
01
Hintergrund
02
Einführung in die Venus-Log-Plattform
Venus ist eine von iQiyi entwickelte Protokolldienstplattform, die Protokolle sammelt, verarbeitet, speichert und analysiert. Sie wird hauptsächlich zur Protokollfehlersuche, zur Big-Data-Analyse, zur Überwachung und zur Alarmierung innerhalb des Unternehmens verwendet 1. angezeigt.
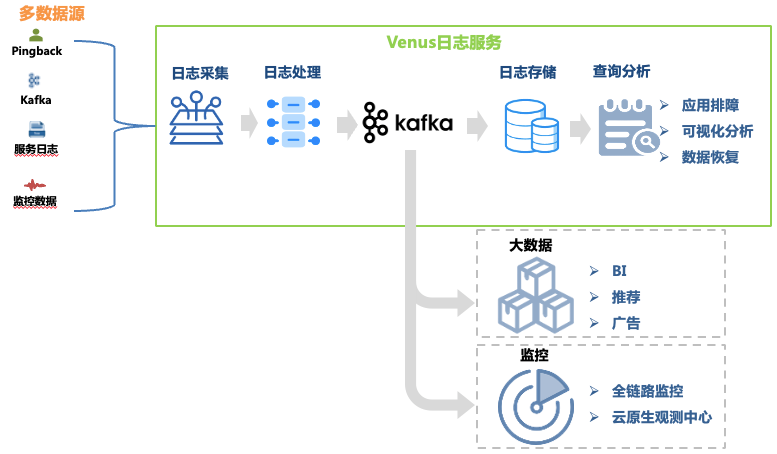 Abbildung 1 Venus-Link
Abbildung 1 Venus-Link
Dieser Artikel konzentriert sich auf die architektonische Entwicklung des Protokoll-Fehlerbehebungslinks. Zu seinen Datenlinks gehören:
Protokollsammlung : Durch die Bereitstellung von Sammlungsagenten auf Maschinen und Container-Hosts werden Protokolle von Front-End, Back-End, Überwachung und anderen Quellen jedes Geschäftsbereichs gesammelt, und das Unternehmen wird auch dabei unterstützt, Protokolle, die den Formatanforderungen entsprechen, selbst bereitzustellen . Es wurden mehr als 30.000 Agenten bereitgestellt, die 10 Datenquellen wie Kafka, MySQL, K8s und Gateways unterstützen.
Protokollverarbeitung : Nach der Protokollerfassung wird es einer standardisierten Verarbeitung wie regelmäßiger Extraktion und integrierter Parser-Extraktion unterzogen und einheitlich im JSON-Format in Kafka geschrieben und dann vom Dump-Programm in das Speichersystem geschrieben.
Protokollspeicher : Venus speichert fast 10.000 Geschäftsprotokollströme mit einer Schreibspitze von mehr als 10 Millionen QPS und täglich neuen Protokollen von mehr als 500 TB. Da sich die Speicherskala ändert, hat auch die Auswahl der Speichersysteme viele Änderungen erfahren, von ElasticSearch bis hin zu Data Lake.
Abfrageanalyse : Venus bietet visuelle Abfrageanalyse, kontextbezogene Abfrage, Protokolldatenträger, Mustererkennung, Protokoll-Download und andere Funktionen.
Um der Speicherung und schnellen Analyse großer Protokolldaten gerecht zu werden, wurde die Venus-Protokollplattform drei großen Architektur-Upgrades unterzogen und entwickelte sich schrittweise von der klassischen ELK-Architektur zu einem selbst entwickelten System, das auf Datenseen basiert. In diesem Artikel werden die aufgetretenen Probleme vorgestellt während der Transformation der Venus-Architektur und -Lösungen.
03
Venus 1.0: Basierend auf ELK-Architektur
Venus 1.0 startete im Jahr 2015 und wurde auf Basis des damals beliebten ElasticSearch+Kibana erstellt, wie in Abbildung 2 dargestellt. ElasticSearch ist für die Speicher- und Analysefunktionen von Protokollen verantwortlich, und Kibana bietet visuelle Abfrage- und Analysefunktionen. Sie müssen nur Kafka nutzen und Protokolle in ElasticSearch schreiben, um Protokolldienste bereitzustellen.
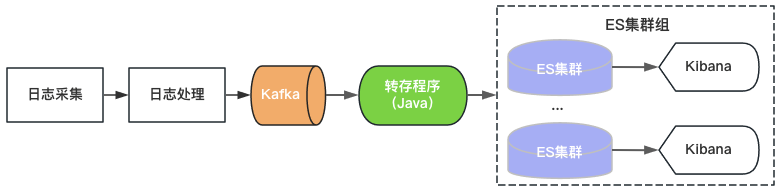 Abbildung 2 Venus 1.0-Architektur
Abbildung 2 Venus 1.0-Architektur
Da es Obergrenzen für den Durchsatz, die Speicherkapazität und die Anzahl der Index-Shards eines einzelnen ElasticSearch-Clusters gibt, fügt Venus weiterhin neue ElasticSearch-Cluster hinzu, um der wachsenden Protokollnachfrage gerecht zu werden. Um die Kosten zu kontrollieren, ist die Auslastung jedes ElasticSearch hoch und der Index ist mit 0 Kopien konfiguriert. Es treten häufig Probleme wie plötzliches Schreiben von Datenverkehr, große Datenabfragen oder Maschinenausfälle auf, die zur Nichtverfügbarkeit des Clusters führen. Gleichzeitig sind die Protokolle aufgrund der großen Anzahl von Indizes im Cluster, der großen Datenmenge und der langen Wiederherstellungszeit für lange Zeit nicht verfügbar und das Venus-Nutzungserlebnis wird immer schlechter.
04
Venus 2.0: Basierend auf ElasticSearch + Hive
Clusterklassifizierung: ElasticSearch-Cluster werden in zwei Kategorien unterteilt: hohe Qualität und niedrige Qualität. Wichtige Unternehmen verwenden hochwertige Cluster, die Last des Clusters wird auf einem niedrigen Niveau gesteuert und der Index ist mit einer 1-Kopie-Konfiguration aktiviert, um den Ausfall eines einzelnen Knotens zu tolerieren wird auf hoher Ebene gesteuert und der Index verwendet weiterhin eine 0-Kopie-Konfiguration.
Speicherklassifizierung: Doppeltes Schreiben von ElasticSearch und Hive für Protokolle mit langer Speicherung. ElasticSearch speichert die Protokolle der letzten 7 Tage und Hive speichert Protokolle über einen längeren Zeitraum, was den Speicherdruck von ElasticSearch verringert und auch das Risiko verringert, dass ElasticSearch durch große Datenabfragen hängen bleibt. Da Hive jedoch keine interaktiven Abfragen durchführen kann, müssen die Protokolle in Hive über eine Offline-Computerplattform abgefragt werden, was zu einer schlechten Abfrageerfahrung führt.
Einheitliches Abfrageportal: Bietet ein einheitliches visuelles Abfrage- und Analyseportal ähnlich wie Kibana und schützt den zugrunde liegenden ElasticSearch-Cluster. Wenn ein Cluster ausfällt, werden neu geschriebene Protokolle für andere Cluster geplant, ohne dass dies Auswirkungen auf die Abfrage und Analyse neuer Protokolle hat. Planen Sie den Datenverkehr zwischen Clustern transparent, wenn die Clusterlast unausgeglichen ist.
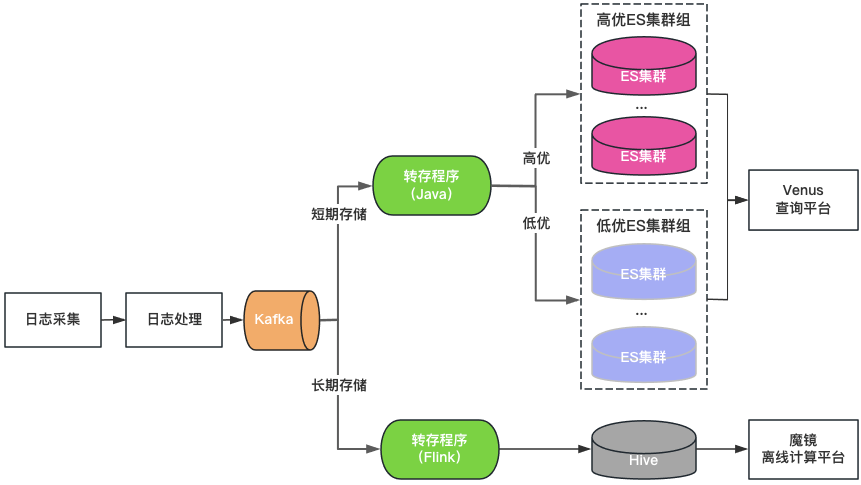
Abbildung 3 Venus 2.0-Architektur
Venus 2.0 ist eine Kompromisslösung zum Schutz wichtiger Unternehmen und zur Reduzierung des Risikos und der Auswirkungen von Ausfällen. Sie weist jedoch immer noch die Probleme hoher Kosten und schlechter Stabilität auf:
ElasticSearch hat eine kurze Speicherzeit: Aufgrund der großen Menge an Protokollen kann ElasticSearch nur 7 Tage speichern, was den täglichen Geschäftsanforderungen nicht gerecht wird.
Es gibt viele Eingänge und Datenfragmentierung: mehr als 20 ElasticSearch-Cluster + 1 Hive-Cluster, es gibt viele Abfrageeingänge, was für Abfrage und Verwaltung sehr unpraktisch ist.
Hohe Kosten: Obwohl ElasticSearch Protokolle nur 7 Tage lang speichert, verbraucht es immer noch mehr als 500 Maschinen.
Integriertes Lesen und Schreiben: Der ElasticSearch-Server ist für das gleichzeitige Lesen und Schreiben verantwortlich und beeinflusst sich gegenseitig.
Viele Fehler: ElasticSearch-Fehler machen 80 % der gesamten Fehler bei Venus aus. Nach Fehlern werden Lese- und Schreibvorgänge blockiert, Protokolle gehen leicht verloren und die Verarbeitung ist schwierig.
05
Venus 3.0: Neue Architektur basierend auf Data Lake
Denken Sie über die Einführung eines Data Lake nach
Nach einer eingehenden Analyse des Protokollszenarios der Venus fassen wir seine Eigenschaften wie folgt zusammen:
Große Datenmenge : fast 10.000 Geschäftsprotokollströme mit einer Spitzenschreibkapazität von 10 Millionen QPS und Datenspeicherung auf PB-Ebene.
Mehr schreiben und weniger prüfen : Unternehmen fragen Protokolle normalerweise nur dann ab, wenn eine Fehlerbehebung erforderlich ist. Bei den meisten Protokollen sind innerhalb eines Tages keine Abfragen erforderlich, und die Abfrage-QPS ist insgesamt äußerst niedrig.
Interaktive Abfrage : Protokolle werden hauptsächlich zur Fehlerbehebung in dringenden Szenarien verwendet, die mehrere aufeinanderfolgende Abfragen erfordern und eine interaktive Abfrageerfahrung der zweiten Ebene erfordern.
Bezüglich der Probleme, die bei der Verwendung von ElasticSearch zum Speichern und Analysieren von Protokollen auftreten, glauben wir, dass es aus folgenden Gründen nicht ganz mit dem Venus-Protokollszenario übereinstimmt:
Ein einzelner Cluster hat begrenzte Schreib-QPS und Speicherskalierung, daher müssen sich mehrere Cluster den Datenverkehr teilen. Komplexe Planungsstrategieprobleme wie Clustergröße, Schreibverkehr, Speicherplatz und Anzahl der Indizes müssen berücksichtigt werden, was die Verwaltung schwieriger macht. Da der Geschäftsprotokollverkehr stark schwankt und unvorhersehbar ist, ist es häufig erforderlich, mehr ungenutzte Ressourcen zu reservieren, um die Auswirkungen plötzlichen Datenverkehrs auf die Clusterstabilität zu beheben, was zu einer enormen Verschwendung von Clusterressourcen führt.
Die Volltextindizierung während des Schreibens verbraucht viel CPU, was zu einer Datenerweiterung und einem erheblichen Anstieg der Rechen- und Speicherkosten führt. In vielen Szenarien erfordert das Speichern von Analyseprotokollen mehr Ressourcen als Hintergrunddienstressourcen. Für Szenarios wie Protokolle, in denen es viele Schreibvorgänge und wenige Abfragen gibt, ist die Vorberechnung des Volltextindex aufwändiger.
Speicherdaten und Berechnungen erfolgen auf demselben Computer. Abfragen großer Datenmengen oder aggregierte Analysen können sich leicht auf das Schreiben auswirken und zu Schreibverzögerungen oder sogar Clusterfehlern führen.
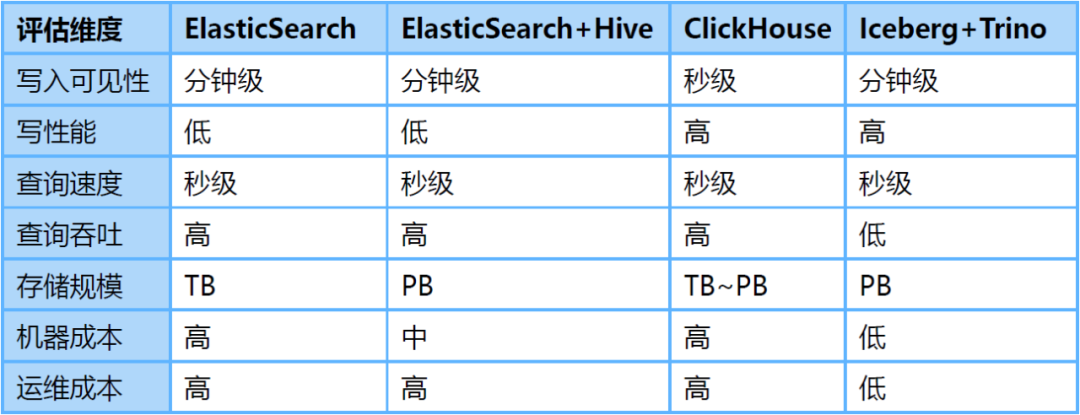
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
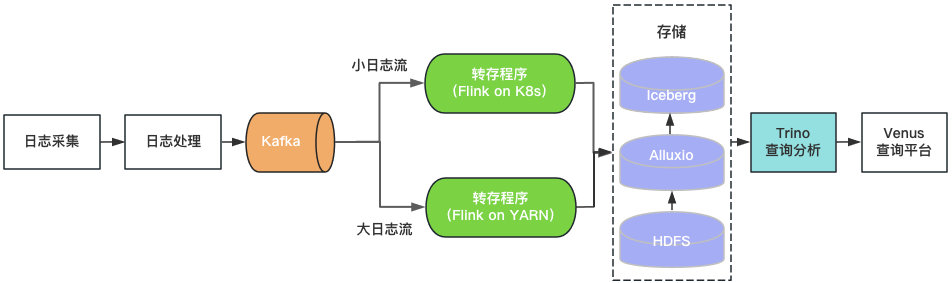 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
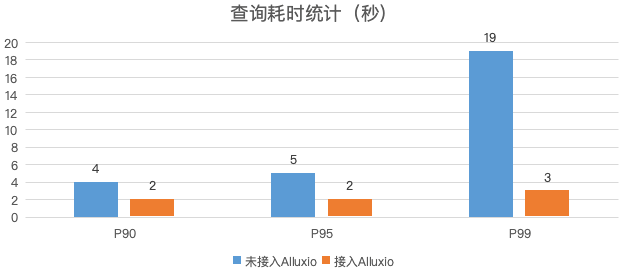
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。