
iQiyi baute ein traditionelles Offline-Data-Warehouse auf Basis von Hive auf, um die operativen Entscheidungen des Unternehmens, das Benutzerwachstum, Videoempfehlungen, Mitgliedschaft, Werbung und andere Geschäftsanforderungen zu unterstützen. In den letzten Jahren haben Unternehmen höhere Anforderungen an Echtzeitdaten gestellt. Wir haben die auf Iceberg basierende Data-Lake-Technologie eingeführt, um die Datenabfrageleistung und die Gesamteffizienz der Zirkulation deutlich zu verbessern. Aus Leistungs- und Kostengründen ist die Migration vorhandener Hive-Tabellen in den Data Lake erforderlich. Im Laufe der Jahre haben sich jedoch Hunderte Petabyte an Hive-Daten auf der Big-Data-Plattform angesammelt. Die Migration von Hive in den Data Lake ist für uns zu einer großen Herausforderung geworden. In diesem Artikel wird die technische Lösung von iQiyi für eine reibungslose Migration von Hive zum Iceberg Data Lake vorgestellt, die Unternehmen dabei hilft, Datenprozesse zu beschleunigen und Effizienz und Umsatz zu verbessern.
01
Bienenstock gegen Eisberg
Hive ist eine Hadoop-basierte Data Warehouse- und Analyseplattform, die eine SQL-ähnliche Sprache zur Unterstützung komplexer Datenverarbeitung und -analyse bereitstellt.
Iceberg ist ein Open-Source-Datentabellenformat, das einen skalierbaren, stabilen und effizienten Tabellenspeicher zur Unterstützung analytischer Arbeitslasten bietet. Iceberg bietet Transaktionsgarantien und Datenkonsistenz ähnlich wie herkömmliche Datenbanken und unterstützt komplexe Datenvorgänge wie Aktualisierungen, Löschungen usw.
Tabelle 1-1 listet den Vergleich zwischen Hive und Iceberg im Hinblick auf Aktualität, Abfrageleistung usw. auf:
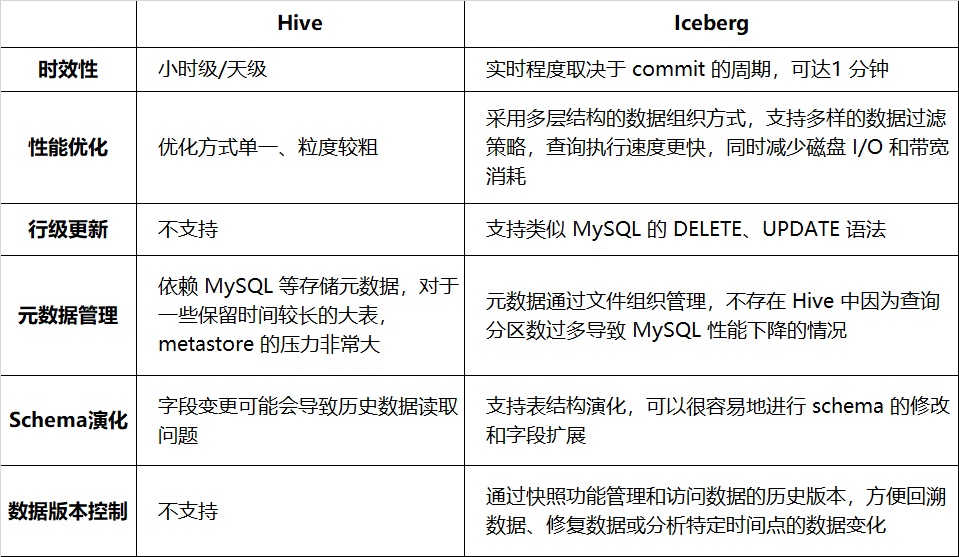
Tabelle 1-1 Vergleich zwischen Hive und Iceberg
Der Wechsel zu Iceberg kann die Effizienz und Zuverlässigkeit der Datenverarbeitung verbessern und eine bessere Unterstützung für komplexe Datenvorgänge bieten. Derzeit ist es mit mehr als einem Dutzend Unternehmen wie Werbung, Mitgliedschaft, Venus-Protokollen und Auditing verbunden. Weitere Einzelheiten zur Iceberg-Praxis von iQiyi finden Sie in der vorherigen Artikelserie (siehe Zitat am Ende des Artikels).
02
Bienenstockbestandsdaten reibungsloser Eisbergwechsel
Iceberg hat viele Vorteile gegenüber Hive, aber die Geschäftsdaten laufen bereits in der Hive-Umgebung und das Unternehmen möchte nicht viel Personal in die Änderung der Inventaraufgaben investieren. Wir haben gängige Umschaltmethoden in der Branche untersucht [1] und die Möglichkeit bereitgestellt, reibungslos zwischen Self-Service-Hive und Iceberg auf der Data-Lake-Plattform zu wechseln. In diesem Abschnitt wird der spezifische Implementierungsplan beschrieben.
1. Kompatibilität prüfen
Vor dem eigentlichen Wechsel haben wir die Kompatibilität von Spark mit Hive und Iceberg überprüft.
Die Abfrage- und Schreibsyntax von Spark für Hive- und Iceberg-Tabellen ist grundsätzlich gleich. Die SQL-Anweisungen zum Abfragen von Hive-Tabellen können Iceberg-Tabellen ohne Änderung abfragen.
Es gibt jedoch große Unterschiede zwischen Iceberg und Hive in Bezug auf DDL, hauptsächlich in der Art und Weise, wie die Tabellenstruktur geändert wird. Die Details sind in Tabelle 2-1 beschrieben. Es muss eine Eins-zu-Eins-Entsprechung zwischen dem tatsächlichen Schema und dem Schema der Datendatei bestehen, da dies sonst Auswirkungen auf die Datenabfrage hat. Daher sollten Sie bei der Verarbeitung von DDL-Anweisungen vorsichtiger sein solche DDL-Anweisungen mit Aufgaben.
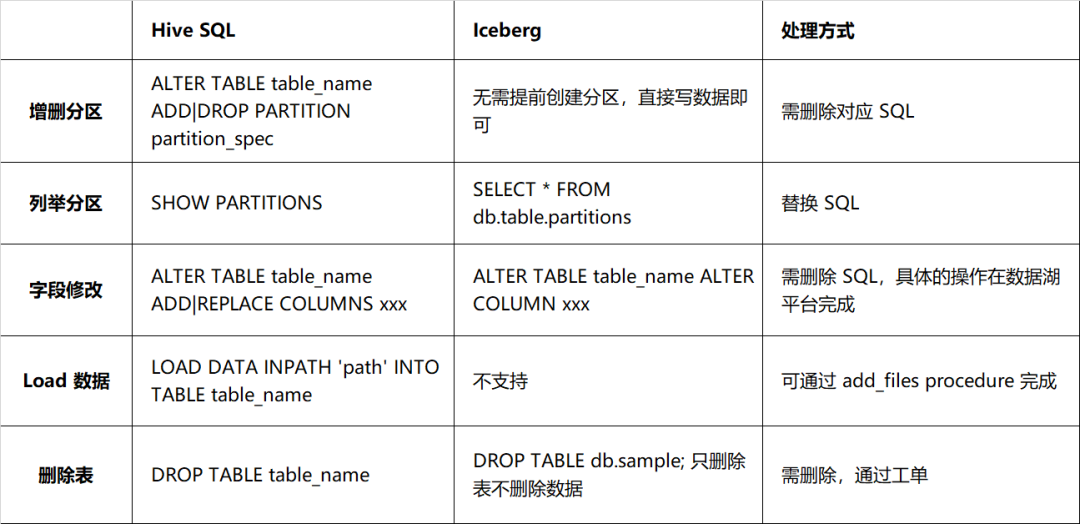
Tabelle 2-1 Syntaxkompatibilitätsvergleich zwischen Hive und Iceberg
2. Branchenwechsellösung
2.1 Business-Double-Write-Switching
Das Unternehmen repliziert die bestehende Pipeline, um das duale Schreiben von Hive und Iceberg zu implementieren. Nachdem die alten und neuen Kanalpaare konsistent sind, wechseln Sie zum Iceberg-Kanal und melden Sie sich vom ursprünglichen Kanal ab. Diese Lösung erfordert, dass das Unternehmen Arbeitskräfte in die Entwicklung und Berechnung investiert, was zeitaufwändig und arbeitsintensiv ist.
2.2 Schalter an Ort und Stelle, Client hört auf zu schreiben
Wenn es dem Unternehmen erlaubt ist, für einen bestimmten Zeitraum mit dem Schreiben aufzuhören und zu wechseln, können die folgenden Methoden verwendet werden:
-
Das Spark-Migrationsverfahren ist eine offiziell von Iceberg bereitgestellte Funktion, mit der eine Hive-Tabelle direkt auf Iceberg umgestellt werden kann. Das Beispiel lautet wie folgt:
CALL Catalogue_name.system.migrate('db.sample'); |
Dieses Programm verändert die Originaldaten nicht, es scannt nur die Daten der Originaltabelle und erstellt dann Iceberg-Metainformationen unter Bezugnahme auf die Originaldatei. Daher wird das Migrationsprogramm sehr schnell ausgeführt, die vorhandenen Daten können jedoch keine Funktionen wie Dateiindizes zur Beschleunigung von Abfragen nutzen. Wenn Sie möchten, dass auch vorhandene Daten beschleunigt werden, können Sie die rewrite_data_files- Methode von Spark verwenden, um historische Daten neu zu schreiben.
Das Migrationsprogramm löscht die Hive-Tabelle nicht, sondern benennt sie in „sample__BACKUP__“ um. Das Suffix __BACKUP__ ist hier fest codiert. Wenn Sie ein Rollback durchführen müssen, können Sie die neu erstellte Iceberg-Tabelle löschen und die Hive-Tabelle wieder umbenennen.
-
Unter Verwendung der CTAS- Anweisung sieht das Spark-Beispiel wie folgt aus:
CREATE TABLE db.sample_iceberg MIT Iceberg PARTITIONIERT DURCH dt STANDORT 'qbfs://....' TBLPROPERTIES('write.target-file-size-bytes' = '512m', ...) AS SELECT * FROM db.sample; |
Nachdem der Schreibvorgang abgeschlossen ist, wird der Logarithmus ausgeführt. Nachdem die Anforderungen erfüllt sind, wird der Wechsel durch Umbenennung abgeschlossen.
ALTER TABLE db.sample RENAME TO db.sample_backup; ALTER TABLE db.sample_iceberg RENAME TO db.sample; |
Der Vorteil von CTAS im Vergleich zu Migrate besteht darin, dass die vorhandenen Daten neu geschrieben werden, sodass Partitionierung, Spaltensortierung, Dateiformate, kleine Dateien usw. optimiert werden können. Der Nachteil besteht darin, dass das Umschreiben bei vielen vorhandenen Daten zeitaufwändig und ressourcenintensiv ist.
Die beiden oben genannten Lösungen weisen die folgenden Merkmale auf:
Vorteil:
Die Lösung ist einfach: Führen Sie einfach vorhandenes SQL aus
Kann zurückgesetzt werden, die ursprüngliche Hive-Tabelle ist noch vorhanden
Mangel:
Schreib-/Leser nicht validiert: Nach dem Wechsel zur Iceberg-Tabelle können Schreib- oder Abfrageausnahmen auftreten
Für einige Unternehmen ist es inakzeptabel, den Umschaltvorgang zum Stoppen des Schreibens zu verpflichten
3. iQiyi reibungsloser Migrationsplan
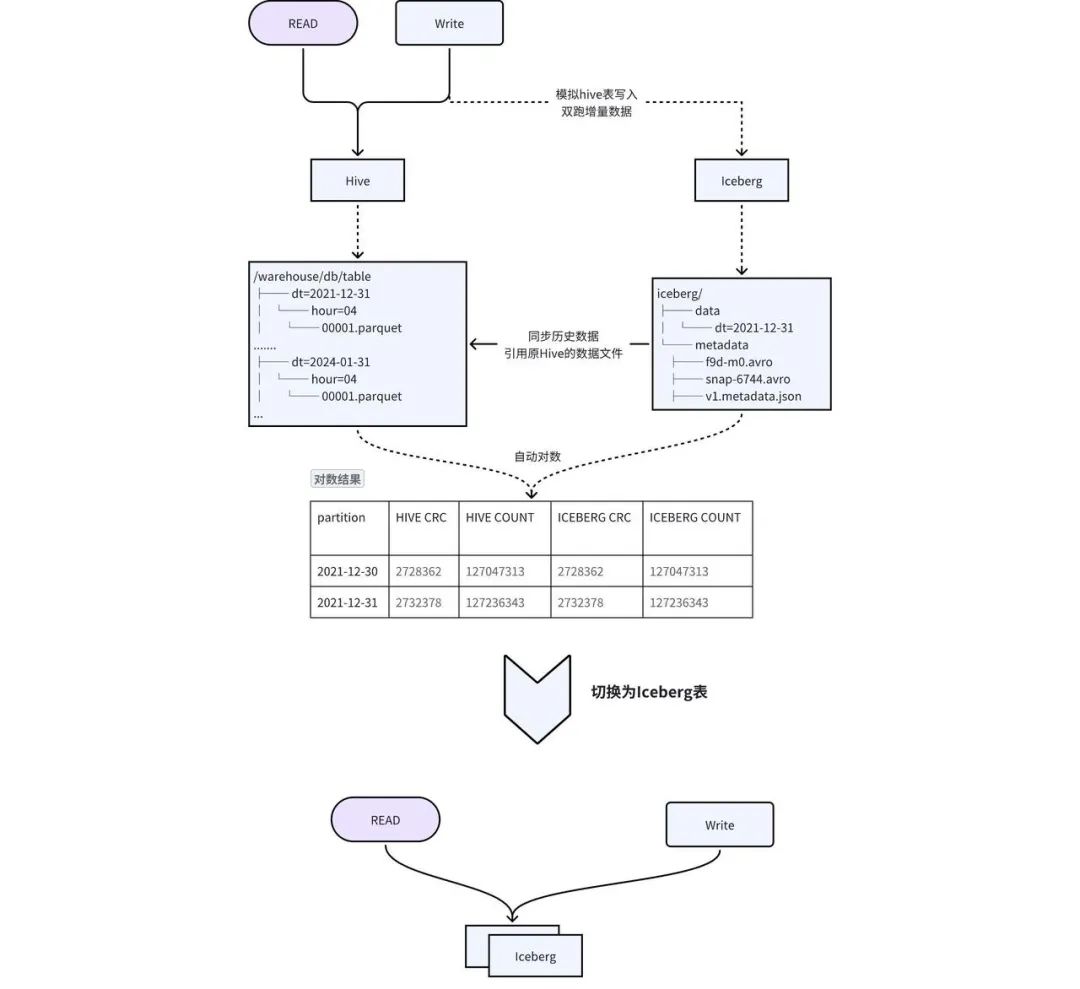
In Anbetracht der Mängel der oben genannten Lösung haben wir eine Lösung aus Dual-Write-in-Place + transparentem Switching entwickelt, um eine reibungslose Migration zu erreichen, wie in Abbildung 2-1 dargestellt:
-
Tabellenerstellung : Erstellen Sie eine Iceberg-Tabelle mit demselben Schema wie Hive und synchronisieren Sie Metainformationen wie TTL und Berechtigungen der Hive-Tabelle mit der Iceberg-Tabelle. -
Migrieren historischer Daten zu Iceberg : Mithilfe der Prozedur „add_file“ werden die Metadaten von Iceberg auf die Datendateien von Hive verwiesen, wodurch die Datenredundanz und die Zeit für die Synchronisierung historischer Daten reduziert werden. -
Inkrementelles doppeltes Schreiben von Daten : Das von iQIYI selbst entwickelte Pilot-SQL-Gateway erkennt Schreibaufgaben in der Hive-Tabelle, kopiert und schreibt automatisch SQL und ersetzt die Ausgabe durch die Iceberg-Tabelle, um doppeltes Schreiben zu erreichen. -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
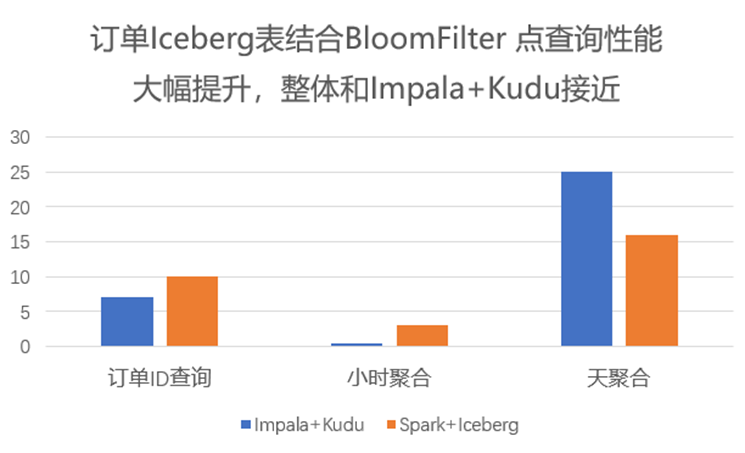
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
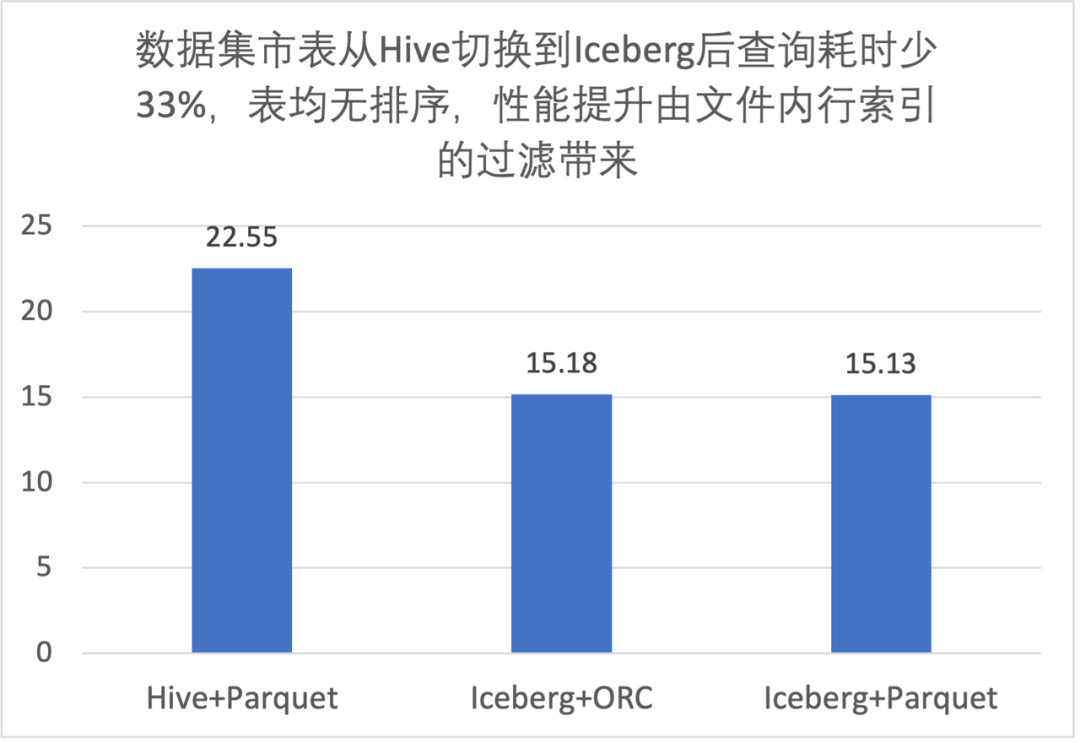
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
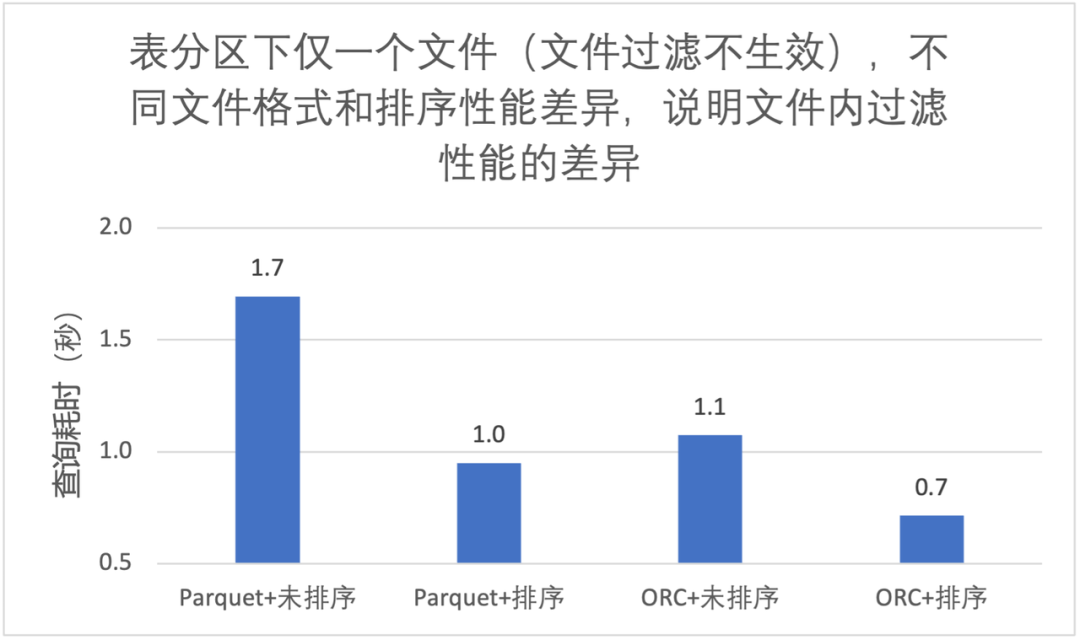
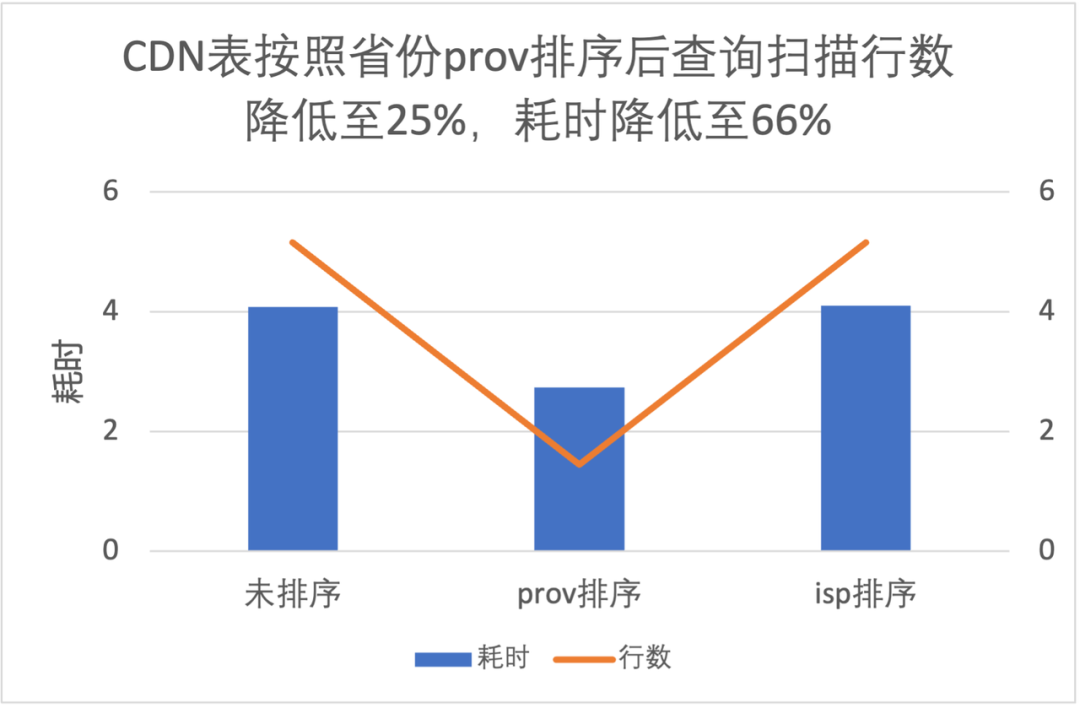
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
3.4 布隆过滤器的性能提升
3.5 Spark 和 Trino 性能比较
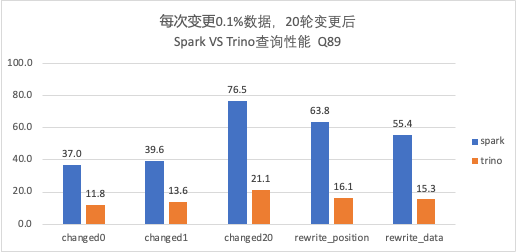
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
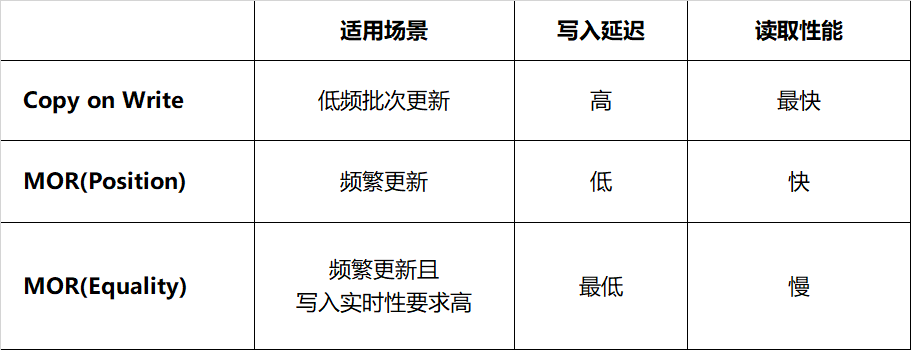 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
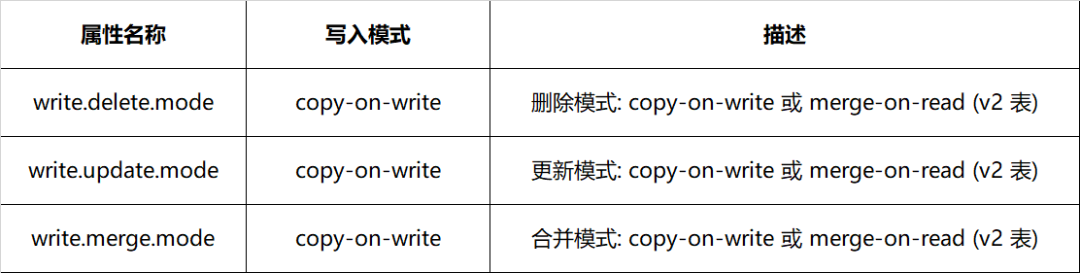 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
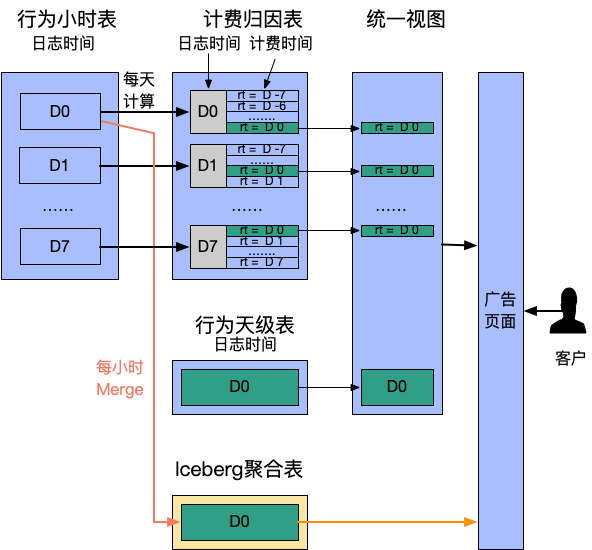
5.1 广告计费转换
-
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。