
Gemeinsamer Gast:
Fu Qingwu – Big-Data-Architekt der OPPO-Datenarchitekturgruppe
In der tatsächlichen Anwendung von OPPO haben wir das selbst entwickelte Shuttle perfekt mit Alluxio kombiniert, wodurch die Leistung des gesamten Shuttle-Dienstes deutlich verbessert und die Leistung im Grunde verdoppelt wurde. Durch diese Optimierung ist es uns gelungen, den Systemdruck um etwa die Hälfte zu reduzieren und den Durchsatz direkt zu verdoppeln. Diese Kombination löst nicht nur Leistungsprobleme, sondern verleiht dem Servicesystem von OPPO auch neue Vitalität.
Volltextversion zum Teilen von Inhalten↓
Teilendes Thema: „Alluxios Praxis in der Data&AI Lake- und Warehouse-Integration“
Data&AI integrierte Data-Lake-Warehouse-Architektur
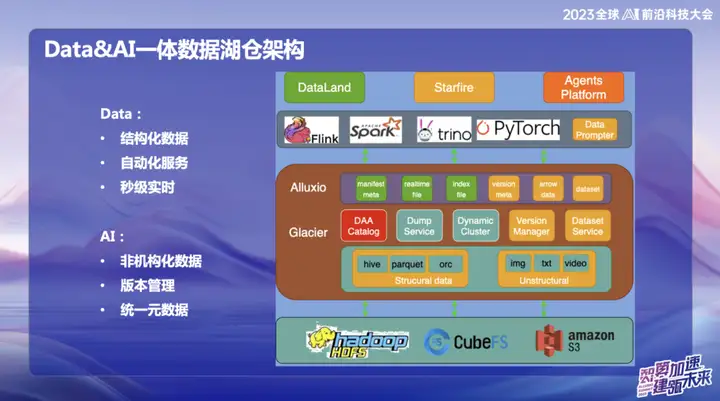
Das Bild oben zeigt die aktuelle Gesamtarchitektur von OPPO, die hauptsächlich in zwei Teile unterteilt ist:
1、Daten
2、KI
Im Datenbereich konzentriert sich OPPO hauptsächlich auf strukturierte Daten, also Daten, die üblicherweise mit SQL verarbeitet werden. Im Bereich KI liegt der Schwerpunkt vor allem auf unstrukturierten Daten. Um eine einheitliche Verwaltung strukturierter und unstrukturierter Daten zu erreichen, hat OPPO ein System namens „Daten und Katalog“ eingerichtet, das in Form von Katalogmetadaten verwaltet wird. Gleichzeitig handelt es sich hierbei auch um einen Data-Lake-Dienst, bei dem die obere Datenzugriffsschicht den verteilten Alluxio-Cache verwendet.
Warum haben wir uns für Alluxio entschieden?
Aufgrund der Größe des heimischen Computerraums von OPPO ist die Menge an ungenutztem Speicher auf den Rechenknoten beträchtlich. Wir schätzen, dass jeden Tag durchschnittlich etwa 1 PB Speicher im Leerlauf ist, und wir hoffen, dass wir ihn durch dieses verteilte Speicherverwaltungssystem vollständig nutzen können. Der orangefarbene Teil stellt die Verwaltung unstrukturierter Daten dar. Unser Ziel ist es, mithilfe von Data Lake-Diensten die Verwaltung unstrukturierter Daten genauso einfach zu gestalten wie strukturierte Daten und eine Beschleunigung des KI-Trainings zu ermöglichen.
DAA-Katalog
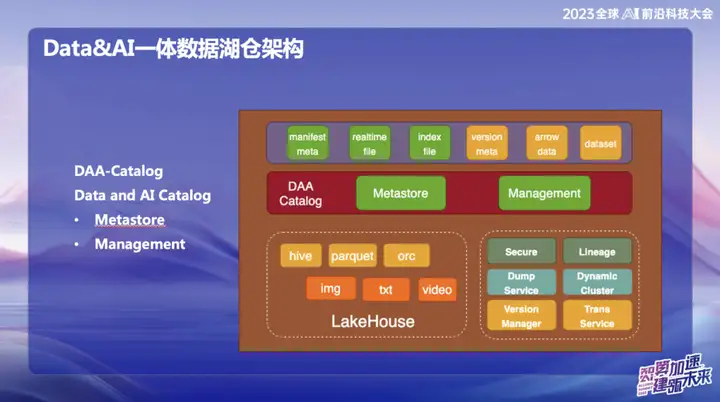
DAA-Katalog oder Daten- und KI-Katalog ist das Ziel, das unser Team am Ende der Datenarchitektur verfolgt. Wir haben diesen Namen gewählt, weil OPPO sich dem Wettbewerb mit den besten Unternehmen der Branche verschrieben hat. Derzeit glauben wir, dass Databricks eines der herausragendsten Unternehmen im Bereich Data&AI ist. Ob es um Technologie, fortschrittliche Konzepte oder Geschäftsmodelle geht, Databricks hat sich gut geschlagen.
Inspiriert durch den Unicatalog von Databricks sehen wir, dass sich die Servicedaten und der KI-Trainingsprozess von Databricks hauptsächlich um Unity Catalog drehen. Aus diesem Grund haben wir uns entschieden, DAA-Catalog zu entwickeln, um unser Ziel zu verfolgen, im Bereich Data Lake Warehousing mit den Besten der Branche zu konkurrieren.
Konkret ist diese Funktionalität in zwei Hauptmodule unterteilt:
- Metastore (Metadatenspeicher) : Dieser Teil ist für die Verwaltung von Metadaten verantwortlich, und die darunter liegende Ebene basiert auf der Iceberg-Metadatenverwaltung. Beinhaltet gleichzeitige Commits und Lebenszyklusverwaltung. Gleichzeitig verwenden wir Down Service für die Verwaltung, da unsere Daten zunächst in den riesigen Speicher-Cache-Pool von Alluxio gelangen und das Einfügen und Abfragen jedes Datensatzes in Echtzeit realisieren.
- Management : Dieser Teil ist ein DOM-Dienst. Warum sollten Sie sich für den Down-Dienst entscheiden? Da die Daten nach der Eingabe zunächst im Speicher von Alluxio gespeichert werden, wird eine Echtzeitleistung der zweiten Ebene erreicht. Während des gesamten Prozesses werden die Daten nach ihrem Eingang automatisch über Catalog an Iceberg weitergeleitet, und die Metadaten befinden sich grundsätzlich in Alluxio.
Warum müssen wir eine solche Echtzeitfunktion der zweiten Ebene implementieren?
Hauptsächlich, weil wir bei der Verwendung von Iceberg zuvor ein ernstes Problem festgestellt haben. Grundsätzlich ist alle 5 Minuten ein Commit erforderlich, was eine große Belastung für das Flink-Computersystem und die Metadaten von HDFS darstellt. Gleichzeitig müssen diese Dateien auch manuell bereinigt und zusammengeführt werden. Über den Alluxio-Dienst können Daten direkt in den Speicher eingegeben werden und auch der Down-Service wird über den Katalog verwaltet. Während des gesamten Prozesses werden die Daten nach der Eingabe automatisch in Iceberg gespeichert, und die Metadaten befinden sich im Grunde alle in Alluxio.
Da OPPO viel mit Alluxio zusammenarbeitet, haben wir auf Basis der Version 2.9 einige Anpassungen vorgenommen und die Leistung deutlich verbessert. Das Lesen und Schreiben von Streaming-Dateien wird im Data Lake implementiert. Jedes Datenelement kann wie ein Commit behandelt werden, ohne dass die gesamte Datei festgeschrieben werden muss.
Strukturierte Datenbeschleunigung
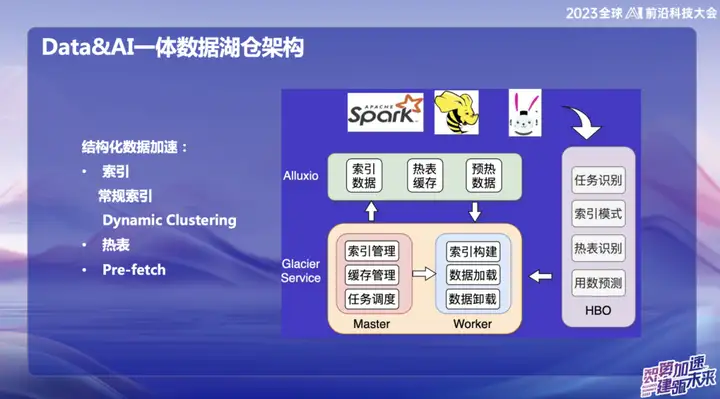
Mit der Entwicklung von Big Data sind viele Infrastrukturen ziemlich vollständig geworden und lösen Probleme in vielen verschiedenen Szenarien. Unser Fokus liegt jedoch darauf, wie wir ungenutzte Ressourcen und Speicher effizienter nutzen können. Daher sind wir bestrebt, von zwei Aspekten auszugehen: Der eine ist die Cache-Beschleunigung und der andere die Optimierung von Hot-Tabellen und Indizes.
Wir haben ein Konzept namens „Dynamic Cluster“ vorgeschlagen, bei dem es sich um eine Funktion zur dynamischen Aggregation von Daten handelt, die von einer Technologie von Databricks inspiriert ist. Obwohl die Flurkurve auch intern verwendet wird, haben wir darüber hinaus die Sortieralgorithmen „Reihenfolge“ und „Inkrementelle Reihenfolge“ implementiert und sie zu einem dynamischen Cluster zusammengeführt. Diese Innovation kann Daten nach der Dateneingabe dynamisch aggregieren, um die Abfrageeffizienz zu verbessern. Im Vergleich zur Hallway-Kurve ist der „Ordnungs“-Algorithmus effizienter, aber die Hallway-Kurve ist bei Echtzeitänderungen überlegen. Diese Integration bietet uns eine flexiblere und effizientere Möglichkeit, Daten abzufragen und zu aggregieren.
Unstrukturierte Datenverwaltung
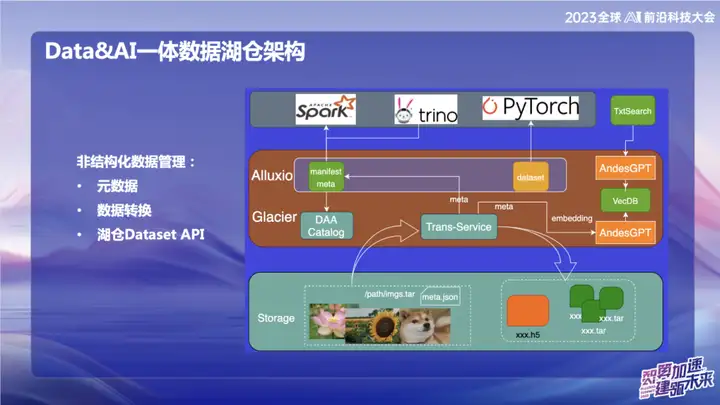
Das Bild oben zeigt einige unserer Arbeiten im Bereich unstrukturierte Daten, hauptsächlich im Zusammenhang mit dem Bereich KI. Innerhalb von OPPO sind die zu Beginn für das KI-Training verwendeten Tools relativ alt. Daten werden normalerweise direkt über Skripte gelesen oder die Daten werden in Form von nackten TXT-Dateien oder nackten Bilddateien im Objektspeicher gespeichert. Mit dem Transferdienst können wir Daten automatisch in den Data Lake importieren und die gepackten Bilddaten in das Update-Set-Format schneiden. Im Bereich der KI, insbesondere im Bereich der Bildverarbeitung, ist Update Set eine effiziente Datensatzschnittstelle. Es ist nicht nur mit Web-Datensatzschnittstellen kompatibel, sondern kann auch in das H5-Format konvertiert werden.
Unser Ziel ist es, die Verwaltung unstrukturierter Daten durch die Verarbeitung von Metadaten genauso komfortabel zu gestalten wie strukturierte Daten. Während des Datenkonvertierungsprozesses werden die Metadaten unstrukturierter Daten in den Katalog geschrieben. Gleichzeitig haben wir mit dem großen Modell kombiniert und einige Informationen der Metadaten in die Vektordatenbank geschrieben, um die Abfrage der Daten im Lake Warehouse mithilfe des großen Modells oder der natürlichen Sprache zu erleichtern. Das Ziel dieser Integrationsarbeit besteht darin, die Verwaltungseffizienz unstrukturierter Daten zu verbessern und sie konsistenter mit der Verwaltung strukturierter Daten zu machen.
Unstrukturierte Daten – Beispiel für Metadatenverwaltung
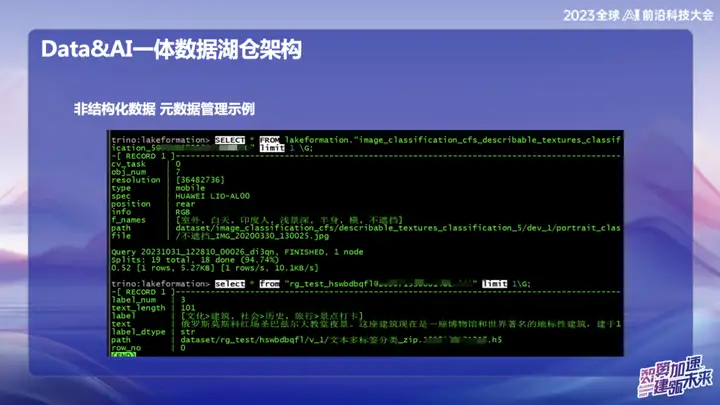
Das Bild oben ist ein Beispiel für die unstrukturierte Datenverwaltung von OPPO, mit der die Position von Text und Bildern wie SQL durchsucht werden kann.
DataPrompte r
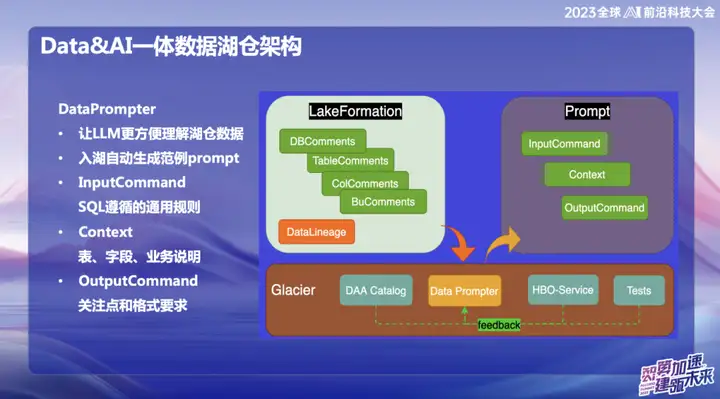
Die ursprüngliche Absicht, sich für die Entwicklung von DataPrompter zu entscheiden, beruht auf dem Streben nach einer besseren Nutzung großer Modelle. OPPO engagiert sich im Bereich der Datenkombination mit großen Modellen und hat ein Produkt namens Data Chart auf den Markt gebracht. Über eine interne Chat-Software können Benutzer alle Daten einfach abfragen. Benutzer können beispielsweise problemlos das Verkaufsvolumen von Mobiltelefonen von gestern überprüfen oder die Verkaufsdifferenz mit den Xiaomi-Handyverkäufen vergleichen und eine Datenanalyse in natürlicher Sprache durchführen.
Während des Produktentwicklungsprozesses erfordern die Datentabellen in jedem Feld die Eingabe von Prompter durch professionelles Geschäftspersonal. Dies stellt die Werbung für das gesamte Data Lake Warehouse oder Produkt vor Herausforderungen, da der Prompter jeder Tabelle lange dauert. Wenn Sie beispielsweise Finanztabellendaten eingeben möchten, müssen Sie professionelle und technische Informationen wie die Felder der Tabelle, die Bedeutung des Geschäftsbereichs und erweiterte Dimensionstabellen im Detail eingeben.
Unser oberstes Ziel ist es, dem großen Modell das einfache Verständnis der Daten der oberen Ebene zu ermöglichen, nachdem die Daten in das Lake Warehouse eingegeben wurden. Während der Dateneingabe in den See muss das Unternehmen einige vorgeschriebene Informationen anzeigen, diese mit unserer gesammelten Erfahrung mit Data Prompter kombinieren und einige häufige Abfragen des HBO-Dienstes verwenden, um schließlich eine Prompter-Vorlage zu generieren, die das große Modell leicht verständlich macht . Diese Kombination soll es dem Modell ermöglichen, Geschäftsdaten besser zu verstehen und die Integration von Hucang und großen Modellen reibungsloser zu gestalten.
Alluxio hilft dabei, den See in Sekundenschnelle in Echtzeit zu betreten
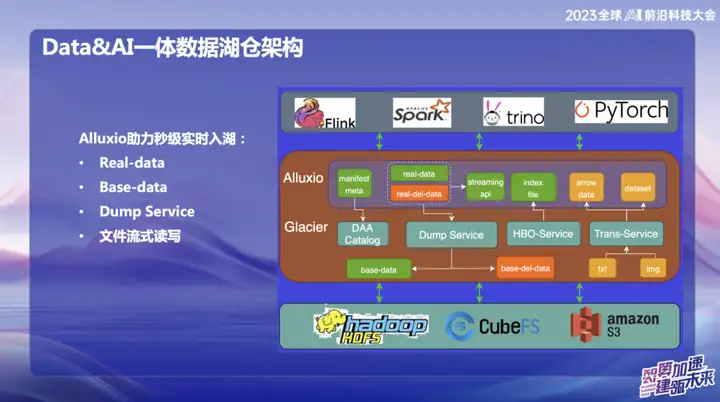
Alluxio hilft dabei, den See in Sekundenschnelle in Echtzeit zu betreten, der hauptsächlich in Folgendes unterteilt ist:
1、Echte Daten
2、Basisdaten
3、Dump-Service
4. Lesen und Schreiben von Dateistreaming
Alluxios Praxis in der Hucang-Architektur
Alluxio kombiniert mit Spark RSS
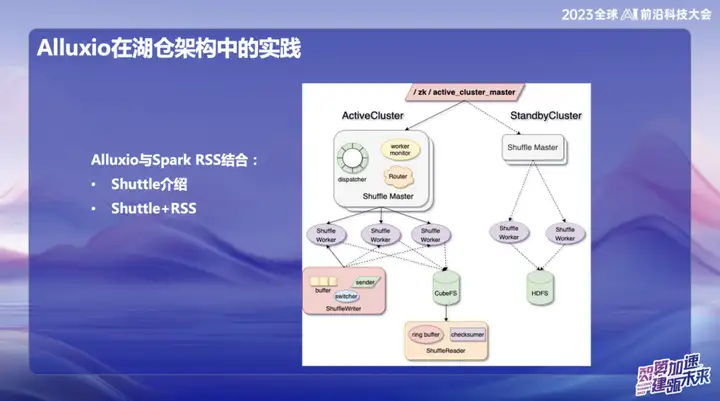
Wir haben uns zunächst dafür entschieden, Alluxio mit dem Spark RSS-Dienst über den selbst entwickelten Spark Shuttle Service zu kombinieren und ihn unter dem Namen Shuttle als Open Source zu veröffentlichen. Anfangs basierte unsere Basis auf einem verteilten Dateisystem, doch dann stießen wir auf einige Leistungsprobleme, sodass wir uns für Alluxio entschieden.
Die perfekte Kombination von Shuttle und Alluxio hat die Leistung des gesamten Shuttle-Dienstes erheblich verbessert und die Leistung praktisch verdoppelt. Durch diese Optimierung ist es uns gelungen, den Systemdruck um etwa die Hälfte zu reduzieren und den Durchsatz direkt zu verdoppeln. Diese Kombination löst nicht nur das Leistungsproblem, sondern verleiht unserem Servicesystem auch neue Dynamik.
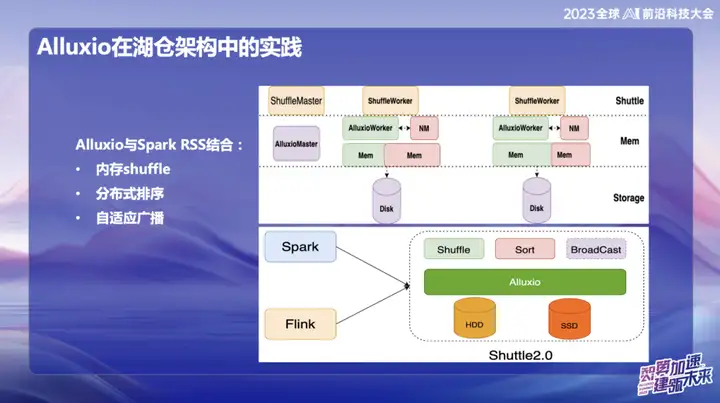
In der anschließenden Forschung und Entwicklung von OPPO hat das auf Alluxio+Shuttle basierende Framework weitere Innovationen erzielt. Wir optimieren sowohl den Shuttle-Operator als auch den Broadcast-Operator auf Speicherdatenebene. Durch effiziente Speicherdateninteraktion, insbesondere bei der Verarbeitung von Einzelpunkt-Reduzierungen, kann der Sortiervorgang, der ursprünglich bis zu 50 Minuten dauerte, migriert werden. Nach der Einführung der neuen Lösung konnte die Bearbeitungszeit erfolgreich auf weniger als 10 Minuten reduziert werden. Diese Optimierung verbessert nicht nur die Verarbeitungseffizienz erheblich, sondern mildert auch wirksam die Auswirkungen von Datenverzerrungen auf die Systemleistung.
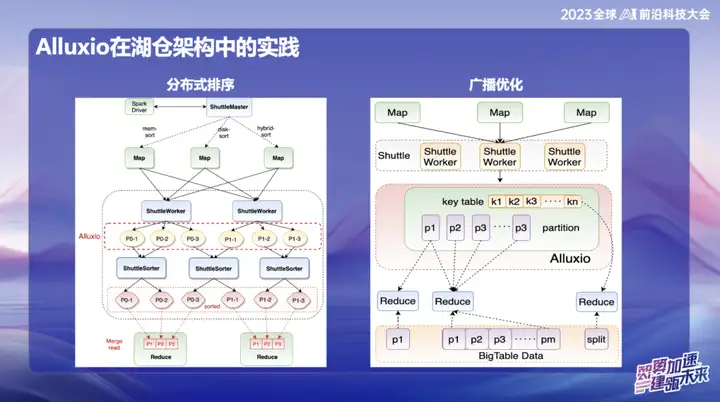
Die Broadcast-Ergebnisse sind besonders in Spark von großer Bedeutung. Da alle Broadcast-Daten auf der Java-Seite gespeichert werden müssen, besteht die Gefahr einer Erweiterung nach der Java-Serialisierung, was wiederum zu OOM-Problemen (Out of Memory) führt . Dies passiert häufig in Online-Umgebungen.
Um dieses Problem zu lösen, speichern wir derzeit Broadcast-Daten in Alluxio. Damit ist die Übertragung nahezu jeder Datengröße möglich, bis zu 10 Gigabyte. Diese Innovation wurde bei OPPO online in mehreren Fällen erfolgreich umgesetzt und hatte erhebliche Auswirkungen auf die Effizienzsteigerung.
Alluxio-Anwendungspraxis in der Public Cloud/Hybrid Cloud
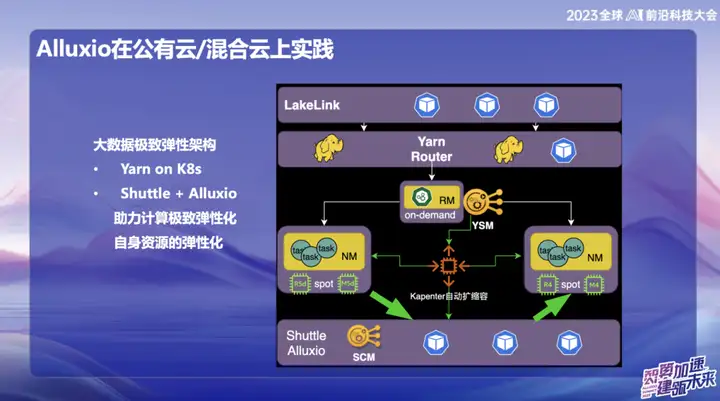
Im öffentlichen Cloud-Big-Data-System von OPPO, insbesondere in Singapur, verwenden wir hauptsächlich AWS als Infrastruktur. In der Anfangsphase nutzten wir den von AWS bereitgestellten Elastic Computing Service (EMR). Allerdings war die gesamtwirtschaftliche Lage der Branche in den letzten Jahren weniger optimistisch und viele Unternehmen streben nach Kostensenkungen und Effizienzsteigerungen. Angesichts dieses Trends haben wir selbst entwickelte Lösungen im Bereich der öffentlichen Cloud in Übersee vorgeschlagen und dabei elastische Ressourcen in der Cloud genutzt, um eine neue Architektur aufzubauen. Der Kern dieser innovativen Lösung basiert auf der Kombination von Alluxio+Shuttle, die eine wichtige Unterstützung für unser Big-Data-System bietet.

Der wesentliche Vorteil der Alluxio+Shuttle-Lösung besteht darin, dass der Alluxio-Cluster nicht exklusiv für Shuttle ist und Unterstützung für andere Dienste bieten kann, einschließlich Daten-Caching und Metadaten-Caching. Wir wissen, dass Listenvorgänge auf S3 während der Übermittlung sehr zeitaufwändig sind. Durch die Kombination von Alluxio und den Open-Source-Lösungen Magic Commit und Shuttle haben wir erhebliche Kostensenkungseffekte erzielt und die Rechenkosten um etwa 80 % gesenkt. .
In einer Hybrid-Cloud-Umgebung stellen wir Dienste für KI-Teams bereit. Da sich am Ende des Datensees ein Objektspeicher befindet, haben wir während des Trainingsprozesses die GPU-Karte in Alibaba Cloud verwendet und diese auch mit selbst erstellten GPU-Ressourcen kombiniert. Aufgrund der begrenzten Bandbreite und der hohen Kosten von Standleitungen ist für das Kopieren von Daten eine effektive Cache-Schicht erforderlich. Zunächst haben wir eine vom Speicherteam bereitgestellte Lösung übernommen, deren Skalierbarkeit und Leistung jedoch nicht ideal waren. Nach der Einführung von Alluxio haben wir in mehreren Szenarien eine mehrfache IO-Beschleunigung erreicht und so eine effizientere Unterstützung für die Datenverarbeitung bereitgestellt.
Ausblick

Die Clustergröße von OPPO hat in China Zehntausende Einheiten erreicht, was eine ziemlich große Größe darstellt. Wir planen, in Zukunft tiefer in die Speicherressourcen einzutauchen, um den internen Speicherplatz besser auszunutzen. Das Team verfügt sowohl über das Echtzeit-Computing-Framework Flink als auch über das Offline-Verarbeitungsframework Spark. Die beiden können von den Anwendungserfahrungen des anderen mit Alluxio lernen, um eine tiefgreifende integrierte Entwicklung von Alluxio und dem Data Lake zu erreichen.
Im Zuge der Kombination von Big Data und maschinellem Lernen bleiben wir mit den Branchentrends Schritt. Integrieren Sie die Datenarchitektur von Grund auf tief in die künstliche Intelligenz (KI), um qualitativ hochwertige Dienste für die KI als oberste Priorität bereitzustellen. Diese Integration ist nicht nur ein technologischer Fortschritt, sondern auch ein strategischer Plan für die zukünftige Entwicklung.
Abschließend werden wir die Vorteile von Alluxio weiter untersuchen, die uns dabei helfen, die Kosten in öffentlichen Cloud-Umgebungen zu senken. Dabei geht es nicht nur um technische Optimierungen, sondern auch um eine effektivere Verwaltung der Cloud-Computing-Ressourcen, die die nachhaltige Entwicklung des Unternehmens nachhaltig unterstützen.
Die Raubkopien von „Qing Yu Nian 2“ wurden auf npmror hochgeladen, was dazu führte, dass npmmirror den Unpkg-Dienst einstellen musste: Es bleibt nicht mehr viel Zeit für Google. Ich schlage vor, dass alle Produkte Open Source sind . time.sleep(6) spielt hier eine Rolle. Linus ist am aktivsten beim „Hundefutter fressen“! Das neue iPad Pro verwendet 12 GB Speicherchips, behauptet jedoch, über 8 GB Speicher zu verfügen. People’s Daily Online bewertet die Aufladung im Matroschka-Stil: Nur durch aktives Lösen des „Sets“ können wir eine Zukunft haben Neues Entwicklungsparadigma für Vue3, ohne die Notwendigkeit von „ref/reactive“ und ohne die Notwendigkeit von „ref.value“. MySQL 8.4 LTS Chinesisches Handbuch veröffentlicht: Hilft Ihnen, den neuen Bereich der Datenbankverwaltung zu meistern Tongyi Qianwen GPT-4-Level-Hauptmodellpreis reduziert um 97 %, 1 Yuan und 2 Millionen Token