Data Lake, wie wir ihn sehen
Als Rechenzentrumsteam von iQiyi besteht unsere Kernaufgabe darin, die große Anzahl an Datenbeständen innerhalb des Unternehmens zu verwalten und zu warten. Im Zuge der Implementierung von Data Governance integrieren wir weiterhin neue Konzepte und führen modernste Tools ein, um unser Datensystemmanagement zu verfeinern.
„Data Lake“ ist ein Konzept, das in den letzten Jahren im Datenbereich viel diskutiert wurde und dessen technische Aspekte auch in der Industrie große Aufmerksamkeit erregt haben. Unser Team hat sich intensiv mit Theorie und Praxis von Data Lakes befasst. Wir glauben, dass Data Lakes nicht nur eine neue Perspektive auf das Datenmanagement, sondern auch eine vielversprechende Technologie zur Integration und Verarbeitung von Daten darstellen.
Data Lake ist eine Idee der Datenverwaltung
Der Zweck der Implementierung eines Data Lake besteht darin, eine effiziente Speicher- und Verwaltungslösung bereitzustellen, um die Benutzerfreundlichkeit und Verfügbarkeit von Daten auf ein neues Niveau zu heben.
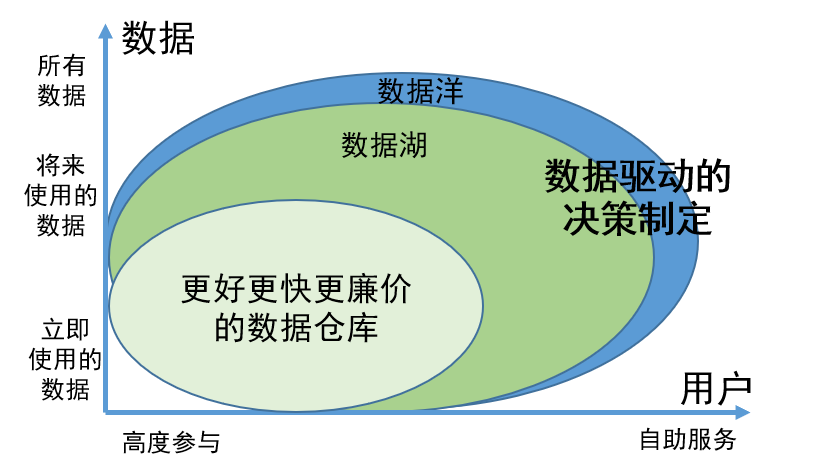
Als innovatives Data-Governance-Konzept spiegelt sich der Wert von Data Lake vor allem in den folgenden zwei Aspekten wider:
1. Die Möglichkeit, alle Daten umfassend zu speichern, unabhängig davon, ob die Daten verwendet werden oder vorübergehend nicht verfügbar sind, stellt sicher, dass die erforderlichen Informationen bei Bedarf leicht gefunden werden können, und verbessert die Arbeitseffizienz.
2. Die Daten im Data Lake wurden wissenschaftlich verwaltet und organisiert, sodass Benutzer die Daten leichter selbst finden und nutzen können. Dieses Verwaltungsmodell reduziert den Einsatz von Dateningenieuren erheblich. Benutzer können die Aufgaben der Datensuche und -nutzung selbst erledigen, wodurch eine Menge Personalressourcen eingespart werden.
Um alle Arten von Daten effektiver verwalten zu können, unterteilt der Data Lake die Daten anhand unterschiedlicher Merkmale und Bedürfnisse in vier Kernbereiche, nämlich Originalbereich, Produktbereich, Arbeitsbereich und sensibler Bereich:
Rohbereich
: Dieser Bereich konzentriert sich auf die Bedürfnisse von Dateningenieuren und professionellen Datenwissenschaftlern und dient hauptsächlich der Speicherung roher, unverarbeiteter Daten. Bei Bedarf kann es auch teilweise geöffnet werden, um bestimmte Zugangsanforderungen zu erfüllen.
Produktbereich
: Die meisten Daten im Produktbereich werden von Dateningenieuren, Datenwissenschaftlern und Geschäftsanalysten verarbeitet und verarbeitet, um die Standardisierung und ein hohes Maß an Datenmanagement sicherzustellen. Diese Art von Daten wird normalerweise häufig in der Geschäftsberichterstattung, Datenanalyse, maschinellem Lernen und anderen Bereichen verwendet.
Arbeitsbereich
: Der Arbeitsbereich wird hauptsächlich zum Speichern von Zwischendaten verwendet, die von verschiedenen Datenarbeitern generiert wurden. Hier sind Benutzer für die Verwaltung ihrer Daten verantwortlich, um eine flexible Datenexploration und -experimentierung zu unterstützen und den Anforderungen verschiedener Benutzergruppen gerecht zu werden.
Sensibler Bereich
: Der sensible Bereich konzentriert sich auf die Sicherheit und wird hauptsächlich zum Speichern sensibler Daten wie personenbezogener Daten, Finanzdaten und Daten zur Einhaltung gesetzlicher Vorschriften verwendet. Dieser Bereich ist durch ein Höchstmaß an Zugangskontrolle und Sicherheit geschützt.
Durch diese Aufteilung kann der Data Lake verschiedene Datentypen besser verwalten und gleichzeitig einen bequemen Datenzugriff und eine bequeme Datennutzung ermöglichen, um verschiedene Anforderungen zu erfüllen.
Anwendung von Data Lake Data Governance-Ideen im Rechenzentrum
Das Ziel des Rechenzentrums besteht darin, Probleme wie inkonsistente statistische Kaliber, wiederholte Entwicklung, langsame Reaktion auf Indikatorenentwicklungsanforderungen, geringe Datenqualität und hohe Datenkosten zu lösen, die durch Datenanstieg und Geschäftsausweitung verursacht werden.
Die Ziele des Rechenzentrums und des Data Lake sind konsistent. Durch die Kombination des Data Lake-Konzepts wurden das Datensystem und die Gesamtarchitektur des Rechenzentrums optimiert und aktualisiert.
In der Anfangsphase des Aufbaus des Rechenzentrums haben wir das Data-Warehouse-System des Unternehmens integriert, eine eingehende Untersuchung des Geschäfts durchgeführt, die vorhandenen Feld- und Dimensionsinformationen sortiert, die Konsistenzdimensionen zusammengefasst, ein einheitliches Indikatorensystem eingerichtet und den Data-Warehouse-Aufbau formuliert Spezifikationen. Gemäß dieser Spezifikation haben wir die ursprüngliche Datenschicht (ODS), die detaillierte Datenschicht (DWD) und die aggregierte Datenschicht (MID) des einheitlichen Data Warehouse erstellt und eine Gerätebibliothek eingerichtet, einschließlich einer akkumulierten Gerätebibliothek und eines neuen Geräts Bibliothek. Auf der Grundlage des einheitlichen Data Warehouse erstellte das Datenteam ein thematisches Data Warehouse und einen Geschäftsmarkt, das auf verschiedenen Analyse- und Statistikrichtungen und Geschäftsanforderungen basiert. Das betreffende Data Warehouse und der Geschäftsmarkt umfassen weiterverarbeitete detaillierte Daten, aggregierte Daten und Datentabellen der Anwendungsschicht. Die Datenanwendungsschicht verwendet diese Daten, um Benutzern verschiedene Dienste bereitzustellen.
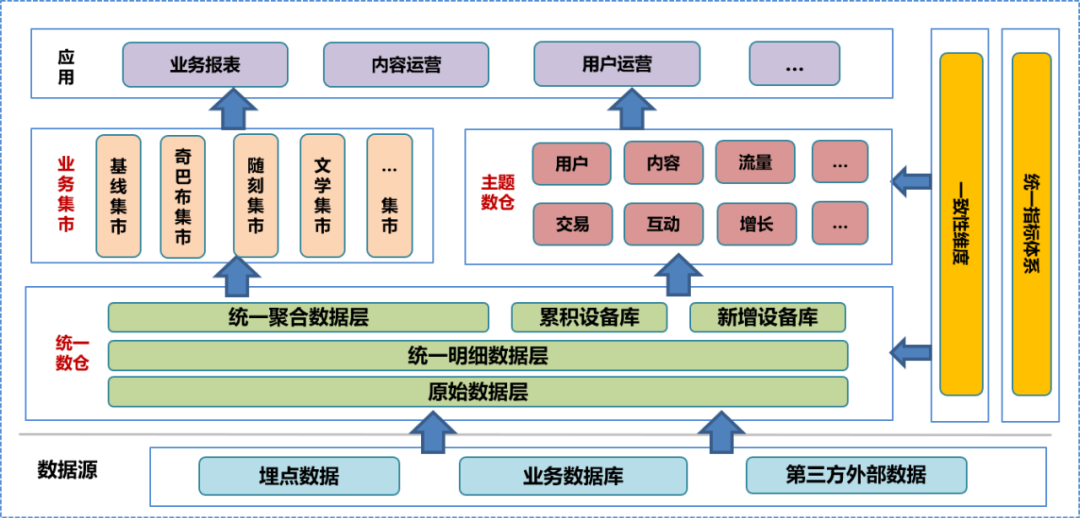
In einem einheitlichen Data Warehouse-System sind die ursprüngliche Datenschicht und
die darunter liegende
Ebene nicht für die Öffentlichkeit zugänglich. Benutzer können nur Dateningenieure zur Verarbeitung verarbeiteter Daten verwenden, sodass es unvermeidlich ist, dass einige Datendetails verloren gehen.
Bei der täglichen Arbeit möchten Benutzer mit Datenanalysefunktionen häufig auf die zugrunde liegenden Rohdaten zugreifen, um personalisierte Analysen oder Fehlerbehebungen durchzuführen.
Das Datenverwaltungskonzept von Data Lake kann dieses Problem effektiv lösen. Nach der Einführung der Data-Governance-Idee des Data Lake haben wir die vorhandenen Datenressourcen sortiert und integriert, die Datenmetadaten angereichert und erweitert und ein Datenmetadatenzentrum speziell für die Verwaltung von Metadaten aufgebaut.
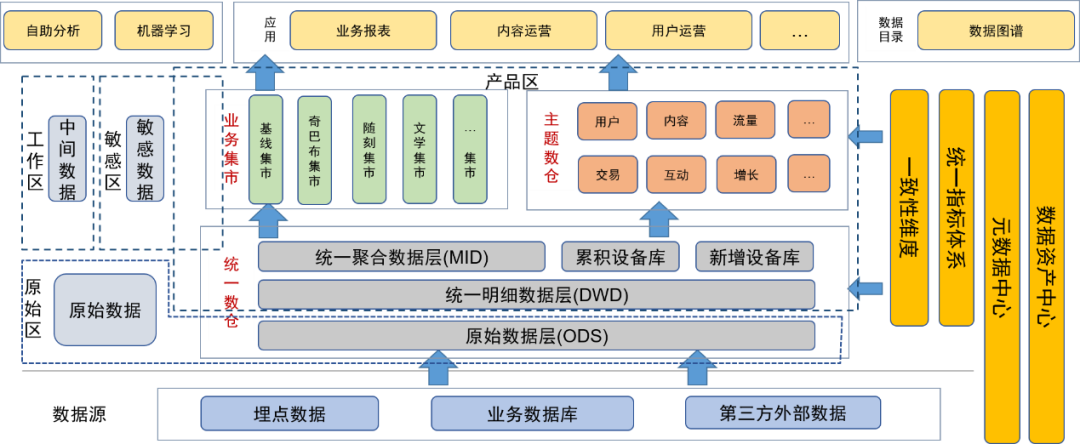
Nach der Einführung des Data-Lake-Konzepts für die Datenverwaltung haben wir die ursprüngliche Datenschicht und andere Originaldaten (z. B. Originalprotokolldateien) im Originaldatenbereich platziert. Benutzer mit Datenverarbeitungsfunktionen können die Erlaubnis zur Verwendung der Daten in diesem Bereich beantragen.
Die Detailschicht, die Aggregationsschicht, das Theme Data Warehouse und der Business Mart des Unified Data Warehouse werden von den Dateningenieuren des Datenteams verarbeitet und den Benutzern als endgültige Datenprodukte bereitgestellt In diesem Bereich wurde die Datenverwaltung verarbeitet, sodass die Datenqualität gewährleistet ist.
Darüber hinaus haben wir sensible Bereiche für sensible Daten definiert und uns auf die Kontrolle der Zugriffsrechte konzentriert.
Temporäre Tabellen oder persönliche Tabellen, die täglich von Benutzern und Datenentwicklern erstellt werden, werden im temporären Bereich abgelegt. Diese Datentabellen liegen in der Verantwortung der Benutzer selbst und können unter bestimmten Bedingungen für andere Benutzer geöffnet werden.
Die Metadaten aller Daten werden über das Metadatenzentrum verwaltet, einschließlich Tabelleninformationen, Feldinformationen sowie den den Feldern entsprechenden Dimensionen und Indikatoren. Gleichzeitig pflegen wir auch die Datenherkunft, einschließlich Herkunftsbeziehungen auf Tabellen- und Feldebene.
Pflegen Sie die Asset-Merkmale der Daten über das Data Asset Center, einschließlich der Verwaltung von Datenebene, Sensibilität und Berechtigungen.
Um Benutzern die bessere Nutzung von Daten selbst zu erleichtern, stellen wir eine Datenkarte als Datenverzeichnis auf Anwendungsebene bereit, damit Benutzer Daten abfragen können, einschließlich Metadaten wie Datennutzung, Dimensionen, Indikatoren und Herkunft. Gleichzeitig kann die Plattform auch als Portal für Genehmigungsanträge genutzt werden.
Darüber hinaus bieten wir auch eine Self-Service-Analyseplattform an, um Datennutzern Self-Service-Analysefunktionen bereitzustellen.
Während wir das Datensystem optimierten, haben wir auch die Architektur der Data-Middle-Plattform auf Basis des Data-Lake-Konzepts aktualisiert.
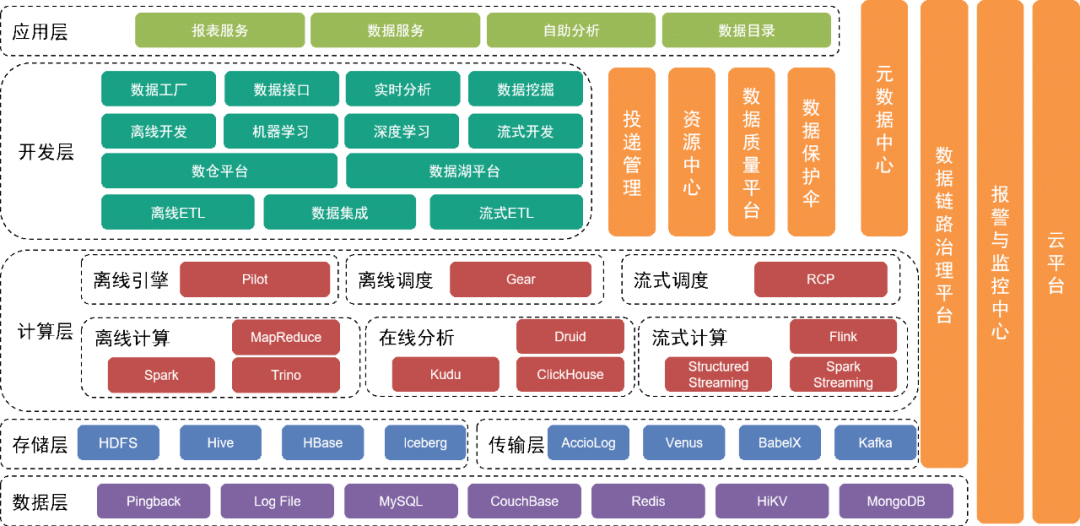
Die unterste Schicht ist die Datenschicht , die verschiedene Datenquellen umfasst, wie z. B. Pingback-Daten, die hauptsächlich zur Erfassung des Benutzerverhaltens verwendet werden und in verschiedenen relationalen Datenbanken und NoSQL-Datenbanken gespeichert werden.
Diese Daten werden in der Speicherschicht über verschiedene Erfassungstools in der Transportschicht gespeichert.
Oberhalb der Datenschicht befindet sich die Speicherschicht
, die hauptsächlich auf HDFS, einem verteilten Dateisystem, zum Speichern von Originaldateien basiert. Andere strukturierte oder unstrukturierte Daten werden in Hive, Iceberg oder HBase gespeichert.
Weiter oben befindet sich die Rechenschicht
, die hauptsächlich die Offline-Engine Pilot verwendet, um Spark oder Trino für Offline-Berechnungen anzutreiben, und die Planungs-Engine Gear, die Offline-Workflow-Engine für die geplante Workflow-Planung verwendet. Die RCP-Echtzeit-Computing-Plattform ist für die Planung des Stream-Computing verantwortlich. Nach mehreren Iterationsrunden nutzt Flow Computing derzeit hauptsächlich Flink als Rechenmaschine.
Die Entwicklungsschicht über der Computerschicht
kapselt außerdem jedes Servicemodul der Computerschicht und der Übertragungsschicht, um Funktionen für die Entwicklung von Offline-Datenverarbeitungs-Workflows, die Integration von Daten, die Entwicklung von Echtzeit-Verarbeitungs-Workflows und die Entwicklung von Engineering-Tool-Suiten und -Zwischenprodukten für maschinelles Lernen bereitzustellen Dienstleistungen bis hin zur kompletten Entwicklungsarbeit. Die Data-Lake-Plattform verwaltet die Informationen jeder Datendatei und Datentabelle im Data Lake, während die Data-Warehouse-Plattform das Data-Warehouse-Datenmodell, das physische Modell, Dimensionen, Indikatoren und andere Informationen verwaltet.
Gleichzeitig bieten wir eine Vielzahl vertikaler Verwaltungstools und -dienste an. Beispielsweise verwaltet das Lieferverwaltungstool Metainformationen wie vergrabene Pingback-Spezifikationen, Felder, Wörterbücher und Lieferfristen werden verwendet, um Datentabellen oder Datendateien zu verwalten und die Datensicherheit zu gewährleisten; basierend auf bestehenden Plänen.
Die zugrunde liegenden Dienste werden vom Cloud-Service-Team bereitgestellt, um Unterstützung für private Clouds und öffentliche Clouds bereitzustellen.
Die obere Schicht der Architektur stellt eine Datenkarte als Datenverzeichnis bereit, damit Benutzer die benötigten Daten finden können. Darüber hinaus bieten wir Self-Service-Anwendungen wie Magic Mirror und Beidou an, um den Anforderungen von Benutzern auf verschiedenen Ebenen an Self-Service-Datenarbeit gerecht zu werden.
Nach der Transformation des gesamten Architektursystems sind Datenintegration und -verwaltung flexibler und umfassender. Wir reduzieren die Benutzerschwelle durch die Optimierung von Self-Service-Tools, erfüllen die Bedürfnisse der Benutzer auf verschiedenen Ebenen, verbessern die Effizienz der Datennutzung und erhöhen den Datenwert.
Anwendung der Data-Lake-Technologie im Rechenzentrum
Im weitesten Sinne ist Data Lake ein Konzept der Datenverwaltung. Im engeren Sinne bezeichnet Data Lake auch eine Datenverarbeitungstechnologie.
Die Data-Lake-Technologie umfasst das Speicherformat von Datentabellen und die Verarbeitungstechnologie von Daten nach dem Eintritt in den Lake.
Es gibt drei Hauptspeicherlösungen in Datenseen in der Branche: Delta Lake, Hudi und Iceberg. Ein Vergleich der drei ist wie folgt:
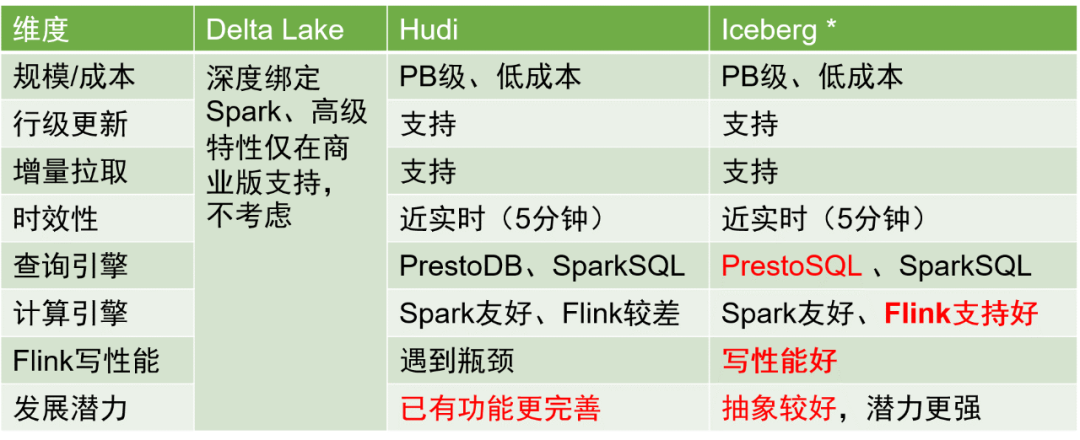
Nach umfassender Überlegung haben wir uns für Iceberg als Speicherformat der Datentabelle entschieden.
Iceberg ist ein Tabellenspeicherformat, das Datendateien im zugrunde liegenden Dateisystem oder Objektspeicher organisiert.
Hier sind die wichtigsten Vergleiche zwischen Iceberg und Hive:
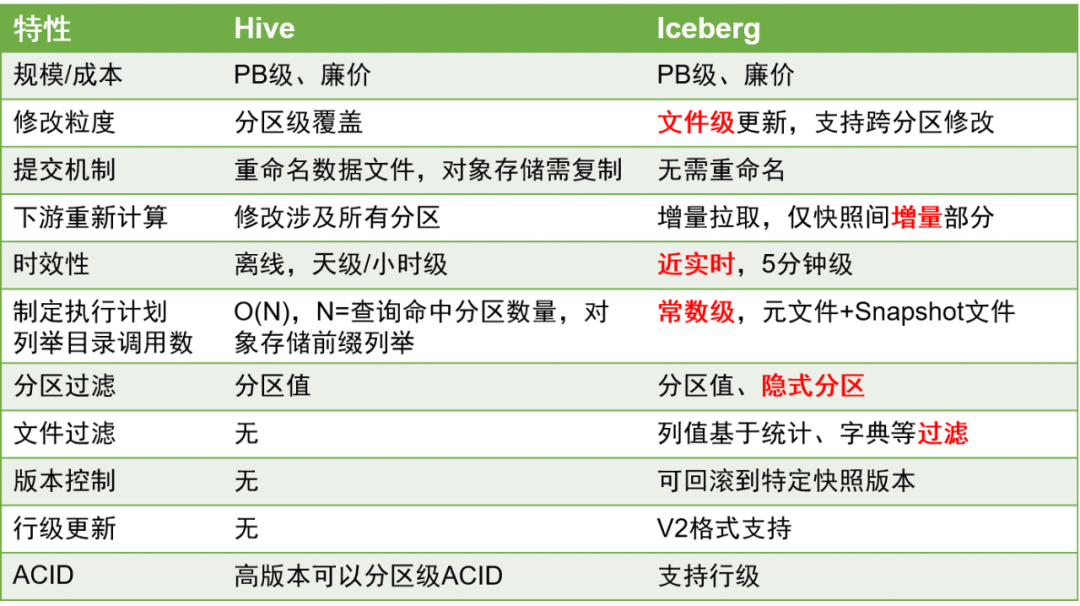
Im Vergleich zu Hive-Tabellen haben Iceberg-Tabellen erhebliche Vorteile, da sie Aktualisierungen auf Zeilenebene besser unterstützen können und die Aktualität der Daten auf Minutenebene verbessert werden kann.
Dies ist bei der Datenverarbeitung von großer Bedeutung, da die Verbesserung der Datenaktualität die Effizienz der ETL-Datenverarbeitung erheblich verbessern kann.
Daher können wir die vorhandene Lambda-Architektur problemlos umwandeln, um eine integrierte Streaming-Batch-Architektur zu erreichen:
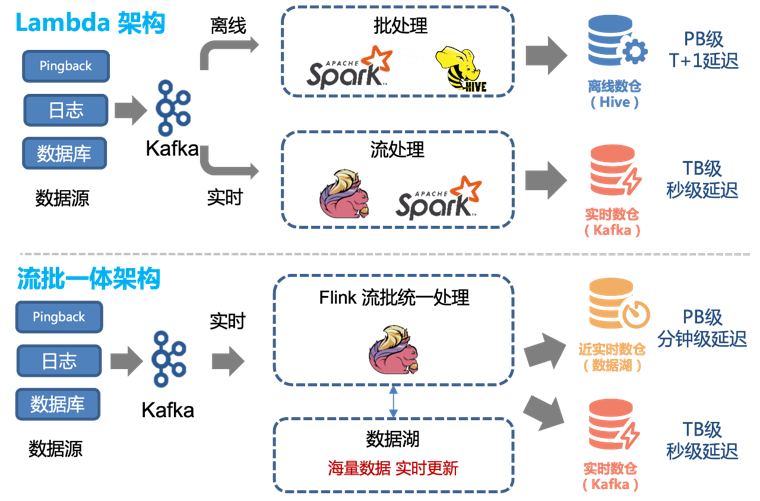
Vor der Einführung der Data-Lake-Technologie verwendeten wir eine Kombination aus Offline-Verarbeitung und Echtzeit-Verarbeitung, um Offline-Data-Warehouse und Echtzeit-Data-Warehouse bereitzustellen.
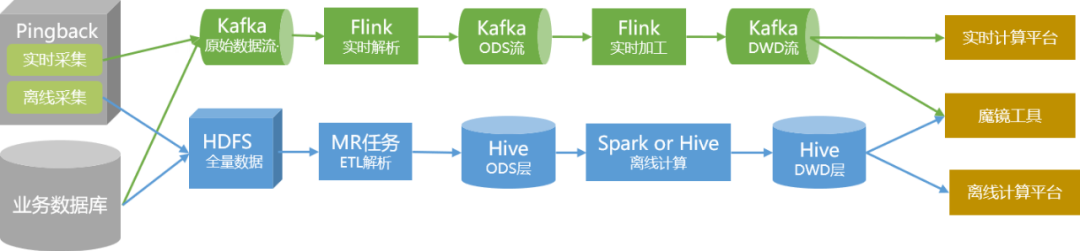
Die gesamte Datenmenge wird durch herkömmliche Offline-Analyse- und Verarbeitungsmethoden
in Data- Warehouse- Daten umgewandelt
und im Cluster in Form von Hive-Tabellen gespeichert.
Für Daten mit hohen Echtzeitanforderungen produzieren wir diese separat über Echtzeitverknüpfungen und stellen sie den Benutzern in Form von Topics in Kafka zur Verfügung.
Diese Architektur weist jedoch die folgenden Probleme auf:
-
Die beiden Kanäle, Echtzeit und Offline, müssen zwei unterschiedliche Codelogiksätze verwalten. Wenn sich die Verarbeitungslogik ändert, müssen sowohl der Echtzeit- als auch der Offline-Kanal gleichzeitig aktualisiert werden, da es sonst zu Dateninkonsistenzen kommt.
-
Stündliche Aktualisierungen von Offline-Links und eine Verzögerung von etwa einer Stunde führen dazu, dass Daten von 00:01 Uhr möglicherweise erst um 02:00 Uhr abgefragt werden. Für einige Downstream-Dienste mit hohen Echtzeitanforderungen ist dies nicht akzeptabel, daher müssen Echtzeitverbindungen unterstützt werden.
-
Obwohl die Echtzeitleistung der Echtzeitverbindung die zweite Ebene erreichen kann, sind die Kosten hoch. Für die meisten Benutzer reicht ein fünfminütiges Update aus. Gleichzeitig ist die Nutzung von Kafka-Streams nicht so bequem wie die direkte Bedienung von Datentabellen.
Diese Probleme können besser gelöst werden, indem die integrierte Datenverarbeitungsmethode von Iceberg-Tabellen und Streaming-Batches verwendet wird.

Während des Optimierungsprozesses führten wir hauptsächlich eine Iceberg-Transformation für die ODS-Schicht- und DWD-Schichttabellen durch und rekonstruierten die Analyse und Datenverarbeitung in Flink-Aufgaben.
Um sicherzustellen, dass die Stabilität und Genauigkeit der Datenproduktion während des Transformationsprozesses nicht beeinträchtigt wird, haben wir folgende Maßnahmen ergriffen:
1. Beginnen Sie mit dem Wechsel mit Nicht-Kerndaten. Basierend auf den tatsächlichen Geschäftsbedingungen nutzen wir QOS-Lieferung und kundenspezifische Lieferung als Pilotprojekte.
2. Durch die Abstraktion der Offline-Parsing-Logik wird ein einheitliches Pingback-Parsing-Speicher-SDK gebildet, das eine einheitliche Echtzeit- und Offline-Bereitstellung realisiert und den Code standardisierter macht.
3. Nachdem der Iceberg-Tisch und der neue Produktionsprozess implementiert waren, führten wir zwei Monate lang parallele Dual-Link-Vorgänge durch und führten eine regelmäßige vergleichende Überwachung der Daten durch.
4. Nachdem wir bestätigt haben, dass es keine Probleme mit Daten und Produktion gibt, führen wir einen unmerklichen Wechsel zur oberen Ebene durch.
5. Für die Start- und Wiedergabedaten im Zusammenhang mit Kerndaten führen wir die integrierte Streaming- und Batch-Transformation durch, nachdem die Gesamtüberprüfung stabil ist.
Nach der Transformation ergeben sich folgende Vorteile:
1. Die QOS- und benutzerdefinierten Lieferdatenverknüpfungen wurden insgesamt nahezu in Echtzeit implementiert. Daten mit einer stündlichen Verzögerung können auf der Fünf-Minuten-Ebene aktualisiert werden.
2. Mit Ausnahme besonderer Umstände kann die integrierte Streaming- und Batch-Verbindung Echtzeitanforderungen erfüllen. Daher können wir die vorhandenen Echtzeit-Links und Offline-Analyse-Links im Zusammenhang mit QOS und Anpassung offline schalten und so Ressourcen sparen.
Durch die Transformation der Datenverarbeitung wird unsere Datenverbindung in Zukunft wie in der folgenden Abbildung dargestellt aussehen:
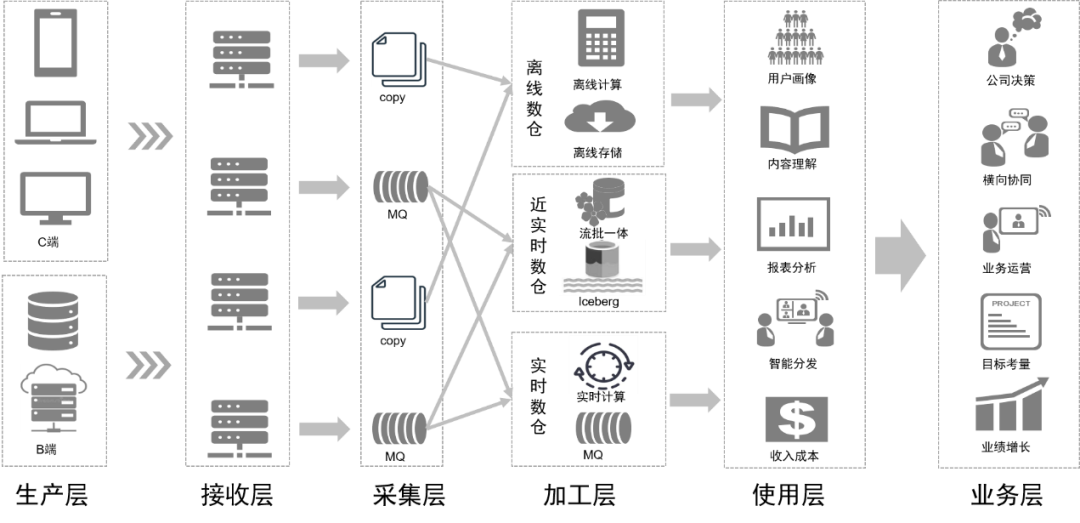
Folgeplanung
Für die spätere Planung der Data-Lake-Anwendung im Rechenzentrum gibt es zwei Hauptaspekte:
Auf architektonischer Ebene werden wir die Entwicklung jedes Moduls weiter verfeinern, um die vom Rechenzentrum bereitgestellten Daten und Dienste umfassender und benutzerfreundlicher zu machen, sodass verschiedene Benutzer sie bequem nutzen können.
Auf technischer Ebene werden wir die Datenverbindung weiterhin in eine Stream-Batch-Integration umwandeln und gleichzeitig weiterhin aktiv geeignete Datentechnologien einführen, um die Effizienz der Datenproduktion und -nutzung zu verbessern und die Produktionskosten zu senken.
6. Alex Gorelik. Der Enterprise Big Data Lake.
Vielleicht möchten Sie es auch sehen
Dieser Artikel wurde vom öffentlichen WeChat-Konto geteilt – iQIYI Technology Product Team (iQIYI-TP).
Bei Verstößen wenden Sie sich bitte zur Löschung an [email protected].
Dieser Artikel ist Teil des „ OSC Source Creation Plan “. Alle, die ihn lesen, sind herzlich eingeladen, mitzumachen und ihn gemeinsam zu teilen.
