
01
zurückSzeneund Status Quo
1. Eigenschaften von Daten im Werbebereich
Daten im Werbebereich können in kontinuierliche Wertmerkmale und diskrete Wertmerkmale unterteilt werden. Im Gegensatz zu KI-Bild-, Video-, Sprach- und anderen Feldern werden die Originaldaten im Werbebereich meist in Form von IDs dargestellt, z. B. Benutzer-ID, Werbe-ID, Werbe-ID-Sequenz, die mit dem Benutzer interagiert usw., und die ID Der Maßstab ist groß und bildet das Werbefeld. Die charakteristischen Merkmale hochdimensionaler spärlicher Daten.
-
Es gibt sowohl statische (z. B. das Alter des Nutzers) als auch dynamische Merkmale, die auf dem Nutzerverhalten basieren (z. B. die Häufigkeit, mit der ein Nutzer auf eine Anzeige in einer bestimmten Branche klickt). -
Der Vorteil besteht darin, dass es über eine gute Generalisierungsfähigkeit verfügt. Die Präferenz eines Benutzers für eine Branche kann auf andere Benutzer übertragen werden, die dieselben statistischen Merkmale der Branche aufweisen. -
Der Nachteil besteht darin, dass die mangelnde Gedächtnisleistung zu einer geringen Diskriminierung führt. Beispielsweise können zwei Benutzer mit denselben statistischen Merkmalen erhebliche Unterschiede im Verhalten aufweisen. Darüber hinaus erfordern Features mit kontinuierlichem Wert auch viel manuelles Feature-Engineering.
-
Diskret bewertete Features sind feinkörnige Features. Es gibt aufzählbare (z. B. Benutzergeschlecht, Branchen-ID) und es gibt auch hochdimensionale (z. B. Benutzer-ID, Werbe-ID). -
Der Vorteil besteht darin, dass es über ein starkes Gedächtnis und eine hohe Unterscheidungskraft verfügt. Diskrete Wertmerkmale können auch kombiniert werden, um übergreifende und kollaborative Informationen zu lernen. -
Der Nachteil besteht darin, dass die Generalisierungsfähigkeit relativ schwach ist.
-
One-Hot-Codierung -
Feature-Einbettung (Einbettung)
-
Funktionskonflikt: Wenn vocabulary_size zu groß eingestellt ist, sinkt die Trainingseffizienz stark und das Training schlägt aufgrund von Speicher-OOM fehl. Daher richten wir selbst für diskrete Wertfunktionen mit Benutzer-IDs auf Milliardenebene nur einen ID-Hash-Bereich mit 100.000 Ebenen ein. Die Hash-Konfliktrate ist hoch, die Feature-Informationen sind beschädigt und es gibt keinen positiven Nutzen aus der Offline-Bewertung. -
Ineffiziente E/A: Da Funktionen wie Benutzer-ID und Werbe-ID hochdimensional und spärlich sind, machen die während des Trainings aktualisierten Parameter nur einen kleinen Teil der Gesamtmenge aus. Unter dem ursprünglichen statischen Einbettungsmechanismus von TensorFlow muss der Modellzugriff verarbeitet werden Der gesamte dichte Tensor verursacht einen enormen E/A-Aufwand und kann das Training spärlicher großer Modelle nicht unterstützen.
02
Werbung spärlich große Modellpraxis
-
Die TFRA-API ist mit dem Tensorflow-Ökosystem kompatibel (durch die Wiederverwendung des ursprünglichen Optimierers und Initialisierers hat die API denselben Namen und ein konsistentes Verhalten), wodurch TensorFlow das Training und die Inferenz von spärlichen großen Modellen vom Typ ID auf nativere Weise unterstützen kann Die Lern- und Nutzungskosten sind gering und ändern nicht die Modellierungsgewohnheiten von Algorithmeningenieuren. -
Die dynamische Speichererweiterung und -kontraktion spart Ressourcen während des Trainings; sie vermeidet effektiv Hash-Konflikte und stellt sicher, dass Feature-Informationen verlustfrei sind.
-
Statische Einbettung wird auf dynamische Einbettung aktualisiert: Für die künstliche Hash-Logik diskreter Wertmerkmale wird die dynamische TFRA-Einbettung zum Speichern, Zugreifen und Aktualisieren von Parametern verwendet, wodurch sichergestellt wird, dass die Einbettung aller diskreten Wertmerkmale im Algorithmus-Framework konfliktfrei ist Sicherstellen, dass alle diskreten Werte verlustfreies Lernen von Funktionen sind. -
Verwendung hochdimensionaler, spärlicher ID-Funktionen: Wie oben erwähnt, haben Benutzer-ID- und Werbe-ID-Funktionen bei Verwendung der statischen Einbettungsfunktion von TensorFlow aufgrund von Hash-Konflikten keinen Gewinn bei der Offline-Auswertung. Nach der Aktualisierung des Algorithmus-Frameworks werden die Benutzer-ID- und Werbe-ID-Funktionen wieder eingeführt, und es gibt sowohl offline als auch online positive Vorteile. -
Die Verwendung hochdimensionaler, spärlicher kombinierter ID-Funktionen: Einführung der kombinierten diskreten Wertfunktionen der Benutzer-ID und der grobkörnigen Werbe-ID, z. B. die Kombination der Benutzer-ID mit der Branchen-ID bzw. dem Namen des App-Pakets. Gleichzeitig werden in Kombination mit der Feature-Zugriffsfunktion diskrete Features eingeführt, die eine Kombination aus spärlicheren Benutzer-IDs und Werbe-IDs verwenden.

2. Modellaktualisierung
-
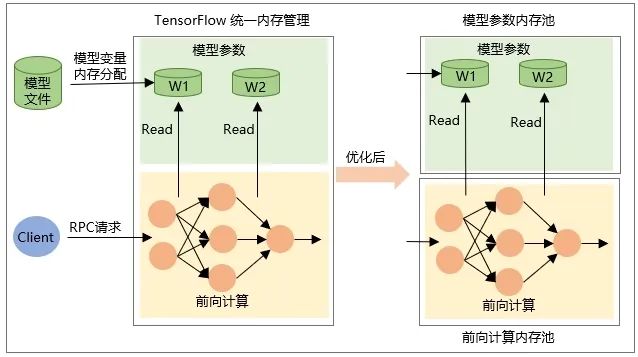
Die Zuordnung der Tensorvariablen selbst erfolgt beim Wiederherstellen des Modells, dh der Speicher wird beim Laden des Modells zugewiesen und der Speicher beim Entladen des Modells freigegeben. -
Der Speicher des Zwischenausgabe-Tensors wird während der Netzwerkvorwärtsberechnung während der RPC-Anfrage zugewiesen und nach Abschluss der Anforderungsverarbeitung freigegeben.
03
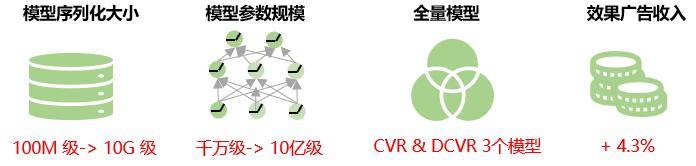
Gesamtnutzen
04
Zukunftsausblick
Derzeit erhalten alle Merkmalswerte desselben Merkmals im Sparse-Modell für große Werbung die gleiche Einbettungsdimension. In der Praxis ist die Datenverteilung hochdimensionaler Merkmale extrem ungleichmäßig, eine sehr kleine Anzahl hochfrequenter Merkmale macht einen sehr hohen Anteil aus und das Long-Tail-Phänomen ist schwerwiegend verringert die Fähigkeit zum Einbetten von Repräsentationslernen. Das heißt, für Merkmale mit niedriger Häufigkeit ist die Einbettungsdimension zu groß und das Modell läuft Gefahr, für Merkmale mit hoher Häufigkeit überzupassen, da es eine Fülle von Informationen gibt, die dargestellt und erlernt werden müssen, die Einbettung Die Dimension ist zu klein und es besteht die Gefahr einer Unteranpassung des Modells. Daher werden wir in Zukunft nach Möglichkeiten suchen, die Feature-Einbettungsdimension adaptiv zu lernen, um die Genauigkeit der Modellvorhersage weiter zu verbessern.
Gleichzeitig werden wir die Lösung des inkrementellen Exports des Modells untersuchen, das heißt, nur die Parameter, die sich während des inkrementellen Trainings ändern, in TensorFlow Serving laden, wodurch die Netzwerkübertragungs- und Ladezeit während der Modellaktualisierung reduziert wird und Aktualisierungen auf Minutenebene erreicht werden von spärlichen großen Modellen und Verbesserung der Echtzeitnatur des Modells.

iQIYI Performance Advertising Dual Bidding Optimierungsprozess
Dieser Artikel wurde vom öffentlichen WeChat-Konto geteilt – iQIYI Technology Product Team (iQIYI-TP).
Bei Verstößen wenden Sie sich bitte zur Löschung an [email protected].
Dieser Artikel ist Teil des „ OSC Source Creation Plan “. Alle, die ihn lesen, sind herzlich eingeladen, mitzumachen und ihn gemeinsam zu teilen.
{{o.name}}
{{m.name}}