Volcano Engine Edge Cloud ist ein Cloud-Computing-Dienst, der auf Cloud-Computing-Basistechnologie und heterogener Edge-Rechenleistung in Kombination mit einem Netzwerk basiert, das auf einer groß angelegten Edge-Infrastruktur aufgebaut ist und ein Edge-basiertes Computing, Netzwerk, Speicher, Sicherheit und Intelligenz bildet. Eine neue Generation von verteilte Cloud-Computing-Lösungen mit Kernfunktionen.
01- Herausforderungen beim Speichern von Edge-Szenen
Edge-Storage ist hauptsächlich für typische Geschäftsszenarien gedacht, die sich an Edge-Computing anpassen, wie z. B. Edge-Rendering. Das Edge-Rendering der Vulkan-Engine stützt sich auf die zugrunde liegenden massiven Rechenleistungsressourcen, die Benutzern helfen können, die einfache Anordnung von Millionen von Rendering-Frame-Warteschlangen, die Planung von Rendering-Aufgaben in der Nähe und das parallele Rendering von Multitasking und Multi-Node zu realisieren , was das Rendern erheblich verbessert. Stellen Sie kurz die Speicherfrage vor, die beim Edge-Rendering angetroffen wird:
- Es ist notwendig, die Metadaten des Objektspeichers und des Dateisystems zu vereinheitlichen, damit die Daten nach dem Hochladen über die Objektspeicherschnittstelle direkt über die POSIX-Schnittstelle bedient werden können;
- Erfüllen Sie die Anforderungen von Szenarien mit hohem Durchsatz, insbesondere beim Lesen;
- Implementiert die S3-Schnittstelle und die POSIX-Schnittstelle vollständig.
Um die beim Edge-Rendering auftretenden Speicherprobleme zu lösen, verbrachte das Team fast ein halbes Jahr damit, Tests zur Speicherauswahl durchzuführen. Zunächst entschied sich das Team für die internen Speicherkomponenten des Unternehmens, die unsere Anforderungen in Bezug auf Nachhaltigkeit und Leistung besser erfüllen können. Aber wenn es um Randszenen geht, gibt es zwei spezifische Probleme:
- Erstens sind die internen Komponenten des Unternehmens für den zentralen Computerraum ausgelegt, und es gibt Anforderungen an physische Maschinenressourcen und -menge, die in einigen peripheren Computerräumen schwer zu erfüllen sind;
- Zweitens werden die Speicherkomponenten des gesamten Unternehmens zusammengepackt, einschließlich: Objektspeicher, Blockspeicher, verteilter Speicher, Dateispeicher usw., während die Edge-Seite hauptsächlich Dateispeicher und Objektspeicher benötigt, die angepasst und transformiert werden müssen. und ein Online-Stall erfordert auch einen Prozess.
Nachdem das Team diskutiert hatte, wurde eine praktikable Lösung entwickelt: CephFS + MinIO-Gateway . MinIO stellt einen Objektspeicherdienst bereit, das Endergebnis wird in CephFS geschrieben, und die Rendering-Engine stellt CephFS bereit, um Rendering-Vorgänge durchzuführen. Während des Test- und Verifizierungsprozesses, als die Anzahl der Dateien mehrere zehn Millionen erreichte, begann die Leistung von CephFS nachzulassen, gelegentlich einzufrieren, und das Feedback von der Geschäftsseite entsprach nicht den Anforderungen.
Ebenso gibt es eine weitere auf Ceph basierende Lösung, die Ceph RGW + S3FS verwenden soll. Diese Lösung kann die Anforderungen grundsätzlich erfüllen, aber die Leistung beim Schreiben und Ändern von Dateien entspricht nicht den Anforderungen der Szene.
Nach mehr als dreimonatiger Testphase haben wir einige Kernanforderungen für die Speicherung im Edge-Rendering geklärt:
- Der Betrieb und die Wartung sollten nicht zu kompliziert sein : Das Forschungs- und Entwicklungspersonal des Speichers kann mit den Betriebs- und Wartungsdokumenten beginnen; die Betriebs- und Wartungsarbeiten späterer Erweiterungen und die Online-Fehlerbehandlung sollten einfach genug sein.
- Datenzuverlässigkeit : Da der Speicherdienst dem Benutzer direkt bereitgestellt wird, dürfen die erfolgreich geschriebenen Daten nicht verloren gehen oder mit den geschriebenen Daten inkonsistent sein.
- Verwenden Sie eine Reihe von Metadaten und unterstützen Sie sowohl die Objektspeicherung als auch die Dateispeicherung : Auf diese Weise müssen Dateien nicht mehrmals hoch- und heruntergeladen werden, wenn die Geschäftsseite sie verwendet, wodurch die Komplexität der Verwendung durch die Geschäftsseite verringert wird.
- Bessere Leistung beim Lesen : Das Team muss das Szenario von mehr Lesen und weniger Schreiben lösen, also hoffen sie auf eine bessere Leseleistung.
- Community-Aktivität : Eine aktive Community kann bei der Lösung bestehender Probleme schneller reagieren und die Iteration neuer Funktionen aktiv vorantreiben.
Nach Klärung der Kernanforderungen stellten wir fest, dass die drei bisherigen Lösungen die Anforderungen nicht ganz erfüllten.
02- Vorteile der Verwendung von JuiceFS
Das Edge-Storage-Team von Volcano Engine erfuhr im September 2021 von JuiceFS und hatte einige Gespräche mit dem Juicedata-Team. Nach der Kommunikation entschieden wir uns, es im Edge-Cloud-Szenario zu versuchen. Die offizielle Dokumentation von JuiceFS ist sehr reichhaltig und sehr gut lesbar. Sie können mehr Details erfahren, indem Sie die Dokumentation lesen.
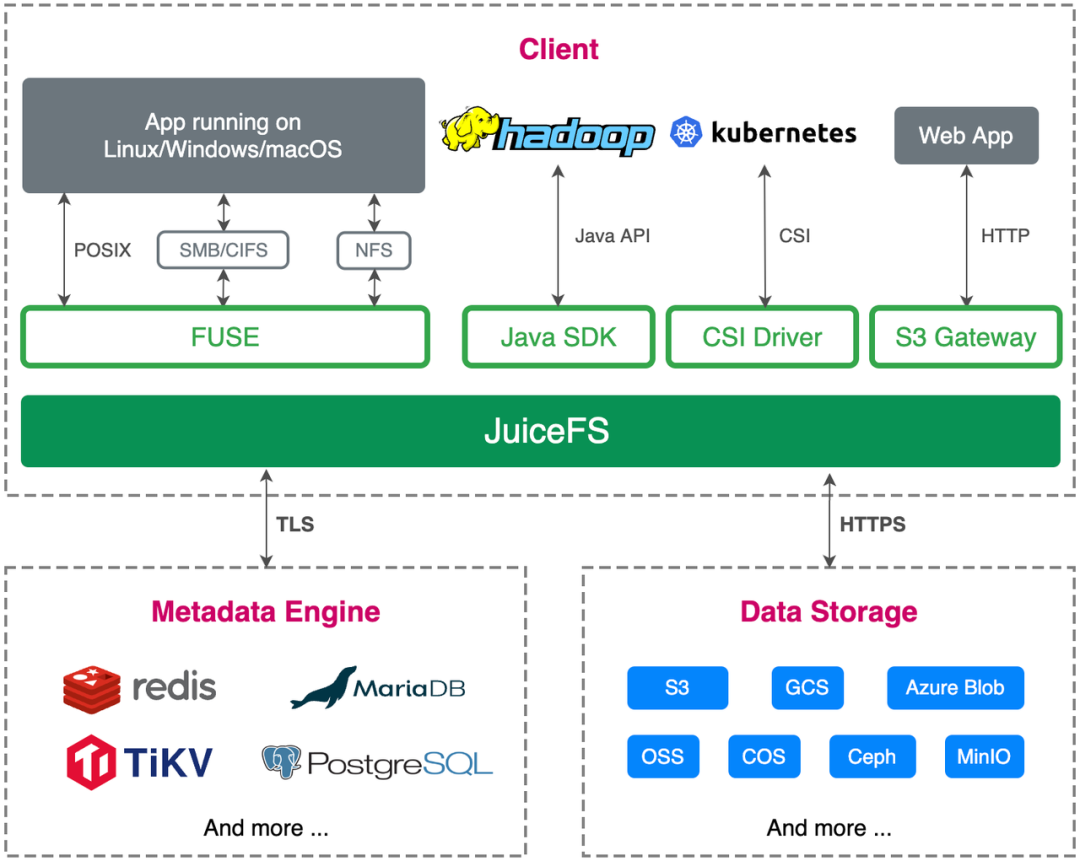
Daher haben wir begonnen, PoC-Tests in der Testumgebung durchzuführen, wobei wir uns auf die Machbarkeitsprüfung, die Komplexität von Betrieb und Wartung und Bereitstellung sowie die Anpassung an das vorgelagerte Geschäft und darauf konzentrierten, ob es die Anforderungen des vorgelagerten Geschäfts erfüllt.
Wir haben zwei Gruppen von Umgebungen bereitgestellt, eine basierend auf Einzelknoten Redis + Ceph und die andere basierend auf Einzelinstanz MySQL + Ceph .
Da Redis, MySQL und Ceph (bereitgestellt durch Rook) relativ ausgereift sind und die Referenzmaterialien zum Bereitstellen des Betriebs- und Wartungsplans relativ umfangreich sind, kann der JuiceFS-Client diese gleichzeitig auch anbinden Datenbanken und Ceph einfach und bequem Der Deployment-Prozess verläuft sehr reibungslos.
In Bezug auf die Geschäftsanpassung wird die Edge-Cloud auf der Grundlage von Cloud Native entwickelt und bereitgestellt. JuiceFS unterstützt die S3-API, ist vollständig kompatibel mit dem POSIX-Protokoll und unterstützt CSI-Mounting, was unsere Geschäftsanforderungen vollständig erfüllt.
Nach umfassenden Tests haben wir festgestellt, dass JuiceFS die Anforderungen der Geschäftsseite vollständig erfüllt und in der Produktion bereitgestellt und ausgeführt werden kann, um die Online-Anforderungen der Geschäftsseite zu erfüllen.
Vorteil 1: Geschäftsprozessoptimierung
Vor der Verwendung von JuiceFS verwendete das Edge-Rendering hauptsächlich den internen Objektspeicherdienst (TOS) von ByteDance. Benutzer luden Daten auf TOS hoch, und die Rendering-Engine lud die von Benutzern hochgeladenen Dateien von TOS auf das lokale herunter, und die Rendering-Engine las die lokalen Dateien. , to das Rendering-Ergebnis zu erzeugen und dann das Rendering-Ergebnis zurück zu TOS hochzuladen, und schließlich lädt der Benutzer das Rendering-Ergebnis von TOS herunter. Es gibt mehrere Verknüpfungen im gesamten Interaktionsprozess, und in der Mitte sind viele Netzwerk- und Datenkopien erforderlich, sodass es bei diesem Prozess zu Netzwerk-Jitter oder hohen Verzögerungen kommt, die sich auf die Benutzererfahrung auswirken.
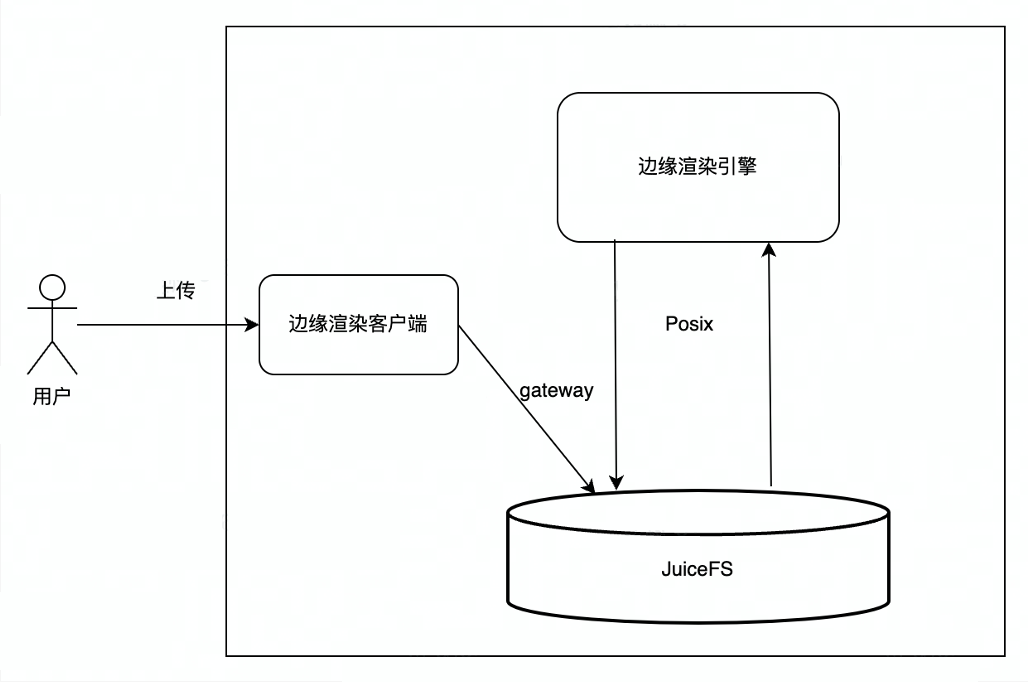
Nach der Verwendung von JuiceFS wird der Prozess so, dass der Benutzer über das JuiceFS S3-Gateway hochlädt. Da JuiceFS die Vereinheitlichung von Objektspeicher und Metadaten des Dateisystems realisiert, kann JuiceFS direkt in die Rendering-Engine eingebunden werden, und die Rendering-Engine verwendet die POSIX-Schnittstelle Dateien zu verarbeiten Lesen und schreiben, der Endbenutzer lädt das Rendering-Ergebnis direkt vom JuiceFS S3-Gateway herunter, der Gesamtprozess ist präziser, effizienter und stabiler.
Vorteil 2: Beschleunigung des Lesens von Dateien und des sequentiellen Schreibens großer Dateien
Dank des clientseitigen Caching-Mechanismus von JuiceFS können wir häufig gelesene Dateien lokal in der Rendering-Engine zwischenspeichern, was das Lesen von Dateien erheblich beschleunigt. Wir haben einen Vergleichstest durchgeführt, ob der Cache geöffnet werden soll, und festgestellt, dass der Durchsatz nach Verwendung des Caches um etwa das 3-5-fache erhöht werden kann .
Da das Schreibmodell von JuiceFS darin besteht, zuerst in den Speicher zu schreiben, werden die Daten in den Objektspeicher hochgeladen, wenn ein Chunk (Standard 64 MB) voll ist oder wenn die Anwendung die erzwungene Schreibschnittstelle (Close- und Fsync-Schnittstelle) aufruft. und der Daten-Upload erfolgreich ist Danach aktualisieren Sie die Metadaten-Engine. Schreiben Sie daher beim Schreiben großer Dateien zuerst in den Speicher und dann auf die Festplatte, was die Schreibgeschwindigkeit großer Dateien erheblich verbessern kann.
Derzeit sind die Nutzungsszenarien des Edge hauptsächlich Rendern, das Dateisystem liest mehr und schreibt weniger, und das Schreiben von Dateien betrifft auch hauptsächlich große Dateien. Die Anforderungen dieser Business-Szenarien stimmen sehr gut mit den anwendbaren Szenarien von JuiceFS überein, nachdem die Business-Seite den Speicher durch JuiceFS ersetzt hat, fällt auch die Gesamtbewertung sehr hoch aus.
03- Verwendung von JuiceFS in Edge-Szenen
JuiceFS wird hauptsächlich auf Kubernetes bereitgestellt.Jeder Knoten verfügt über einen DaemonSet-Container, der für das Mounten des JuiceFS-Dateisystems verantwortlich ist, und mountet es dann in Form von HostPath in den Pod der Rendering-Engine. Wenn der Einhängepunkt fehlschlägt, kümmert sich DaemonSet um die automatische Wiederherstellung des Einhängepunkts.
In Bezug auf die Autoritätskontrolle verwendet der Edge-Speicher den LDAP-Dienst, um die Identität der JuiceFS-Cluster-Knoten zu authentifizieren, und jeder Knoten des JuiceFS-Clusters wird vom LDAP-Client und dem LDAP-Dienst authentifiziert.
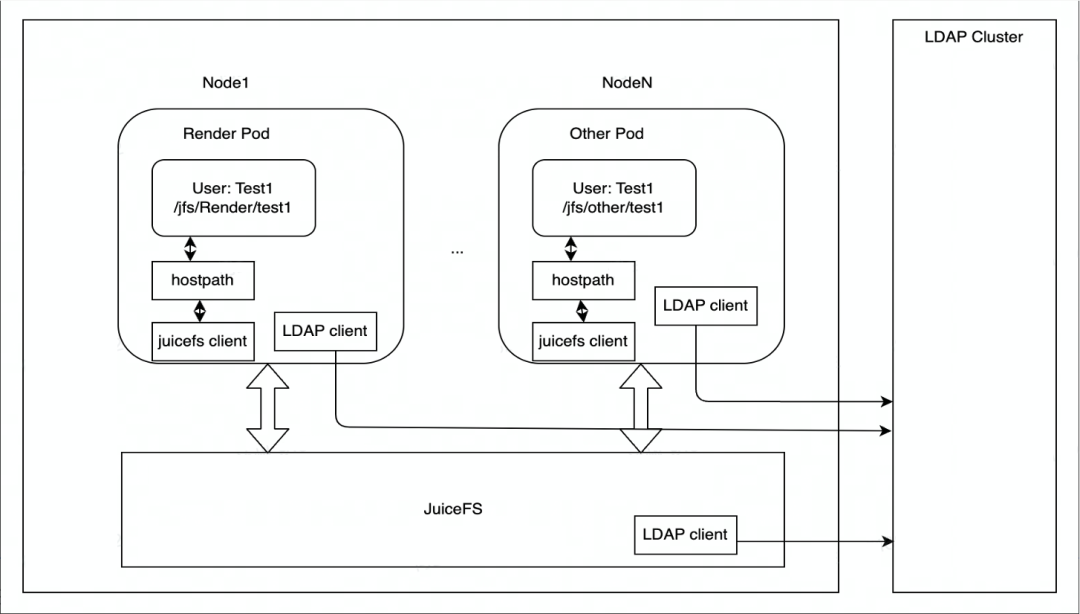
Unsere aktuellen Anwendungsszenarien basieren hauptsächlich auf Rendering und werden in Zukunft auf weitere Geschäftsszenarien ausgeweitet. In Bezug auf den Datenzugriff wird auf Edge-Storage derzeit hauptsächlich über HostPath zugegriffen.Wenn in Zukunft eine elastische Erweiterung erforderlich ist, wird der Einsatz von JuiceFS CSI Driver in Betracht gezogen.

04- Praktische Erfahrung im Produktionsumfeld
Metadaten-Engine
JuiceFS unterstützt viele Metadaten-Engines (wie MySQL, Redis), und die Edge-Storage-Produktionsumgebung der Volcano-Engine verwendet MySQL . Nach der Auswertung der Größenordnung des Datenvolumens und der Anzahl der Dateien (die Anzahl der Dateien liegt im zweistelligen Millionenbereich, wahrscheinlich im zweistelligen Millionenbereich, das Szenario von mehr Lesevorgängen und weniger Schreibvorgängen) sowie der Schreib- und Leseleistung, stellten wir fest dass MySQL in Betrieb und Wartung ist, die Daten zuverlässig sind, und die Geschäftsseite hat sich besser entwickelt.
MySQL verwendet derzeit zwei Bereitstellungsschemata: Einzelinstanz und Multiinstanz (ein Master und zwei Slaves), die flexibel für verschiedene Szenarien am Edge ausgewählt werden können. In einer Umgebung mit wenigen Ressourcen kann eine einzelne Instanz für die Bereitstellung verwendet werden, und der Durchsatz von MySQL ist innerhalb eines bestimmten Bereichs relativ stabil. Beide Bereitstellungsschemata verwenden leistungsstarke Cloud-Festplatten (bereitgestellt von Ceph-Clustern) als MySQL-Datenfestplatten, wodurch sichergestellt werden kann, dass MySQL-Daten selbst bei Bereitstellungen mit einer einzelnen Instanz nicht verloren gehen.
In Szenarien mit reichlich Ressourcen können mehrere Instanzen für die Bereitstellung verwendet werden. Die Master-Slave-Synchronisation mehrerer Instanzen wird durch die von MySQL Operator ( https://github.com/bitpoke/mysql-operator) bereitgestellte Orchestrator-Komponente realisiert und gilt nur dann als OK, wenn zwei Slave-Instanzen erfolgreich synchronisiert wurden, aber ein Timeout Wenn die Synchronisierung nach Ablauf der Zeitüberschreitung nicht abgeschlossen ist, wird ein Erfolg zurückgegeben und ein Alarm ausgegeben. Nachdem der spätere Notfallwiederherstellungsplan abgeschlossen ist, kann die lokale Festplatte als Datenfestplatte von MySQL verwendet werden, um die Lese- und Schreibleistung weiter zu verbessern, die Latenz zu reduzieren und den Durchsatz zu erhöhen.
Container-Ressourcen für die MySQL-Einzelinstanzkonfiguration :
- Prozessor: 8C
- Speicher: 24G
- Festplatte: 100 GB (basierend auf Ceph RBD, Metadaten belegen etwa 30 GB Speicherplatz in dem Szenario, in dem zig Millionen Dateien gespeichert werden)
- Container-Image: mysql:5.7
MySQL- my.cnfKonfiguration :
ignore-db-dir=lost+found # 如果使用 MySQL 8.0 及以上版本,需要删除这个配置
max-connections=4000
innodb-buffer-pool-size=12884901888 # 12G
Objektspeicher
Als Objektspeicher kommt ein selbst gebauter Ceph-Cluster zum Einsatz , der über Rook bereitgestellt wird, in der aktuellen Produktionsumgebung kommt die Octopus-Version zum Einsatz. Mit Rook können Ceph-Cluster Cloud-nativ betrieben und gewartet werden, und Ceph-Komponenten können über Kubernetes verwaltet und gesteuert werden, was die Komplexität der Bereitstellung und Verwaltung von Ceph-Clustern erheblich reduziert.
Hardwarekonfiguration des Ceph-Servers:
- 128 Kern-CPU
- 512 GB Arbeitsspeicher
- Systemfestplatte: 2T * 1 NVMe-SSD
- Datenfestplatte: 8T * 8 NVMe SSD
Konfiguration der Ceph-Serversoftware:
- Betriebssystem: Debian 9
- Kernel: Ändern Sie /proc/sys/kernel/pid_max
- Ceph-Version: Octopus
- Ceph-Speicher-Backend: BlueStore
- Anzahl der Ceph-Repliken: 3
- Deaktivieren Sie die automatische Anpassungsfunktion der Platzierungsgruppe
Das Hauptaugenmerk beim Edge-Rendering liegt auf niedriger Latenz und hoher Leistung, daher konfigurieren wir den Cluster in Bezug auf die Auswahl der Serverhardware mit NVMe-SSD-Festplatten. Andere Konfigurationen basieren hauptsächlich auf der Version, die von der Vulkan-Engine verwaltet wird, und das von uns gewählte Betriebssystem ist Debian 9. Für Datenredundanz sind drei Kopien für Ceph konfiguriert In einer Edge-Computing-Umgebung kann EC aufgrund von Ressourcenbeschränkungen instabil sein.
JuiceFS-Client
Der JuiceFS-Client unterstützt die direkte Verbindung zu Ceph RADOS (bessere Leistung als Ceph RGW), aber diese Funktion ist in der offiziellen Binärdatei nicht standardmäßig aktiviert, sodass der JuiceFS-Client neu kompiliert werden muss. Sie müssen librados vor dem Kompilieren installieren. Es wird empfohlen, dass die librados-Version der Ceph-Version entspricht. Debian 9 hat kein librados-dev-Paket, das der Version von Ceph Octopus (v15.2.*) entspricht, also müssen Sie es herunterladen das Installationspaket selbst.
Nach der Installation von librados-dev können Sie mit dem Kompilieren des JuiceFS-Clients beginnen. Wir kompilieren hier mit Go 1.19.In 1.19 wurde die Funktion zur Steuerung der maximalen Speicherzuweisung ( https://go.dev/doc/gc-guide#Memory_limit) hinzugefügt , die verhindern kann , dass der JuiceFS-Client zu viel belegt in extremen Fällen tritt OOM aufgrund von mehr Speicher auf.
make juicefs.ceph
Nachdem Sie den JuiceFS-Client kompiliert haben, können Sie ein Dateisystem erstellen und das JuiceFS-Dateisystem auf dem Rechenknoten mounten. Detaillierte Schritte finden Sie in der offiziellen JuiceFS-Dokumentation.
05- Zukunft und Ausblick
JuiceFS ist ein verteiltes Speichersystemprodukt im Cloud-nativen Bereich. Es bietet eine CSI-Treiberkomponente, die Cloud-native Bereitstellungsmethoden sehr gut unterstützen kann. Es bietet Benutzern sehr flexible Wahlmöglichkeiten in Bezug auf Betrieb und Wartung. Benutzer können Cloud wählen , Sie können sich auch für eine privatisierte Bereitstellung entscheiden, die in Bezug auf die Speichererweiterung sowie den Betrieb und die Wartung relativ einfach ist. Es ist vollständig mit dem POSIX-Standard kompatibel und verwendet dieselben Metadaten wie S3, wodurch es sehr bequem ist, den Vorgang des Hochladens, Verarbeitens und Herunterladens durchzuführen. Da es sich bei seinem Back-End-Speicher um eine Objektspeicherfunktion handelt, gibt es eine hohe Verzögerung beim Lesen und Schreiben zufälliger kleiner Dateien und die IOPS sind relativ niedrig.Für Szenarien mit mehr und weniger Schreiben hat JuiceFS einen relativ großen Vorteil, der sehr ist geeignet für die geschäftlichen Anforderungen von Edge-Rendering-Szenarien .
Die Zukunftspläne des Edge-Cloud-Teams von Volcano Engine in Bezug auf JuiceFS lauten wie folgt:
- Eher Cloud-nativ : JuiceFS wird derzeit in Form von HostPath verwendet. Später, in Anbetracht einiger elastischer Skalierungsszenarien, können wir zur Verwendung von JuiceFS in Form von CSI Driver wechseln;
- Metadaten-Engine-Upgrade : Abstrahieren Sie den gRPC-Dienst von einer Metadaten-Engine, die Caching-Funktionen auf mehreren Ebenen bietet, um sich besser an Szenarien mit mehr Lesevorgängen und weniger Schreibvorgängen anzupassen. Der zugrunde liegende Metadatenspeicher kann eine Migration auf TiKV in Betracht ziehen, um eine größere Anzahl von Dateien zu unterstützen.Im Vergleich zu MySQL kann es die Leistung der Metadaten-Engine durch horizontale Erweiterung besser steigern;
- Neue Funktionen und Fehlerbehebungen : Für das aktuelle Geschäftsszenario werden einige Funktionen hinzugefügt und einige Fehler behoben, und wir erwarten, PR zur Community beizutragen und der Community etwas zurückzugeben.
Wenn Sie hilfreich sind, beachten Sie bitte unser Projekt Juicedata/JuiceFS ! (0ᴗ0✿)