
Dieser Artikel basiert auf einer Rede von Shao Wei, leitender Forschungs- und Entwicklungsingenieur von Volcano Engine, auf der QCon Global Software Development Conference. Redner|Shao Weis Redezeit|QCon Guangzhou im Mai 2023
PPT |. Katalyst: ByteDance Cloud Native Kostenoptimierungspraxis
1. Hintergrund
Byte hat seit 2016 damit begonnen, seine Dienste in Cloud-native Dienste umzuwandeln. Bis heute umfasst das Dienstsystem von Byte hauptsächlich vier Kategorien: Traditionelle Mikrodienste sind meist RPC-Webdienste auf Basis von Golang; der Promotion-Suchdienst ist ein traditioneller C++-Dienst mit höherer Leistung Darüber hinaus gibt es auch maschinelles Lernen, Big Data und verschiedene Speicherdienste .
Das Kernproblem, das nach Cloud Native gelöst werden muss, besteht darin, die Ressourcennutzungseffizienz des Clusters zu verbessern. Am Beispiel der Ressourcennutzung eines typischen Online-Dienstes ist der dunkelblaue Teil die Menge der tatsächlich vom Unternehmen genutzten Ressourcen Der hellblaue Teil ist der vom Geschäftsbereich bereitgestellte Sicherheitspuffer. Auch wenn der Pufferbereich vergrößert wird, gibt es immer noch viele Ressourcen, die vom Unternehmen beantragt, aber nicht genutzt wurden. Daher liegt der Optimierungsschwerpunkt darin, diese ungenutzten Ressourcen aus architektonischer Sicht so weit wie möglich zu nutzen.
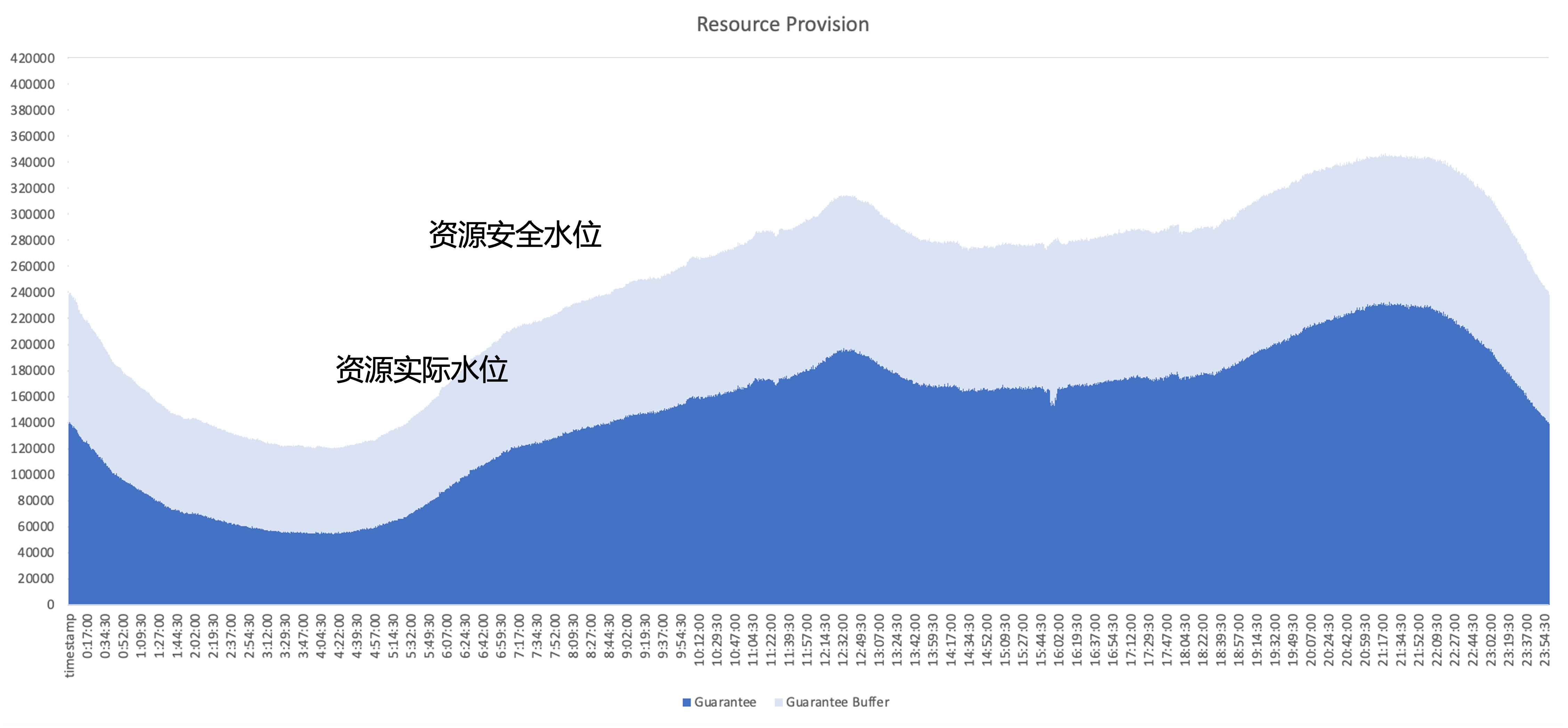
Ressourcenmanagementplan
Byte hat intern verschiedene Arten von Ressourcenmanagementlösungen ausprobiert, darunter
- Ressourcenbetrieb: Helfen Sie dem Unternehmen regelmäßig bei der Verwaltung des Ressourcennutzungsstatus und fördern Sie das Ressourcenanwendungsmanagement. Das Problem besteht darin, dass der Betriebs- und Wartungsaufwand hoch ist und das Nutzungsproblem nicht gelöst werden kann.
- Dynamische Überbuchung: Bewerten Sie die Menge der Geschäftsressourcen auf der Systemseite und reduzieren Sie die Quote proaktiv. Das Problem besteht darin, dass die Überbuchungsstrategie nicht unbedingt korrekt ist und zu einem Run-Risiko führen kann.
- Dynamische Skalierung: Das Problem besteht darin, dass die Auslastung im Laufe des Tages nicht vollständig verbessert werden kann, wenn Sie die Skalierung nur auf Online-Dienste ausrichten, da die Spitzen und Tiefpunkte des Datenverkehrs bei Online-Diensten ähnlich sind.
Daher setzt Byte letztendlich auf eine Hybridbereitstellung, die gleichzeitig online und offline auf demselben Knoten ausgeführt wird und dabei die komplementären Eigenschaften zwischen Online- und Offline-Ressourcen voll ausnutzt, um letztendlich eine bessere Ressourcennutzung zu erzielen , das heißt, Sekundärverkäufe erfolgen online. Ungenutzte Ressourcen können gut durch Offline-Arbeitslasten aufgefüllt werden, um die Effizienz der Ressourcennutzung den ganzen Tag über auf einem hohen Niveau zu halten.
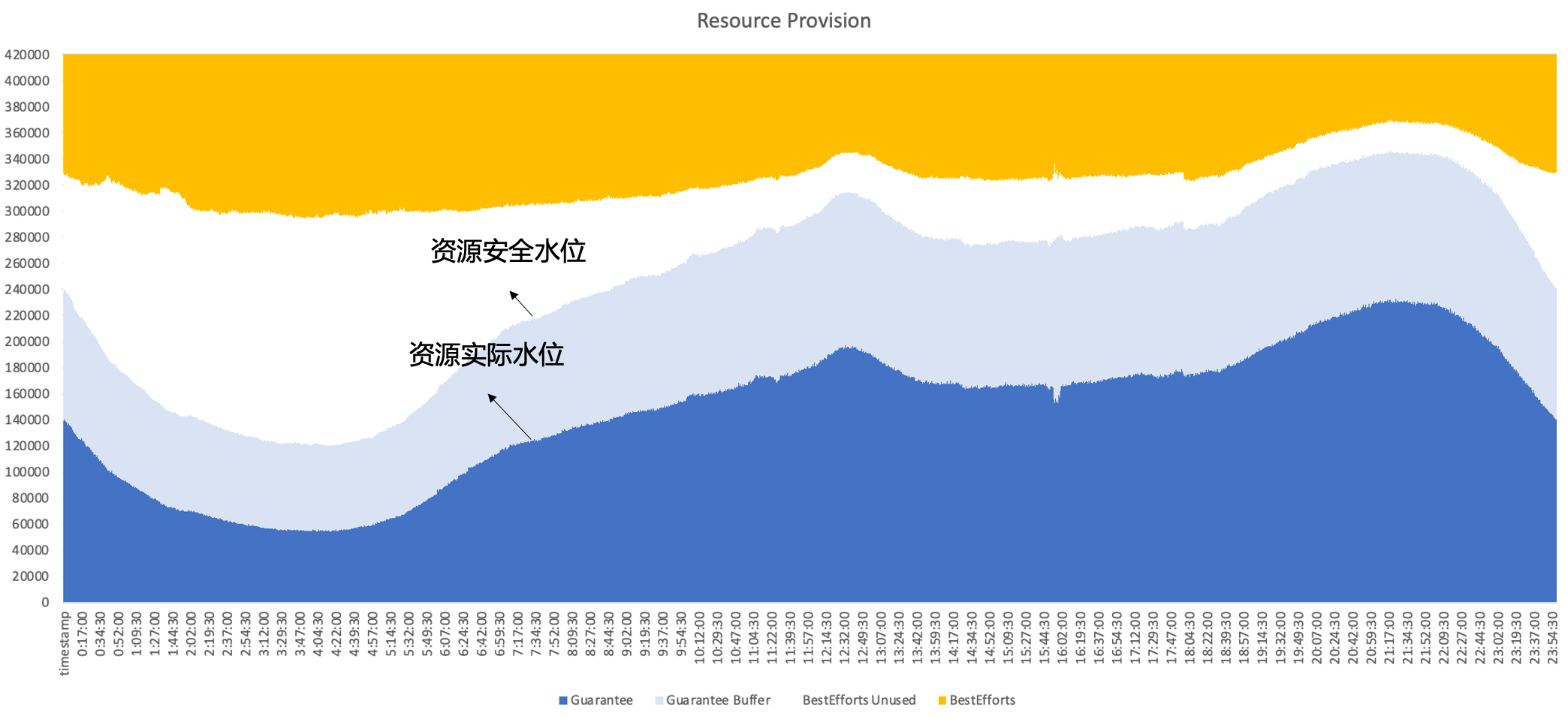
2. Entwicklungsgeschichte der Byte-Hybrid-Bereitstellung
Wenn Byte Cloud nativ wird, wählen wir in verschiedenen Phasen geeignete Hybrid-Bereitstellungslösungen basierend auf den Geschäftsanforderungen und technischen Merkmalen aus und iterieren dabei unser Hybridsystem weiter.
2.1 Phase 1: Offline-Time-Sharing-Mischbereitstellung
Die erste Phase umfasst hauptsächlich den Online- und Offline-Time-Sharing-Hybrideinsatz.
- Online: In dieser Phase haben wir eine Online-Service-Elastizitätsplattform erstellt. Benutzer können horizontale Skalierungsregeln basierend auf Geschäftsindikatoren konfigurieren. Wenn der Geschäftsverkehr beispielsweise am frühen Morgen abnimmt und das Unternehmen einige Instanzen proaktiv verkleinert, führt das System eine geringere Leistung aus Bing-Packung auf Basis der Instanzschrumpfung. Dadurch wird die gesamte Maschine entlastet.
- Für Offline: In diesem Stadium können Offline-Dienste eine große Anzahl von Spot-Ressourcen erhalten, und da ihr Angebot instabil ist, können sie gleichzeitig einen gewissen Rabatt auf die Kosten genießen, während sie online ungenutzte Ressourcen an Offline-Dienste verkaufen können einen gewissen Rabatt auf die Kosten erhalten.
Der Vorteil dieser Lösung besteht darin, dass kein komplexer Einzelmaschinen-Isolationsmechanismus erforderlich ist und die technische Implementierung relativ gering ist. Es gibt jedoch auch einige Probleme, wie z
- Die Umwandlungseffizienz ist nicht hoch und während des Bing-Packungsprozesses können Probleme wie Fragmentierung auftreten.
- Auch das Offline-Erlebnis ist möglicherweise nicht gut. Wenn der Online-Verkehr gelegentlich schwankt, kann es sein, dass der Offline-Benutzer gewaltsam getötet wird, was zu starken Ressourcenschwankungen führt.
- Dies führt zu Instanzänderungen im Unternehmen. Im tatsächlichen Betrieb konfiguriert das Unternehmen normalerweise eine relativ konservative elastische Richtlinie, was zu einer niedrigen Obergrenze für die Ressourcenverbesserung führt.
2.2 Phase 2: Gemeinsame Bereitstellung von Kubernetes/YARN
Um die oben genannten Probleme zu lösen, sind wir in die zweite Phase eingetreten und haben versucht, auf einem Knoten offline und online zu laufen.
Da der Online-Teil früher nativ auf Basis von Kubernetes transformiert wurde, werden die meisten Offline-Jobs immer noch auf Basis von YARN ausgeführt. Um die Hybridbereitstellung zu fördern, führen wir Komponenten von Drittanbietern auf einem einzigen Computer ein, um die Menge der koordinierten Ressourcen online und offline zu bestimmen, und verbinden sie gleichzeitig mit eigenständigen Komponenten wie Kubelet oder Node Manager Online- und Offline-Workloads werden für Knoten geplant und auch koordiniert. Die Koordinationskomponente aktualisiert asynchron die Ressourcenzuweisungen für beide Workloads.
Dieser Plan ermöglicht es uns, die Reserveakkumulation von Co-Location-Fähigkeiten abzuschließen und die Machbarkeit zu überprüfen, es gibt jedoch immer noch einige Probleme
- Die beiden Systeme werden asynchron ausgeführt, sodass der Offline-Container nur die Verwaltung und Kontrolle umgehen kann und es zu einem Wettlauf und zu großen Ressourcenverlusten in den Zwischenverbindungen kommt.
- Die einfache Abstraktion von Offline-Workloads hindert uns daran, komplexe QoS-Anforderungen zu beschreiben
- Die Fragmentierung von Offline-Metadaten erschwert eine extreme Optimierung und kann keine globale Planungsoptimierung erreichen.
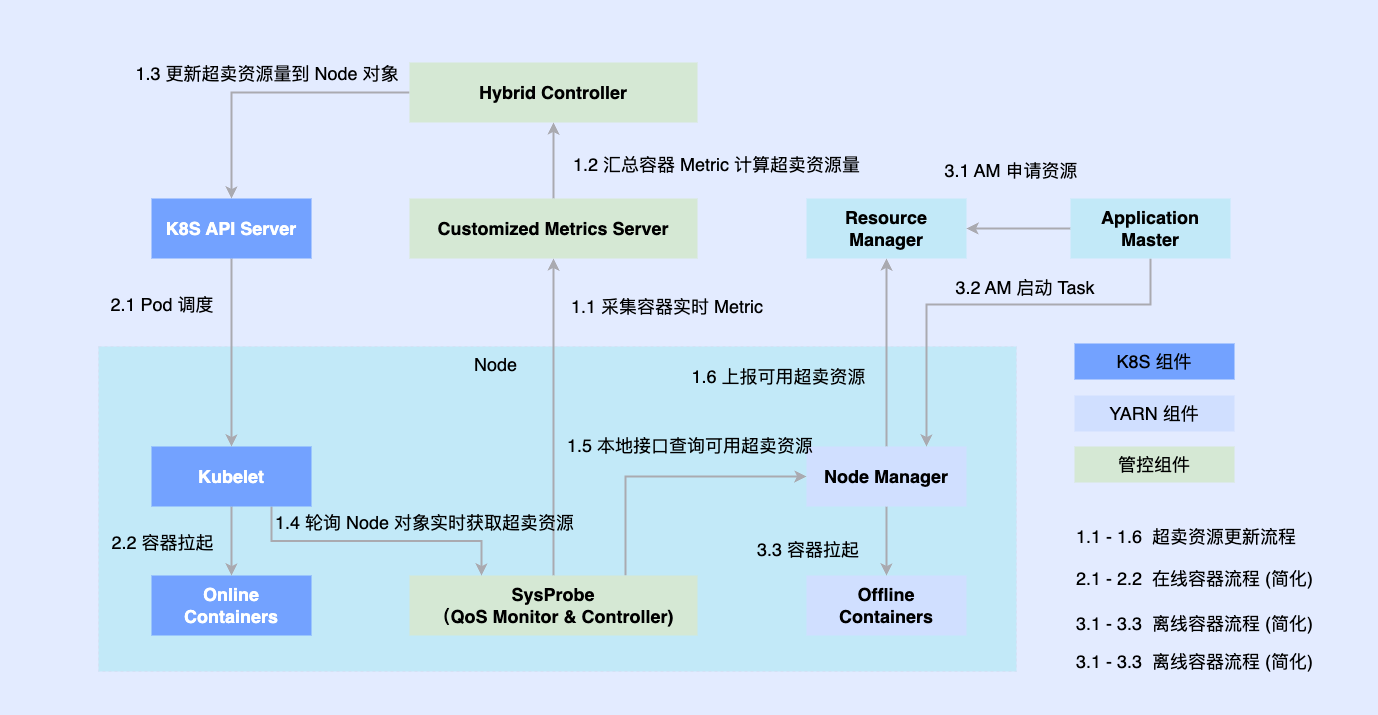
2.3 Phase 3: Einheitliche Planung und gemischte Offline-Bereitstellung
Um die Probleme in der zweiten Phase zu lösen, haben wir in der dritten Phase eine einheitliche Offline-Hybridbereitstellung vollständig realisiert.
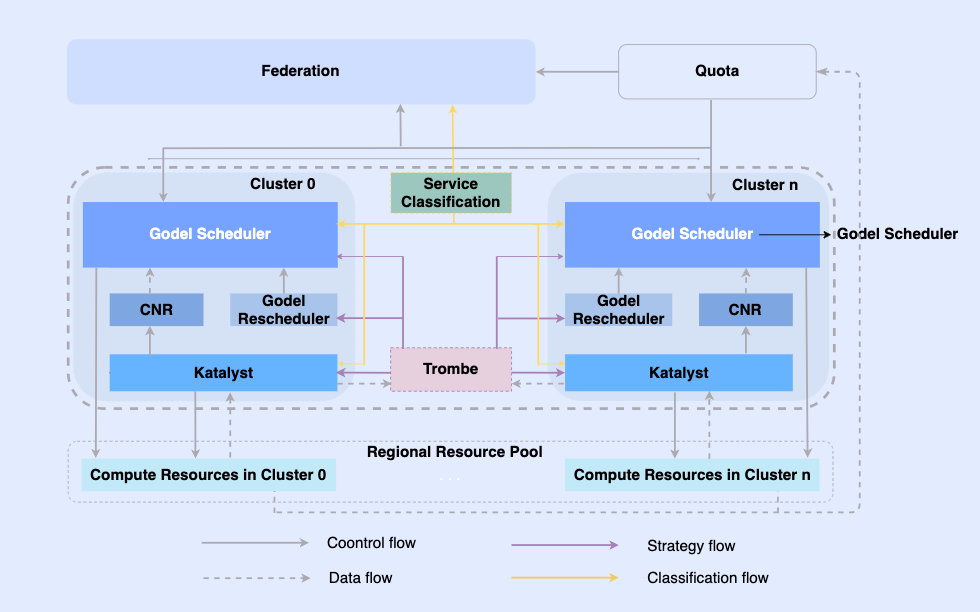
Indem wir Offline-Jobs cloudnativ machen, ermöglichen wir deren Planung und Ressourcenverwaltung auf derselben Infrastruktur. In diesem System ist die oberste Ebene ein einheitlicher Ressourcenverbund, um die Ressourcenverwaltung mit mehreren Clustern zu realisieren. In einem einzelnen Cluster gibt es einen zentralen einheitlichen Scheduler und einen eigenständigen einheitlichen Ressourcenmanager. Sie arbeiten zusammen, um integrierte Offline-Ressourcenverwaltungsfunktionen zu erreichen .
In dieser Architektur dient Katalyst als zentrale Ressourcenverwaltungs- und Kontrollschicht und ist für die Realisierung der Ressourcenzuweisung und -schätzung in Echtzeit auf der Einzelmaschinenseite verantwortlich. Es weist die folgenden Eigenschaften auf
- Abstraktionsstandardisierung: Öffnen Sie Offline-Metadaten, machen Sie die QoS-Abstraktion komplexer und umfangreicher und erfüllen Sie die Anforderungen an die Geschäftsleistung besser.
- Verwaltungs- und Kontrollsynchronisierung: Die Verwaltungs- und Kontrollrichtlinie wird beim Starten des Containers ausgegeben, um eine asynchrone Korrektur von Ressourcenanpassungen nach dem Start zu vermeiden und gleichzeitig die freie Erweiterung der Richtlinie zu unterstützen.
- Intelligente Strategie: Durch die Erstellung von Serviceporträts können Sie den Ressourcenbedarf im Voraus erkennen und intelligentere Ressourcenmanagement- und Kontrollstrategien umsetzen.
- Betriebs- und Wartungsautomatisierung: Durch integrierte Lieferung werden Betriebs- und Wartungsautomatisierung und Standardisierung erreicht.
3. Einführung in das Katalyst-System
Katalyst leitet sich vom englischen Wort „Catalyst“ ab, was ursprünglich „Katalysator“ bedeutet. Der erste Buchstabe wird in „K“ geändert, was bedeutet, dass das System leistungsfähigere automatisierte Ressourcenverwaltungsfunktionen für alle im Kubernetes-System ausgeführten Lasten bereitstellen kann.
3.1 Übersicht über das Katalysatorsystem
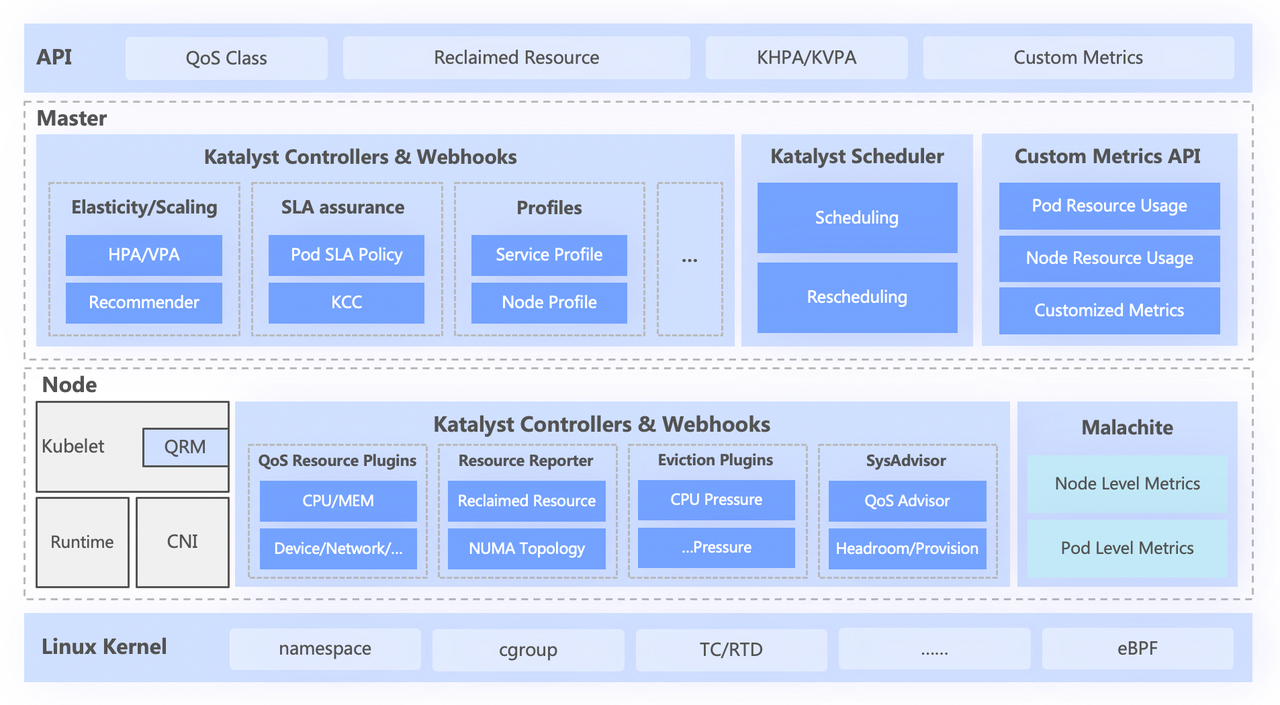
Das Katalyst-System ist grob in vier Schichten unterteilt, darunter
- Die Standard-API der obersten Ebene abstrahiert verschiedene QoS-Ebenen für Benutzer und bietet umfassende Ressourcenausdrucksfunktionen.
- Die zentrale Ebene ist für grundlegende Funktionen wie einheitliche Terminplanung, Ressourcenempfehlung und Gebäudeservice-Portraits verantwortlich;
- Die eigenständige Schicht umfasst ein selbst entwickeltes Datenüberwachungssystem und einen Ressourcenzuteiler, der für die Echtzeitzuweisung und dynamische Anpassung von Ressourcen verantwortlich ist;
- Die unterste Ebene ist ein byte-angepasster Kernel, der das Problem der Einzelmaschinenleistung bei der Offline-Ausführung löst, indem er den Kernel-Patch und den zugrunde liegenden Isolationsmechanismus verbessert.
3.2 Abstrakte Standardisierung: QoS-Klasse
Katalyst QoS kann sowohl aus Makro- als auch aus Mikroperspektive interpretiert werden
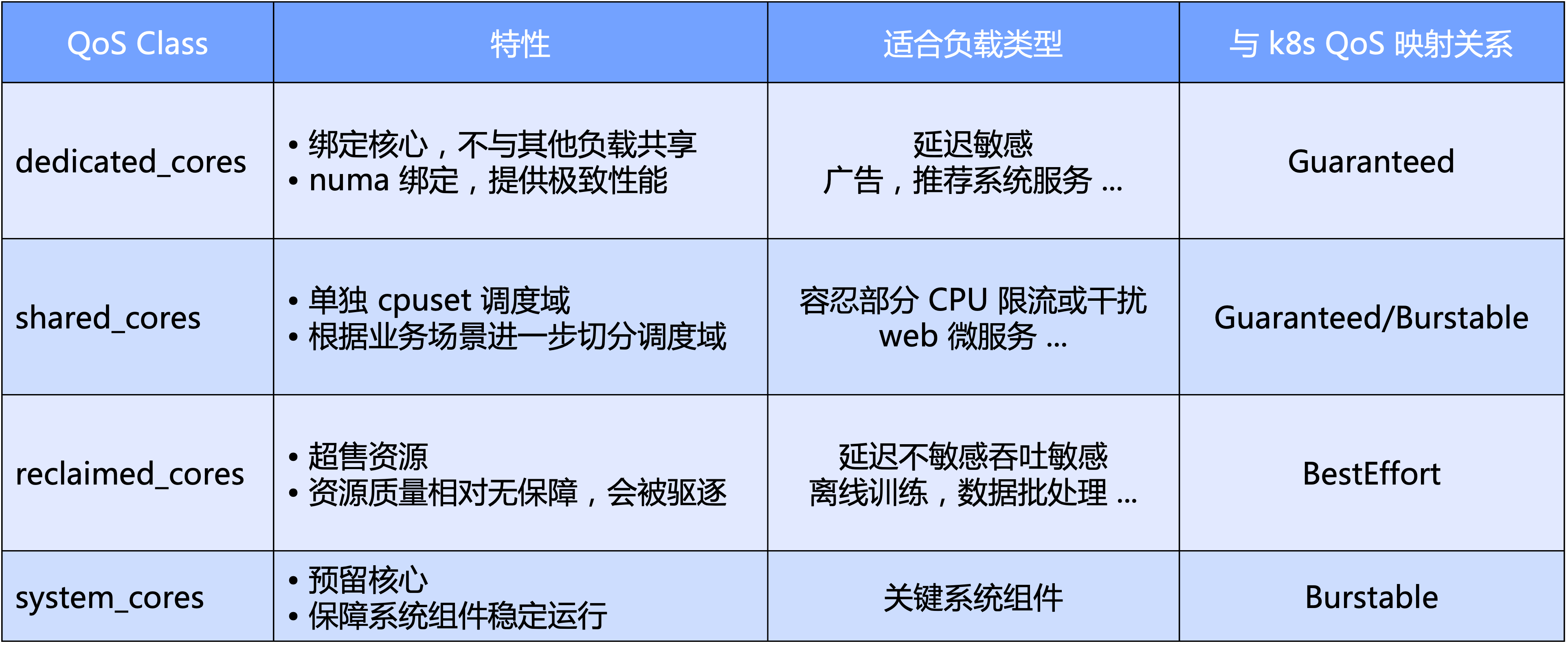
- Auf Makroebene definiert Katalyst Standard-QoS-Stufen basierend auf der Hauptdimension der CPU. Konkret unterteilen wir QoS in vier Kategorien: exklusiv, gemeinsam genutzt, Recycling und Systemtyp, der für wichtige Systemkomponenten reserviert ist;
- Aus Mikrosicht besteht die endgültige Erwartung von Katalyst darin, dass es unabhängig von der Art der Arbeitslast in einem Pool auf demselben Knoten ausgeführt werden kann, ohne dass der Cluster durch hartes Schneiden isoliert werden muss, wodurch eine bessere Effizienz des Ressourcenverkehrs und eine bessere Ressourcennutzung erreicht werden Effizienz.
Auf Basis von QoS bietet Katalyst außerdem zahlreiche Erweiterungserweiterungen, um neben den CPU-Kernen auch andere Ressourcenanforderungen auszudrücken.
- QoS-Verbesserung: Erweiterter Ausdruck von Geschäftsanforderungen für mehrdimensionale Ressourcen wie NUMA/Netzwerkkartenbindung, Netzwerkkarten-Bandbreitenzuweisung, IO-Gewichtung usw.
- Pod-Verbesserung: Erweitert den Ausdruck der Sensibilität des Unternehmens auf verschiedene Systemindikatoren, z. B. die Auswirkung der CPU-Planungsverzögerung auf die Geschäftsleistung
- Knotenverbesserung: Drücken Sie die kombinierten Anforderungen der Mikrotopologie über mehrere Ressourcendimensionen hinweg aus, indem Sie die native TopologyPolicy erweitern
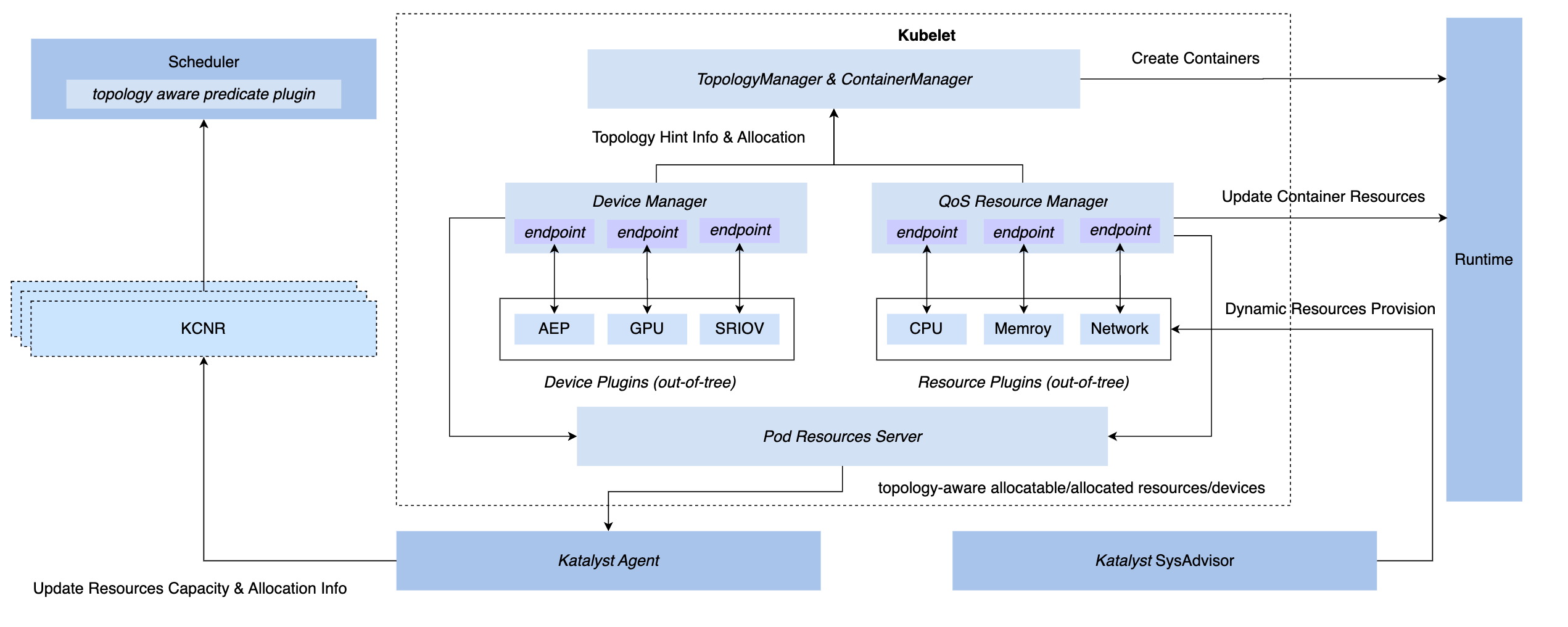
3.3 Verwaltungs- und Kontrollsynchronisierung: QoS Resource Manager
Um synchrone Verwaltungs- und Steuerungsfunktionen unter dem K8s-System zu erreichen, verfügen wir über drei Hook-Methoden: CRI-Schicht-Einfügung, OCI-Schicht und Kubelet-Schicht. Am Ende entschied sich Katalyst für die Implementierung von Verwaltung und Steuerung auf der Kubelet-Seite, d. h. einen QoS-Ressourcenmanager auf der gleichen Ebene wie der native Gerätemanager zu implementieren. Zu den Vorteilen dieses Programms gehören
- Implementieren Sie das Abfangen während der Zulassungsphase, sodass Sie sich in den nachfolgenden Schritten nicht mehr auf verdeckte Maßnahmen verlassen müssen, um die Kontrolle zu erlangen.
- Verbinden Sie Metadaten mit Kubelet, melden Sie Informationen zur Mikrotopologie einer einzelnen Maschine über die Standardschnittstelle an Knoten-CRD und realisieren Sie das Andocken an den Scheduler
- Basierend auf diesem Framework können steckbare Plugins flexibel implementiert werden, um individuelle Verwaltungs- und Kontrollanforderungen zu erfüllen.
3.4 Intelligente Strategie: Serviceporträt und Ressourcenschätzung
Normalerweise ist es intuitiver, sich für die Verwendung von Geschäftsindikatoren zu entscheiden, um ein Serviceporträt zu erstellen, wie z. B. die Service-P99-Verzögerung oder die Downstream-Fehlerrate. Es gibt jedoch auch einige Probleme. Im Vergleich zu Systemindikatoren ist es beispielsweise normalerweise schwieriger, mehrere Frameworks zu integrieren, und die Bedeutung der von ihnen erstellten Geschäftsindikatoren ist nicht genau gleich Wenn man sich stark auf diese Indikatoren verlässt, wird die gesamte Steuerung sehr kompliziert.
Daher hoffen wir, dass die endgültige Ressourcenkontrolle oder das Serviceporträt auf Systemindikatoren und nicht auf Geschäftsindikatoren basiert. Die wichtigste Frage besteht darin, die Systemindikatoren zu finden, die dem Unternehmen am meisten am Herzen liegen. Unser Ansatz besteht darin, eine Reihe von Offline-Indikatoren zu verwenden Pipelines zur Ermittlung von Geschäftsindikatoren und Systemindikatoren. Für den Dienst in der Abbildung ist der Kerngeschäftsindikator beispielsweise die P99-Verzögerung. Durch Analyse wurde festgestellt, dass der Systemindikator mit der höchsten Korrelation die CPU-Planungsverzögerung ist. Wir werden die Ressourcenversorgung des Dienstes weiterhin anpassen Sein Ziel ist es, die CPU-Planung so weit wie möglich zu verzögern.
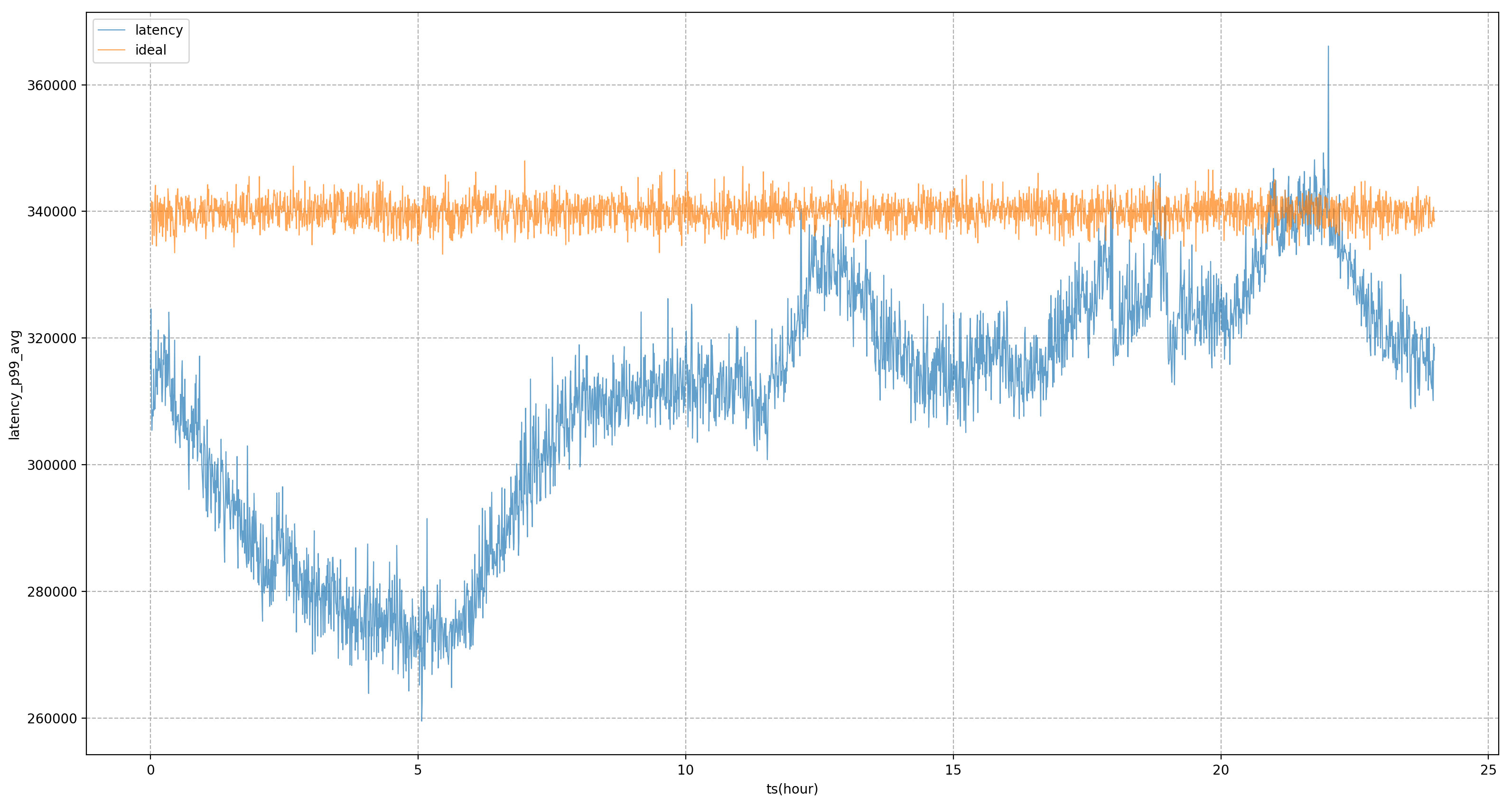
Auf der Grundlage von Dienstporträts bietet Katalyst umfassende Isolationsmechanismen für CPU, Speicher, Festplatte und Netzwerk und passt den Kernel bei Bedarf an, um höhere Leistungsanforderungen zu erfüllen. Diese Mittel sind jedoch nicht unbedingt anwendbar Es muss betont werden, dass Isolation eher ein Mittel als ein Zweck ist. Im Geschäftsprozess müssen wir je nach spezifischen Bedürfnissen und Szenarien unterschiedliche Isolationslösungen auswählen.
3.5 Betriebs- und Wartungsautomatisierung: mehrdimensionales dynamisches Konfigurationsmanagement
Obwohl wir hoffen, dass sich alle Ressourcen in einem Ressourcenpoolsystem befinden, ist es in einer großen Produktionsumgebung unmöglich, alle Knoten in einem Cluster zusammenzufassen. Darüber hinaus kann ein Cluster sowohl CPU- als auch GPU-Maschinen haben, obwohl die Steuerungsebene dies kann gemeinsam genutzt werden, auf der Datenebene ist jedoch eine gewisse Isolation erforderlich. Auf der Knotenebene müssen wir häufig die Knotendimensionskonfiguration für die Graustufenüberprüfung ändern, was zu Unterschieden in den SLOs verschiedener Dienste führt, die auf demselben Knoten ausgeführt werden.
Um diese Probleme zu lösen, müssen wir die Auswirkungen unterschiedlicher Knotenkonfigurationen auf Dienste während der Geschäftsbereitstellung berücksichtigen. Zu diesem Zweck bietet Katalyst dynamische Konfigurationsverwaltungsfunktionen für die Standardbereitstellung, die die Leistung und Konfiguration verschiedener Knoten mithilfe automatisierter Methoden bewerten und auf der Grundlage dieser Ergebnisse den am besten geeigneten Knoten für den Dienst auswählen.
4. Katalyst-Colocation-Anwendung und Fallanalyse
In diesem Abschnitt stellen wir einige Best Practices vor, die auf internen Fällen von Byte basieren.
4.1 Nutzungseffekt
Im Hinblick auf die Auswirkungen der Katalyst-Implementierung können unsere Ressourcen basierend auf den internen Geschäftspraktiken von Byte während des vierteljährlichen Zyklus in einem einzelnen Cluster auf einem relativ hohen Niveau gehalten werden, und die Ressourcenauslastung weist auch in verschiedenen Zeiträumen jeden Tages ein relativ hohes Niveau auf. Stabile Verteilung; gleichzeitig ist auch die Auslastung der meisten Maschinen im Cluster relativ konzentriert und unser Hybrid-Bereitstellungssystem läuft relativ stabil auf allen Knoten.
| Algorithmus zur Ressourcenprognose | Verhältnis der zurückgewonnenen Ressourcen | Durchschnittliche CPU-Auslastung auf Tagesebene | Spitzen-CPU-Auslastung auf Tagesebene |
|---|---|---|---|
| Auslastung des festen Puffers | 0,26 | 0,33 | 0,58 |
| k-means-Clustering-Algorithmus | 0,35 | 0,48 | 0,6 |
| Systemanzeige-PID-Algorithmus | 0,39 | 0,54 | 0,66 |
| Schätzung des Systemindikatormodells + PID-Algorithmus | 0,42 | 0,57 | 0,67 |
4.2 Praxis: Sinnloser Offline-Zugriff
Nach Eintritt in die dritte Phase müssen wir die Cloud-native Transformation offline durchführen. Es gibt zwei Haupttransformationsmethoden. Eine davon ist für Dienste gedacht, die bereits im K8s-System vorhanden sind. Die andere ist für Dienste unter der YARN-Architektur vorgesehen Eine vollständige Umgestaltung des Frameworks wird für das Unternehmen sehr kostspielig sein und theoretisch zu fortlaufenden Upgrades für alle Unternehmen führen. Dies ist offensichtlich kein idealer Zustand.
Um dieses Problem zu lösen, bezieht sich Byte auf die Klebeschicht von Yodel, d so etwas wie Pod oder Beschreibung des Containers. Mit dieser Methode können wir auf der untersten Ebene ausgereiftere K8s-Technologie verwenden, um Ressourcen zu verwalten, eine Offline-Cloud-native Transformation zu erreichen und gleichzeitig die Stabilität des Unternehmens sicherzustellen.
4.3 Praxis: Resource Operation Governance
Während des Co-Location-Prozesses müssen wir das Big-Data- und Schulungs-Framework anpassen und transformieren und verschiedene Wiederholungsversuche, Prüfpunkte und Bewertungen durchführen, um sicherzustellen, dass, nachdem wir diese Big-Data- und Schulungsaufgaben auf den gesamten Co-Location-Ressourcenpool übertragen haben, Die Erfahrung mit ihnen ist nicht schlecht.
Gleichzeitig müssen wir über umfassende Grundfunktionen in den Bereichen Ressourcenrohstoffe, Geschäftsklassifizierung, Betriebsführung und Quotenverwaltung im System verfügen. Wenn der Betrieb nicht ordnungsgemäß durchgeführt wird, kann die Auslastungsrate in bestimmten Spitzenzeiten sehr hoch sein. In anderen Zeiträumen kann es jedoch zu einer großen Ressourcenlücke kommen, sodass die Auslastungsrate nicht den Erwartungen entspricht.
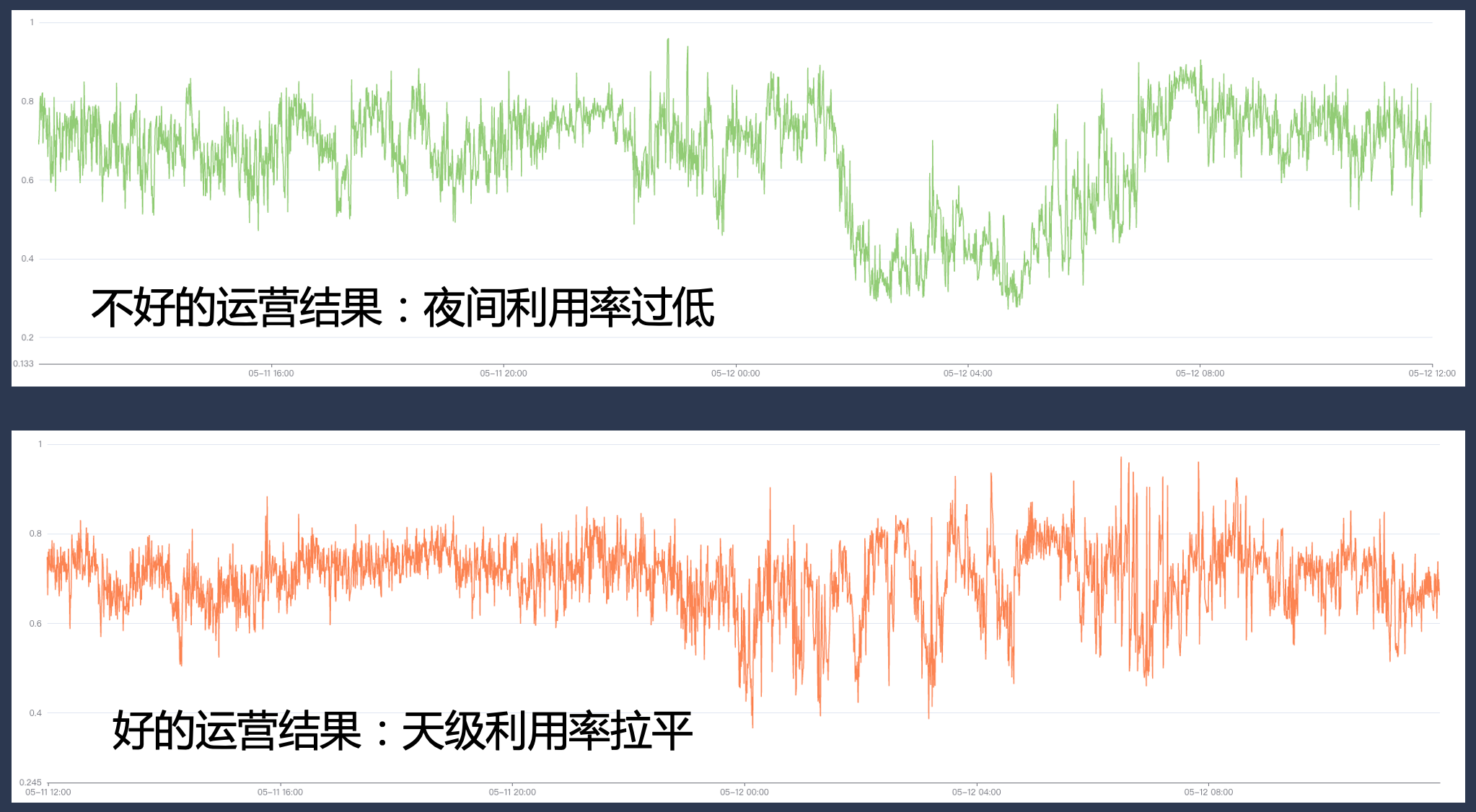
4.4 Praxis: Maximierung der Verbesserung der Ressourceneffizienz
Bei der Erstellung von Serviceporträts verwenden wir Systemindikatoren zur Verwaltung und Steuerung. Statische Systemindikatoren, die auf Offline-Analysen basieren, können jedoch nicht in Echtzeit mit den Änderungen auf der Geschäftsseite Schritt halten Zeit, statische Werte anzupassen.
Zu diesem Zweck führt Katalyst Modelle zur Feinabstimmung von Systemmetriken ein. Wenn wir beispielsweise davon ausgehen, dass die CPU-Planungsverzögerung x Millisekunden betragen kann, und nach einer gewissen Zeit mithilfe des Modells berechnen, dass die Verzögerung des Geschäftsziels y Millisekunden betragen kann, können wir den Wert des Ziels dynamisch anpassen, um eine bessere Bewertung zu ermöglichen Geschäftsleistung.
Wenn beispielsweise in der Abbildung unten statische Systemziele vollständig für die Regulierung verwendet werden, unterliegt der Geschäfts-P99 starken Schwankungen, was bedeutet, dass wir die Geschäftsressourcennutzung außerhalb der abendlichen Spitzenzeiten nicht weiter reduzieren können Extremer Zustand, um es näher an das Geschäft heranzuführen. Der Betrag, der während der abendlichen Spitzenzeiten toleriert werden kann, zeigt, dass die Geschäftsverzögerung nach der Einführung des Modells stabiler sein wird, sodass wir die Geschäftsleistung auf ein relativ stabiles Niveau bringen können den ganzen Tag über und erhalten Sie Ressourcenvorteile.
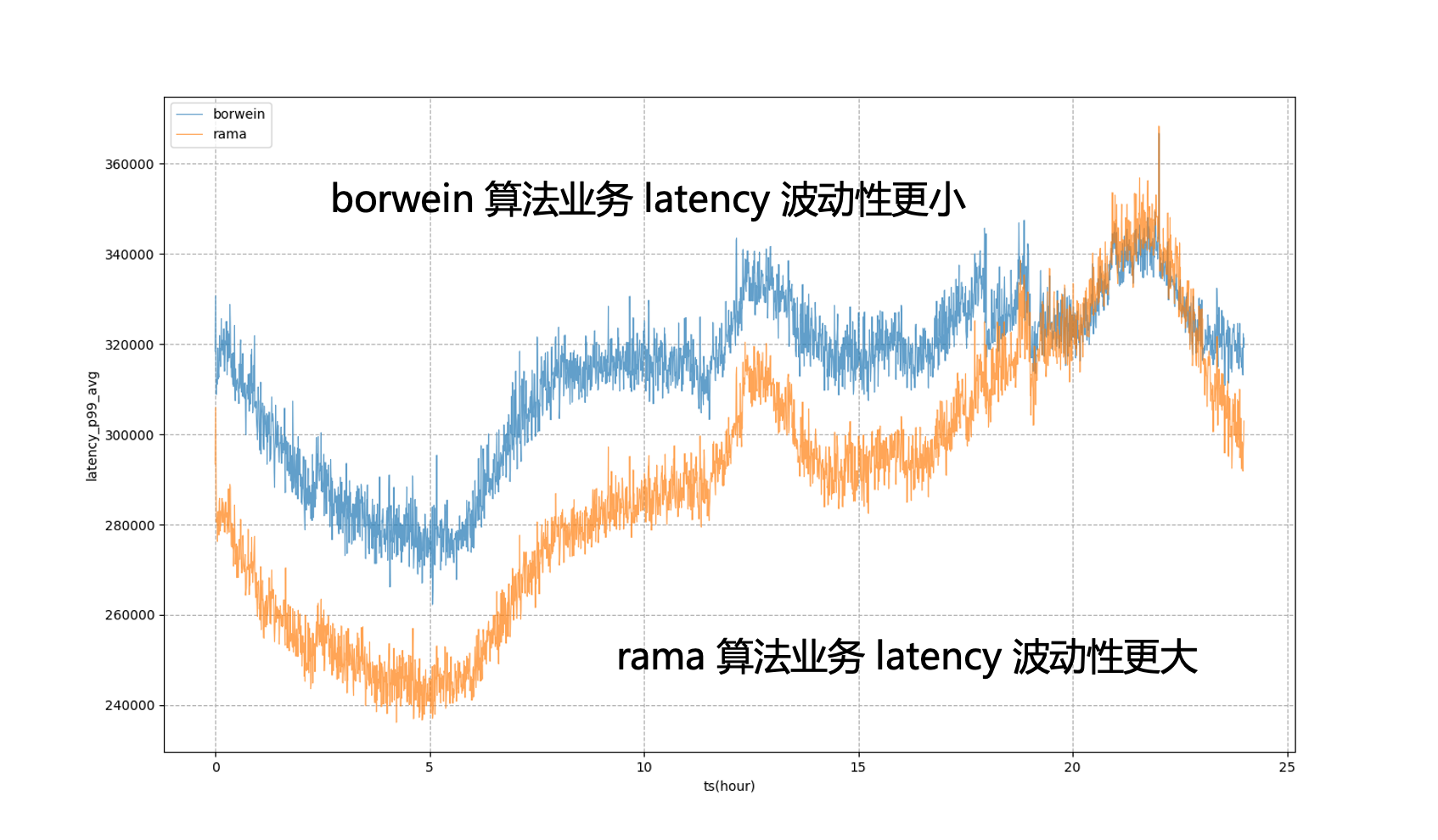
4.5 Übung: Einzelmaschinenprobleme lösen
Bei der Förderung der Co-Location werden wir weiterhin auf verschiedene Online- und Offline-Leistungsprobleme und Anforderungen an das Mikrotopologiemanagement stoßen. Beispielsweise wurden zunächst alle Maschinen auf Basis von cgroup V1 verwaltet und gesteuert. Aufgrund der Struktur von V1 muss das System jedoch einen sehr tiefen Verzeichnisbaum durchlaufen und viel Kernel-Modus-CPU verbrauchen , wir stellen die Knoten im gesamten Cluster auf cgroup V1 um. Die cgroup V2-Architektur ermöglicht es uns, Ressourcen für Dienste wie die Promotion-Suche effizienter zu isolieren und zu überwachen. Um eine extremere Leistung zu erzielen, müssen wir eine komplexere Affinität implementieren und Anti-Affinitätsstrategien auf Socket/NUMA-Ebene usw. usw. Diese erweiterten Anforderungen an die Ressourcenverwaltung können in Katalyst besser umgesetzt werden.
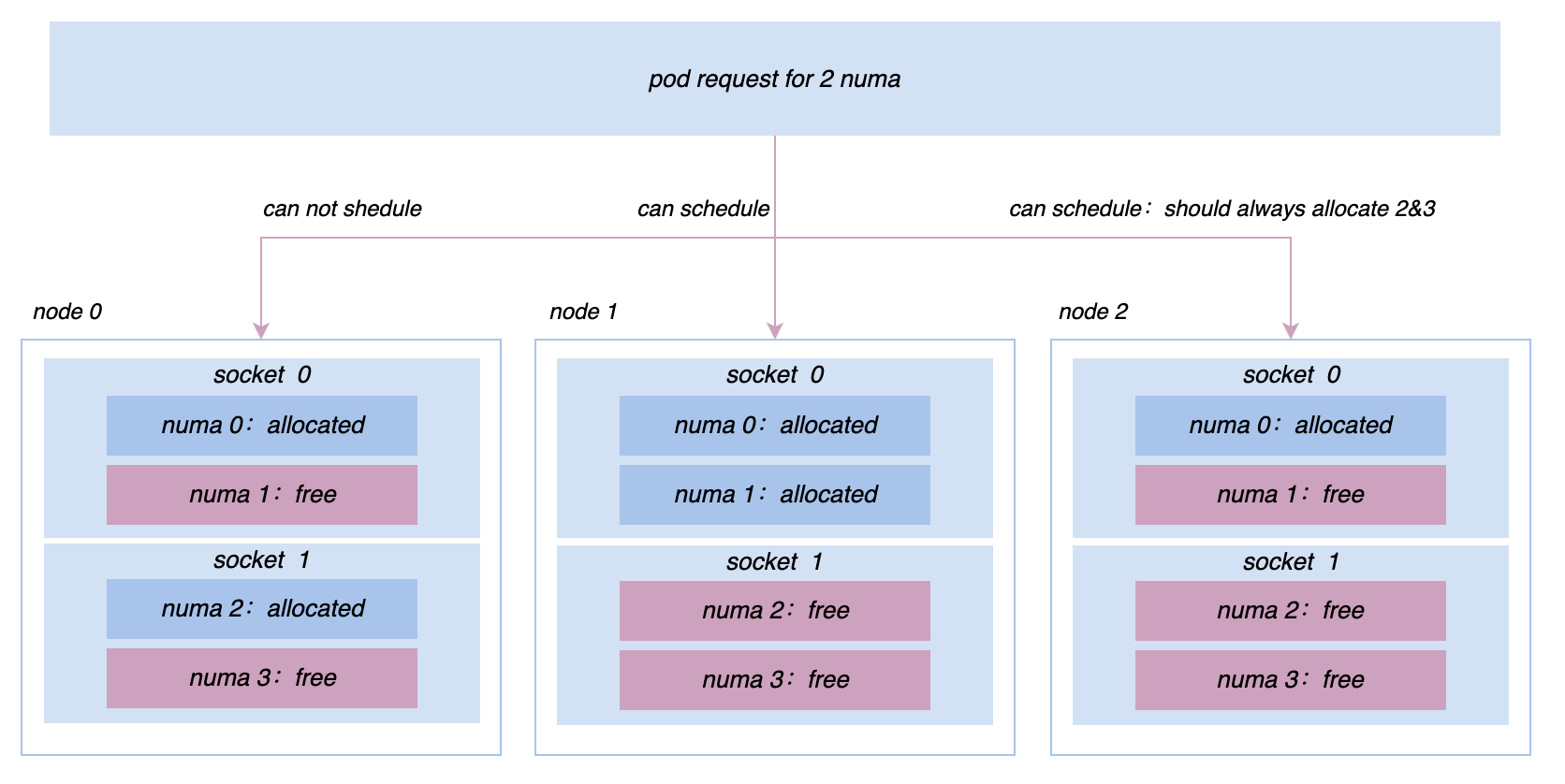
5 Zusammenfassung und Ausblick
Katalyst ist offiziell Open Source und hat die Version v0.3.0 veröffentlicht. Die Community wird weiterhin mehr Energie in die Iteration investieren; Jeder ist herzlich eingeladen, diesem Projekt Aufmerksamkeit zu schenken, sich daran zu beteiligen und Feedback zu geben.
Fellow Chicken „Open-Source“ -Deepin-IDE und endlich Bootstrapping erreicht! Guter Kerl, Tencent hat Switch wirklich in eine „denkende Lernmaschine“ verwandelt. Tencent Clouds Fehlerüberprüfung und Situationserklärung vom 8. April RustDesk-Remote-Desktop-Startup-Rekonstruktion Web-Client WeChats Open-Source-Terminaldatenbank basierend auf SQLite WCDB leitete ein großes Upgrade ein TIOBE April-Liste: PHP fiel auf ein Allzeittief, Fabrice Bellard, der Vater von FFmpeg, veröffentlichte das Audiokomprimierungstool TSAC , Google veröffentlichte ein großes Codemodell, CodeGemma , wird es dich umbringen? Es ist so gut, dass es Open Source ist – ein Open-Source-Bild- und Poster-Editor-ToolVideo zur Konferenzrede: Katalyst: Bytedance Cloud Native Cost Optimization Practice |