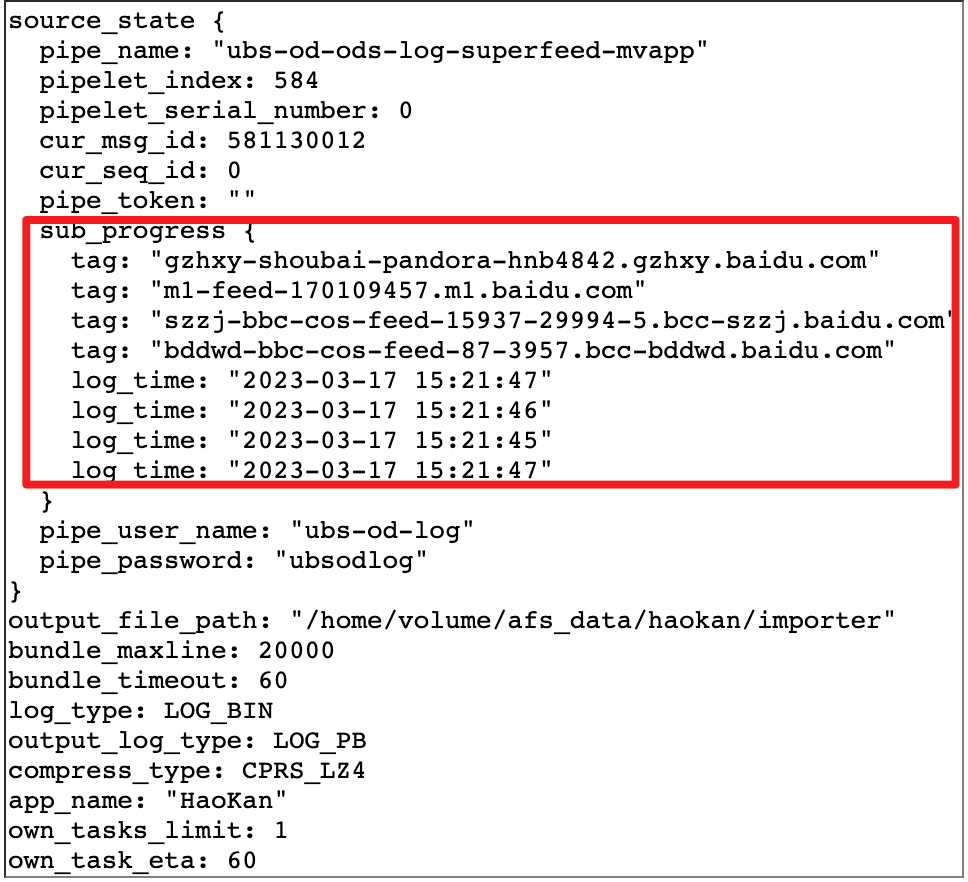
Um den Wasserstand bei der Echtzeitberechnung genauer zu machen, haben wir eine zentralisierte Wasserstandsmanagement-Idee entworfen, d. h. jeder Knoten der Echtzeitberechnung, einschließlich Quelle, Bediener, Senker usw., wird den Wasserstand melden selbst errechnete Informationen an den globalen Watermark Server, die einheitliche Verwaltung der Wasserstandsinformationen erfolgt durch Watermark Server.
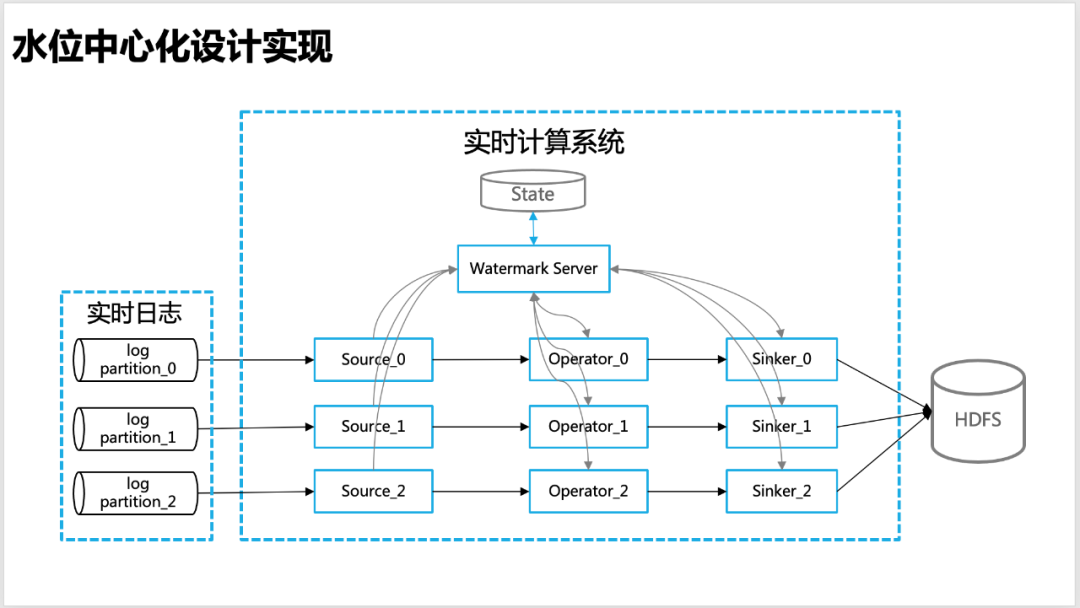
△Zentrales Wasserstandsdesign
Wasserzeichen-Server : Führen einer Wasserstandsinformationstabelle (hash_table), die die Wasserstandsinformationen enthält, die jeder Ebene der Gesamttopologieinformationen (Quelle, Betreiber, Sinker usw.) des Echtzeit-Berechnungsprogramms (APP) entsprechen, so Um die Berechnung des globalen Wasserstands (z. B. Niedrigwassermarke) zu erleichtern, interagiert Watermark Server regelmäßig mit dem Staat, um sicherzustellen, dass die Wasserstandsinformationen nicht verloren gehen.
Watermark-Client : Wasserstand-Update-Client, in Echtzeit Operatoren wie Quelle, Arbeiter und Senker, ist dafür verantwortlich, Wasserstandsinformationen (wie stromaufwärts oder globaler Wasserstand) an Watermark Server zu melden und anzufordern und einen Rückruf über baidu-rpc anzufordern Service.
Low Watermark (Niedrigwasserstand) : Low Watermark ist ein Zeitstempel, der verwendet wird, um die Zeit der frühesten (ältesten) unverarbeiteten Daten im Echtzeit-Datenverarbeitungsprozess zu markieren (Low Watermark, der pessimistisch versucht, die Ereigniszeit der ältesten unverarbeiteten Daten zu erfassen Aufzeichnung, die dem System bekannt ist. ). Es verspricht, dass keine zukünftigen Daten früher als dieser Zeitstempel eintreffen werden. Die Zeitberechnung basiert hier im Allgemeinen auf Eventtime, also dem Zeitpunkt, zu dem das Ereignis eintritt, wie zum Beispiel dem Zeitpunkt, zu dem das Benutzerverhalten im Protokoll auftritt, und der Datenverarbeitungszeit (Verarbeitungszeit, die in einigen Szenarien auch verwendet werden kann ) wird weniger verwendet. Die Formel für die Wasserzeichenberechnung lautet (aus Google MillWheel Thesis ):
Low Watermark von A = min (ältestes Werk von A, Low Watermark von C : C gibt an A aus)
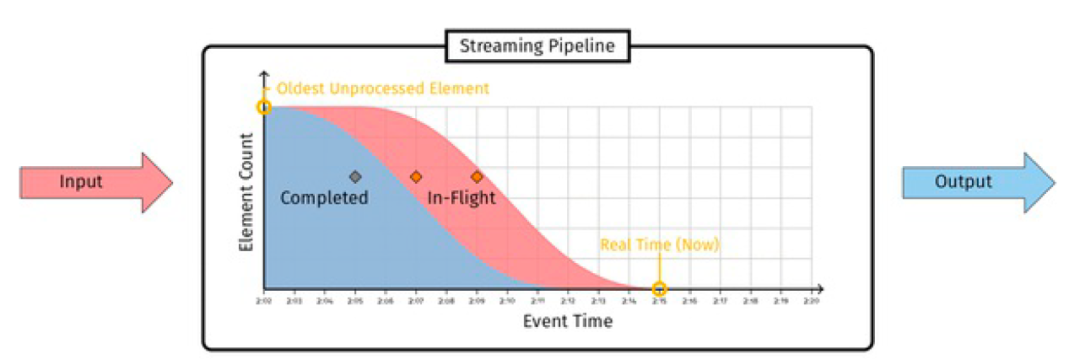
Beim tatsächlichen Systemdesign kann die Niedrigwassermarke jedoch gemäß der Grenze der Bedienerverarbeitung wie folgt unterschieden werden:
-
Input Low Watermark : Ältestes Werk, das noch nicht an diese Streaming-Phase gesendet wurde.
InputLowWatermark(Stage) = min { OutputLowWatermark(Stage') | Stage' ist stromaufwärts von Stage}
Geben Sie den niedrigsten Wasserstand ein, der als Wasserzeichen verstanden werden kann, das in den aktuellen Operator eingegeben wird, dh die Daten, die vom stromaufwärts gelegenen Operator verarbeitet werden.
-
Output Low Watermark : Ältestes Werk, das in dieser Streaming-Phase noch nicht abgeschlossen ist.
OutputLowWatermark(Stage) = min { InputLowWatermark(Stage), OldestWork(Stage) }
Geben Sie den niedrigsten Wasserstand aus, der als der früheste (älteste) Wasserstand von unverarbeiteten Daten durch den aktuellen Betreiber verstanden werden kann, d. h. den Wasserstand von verarbeiteten Daten.
Wie in der Abbildung unten gezeigt, wird das Verständnis lebendiger.
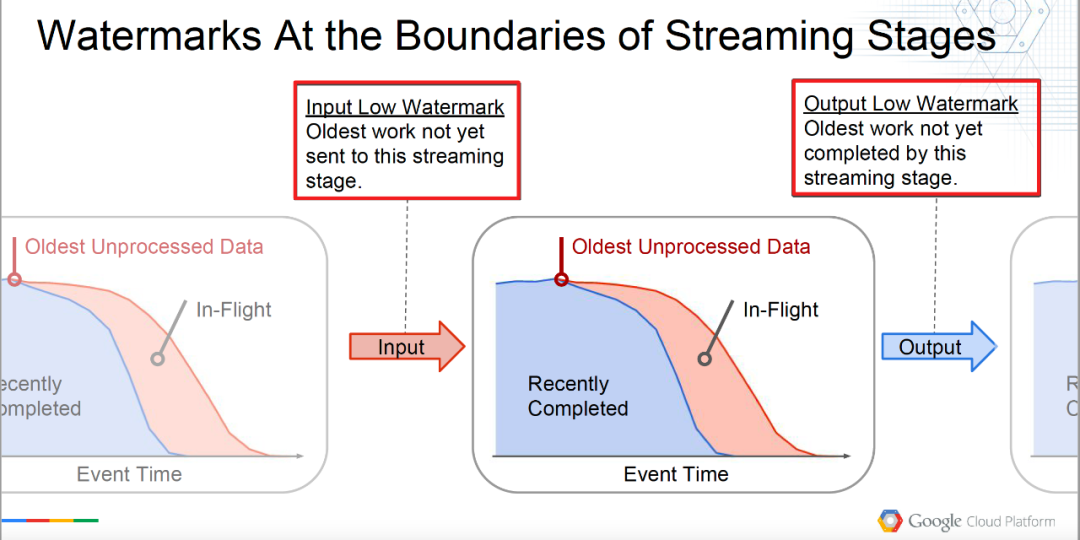 Grenzdefinition von △Low Watermark
Grenzdefinition von △Low Watermark
4.2 So erreichen Sie einen genauen Wasserstand
4.2.1 Voraussetzungen für einen genauen Wasserstand
Derzeit verwenden wir alle in den Anwendungsszenarien von Echtzeit-Rechensystemen in Echtzeit-Data Warehouses Low Watermark, um die Fensterberechnung auszulösen (weil es zuverlässiger ist. Aus der Definition von Low Watermark in 3.1 können wir das wissen). : Low Watermark wird durch hierarchische Iteration berechnet, und ob der Wasserstand genau ist, hängt von der Genauigkeit des am weitesten stromaufwärts gelegenen (dh Quell-) Wasserstands ab. Um also die Genauigkeit der Quellwasserstandsberechnung zu verbessern, benötigen wir folgende Voraussetzungen:
-
Protokolle werden serverseitig sequentiell nach Zeit (event_time) auf einem einzelnen Server erzeugt
-
Wenn das Protokoll erfasst wird, muss es zusätzlich zum eigentlichen Benutzerverhaltensprotokoll auch andere Informationen enthalten, wie z. B. Server-Tag (Hostname) und Protokollzeit (msg_time), wie in der folgenden Abbildung gezeigt

△ Verpackungsinformationen protokollieren
-
Das Protokoll wird Punkt-zu-Punkt in Echtzeit in der Nachrichtenwarteschlange veröffentlicht, um sicherzustellen, dass innerhalb einer einzelnen Partition der Nachrichtenwarteschlange die Protokolle eines einzelnen Servers strikt geordnet sind
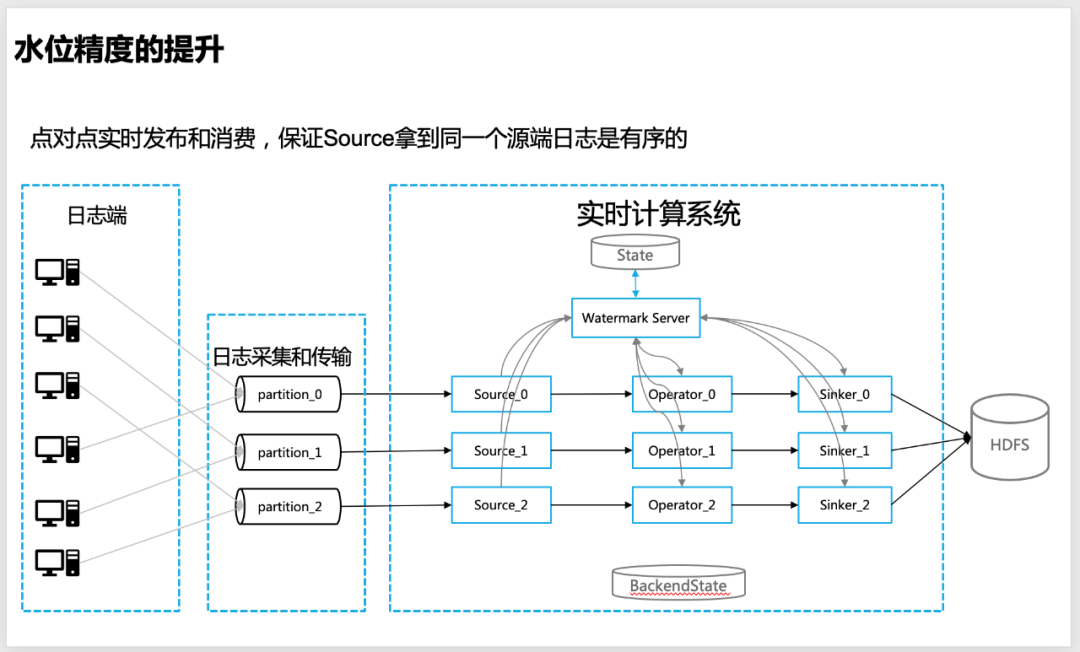
△ Das Quellprotokoll wird Punkt-zu-Punkt in der Nachrichtenwarteschlange veröffentlicht, um sicherzustellen, dass das Einzelpartitionsprotokoll geordnet ist
4.2.2 Berechnungsverfahren des Wasserstands
1. Wasserzeichenserver
Initialisieren :
Zuerst als separater Thread (Thread) gestartet. Gemäß dem BNS (Baidu Naming Service, Baidu Name Service, der eine Zuordnung vom Dienstnamen zu allen laufenden Instanzen des Servers bereitstellt) der konfigurierten Protokollübertragungsaufgabe wird die Serverliste (Hostnamenliste) der Protokollquelle geparst; Gemäß der konfigurierten APP-Topologiebeziehung wird das Wasserzeichen initialisiert Informationstabelle und persistente Schreibtabelle (Baidu Distributed KV Storage Engine).
Gewöhnliche Aktualisierung der Wasserstandsinformationen : Empfangen Sie die Wasserstandsinformationen vom Client und aktualisieren Sie den Wasserstand der entsprechenden Granularität (Prozessor-Granularität oder Schlüsselgruppen-Granularität) und aktualisieren Sie den lokalen Wasserstand
Genaue Wasserstandsberechnung :
Wenn das Protokoll an der Quelle 100 % genau ankommen muss, führt dies in Wirklichkeit zu häufigen oder zu langen Verzögerungen (wenn die globale Low-Watermark-Logik für die Verteilung verwendet wird). Der Grund ist: Bei zu vielen Serverinstanzen auf der Protokollseite (z. B. haben wir tatsächlich 6000-10000 Instanzen von Protokollen) kommt es immer zu einer Verzögerung beim Hochladen von Protokollen in Echtzeit in Instanzen von kabelgebundenen Onlinediensten , daher muss dies unter Gehen Sie einen Kompromiss zwischen Datenintegrität und Aktualität ein, wie z. B. die genaue Steuerung der Anzahl der Instanzen, die Verzögerungen in Form von Prozentsätzen zulassen (konfigurieren Sie beispielsweise 99,9 % oder 99,99 %, um den Anteil festzulegen, der source Protokolle zu verzögern ), um die Genauigkeit des Wasserstands an der Quelle genau zu kontrollieren.
Der genaue Wasserstand erfordert eine spezielle Konfiguration.Die untere Ausgangsgrenze der Quelle wird gemäß der Zuordnungsbeziehung zwischen dem Server und dem von der Quelle in Echtzeit gemeldeten Protokollfortschritt und dem konfigurierten Verhältnis der zulässigen Verzögerungsinstanzen berechnet.
Berechnen Sie die globale Niedrigwassermarke : Ein globaler Mindestwasserstand wird berechnet und auf Anfrage des Kunden zurückgegeben
Zustandspersistenz : Schreiben Sie regelmäßig globale Wasserstandsinformationen in einen externen Speicher, um den Zustand einfach wiederherzustellen
2. Wasserzeichen-Client
Source end : Analysieren Sie das Protokollpaket und rufen Sie Informationen wie den Computernamen und das ursprüngliche Protokoll im Protokollpaket ab. Nachdem das ursprüngliche Protokoll von ETL verarbeitet wurde und der neueste Zeitstempel (event_timestamps) gemäß dem ursprünglichen Protokoll abgerufen wurde, meldet Source regelmäßig die Zuordnungsbeziehungstabelle, die in den Hostnamen und den neuesten Zeitstempel (event_timestamps) aufgelöst wurde, über die Watermark-Client-API (derzeit konfiguriert 1000 ms) an Watermark Server.
△Quelle Die Zuordnungsbeziehung zwischen Server und Protokollfortschritt, die durch Analysieren des Protokolls erhalten wird
Bedienerseite :
Eingabe-Low-Watermark-Berechnung: Erhalten Sie das Ausgabe-Low-Watermark des Upstream (Upstream) als Eingabe-Low-Watermark, um zu bestimmen, ob die Fensterberechnung und andere Operationen ausgelöst werden sollen;
Berechnung des unteren Wasserzeichens für die Ausgabe: Berechnen Sie Ihr eigenes niedriges Wasserzeichen für die Ausgabe basierend auf Protokoll, Status (Zustand) und anderem Verarbeitungsfortschritt (älteste Arbeit) und melden Sie es an den Wasserzeichenserver zur Verwendung durch nachgeschaltete Betreiber (Download-Prozessor).
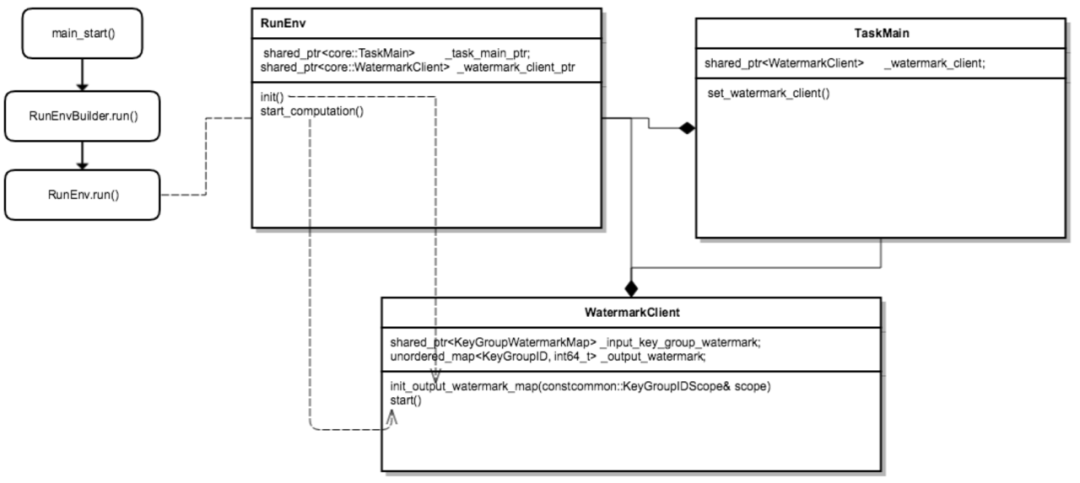
△Wasserzeichen-Client-Workflow
Platinenseite :
Die Sinker-Seite ist die gleiche wie der oben genannte normale Echtzeit-Operator (Operator), sie berechnet die Eingangs-Niedrigwassermarke und die Ausgangs-Niedrigwassermarke, um ihren eigenen Wasserstand zu aktualisieren.
Zusätzlich muss eine globale Low Watermark angefordert werden, um festzustellen, ob das Datenausgabefenster geschlossen ist.
4.3 Übertragung des genauen Wasserstands zwischen Systemen
Die Notwendigkeit der Wasserstandsübertragung
In vielen Fällen sind Echtzeitsysteme nicht isoliert, und es gibt eine Dateninteraktion zwischen mehreren Echtzeit-Rechensystemen.Die üblichste Art ist, dass zwei Echtzeit-Datenverarbeitungssysteme stromaufwärtsund stromabwärts angeordnet sind.
Die spezifische Leistung ist: Zwei Echtzeit-Datenverarbeitungssysteme implementieren die Datenübertragung über Nachrichtenwarteschlangen (wie Apache Kafka in der Community). Wie kann in diesem Fall also eine genaue Wasserstandsübertragung erreicht werden?
Die konkreten Umsetzungsschritte sind wie folgt :
1. Die Protokollquelle des vorgelagerten Echtzeit-Computersystems stellt sicher, dass das Protokoll Punkt-zu-Punkt freigegeben wird, wodurch die Genauigkeit des globalen Wasserstands sichergestellt werden kann (das spezifische Verhältnis ist einstellbar);
2. Auf der Ausgangsseite des vorgelagerten Echtzeit-Rechensystems (Senker/Exporter zum Ende der Nachrichtenwarteschlange) muss sichergestellt werden, dass die globale Niedrigwassermarke ausgegeben wird. Derzeit verwenden wir die zu druckenden globalen Wasserstandsinformationen auf jedem Protokoll, um die Lieferung zu erreichen;
3. Am Quellenende des stromabwärts gelegenen Echtzeit-Datenberechnungssystems ist es erforderlich, das Wasserstandsinformationsfeld zu analysieren, das von dem Protokoll (vom stromaufwärts gelegenen Echtzeit-Berechnungssystem) getragen wird, und damit zu beginnen, es als Eingabe zu verwenden den Wasserstand (Input Low Watermark) und starten Sie die iterative Berechnung des schichtweisen Wasserstands und der globalen Wasserstandsberechnung;
4. Auf der Operator/Ballastseite des nachgeschalteten Echtzeit-Datenverarbeitungssystems kann die Ereigniszeit des Protokolls immer noch verwendet werden, um eine spezifische Datensegmentierung als Eingabe der Fensterberechnung zu erreichen, aber der Mechanismus zum Auslösen der Fensterberechnung basiert immer noch auf die vom Watermark-Server zurückgegebenen globalen Daten hat Low Watermark Vorrang, um die Datenintegrität zu gewährleisten.
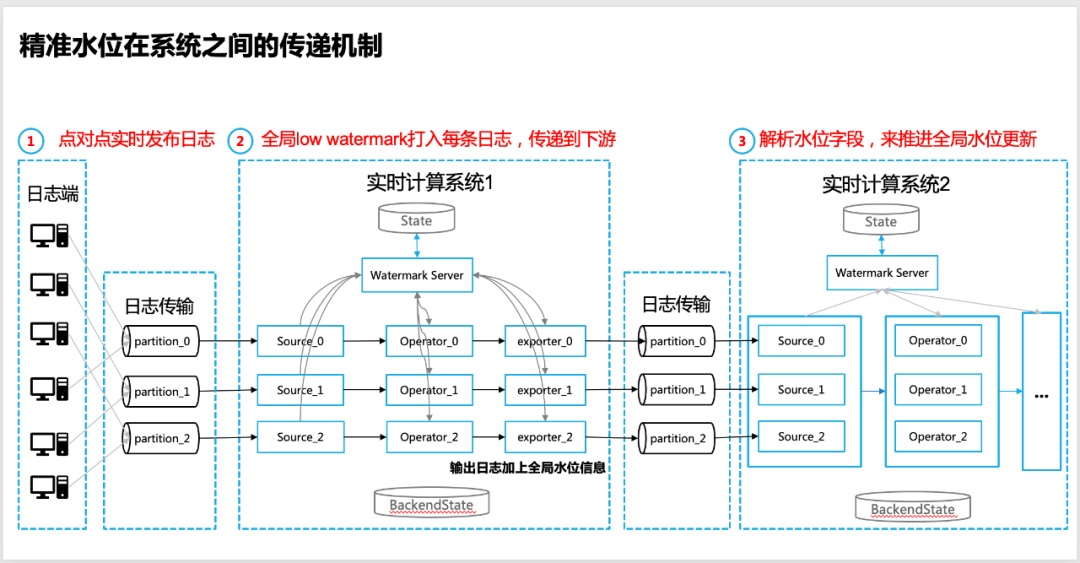
△Übertragungsmechanismus des genauen Wasserstands zwischen Echtzeit-Computersystemen
05 Tatsächliche Auswirkungen und Folgeperspektiven
5.1 Tatsächlicher Online-Effekt
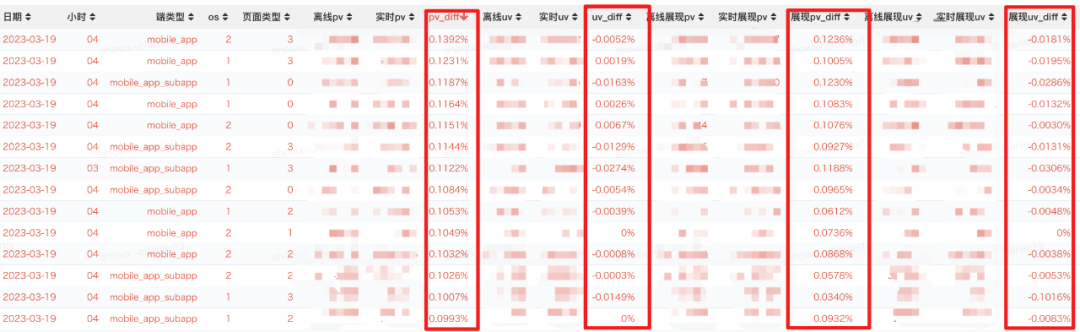
5.1.1 Der gemessene Effekt (Vollständigkeit) von Landedaten
Der eigentliche Online-Test übernimmt den genauen Wasserstand (die konfigurierte Genauigkeit des Wasserstands beträgt 99,9 %, d. h. es ist nur ein Tausendstel der Quellinstanzverzögerung zulässig) und, wenn keine Verzögerung im Protokoll auftritt, die Echtzeit-Landedaten und Offline-Daten liegen im selben Zeitfenster (Event Time) Der Wirkungsvergleich sieht wie folgt aus (grundsätzlich alle unter 100.000 Punkte):

△Die Auswirkung der Datenintegrität, wenn das Quellprotokoll nicht verzögert wird
Wenn das Quellprotokoll verzögert wird (<=0,1 % der Quellprotokollinstanz wird verzögert, der Wasserstand wird weiterhin aktualisiert), beträgt der gesamte Datendifferenzeffekt im Grunde etwa 1/1.000 (vorbehaltlich der Möglichkeit, dass der Protokollquellpunkt -to-point log selbst Einfluss von Dateninhomogenität):

Im Falle einer großen Verzögerung im Quellprotokoll (> 0,1 % der Quellprotokollinstanzverzögerung) wird aufgrund der Verwendung eines genauen Wasserstandsmechanismus (Wasserstandsgenauigkeit 99,9 %) der globale Wasserstand angezeigt nicht aktualisiert, und Echtzeitdaten werden in AFS geschrieben. Das Fenster wird nicht geschlossen, und das Fenster wird erst geschlossen, nachdem auf das Eintreffen verzögerter Daten und die Aktualisierung des globalen Wasserstands gewartet wurde, um die Integrität des zu gewährleisten Die tatsächlichen Testergebnisse sind wie folgt (zwischen 1,1 und 1,2 Promille, abhängig von der Protokollquelle Die Instanz selbst hat den Effekt der Ungleichmäßigkeit):
5.2 Zusammenfassung und Präsentation
Nach der Recherche zum tatsächlichen genauen Wasserstand und der tatsächlichen Online-Anwendung verbessert das auf dem genauen Wasserstand basierende Echtzeit-Data Warehouse nicht nur die Aktualität, sondern verfügt auch über einen höheren und flexibleren Datenpräzisionsmechanismus.Nach der Stabilitätsoptimierung ist es tatsächlich vollständig Anstelle der bisherigen Offline- und Echtzeit-Data-Warehouse-Systeme wird ein echtes Stream-Batch-integriertes Data-Warehouse realisiert.
Gleichzeitig wird es sich auf der Grundlage des zentralisierten Wasserstandsmechanismus auch den Herausforderungen der Leistungsoptimierung, der Hochverfügbarkeit (Verbesserung des Fehlerbehebungsmechanismus) und der feineren Granularität und des präzisen Wasserstands (unter dem Auslösemechanismus der Fensterberechnung) stellen.
--ENDE--
Verweise:
[1] T. Akidau, A. Balikov, K. Bekiroğlu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom und S. Whittle. Millwheel: Fehlertolerante Stream-Verarbeitung im Internetmaßstab. Proz. VLDB Endow., 6(11):1033–1044, Aug. 2013.
[2] T. Akidau, R. Bradshaw, C. Chambers, S. Chernyak, RJ Fernández-Moctezuma, R. Lax, S. McVeety, D. Mills, F. Perry, E. Schmidt, et al. Das Datenflussmodell: ein praktischer Ansatz zum Ausgleich von Korrektheit, Latenz und Kosten bei einer massiven, unbegrenzten, ungeordneten Datenverarbeitung. Proceedings of the VLDB Endowment, 8(12):1792–1803, 2015.
[3] T. Akidau, S. Chernyak und R. Lax. Streaming-Systeme. O'Reilly Media, Inc., 1. Auflage, 2018.
[4] „Wasserzeichen – Messung von Zeit und Fortschritt in Streaming-Pipelines“, Slava Chernyak, Google Inc
[5] P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi und K. Tzoumas. Apache flink: Stream- und Batch-Verarbeitung in einer einzigen Engine. Bulletin des Technischen Ausschusses für Data Engineering der IEEE Computer Society, 36(4), 2015.
Literatur-Empfehlungen:
Technische Lösung für Textvorlagen im Videobearbeitungsszenario
Sprechen Sie über die Anwendung des Graphalgorithmus in der Aktivitätsszene beim Anti-Cheating
Serverlos: Flexible Skalierungspraxis basierend auf personalisierten Serviceportraits
Aktionszerlegungsmethode in der Bildanimationsanwendung
Performance Platform Data Acceleration Road
Bearbeitung der AIGC-Videoproduktionsprozess-Anordnungspraxis