Der aktuelle Status von Apache Spark in iQiyi
Apache Spark ist das Offline-Computing-Framework, das hauptsächlich von der iQiyi-Big-Data-Plattform verwendet wird und einige Stream-Computing-Aufgaben für die Datenverarbeitung, Datensynchronisierung, Datenabfrageanalyse und andere Szenarien unterstützt:
-
Datenverarbeitung : Die Datenentwicklungsplattform unterstützt Entwickler bei der Übermittlung von Spark-Jar-Paketaufgaben oder Spark-SQL-Aufgaben für die ETL-Verarbeitung von Daten.
-
Datensynchronisierung
: Das von iQIYI selbst entwickelte BabelX-Datensynchronisierungstool basiert auf dem Spark-Computing-Framework. Es unterstützt den Datenaustausch zwischen mehreren Clustern und mehreren Clouds konfigurierte vollständig verwaltete Datensynchronisierungsaufgaben.
-
Datenanalyse : Datenanalysten und Betriebsstudenten übermitteln SQL oder konfigurieren Datenindikatorabfragen auf der Ad-hoc-Abfrageplattform Magic Mirror und rufen den Spark SQL-Dienst über das Pilot Unified SQL Gateway zur Abfrageanalyse auf.
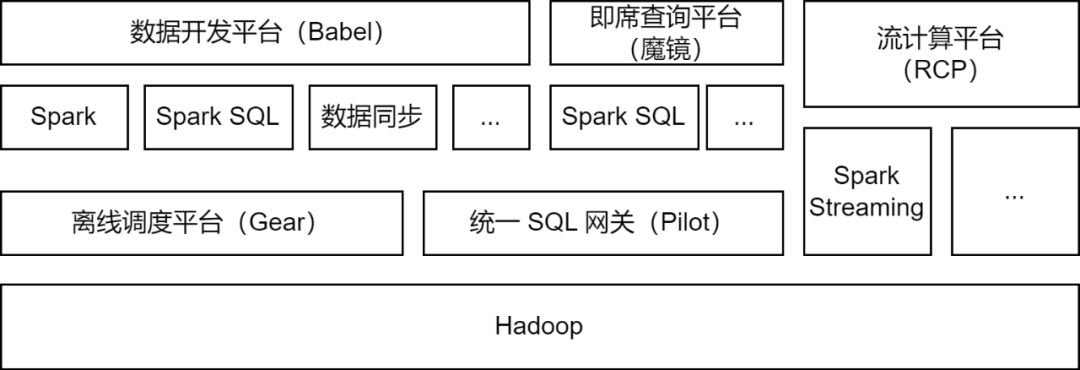
Derzeit führt der iQiyi Spark-Dienst täglich mehr als 200.000 Spark-Aufgaben aus und belegt damit mehr als die Hälfte der gesamten Big-Data-Computing-Ressourcen.
Im Zuge der Aktualisierung und Optimierung der iQiyi-Big-Data-Plattformarchitektur wurde der Spark-Dienst einer Versionsiteration, Dienstoptimierung, Aufgaben-SQLisierung und Ressourcenkostenmanagement usw. unterzogen, was die Recheneffizienz und Ressourceneinsparung bei Offline-Aufgaben erheblich verbessert hat.
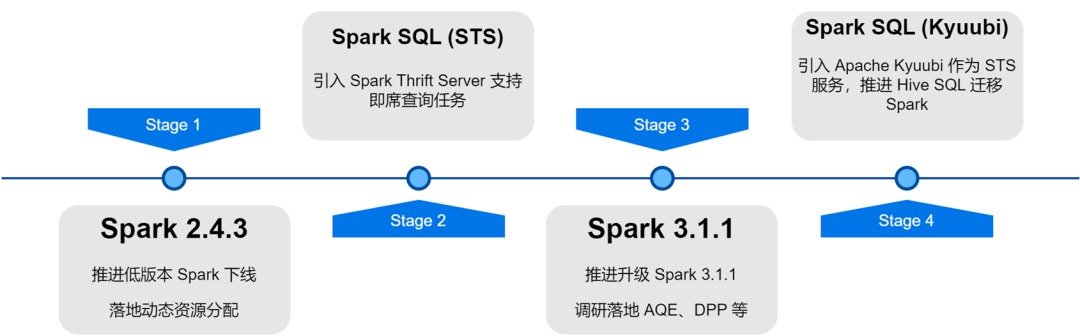
Optimierung der Spark-Computing-Framework-Anwendung
Mit dem iterativen Upgrade der internen Spark-Version haben wir einige hervorragende Funktionen der neuen Spark-Version untersucht und implementiert: dynamische Ressourcenzuweisung, adaptive Abfrageoptimierung, dynamische Partitionsbereinigung usw.
-
Dynamische Ressourcenzuteilung (DRA)
: Es besteht Blindheit bei der Benutzeranwendung für Ressourcen, und auch die Ressourcenanforderungen jeder Stufe von Spark-Aufgaben sind unterschiedlich. Eine unangemessene Ressourcenzuteilung führt zu einer Verschwendung von Aufgabenressourcen oder einer langsamen Ausführung. Wir haben den External Shuffle Service in Spark 2.4.3 gestartet und die dynamische Ressourcenzuteilung (DRA) aktiviert. Nach der Aktivierung startet Spark den Executor dynamisch oder gibt ihn frei, basierend auf den Ressourcenanforderungen der aktuellen Ausführungsphase. Nachdem DRA online ging, wurde der Ressourcenverbrauch von Spark-Aufgaben um 20 % reduziert.
-
Adaptive Abfrageoptimierung (AQE)
: Adaptive Abfrageoptimierung (AQE) ist eine hervorragende Funktion, die in Spark 3.0 eingeführt wurde. Basierend auf den statistischen Indikatoren während der Laufzeit der Vorstufe optimiert sie dynamisch den Ausführungsplan der nachfolgenden Stufen und wählt automatisch aus Geeignete Join-Strategie: Optimieren Sie schiefe Joins, führen Sie kleine Partitionen zusammen, teilen Sie große Partitionen usw. Nach dem Upgrade von Spark 3.1.1 war AQE standardmäßig aktiviert, wodurch Probleme wie kleine Dateien und Datenversatz effektiv gelöst und die Rechenleistung von Spark erheblich verbessert wurden. Die Gesamtleistung stieg um etwa 10 %.
-
Dynamische Partitionsbereinigung (DPP)
: In SQL-Computing-Engines wird Prädikat-Pushdown normalerweise verwendet, um die aus der Datenquelle gelesene Datenmenge zu reduzieren und dadurch die Recheneffizienz zu verbessern. In Spark3 wird eine neue Pushdown-Methode eingeführt: dynamische Partitionsbereinigung und Laufzeitfilter. Indem zunächst die kleine Tabelle des Joins berechnet wird, wird die große Tabelle des Joins basierend auf den Berechnungsergebnissen gefiltert, wodurch die von der großen Tabelle gelesene Datenmenge reduziert wird Tisch. Wir haben diese beiden Funktionen untersucht und getestet und DPP standardmäßig aktiviert. In einigen Geschäftsszenarien stieg die Leistung um das 33-fache. Wir haben jedoch festgestellt, dass die Aktivierung von DPP in Spark 3.1.1 dazu führt, dass die SQL-Analyse mit vielen Unterabfragen besonders langsam ist. Aus diesem Grund haben wir eine Optimierungsregel implementiert: Berechnen Sie die Anzahl der Unterabfragen und
deaktivieren Sie die DPP-
Optimierung, wenn sie 5 überschreitet.
Bei der Verwendung von Spark sind wir auch auf einige Probleme gestoßen, indem wir die neuesten Fortschritte der Community verfolgt haben und einige Patches zur Lösung dieser Probleme installiert haben. Darüber hinaus haben wir selbst einige Verbesserungen an Spark vorgenommen, um es für verschiedene Anwendungsszenarien geeignet zu machen und die Stabilität des Computer-Frameworks zu verbessern.
-
Unterstützt gleichzeitiges Schreiben
Da Spark 3.1.1 Tabellen im Hive-Parquet-Format standardmäßig in den integrierten Parquet Writer von Spark konvertiert, verwenden Sie den Operator „InsertIntoHadoopFsRelationCommand“ zum Schreiben von Daten (spark.sql.hive.convertMetastoreParquet=true). Beim Schreiben einer statischen Partition wird das temporäre Verzeichnis direkt unter dem Tabellenpfad erstellt. Wenn mehrere statische Partitionsschreibaufgaben gleichzeitig in verschiedene Partitionen derselben Tabelle schreiben, besteht das Risiko eines Schreibfehlers oder eines Datenverlusts (wenn eine Aufgabe festgeschrieben wird, wird das gesamte temporäre Verzeichnis bereinigt, was zu Datenverlust führt). für andere Aufgaben).
Wir fügen dem Operator „InsertIntoHadoopFsRelationCommand“ einen Parameter „forceUseStagingDir“ hinzu und verwenden das aufgabenspezifische Staging-Verzeichnis als temporäres Verzeichnis. Auf diese Weise verwenden verschiedene Aufgaben unterschiedliche temporäre Verzeichnisse, wodurch das Problem des gleichzeitigen Schreibens gelöst wird. Wir haben das relevante Problem [SPARK-37210] an die Community weitergeleitet.
-
Unterstützt das Abfragen von Unterverzeichnissen
Nach dem Upgrade von Hive auf 3.x wird standardmäßig die Tez-Engine verwendet. Wenn die Union-Anweisung ausgeführt wird, wird das Unterverzeichnis HIVE_UNION_SUBDIR generiert. Da Spark Daten in Unterverzeichnissen ignoriert, können keine Daten gelesen werden.
Dieses Problem kann gelöst werden, indem Parquet/Orc Reader auf Hive Reader zurückgesetzt wird und die folgenden Parameter hinzugefügt werden:

Die Verwendung des integrierten Parquet Reader von Spark führt jedoch zu einer besseren Leistung. Daher haben wir den Plan, auf Hive Reader zurückzugreifen, aufgegeben und Spark stattdessen umgestaltet. Da Spark bereits das Lesen von Unterverzeichnissen nicht partitionierter Tabellen über den Parameter „recursiveFileLookup“ unterstützt, haben wir dies erweitert, um das Lesen von Unterverzeichnissen partitionierter Tabellen zu unterstützen. Weitere Informationen finden Sie unter: [SPARK-40600].
-
Verbesserungen der JDBC-Datenquelle
In Datensynchronisierungsanwendungen gibt es eine große Anzahl von JDBC-Datenquellenaufgaben. Um die Betriebseffizienz zu verbessern und sich an verschiedene Anwendungsszenarien anzupassen, haben wir die folgenden Änderungen an der integrierten JDBC-Datenquelle vorgenommen:
Sharding-Bedingungen nach unten verschieben
:
Nachdem Spark die JDBC-Datenquelle fragmentiert hat, werden Sharding-Bedingungen über Unterabfragen eingefügt. Wir haben festgestellt, dass die Unterabfragebedingungen in MySQL 5.x nicht nach unten verschoben werden können, daher haben wir einen Platzhalter hinzugefügt, der die Position der Bedingung darstellt , und wenn die Sharding-Bedingung in Spark eingefügt wird, wird sie in die Unterabfrage verschoben, wodurch die Möglichkeit erkannt wird, die Sharding-Bedingung nach unten zu verschieben.
Mehrere Schreibmodi
:
Wir haben mehrere Schreibmodi für JDBC-Datenquellen in Spark implementiert.
-
Normal: Normaler Modus, verwenden Sie zum Schreiben den Standard-INSERT INTO
-
Upsert: Aktualisierung, wenn der Primärschlüssel vorhanden ist, geschrieben im Modus INSERT INTO...ON DUPLICATE KEY UPDATE
-
Ignorieren: Ignorieren, wenn der Primärschlüssel vorhanden ist, Schreiben im INSERT IGNORE INTO-Modus
Stiller Modus:
Wenn während des JDBC-Schreibens eine Ausnahme auftritt, wird nur das Ausnahmeprotokoll gedruckt und die Aufgabe wird nicht beendet.
Unterstützung des Kartentyps
: Wir verwenden die JDBC-Datenquelle zum Lesen und Schreiben von ClickHouse-Daten. Der Kartentyp in ClickHouse wird in der JDBC-Datenquelle nicht unterstützt, daher haben wir Unterstützung für den Kartentyp hinzugefügt.
-
Beschränkung der Schreibgröße auf der lokalen Festplatte
Vorgänge wie „Shuffle“, „Cache“ und „Spill“ in Spark generieren einige lokale Dateien. Wenn zu viele lokale Dateien geschrieben werden, ist möglicherweise die Festplatte des Computerknotens voll, was die Stabilität des Clusters beeinträchtigt.
In diesem Zusammenhang haben wir in Spark einen Indikator für das Festplatten-Schreibvolumen hinzugefügt, eine Ausnahme ausgelöst, wenn das Festplatten-Schreibvolumen den Schwellenwert erreicht, die Task-Fehlerausnahme in TaskScheduler beurteilt und DagScheduler aufgerufen hat, wenn die Festplatten-Schreiblimit-Ausnahme erfasst wurde Die Methode stoppt Aufgaben mit übermäßiger Festplattennutzung.
Gleichzeitig haben wir in ExecutorMetric auch den Executor-Festplattennutzungsindikator hinzugefügt, um die aktuelle Festplattennutzung von Spark Executor anzuzeigen und so die Beobachtung von Trends und die Datenanalyse zu erleichtern.
Der Spark-Dienst beansprucht viele Rechenressourcen. Wir haben eine Ausnahmeverwaltungsplattform entwickelt, um Rechenressourcen für Spark-Batchverarbeitungsaufgaben bzw. Stream-Computing-Aufgaben zu prüfen und zu verwalten.
Im täglichen Betrieb und bei der Wartung haben wir festgestellt, dass bei vielen Spark-Aufgaben Probleme wie Speicherverschwendung und geringe CPU-Auslastung auftreten. Um Aufgaben mit diesen Problemen zu finden, liefern wir Ressourcenindikatoren an Prometheus, wenn Spark-Aufgaben ausgeführt werden, um die Aufgabenressourcennutzung zu analysieren und Ressourcenkonfigurations- und Berechnungsdetails durch Parsen von Spark EventLog zu erhalten.
Durch die Optimierung der Ressourcenparameter von Aufgaben und die Ermöglichung einer dynamischen Ressourcenzuweisung wird die Rechenressourcennutzung von Spark-Aufgaben effektiv verbessert. Das Upgrade der Spark-Version bringt auch viele Ressourceneinsparungen mit sich.
Die Optimierung der Ressourcenparameter ist in Speicher- und CPU-Optimierung unterteilt. Die Ausnahmeverwaltungsplattform empfiehlt angemessene Ressourcenparametereinstellungen basierend auf der Spitzenressourcennutzung der Aufgabe in den letzten sieben Tagen und verbessert so die Ressourcennutzung von Spark-Aufgaben.
Am Beispiel der Speicheroptimierung lösen Benutzer das Problem des Speicherüberlaufs (OOM) häufig durch Erhöhen des Speichers, ignorieren jedoch die eingehende Untersuchung der Ursachen von OOM. Dies führt dazu, dass die Speicherparameter einer großen Anzahl von Spark-Aufgaben zu hoch eingestellt sind und das Verhältnis von Warteschlangenressourcenspeicher zu CPU unausgeglichen ist. Wir erhalten Spark Executor-Speicherindikatoren und senden Ausnahmearbeitsaufträge, um Benutzer zu benachrichtigen und sie bei der ordnungsgemäßen Konfiguration der Speicherparameter und der Anzahl der Partitionen anzuleiten.
Nach fast einem Jahr Ressourcen-Audit-Management hat die Ausnahmemanagementplattform mehr als 1.600 Arbeitsaufträge erteilt und damit insgesamt etwa 27 % der Rechenressourcen eingespart.
Implementierung und Optimierung des Spark SQL-Dienstes
Der iQiyi Spark SQL-Dienst hat mehrere Phasen durchlaufen, vom nativen Thrift Server-Dienst von Spark über Kyuubi 0.7 bis zur Apache Kyuubi 1.4-Version, was große Verbesserungen der Dienstarchitektur und -stabilität mit sich gebracht hat.
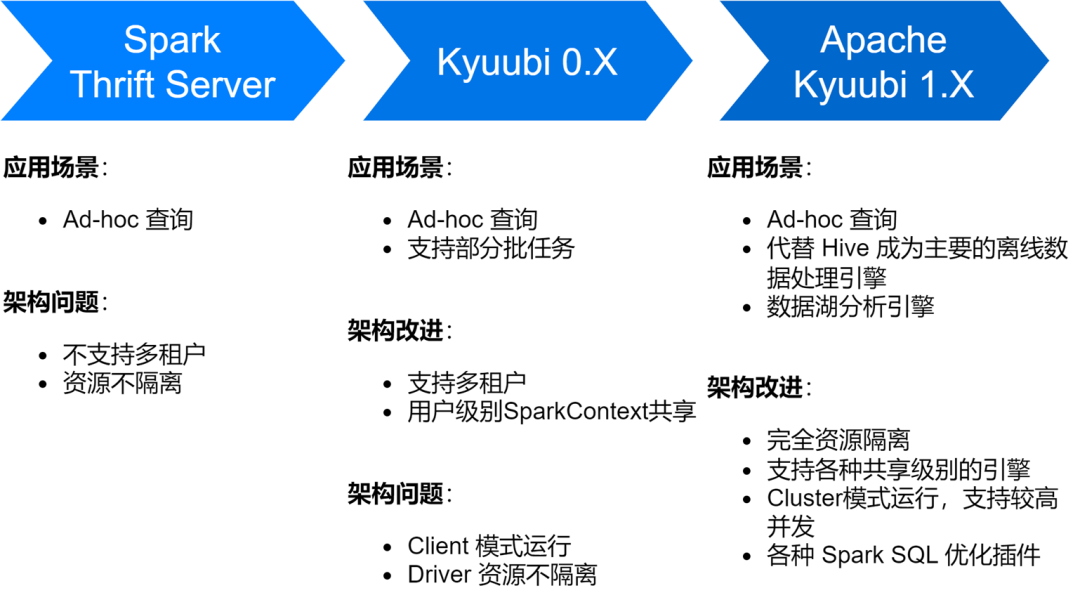
Derzeit hat der Spark SQL-Dienst Hive als wichtigste Offline-Datenverarbeitungs-Engine von iQiyi abgelöst und führt täglich durchschnittlich etwa 150.000 SQL-Aufgaben aus.
-
Optimieren Sie die Speicher- und Recheneffizienz
Bei der Erkundung des Spark SQL-Dienstes sind wir auch auf einige Probleme gestoßen, darunter vor allem die Generierung einer großen Anzahl kleiner Dateien, größerer Speicher und langsamere Berechnungen. Aus diesem Grund haben wir auch eine Reihe von Optimierungen der Speicher- und Recheneffizienz durchgeführt.
Aktivieren Sie die ZStandard-Komprimierung, um das Komprimierungsverhältnis zu verbessern
Zstd ist der Open-Source-Komprimierungsalgorithmus von Meta und weist im Vergleich zu anderen Komprimierungsformaten eine höhere Komprimierungsrate und Dekomprimierungseffizienz auf. Unsere tatsächlichen Messergebnisse zeigen, dass die Komprimierungsrate von Zstd der von Gzip entspricht und die Dekomprimierungsgeschwindigkeit besser als die von Snappy ist. Daher haben wir während des Spark-Upgrades das Zstd-Komprimierungsformat als Standarddatenkomprimierungsformat verwendet und Shuffle-Daten auch auf Zstd-Komprimierung eingestellt, was zu großen Einsparungen beim Clusterspeicher führte. Bei der Anwendung in Werbedatenszenarien wurde die Komprimierungsrate um das 3,3-fache verbessert , wodurch 76 % der Lagerkosten eingespart werden.
Fügen Sie die Rebalance-Phase hinzu, um die Generierung kleiner Dateien zu vermeiden
Das Problem kleiner Dateien ist ein wichtiges Problem in Spark SQL: Zu viele kleine Dateien üben großen Druck auf den Hadoop-Namenode aus und beeinträchtigen die Stabilität des Clusters. Das native Spark-Computing-Framework verfügt nicht über eine gute automatisierte Lösung zur Lösung des Problems kleiner Dateien. In diesem Zusammenhang haben wir auch einige Branchenlösungen untersucht und schließlich die Lösung zur Optimierung kleiner Dateien verwendet, die zum Kyuubi-Dienst gehört.
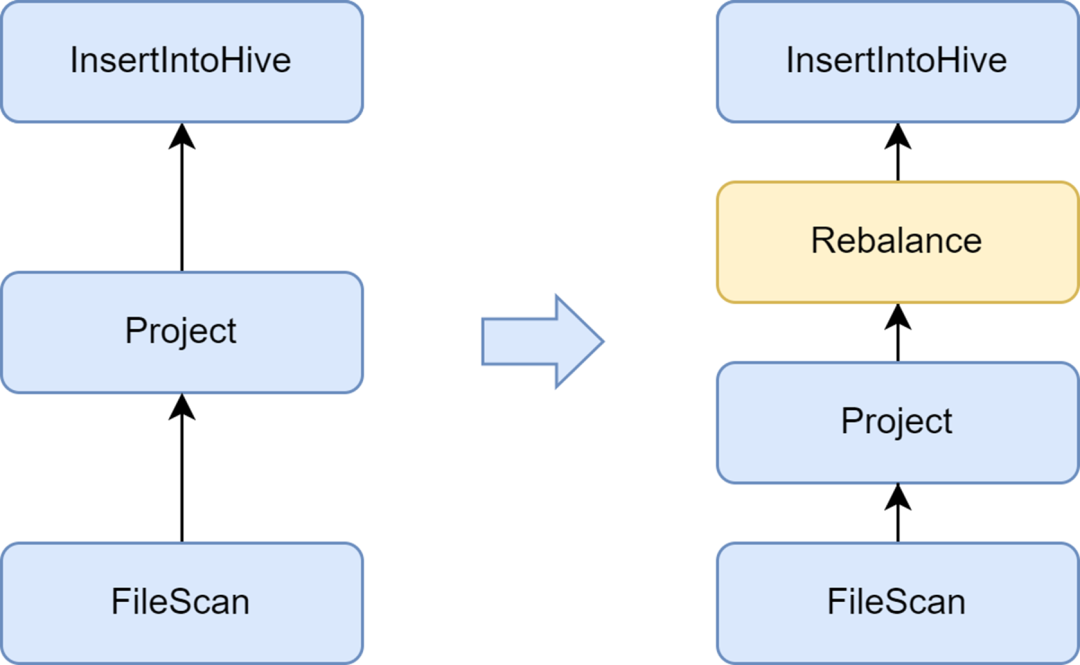
Der von Kyuubi bereitgestellte insertRepartitionBeforeWrite-Optimierer kann den Rebalance-Operator vor dem Insert-Operator einfügen. In Kombination mit der Logik von AQE zum automatischen Zusammenführen kleiner Partitionen und Teilen großer Partitionen wird die Steuerung der Ausgabedateigröße realisiert und das Problem kleiner Dateien effektiv gelöst.
Nach der Aktivierung wird die durchschnittliche Ausgabedateigröße von Spark SQL von 10 MB auf 262 MB optimiert, wodurch die Generierung einer großen Anzahl kleiner Dateien vermieden wird.
Aktivieren Sie die Neupartitionssortierungsinferenz, um die Komprimierungsrate weiter zu verbessern
Nachdem wir die Optimierung kleiner Dateien aktiviert hatten, stellten wir fest, dass der Datenspeicher einiger Aufgaben viel größer wurde. Dies liegt daran, dass die in die Optimierung kleiner Dateien eingefügte Rebalance-Operation Partitionsfelder oder zufällige Partitionen für die Partitionierung verwendet und die Daten zufällig verstreut sind, was zu einer Verringerung der Codierungseffizienz der Datei im Parquet-Format führt, was wiederum zu einer Verringerung führt in der Dateikomprimierungsrate.
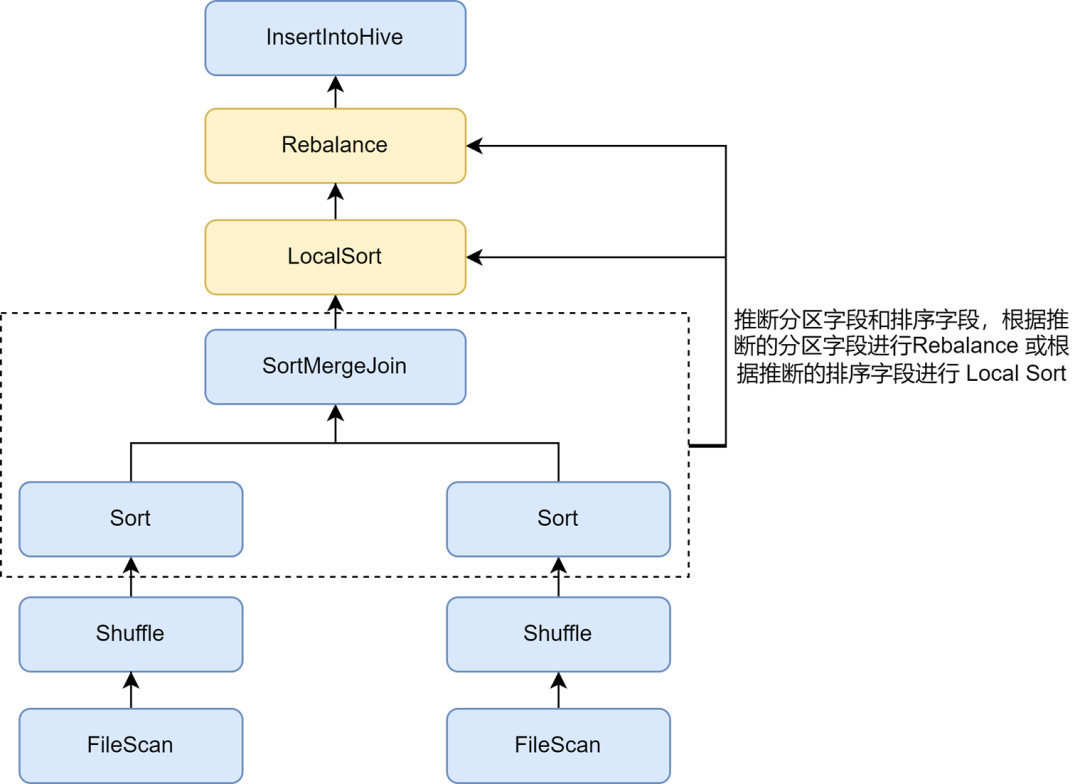
In den Regeln der Kyuubi-Optimierung für kleine Dateien kann die automatische Inferenz von Partitionen und Sortierfeldern über den Parameter spark.sql.optimizer.inferRebalanceAndSortOrders.enabled aktiviert werden. Für nicht dynamisches Partitionsschreiben können Operatoren wie Join, Aggregate und Sort in verwendet werden Die Partitionierungs- und Sortierfelder werden aus den Schlüsseln abgeleitet, und die abgeleiteten Partitionsfelder werden für die Neuverteilung verwendet, oder die abgeleiteten Sortierfelder werden für die lokale Sortierung vor der Neuverteilung verwendet, sodass die Datenverteilung endgültig eingefügt wird Der Rebalance-Operator stimmt so weit wie möglich mit dem Vorplan überein und vermeidet das Schreiben. Die eingehenden Daten werden zufällig verteilt, wodurch die Komprimierungsrate effektiv verbessert wird.
Aktivieren Sie die Zorder-Optimierung, um die Komprimierungsrate und die Abfrageeffizienz zu verbessern
Die Zorder-Sortierung ist ein mehrdimensionaler Sortieralgorithmus. Bei spaltenorientierten Speicherformaten wie Parquet können effektive Sortieralgorithmen die Daten kompakter machen und dadurch die Datenkomprimierungsrate verbessern. Da außerdem ähnliche Daten in derselben Speichereinheit gesammelt werden, ist beispielsweise der statistische Bereich von Min./Max. kleiner, wodurch die Menge der Datenübersprungen während des Abfragevorgangs erhöht werden kann, wodurch die Abfrageeffizienz effektiv verbessert wird.
Die Optimierung der Zorder-Cluster-Sortierung ist in Kyuubi implementiert. Zorder-Felder können für Tabellen konfiguriert werden, und die Zorder-Sortierung wird beim Schreiben automatisch hinzugefügt. Für bestehende Aufgaben wird auch der Befehl „Optimieren“ zur Zorder-Optimierung vorhandener Daten unterstützt. Wir haben in einigen wichtigen Unternehmen die Zorder-Optimierung intern hinzugefügt, wodurch der Datenspeicherplatz um 13 % reduziert und die Datenabfrageleistung um 15 % verbessert wurde.
Führen Sie in der letzten Phase eine unabhängige AQE-Konfiguration ein, um die Rechenparallelität zu erhöhen
Während der Migration einiger Hive-Aufgaben zu Spark stellten wir fest, dass sich die Ausführungsgeschwindigkeit einiger Aufgaben tatsächlich verlangsamte. Die Analyse ergab, dass wir den Spark von AQE geändert haben, weil der Rebalance-Operator vor dem Schreiben eingefügt und mit Spark AQE kombiniert wurde. sql. Die adaptive.advisoryPartitionSizeInBytes-Konfiguration ist auf 1024 MB eingestellt, was dazu führt, dass die Parallelität der Zwischen-Shuffle-Phase kleiner wird, was wiederum die Aufgabenausführung langsamer macht.
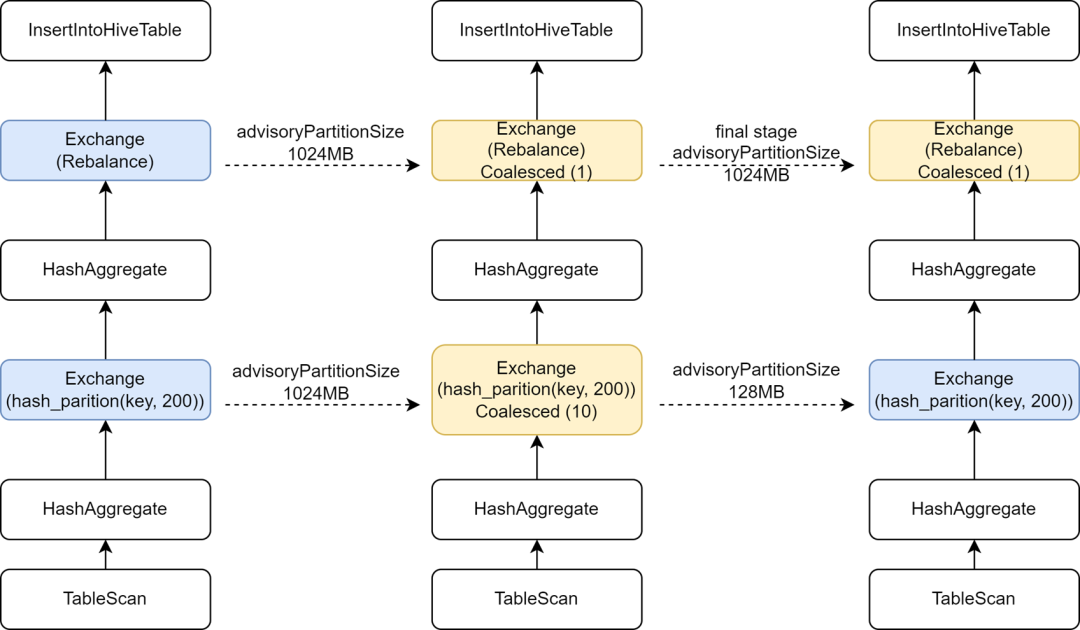
Kyuubi bietet eine Optimierung der Endstufenkonfiguration und ermöglicht das separate Hinzufügen einiger Konfigurationen für die Endstufe, sodass wir eine größere AdvisoryPartitionSizeInBytes für die Endstufe der Steuerung kleiner Dateien hinzufügen und eine kleinere AdvisoryPartitionSizeInBytes für die vorherigen Stufen verwenden können, um die Parallelität zu erhöhen des Berechnungsgrads und reduziert den Festplattenüberlauf während der Shuffle-Phase, wodurch die Recheneffizienz effektiv verbessert wird. Durch das Hinzufügen dieser Konfiguration wird die Gesamtausführungszeit von Spark SQL-Aufgaben um etwa 9 % verkürzt.
Leiten Sie dynamisches Schreiben von Einzelpartitionsaufgaben ab, um übermäßig große Shuffle-Partitionen zu vermeiden
Für das dynamische Schreiben von Partitionen verwendet die Optimierung kleiner Dateien von Kyuubi das dynamische Partitionsfeld für die Neuverteilung. Bei Aufgaben, die dynamische Partitionierung zum Schreiben auf eine einzelne Partition verwenden, werden alle Shuffle-Daten auf dieselbe Shuffle-Partition geschrieben. iQIYI verwendet intern Apache Uniffle als Remote-Shuffle-Dienst. Große Partitionen verursachen einen einzigen Druckpunkt auf dem Shuffle-Server und lösen sogar eine Strombegrenzung aus und führen zu einer Verringerung der Schreibgeschwindigkeit. Zu diesem Zweck haben wir eine Optimierungsregel entwickelt, um die Filterbedingungen für geschriebene Partitionen zu erfassen und abzuleiten, ob die Daten einer einzelnen Partition für solche Aufgaben dynamisch geschrieben werden. Für die Neuverteilung verwenden wir keine dynamischen Partitionsfelder mehr, sondern zufällige Neu ausgleichen, dadurch wird die Generierung einer größeren Shuffle-Partition vermieden. Weitere Informationen finden Sie unter: [KYUUBI-5079].
-
Abnormale SQL-Erkennung und -Abfang
Wenn es Probleme mit der Datenqualität gibt oder Benutzer mit der Datenverteilung nicht vertraut sind, ist es leicht, abnormales SQL zu übermitteln, was zu einer erheblichen Ressourcenverschwendung und einer geringen Recheneffizienz führen kann. Wir haben dem Spark SQL-Dienst einige Überwachungsindikatoren hinzugefügt und einige abnormale Computerszenarien erkannt und abgefangen.
Begrenzen Sie große Abfragen
Bei iQiyi übermitteln Datenanalysten SQL für Ad-hoc-Abfrageanalysen über die Ad-hoc-Abfrageplattform Magic Mirror, die Benutzern Abfragefunktionen der zweiten Ebene bietet. Wir verwenden die gemeinsam genutzte Engine von Kyuubi als Back-End-Verarbeitungs-Engine, um zu vermeiden, dass für jede Abfrage eine neue Engine gestartet wird, was Startzeit und Rechenressourcen verschwendet. Die permanente Präsenz der gemeinsam genutzten Engine im Hintergrund kann den Benutzern ein schnelleres interaktives Erlebnis bieten.
Bei der gemeinsam genutzten Engine beanspruchen mehrere Anforderungen gegenseitig Ressourcen. Auch wenn wir die dynamische Ressourcenzuweisung aktivieren, gibt es immer noch Situationen, in denen die Ressourcen durch einige große Abfragen belegt werden, was dazu führt, dass andere Abfragen blockiert werden. In diesem Zusammenhang haben wir die Funktion zum Abfangen großer Abfragen im Spark-Plug-in von Kyuubi implementiert. Durch das Parsen von Vorgängen wie Table Scan im SQL-Ausführungsplan können wir die Anzahl der abgefragten Partitionen und die gescannte Datenmenge zählen den angegebenen Schwellenwert überschreitet, wird dies für große Abfragen und die Ausführung von Abfangvorgängen ermittelt.
Basierend auf den Ermittlungsergebnissen leitet die Magic Mirror-Plattform große Abfragen zur Ausführung an eine unabhängige Engine weiter. Darüber hinaus definiert Magic Mirror eine Zeitüberschreitung auf Minutenebene. Aufgaben, die die gemeinsame Engine zur Ausführung von Überstunden verwenden, werden abgebrochen und automatisch in eine unabhängige Engine-Ausführung umgewandelt. Der gesamte Prozess ist unempfindlich gegenüber Benutzern, wodurch verhindert wird, dass normale Abfragen blockiert werden, und dass große Abfragen weiterhin mit unabhängigen Ressourcen ausgeführt werden können.
Überwachen Sie die Datenflut
Einige Vorgänge wie Explode, Join und Count Distinct in Spark SQL führen zu einer Datenerweiterung. Wenn die Datenerweiterung sehr groß ist, kann dies zu einem Festplattenüberlauf, einem vollständigen GC oder sogar OOM führen und auch die Berechnungseffizienz verschlechtern. Anhand der Indikatoren für die Anzahl der Ausgabezeilen der vorhergehenden und folgenden Knoten im SQL-Ausführungsplandiagramm der SQL-Registerkarte der Spark-Benutzeroberfläche können wir leicht erkennen, ob eine Datenerweiterung stattgefunden hat.

Die Indikatoren im Spark SQL-Ausführungsplandiagramm werden dem Treiber über Aufgabenausführungsereignisse und Executor-Heartbeat-Ereignisse gemeldet und im Treiber aggregiert.
Um Laufzeitindikatoren schneller zu erfassen, haben wir den SQLOperationListener in Kyuubi erweitert, das SparkListenerSQLExecutionStart-Ereignis abgehört, um sparkPlanInfo aufrechtzuerhalten, und gleichzeitig das SparkListenerExecutorMetricsUpdate-Ereignis abgehört und die Änderungen in den statistischen SQL-Indikatoren des laufenden Knotens erfasst , und verglichen die Anzahl der Ausgabezeilenindikatoren des aktuell ausgeführten Knotens und die Anzahl der Ausgabezeilenindikatoren der vorhergehenden untergeordneten Knoten, berechnen die Datenerweiterungsrate, um festzustellen, ob eine schwerwiegende Datenerweiterung auftritt, und erfassen abnormale Ereignisse oder fangen abnormale Aufgaben ab Es erfolgt eine Datenerweiterung.
Das Problem der Datenverzerrung ist ein häufiges Problem in Spark SQL und beeinträchtigt die Leistung. Obwohl es in Spark AQE einige Regeln zur automatischen Optimierung der Datenverzerrung gibt, sind diese nicht immer effektiv. Darüber hinaus wird das Problem der Datenverzerrung wahrscheinlich durch den Benutzer verursacht Die falsche Analyselogik wurde geschrieben, weil das Verständnis nicht tief genug ist oder die Daten selbst Probleme mit der Datenqualität aufweisen. Daher müssen wir die Aufgabe der Datenverzerrung analysieren und den verzerrten Schlüsselwert lokalisieren.

Mithilfe der Stage Tasks-Statistiken in der Spark-Benutzeroberfläche können wir leicht feststellen, ob in der Aufgabe ein Datenversatz aufgetreten ist. Wie in der Abbildung oben gezeigt, überschreitet der Maximalwert von „Task's Duration“ und „Shuffle Read“ den 75. Perzentilwert, sodass die Daten offensichtlich sind Es ist ein Versatz aufgetreten.
Um jedoch die Schlüsselwerte zu berechnen, die eine Verzerrung in der Verzerrungsaufgabe verursachen, ist es normalerweise erforderlich, die SQL manuell aufzuteilen und dann die Verteilung der Schlüssel in jeder Phase mithilfe von Count Group By Keys zu berechnen, um den verzerrten Schlüsselwert zu ermitteln ist in der Regel eine relativ zeitaufwändige Aufgabe.
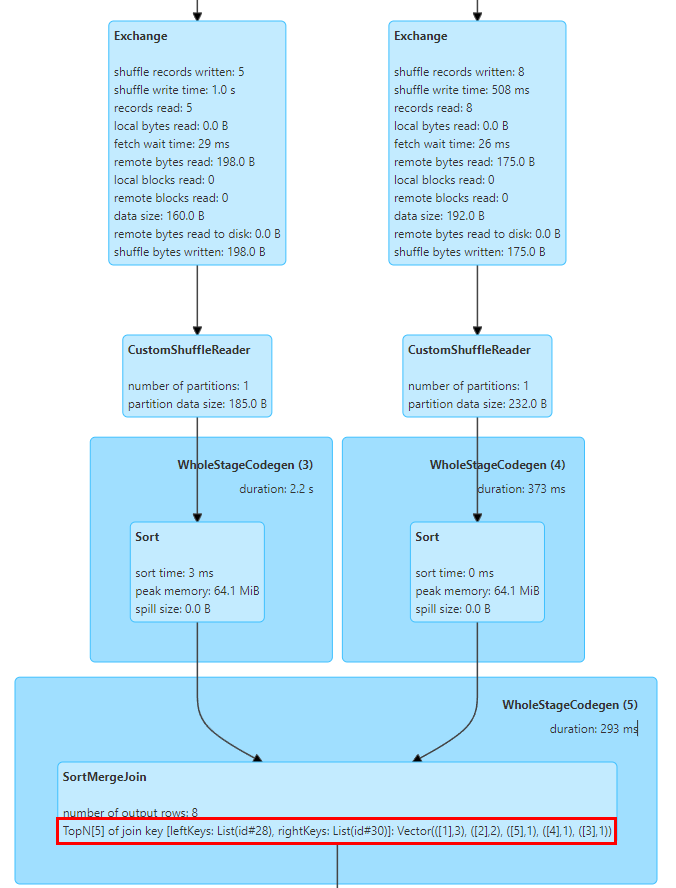
In diesem Zusammenhang haben wir TopN Keys-Statistiken in SortMergeJoinExec implementiert.
Die Implementierung von SortMergeJoin besteht darin, zuerst den Schlüssel zu sortieren und dann die Join-Operation auszuführen, sodass wir die TopN-Werte des Schlüssels durch Akkumulation leicht zählen können.
Wir haben einen TopNAccumulator-Akkumulator implementiert, der intern ein Objekt vom Typ Map[String, Long] verwaltet. Er verwendet den Schlüsselwert des Joins als Schlüssel der Karte und behält den Count-Wert des Schlüssels im Wert der Karte für jede Datenzeile bei Da die Daten in Ordnung sind, müssen wir für die kumulative Berechnung nur die eingefügten Schlüssel akkumulieren und beim Einfügen neuer Schlüssel feststellen, ob der N-Wert erreicht ist, und den kleinsten Schlüssel eliminieren.
Darüber hinaus unterstützt Spark nur die Anzeige statistischer Indikatoren vom Typ Long. Wir haben auch die Anzeigelogik von statistischen SQL-Indikatoren geändert, um sie an Werte vom Typ Map anzupassen.
Die obige Abbildung zeigt die Top-5-Join-Schlüsselwerte der beiden Join-Tabellen, wobei der Schlüssel das ID-Feld ist und es 3 Zeilen mit ID = 1 gibt.
Nach einer Reihe von Untersuchungen und Tests haben wir festgestellt, dass Spark SQL im Vergleich zu Hive eine deutlich verbesserte Leistung und Ressourcennutzung aufweist. Bei der Migration von Hive SQL zu Spark sind jedoch auch viele Probleme aufgetreten. Durch einige Kompatibilitätsänderungen und Anpassungen am Spark SQL-Dienst konnten wir die meisten Hive SQL-Aufgaben erfolgreich auf Spark migrieren.
Bei der Unterstützung von Hive UDF durch Spark SQL treten bei der tatsächlichen Verwendung einige Probleme auf. Beispielsweise verwenden Unternehmen häufig die Reflect-Funktion, um statische Java-Methoden zur Verarbeitung von Daten aufzurufen. Wenn im Reflection-Aufruf eine Ausnahme auftritt, gibt Hive einen NULL-Wert zurück und Spark SQL löst eine Ausnahme aus und führt dazu, dass die Aufgabe fehlschlägt. Zu diesem Zweck haben wir die Reflect-Funktion von Spark geändert, um Ausnahmen von Reflection-Aufrufen zu erfassen und NULL-Werte zurückzugeben, im Einklang mit Hive.
Ein weiteres Problem besteht darin, dass Spark SQL den privaten Konstruktor von Hive UDAF nicht unterstützt, was dazu führt, dass die UDAF einiger Unternehmen nicht initialisiert werden kann. Wir haben die Funktionsregistrierungslogik von Spark geändert, um private Hive-UDAF-Konstruktoren zu unterstützen.
-
Integrierte Funktionskompatibilität
Es gibt Unterschiede in der Berechnungslogik der integrierten Funktion GROUPING_ID zwischen Spark SQL und Hive Version 1.2, was zu Dateninkonsistenzen während der Dual-Run-Phase führt. In der Hive-Version 3.1 wurde die Berechnungslogik dieser Funktion geändert, um mit der Logik von Spark übereinzustimmen. Daher empfehlen wir Benutzern, die SQL-Logik zu aktualisieren und die Logik dieser Funktion in Spark anzupassen, um die Richtigkeit der Berechnungslogik sicherzustellen.
Darüber hinaus verwendet die Hash-Funktion von Spark SQL den Murmur3-Hash-Algorithmus, der sich von der Implementierungslogik von Hive unterscheidet. Wir empfehlen Benutzern, die integrierte Hash-Funktion von Hive manuell zu registrieren, um die Datenkonsistenz vor und nach der Migration sicherzustellen.
-
Kompatibilität der Typkonvertierung
Spark SQL hat die ANSI SQL-Spezifikation seit Version 3.0 eingeführt. Im Vergleich zu Hive SQL gelten strengere Anforderungen an die Typkonsistenz. Beispielsweise ist die automatische Konvertierung zwischen String- und numerischen Typen verboten. Um automatische Konvertierungsanomalien zu vermeiden, die durch nicht standardmäßige Datentypdefinitionen im Unternehmen verursacht werden, empfehlen wir Benutzern, CAST zu SQL für die explizite Konvertierung hinzuzufügen. Bei umfangreichen Transformationen kann die Konfiguration spark.sql.storeAssignmentPolicy=LEGACY vorübergehend hinzugefügt werden Reduzieren Sie die Typprüfung auf Spark SQL-Ebene, um Migrationsausnahmen zu vermeiden.
Die Funktion str_to_map in Hive behält automatisch den letzten Wert für wiederholte Schlüssel bei, während in Spark eine Ausnahme ausgelöst wird und die Aufgabe fehlschlägt. In diesem Zusammenhang empfehlen wir Benutzern, die Qualität der Upstream-Daten zu prüfen oder die Konfiguration spark.sql.mapKeyDedupPolicy=LAST_WIN hinzuzufügen, um den letzten doppelten Wert im Einklang mit Hive beizubehalten.
-
Andere Syntaxkompatibilität
Die Hint-Syntax von Spark SQL und Hive SQL ist nicht kompatibel und Benutzer müssen relevante Konfigurationen während der Migration manuell löschen. Zu den allgemeinen Hive-Hinweisen gehört die Übertragung kleiner Tabellen. Da die Spark AQE-Funktion intelligenter für die Übertragung kleiner Tabellen und die Optimierung der Task-Neigung ist, ist für den Benutzer normalerweise keine zusätzliche Konfiguration erforderlich.
Es gibt auch einige Kompatibilitätsprobleme zwischen Spark SQL und den DDL-Anweisungen von Hive. Wir empfehlen Benutzern normalerweise, die Plattform zu verwenden, um DDL-Operationen an Hive-Tabellen durchzuführen. Für einige Partitionsoperationsbefehle, wie zum Beispiel: Löschen nicht vorhandener Partitionen [KYUUBI-1583], ungleiche Alter Partition-Anweisungen und andere Kompatibilitätsprobleme, haben wir aus Kompatibilitätsgründen auch das Spark-Plug-in erweitert.
Zusammenfassung und Ausblick
Derzeit haben wir die meisten Hive-Aufgaben im Unternehmen auf Spark migriert, sodass Spark zur wichtigsten Offline-Verarbeitungs-Engine von iQiyi geworden ist. Wir haben vorläufige Ressourcenaudits und Leistungsoptimierungsarbeiten an der Spark-Engine abgeschlossen, was dem Unternehmen erhebliche Einsparungen brachte. Auch in Zukunft werden wir die Leistung und Stabilität der Spark-Dienste und Computing-Frameworks weiter optimieren. Außerdem werden wir die Migration der wenigen verbliebenen Hive-Aufgaben weiter vorantreiben.
Mit der Implementierung des Data Lake des Unternehmens migrieren immer mehr Unternehmen auf den Iceberg Data Lake. Da Iceberg die Funktionen von Spark DataSourceV2 weiter verbessert, kann Spark 3.1 einige neue Anforderungen an die Data-Lake-Analyse nicht mehr erfüllen. Daher stehen wir kurz vor einem Upgrade auf Spark 3.4. Gleichzeitig haben wir auch Untersuchungen zu einigen neuen Funktionen durchgeführt, z. B. Laufzeitfilter, speicherpartitionierter Join usw., in der Hoffnung, die Leistung des Spark-Computing-Frameworks basierend auf den Geschäftsanforderungen weiter zu verbessern.
Um den Prozess des Cloud-nativen Big Data Computing zu fördern, haben wir außerdem Apache Uniffle eingeführt, einen Remote Shuffle Service (RSS). Während der Verwendung haben wir festgestellt, dass es in Kombination mit Spark AQE zu Leistungsproblemen kommt, wie z. B. der BroadcastHashJoin-Skew-Optimierung [SPARK-44065], dem zuvor erwähnten Problem mit großen Partitionen und der Frage, wie die AQE-Partitionsplanung besser durchgeführt werden kann. Wir werden weiter daran arbeiten Dies wird in Zukunft zu einer tiefergehenden Forschung und Optimierung führen.
Vielleicht möchten Sie es auch sehen

