

Wenn Sie Ihre KI-Anwendungen auf Basis von Open-Source-Modellen aufbauen, können Sie sie besser, günstiger und schneller machen.
Übersetzt aus „ How to Beat Proprietary LLMs With Smaller Open Source Models“ , Autor Aidan Cooper.
Einführung
Beim Entwerfen von Systemen, die Textgenerierungsmodelle verwenden, greifen viele Menschen zunächst auf proprietäre Dienste zurück, beispielsweise GPT-4 von OpenAI oder Gemini von Google. Schließlich handelt es sich hierbei um die größten und besten Modelle auf dem Markt. Warum sollte man sich also mit etwas anderem beschäftigen? Irgendwann erreichen Anwendungen ein Ausmaß, das diese APIs nicht unterstützen, oder sie werden unerschwinglich teuer oder die Antwortzeiten sind zu langsam. Open-Source-Modelle können all diese Probleme lösen, aber wenn Sie versuchen, sie auf die gleiche Weise wie proprietäre LLMs zu verwenden, erhalten Sie nicht genügend Leistung.
In diesem Artikel untersuchen wir die einzigartigen Vorteile von Open-Source-LLMs und wie sie genutzt werden können, um KI-Anwendungen zu entwickeln, die nicht nur billiger und schneller als proprietäre LLMs, sondern auch besser sind.
Proprietäres LLM vs. Open-Source-LLM
Tabelle 1 vergleicht die Hauptmerkmale proprietärer LLMs und Open-Source-LLMs. Open-Source-LLM soll auf einer vom Benutzer verwalteten Infrastruktur ausgeführt werden, sei es vor Ort oder in der Cloud. Zusammenfassend lässt sich sagen: Proprietäres LLM ist der verwaltete Dienst und bietet das leistungsstärkste Closed-Source-Modell und das größte Kontextfenster, aber Open-Source-LLM ist in jeder anderen wichtigen Hinsicht überlegen.
Das Folgende ist die chinesische Version der Tabelle (Markdown-Format):
| Proprietäres großes Sprachmodell | Open-Source-Modell für große Sprachen | |
|---|---|---|
| Beispiel | GPT-4 (OpenAI), Gemini (Google), Claude (Anthropic) | Gemma 2B (Google), Mistral 7B (Mistral AI), Llama 3 70B (Meta) |
| Zugänglichkeit der Software | Geschlossene Quelle | Open Source |
| Anzahl der Parameter | Billionen-Ebene | Typischer Maßstab: 2B, 7B, 70B |
| Kontextfenster | Länger, 100.000 bis 1 Mio. Token | Kürzere, typische 8k-32k-Token |
| Fähigkeit | Bester Performer in allen Bestenlisten und Benchmarks | Historisch gesehen hinter proprietären großen Sprachmodellen zurück |
| Infrastruktur | Platform as a Service (PaaS), verwaltet vom Anbieter. Nicht konfigurierbar. API-Ratenbegrenzungen. | In der Regel selbstverwaltet auf einer Cloud-Infrastruktur (IaaS). Vollständig konfigurierbar. |
| Begründungskosten | höher | untere |
| Geschwindigkeit | Langsamer zum gleichen Preis. Kann nicht angepasst werden. | Hängt von Infrastruktur, Technologie und Optimierung ab, aber schneller. Hochgradig konfigurierbar. |
| Durchsatz | Unterliegt normalerweise der API-Ratenbegrenzung. | Unbegrenzt: Skaliert mit Ihrer Infrastruktur. |
| Verzögerung | höher. Mehrere Gesprächsrunden können zu einer erheblichen Netzwerklatenz führen. | Wenn Sie das Modell lokal ausführen, gibt es keine Netzwerklatenz. |
| Funktion | Stellt in der Regel über seine API einen begrenzten Funktionsumfang zur Verfügung. | Durch den direkten Zugriff auf das Modell werden viele leistungsstarke Techniken freigeschaltet. |
| Zwischenspeicher | Zugriff auf die Serverseite nicht möglich | Konfigurierbare serverseitige Richtlinien zur Erhöhung des Durchsatzes und Reduzierung der Kosten. |
| Feinabstimmung | Begrenzte Feinabstimmungsdienste (wie OpenAI) | Volle Kontrolle über die Feinabstimmung. |
| Prompt/Flow-Projekt | Aufgrund hoher Kosten oder aufgrund von Tarifbeschränkungen oder Verzögerungen ist dies oft nicht möglich | Uneingeschränkte, sorgfältig gestaltete Kontrollprozesse haben minimale negative Auswirkungen. |
**Tabelle 1.** Vergleich proprietärer LLM- und Open-Source-LLM-Funktionen
Der Schwerpunkt dieses Artikels liegt darauf, dass es durch die Nutzung der Stärken von Open-Source-Modellen möglich ist, KI-Anwendungen zu erstellen, die Aufgaben besser ausführen als proprietäre LLMs und gleichzeitig bessere Durchsatz- und Kostenprofile erzielen.
Wir werden uns auf Strategien für Open-Source-Modelle konzentrieren, die mit proprietären LLMs nicht möglich oder weniger effektiv sind. Das bedeutet, dass wir nicht auf Techniken eingehen, die beiden zugute kommen, wie z. B. Fow-Shot-Hinweise oder Retrieval-Augmented Generation (RAG).
Anforderungen an ein effektives LLM-System
Bei der Überlegung, effektive Systeme rund um LLM zu entwerfen, sind einige wichtige Grundsätze zu beachten.
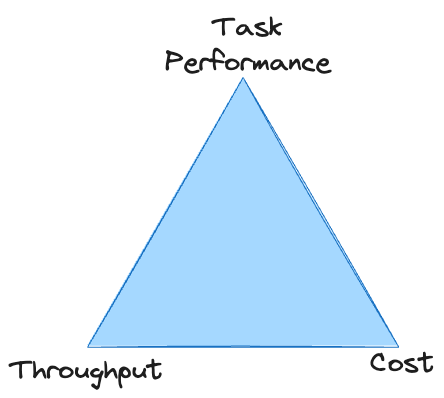
Es besteht ein direkter Kompromiss zwischen Aufgabenleistung, Durchsatz und Kosten: Es ist leicht, eine davon zu verbessern, aber normalerweise auf Kosten der anderen beiden. Sofern Sie nicht über ein unbegrenztes Budget verfügen, muss das System in allen drei Bereichen Mindeststandards erfüllen, um zu überleben. Bei proprietären LLMs stecken Sie häufig am Scheitelpunkt des Dreiecks fest und können keinen ausreichenden Durchsatz zu akzeptablen Kosten erzielen.
Wir werden kurz die Merkmale jeder dieser nichtfunktionalen Anforderungen beschreiben, bevor wir Strategien untersuchen, die zur Lösung jedes Problems beitragen können.
Durchsatz
Viele LLM-Systeme haben einfach deshalb Schwierigkeiten, einen angemessenen Durchsatz zu erreichen, weil LLM langsam ist.
Bei Verwendung von LLM wird der Gesamtsystemdurchsatz fast vollständig von der Zeit bestimmt, die für die Generierung der Textausgabe erforderlich ist.
Sofern Ihre Datenverarbeitung nicht besonders umfangreich ist, sind andere Faktoren als die Textgenerierung relativ unwichtig. LLM kann Text viel schneller „lesen“ als es ihn erzeugen kann – das liegt daran, dass Eingabe-Tokens parallel berechnet werden, während Ausgabe-Tokens sequentiell generiert werden.
Wir müssen die Geschwindigkeit der Texterstellung maximieren, ohne Abstriche bei der Qualität zu machen oder übermäßige Kosten zu verursachen.
Dies gibt uns zwei Hebel an die Hand, wenn das Ziel darin besteht, den Durchsatz zu steigern:
- Reduzieren Sie die Anzahl der zu generierenden Token
- Erhöhen Sie die Geschwindigkeit der Generierung jedes einzelnen Tokens
Viele der folgenden Strategien zielen darauf ab, einen oder beide dieser Bereiche zu verbessern.
kosten
Für proprietäres LLM wird Ihnen die Rechnung pro Eingabe- und Ausgabe-Token berechnet. Der Preis jedes Tokens hängt von der Qualität (d. h. der Größe) des von Ihnen verwendeten Modells ab. Dadurch haben Sie nur begrenzte Möglichkeiten, die Kosten zu senken: Sie müssen die Anzahl der Ein-/Ausgabe-Tokens reduzieren oder ein günstigeres Modell verwenden (die Auswahl wird nicht allzu groß sein).
Bei selbst gehostetem LLM werden Ihre Kosten von Ihrer Infrastruktur bestimmt. Wenn Sie für das Hosting einen Cloud-Dienst nutzen, wird Ihnen pro Zeiteinheit abgerechnet, in der Sie die virtuelle Maschine „mieten“.

Größere Modelle erfordern größere, teurere virtuelle Maschinen. Eine Erhöhung des Durchsatzes ohne Hardwarewechsel senkt die Kosten, da weniger Rechenstunden erforderlich sind, um eine feste Datenmenge zu verarbeiten. Ebenso kann der Durchsatz durch die vertikale oder horizontale Skalierung der Hardware erhöht werden, was jedoch die Kosten erhöht.
Strategien zur Kostenminimierung konzentrieren sich darauf, kleinere Modelle für die Aufgabe zu ermöglichen, da diese den höchsten Durchsatz haben und am kostengünstigsten auszuführen sind.
Aufgabenerfüllung
Die Missionsleistung ist die vageste der drei Anforderungen, bietet aber auch den größten Spielraum für Optimierung und Verbesserung. Eine der größten Herausforderungen bei der Erzielung einer angemessenen Aufgabenleistung ist deren Messung: Es ist schwierig, eine zuverlässige, quantitative Bewertung der LLM-Ergebnisse richtig zu machen.
Da wir uns auf Technologien konzentrieren, die in einzigartiger Weise Open-Source-LLM zugute kommen, liegt der Schwerpunkt unserer Strategie darauf, mit weniger Ressourcen mehr zu erreichen und Methoden zu nutzen, die nur mit direktem Zugriff auf das Modell möglich sind.
Open-Source-LLM-Strategien zum Sieg über proprietäres LLM
Alle folgenden Strategien sind isoliert wirksam, sie ergänzen sich jedoch auch. Sie können in unterschiedlichem Ausmaß eingesetzt werden, um das richtige Gleichgewicht zwischen den nichtfunktionalen Anforderungen des Systems und der Maximierung der Gesamtleistung zu finden.
Multi-Turn-Dialog und Kontrollfluss
- Verbessern Sie die Aufgabenleistung
- Reduzieren Sie den Durchsatz
- Fügen Sie die Kosten pro Eingabe hinzu
Während mit proprietären LLMs eine breite Palette von Multi-Turn-Dialogstrategien verwendet werden kann, sind diese Strategien oft nicht realisierbar, weil sie:
- Bei Abrechnung per Token kann es kostspielig sein
- Möglicherweise werden die API-Ratenbegrenzungen ausgeschöpft, da mehrere API-Aufrufe pro Eingabe erforderlich sind
- Könnte zu langsam sein, wenn der Hin- und Her-Austausch die Generierung vieler Token oder die Anhäufung einer hohen Netzwerklatenz erfordert
Diese Situation dürfte sich mit der Zeit verbessern, da proprietäre LLMs schneller, skalierbarer und erschwinglicher werden. Derzeit sind proprietäre LLMs jedoch häufig auf eine einzige Strategie mit einer einzigen Eingabeaufforderung beschränkt, die in großem Maßstab auf reale Anwendungsfälle angewendet werden kann. Dies steht im Einklang mit dem größeren Kontextfenster, das proprietäre LLMs bieten: Die bevorzugte Strategie besteht oft darin, einfach viele Informationen und Anweisungen in eine einzige Eingabeaufforderung zu packen (was sich übrigens negativ auf Kosten und Geschwindigkeit auswirkt).
Bei einem selbstgehosteten Modell sind diese Nachteile von Mehrrundengesprächen weniger besorgniserregend: Die Kosten pro Token sind weniger relevant; es gibt keine API-Ratenbegrenzungen und die Netzwerklatenz kann minimiert werden. Das kleinere Kontextfenster und die schwächeren Inferenzfähigkeiten von Open-Source-Modellen sollten Sie auch daran hindern, einen einzelnen Hinweis zu verwenden. Dies bringt uns zur Kernstrategie zur Bekämpfung proprietärer LLMs:
Der Schlüssel zur Überwindung von proprietärem LLM liegt in der Verwendung kleinerer Open-Source-Modelle, um mehr Arbeit in einer Reihe feinkörnigerer Teilaufgaben zu erledigen.
Für lokale Modelle sind sorgfältig formulierte Multi-Runden-Prompting-Strategien machbar. Techniken wie Chain of Thoughts (CoT), Trees of Thought (ToT) und ReAct ermöglichen es weniger leistungsfähigen Modellen, die gleiche Leistung wie größere Modelle zu erbringen.
Eine weitere Ebene der Komplexität ist die Verwendung von Kontrollfluss und Verzweigung , um das Modell dynamisch entlang des richtigen Inferenzpfads zu führen und einige Verarbeitungsaufgaben auf externe Funktionen auszulagern. Diese können auch als Mechanismus zum Erhalt des Kontextfenster-Token-Budgets verwendet werden, indem Unteraufgaben in Verzweigungen außerhalb des Haupt-Eingabeaufforderungsflusses verzweigt und dann die aggregierten Ergebnisse dieser Verzweigungen wieder zusammengeführt werden.
Anstatt ein kleines Open-Source-Modell mit einer übermäßig komplexen Aufgabe zu belasten, zerlegen Sie das Problem in einen logischen Ablauf durchführbarer Teilaufgaben.
eingeschränkte Dekodierung
- Verbessern Sie den Durchsatz
- Kosten senken
- Verbessern Sie die Aufgabenleistung
Für Anwendungen, bei denen eine strukturierte Ausgabe generiert wird (z. B. JSON-Objekte), ist die eingeschränkte Dekodierung eine leistungsstarke Technik, die Folgendes kann:
- Garantierte Ausgabe, die der erforderlichen Struktur entspricht
- Verbessern Sie den Durchsatz erheblich, indem Sie die Token-Generierung beschleunigen und die Anzahl der zu generierenden Token reduzieren
- Verbessern Sie die Aufgabenleistung durch Anleitungsmodelle
Ich habe einen separaten Artikel geschrieben, in dem dieses Thema ausführlich erläutert wird: „ Ein Leitfaden zur strukturierten Generierung mit eingeschränkter Dekodierung: Das Wie, Warum, die Möglichkeiten und die Fallstricke der Generierung von Sprachmodellausgaben“.
Entscheidend ist, dass die Einschränkungsdekodierung nur mit Textgenerierungsmodellen funktioniert, die direkten Zugriff auf die vollständige Wahrscheinlichkeitsverteilung des nächsten Tokens bieten, die zum Zeitpunkt des Verfassens dieses Artikels von keinem großen proprietären LLM-Anbieter verfügbar ist.
OpenAI stellt zwar ein JSON-Schema bereit , diese streng eingeschränkte Dekodierung gewährleistet jedoch keine Struktur- oder Durchsatzvorteile der JSON-Ausgabe.
Die Einschränkungsdekodierung geht Hand in Hand mit Kontrollflussstrategien, da sie es Ihnen ermöglicht, ein großes Sprachmodell zuverlässig auf einen vorab festgelegten Pfad zu leiten, indem Sie seine Reaktion auf verschiedene Verzweigungsoptionen einschränken. Ein Modell zu bitten, kurze, eingeschränkte Antworten auf eine Reihe langwieriger Dialogfragen mit mehreren Runden zu liefern, ist sehr schnell und kostengünstig (denken Sie daran: Die Durchsatzgeschwindigkeit wird durch die Anzahl der generierten Token bestimmt).
Die Einschränkungsdekodierung hat keine nennenswerten Nachteile. Wenn Ihre Aufgabe also eine strukturierte Ausgabe erfordert, sollten Sie sie verwenden.
Caching, Modellquantisierung und andere Backend-Optimierungen
- Verbessern Sie den Durchsatz
- Kosten senken
- Hat keinen Einfluss auf die Aufgabenleistung
Caching ist eine Technik, die Datenabrufvorgänge beschleunigt, indem Eingabe-Ausgabe-Paare einer Berechnung gespeichert und die Ergebnisse wiederverwendet werden, wenn dieselbe Eingabe erneut auftritt.
In Nicht-LLM-Systemen wird Caching typischerweise auf Anfragen angewendet, die genau mit zuvor gesehenen Anfragen übereinstimmen. Einige LLM-Systeme profitieren möglicherweise auch von dieser strikten Form des Cachings, aber im Allgemeinen möchten wir beim Erstellen mit LLM nicht zu oft auf genau die gleichen Eingaben stoßen.
Glücklicherweise gibt es speziell für LLM ausgefeilte Schlüsselwert-Caching- Techniken, die viel flexibler sind. Diese Techniken können die Textgenerierung für Anfragen erheblich beschleunigen, die teilweise, aber nicht genau mit zuvor gesehenen Eingaben übereinstimmen. Dies verbessert den Systemdurchsatz, indem die Menge der zu generierenden Token reduziert wird (oder sie zumindest beschleunigt wird, abhängig von der spezifischen Caching-Technologie und dem Szenario).
Bei einem proprietären LLM haben Sie keine Kontrolle darüber, wie das Caching für Ihre Anfragen durchgeführt wird oder nicht. Für Open-Source-LLM gibt es jedoch verschiedene Backend-Frameworks für LLM-Dienste, die den Inferenzdurchsatz erheblich verbessern können und entsprechend den individuellen Anforderungen Ihres Systems konfiguriert werden können.
Neben dem Caching gibt es weitere LLM-Optimierungen, die zur Verbesserung des Inferenzdurchsatzes genutzt werden können, etwa die Modellquantisierung . Durch die Reduzierung der für Modellgewichte verwendeten Präzision kann die Modellgröße (und damit der Speicherbedarf) reduziert werden, ohne die Qualität der Ausgabe wesentlich zu beeinträchtigen. Beliebte Modelle verfügen oft über eine große Anzahl quantisierter Varianten auf Hugging Face, die von der Open-Source-Community bereitgestellt werden, sodass Sie den Quantisierungsprozess nicht selbst durchführen müssen.
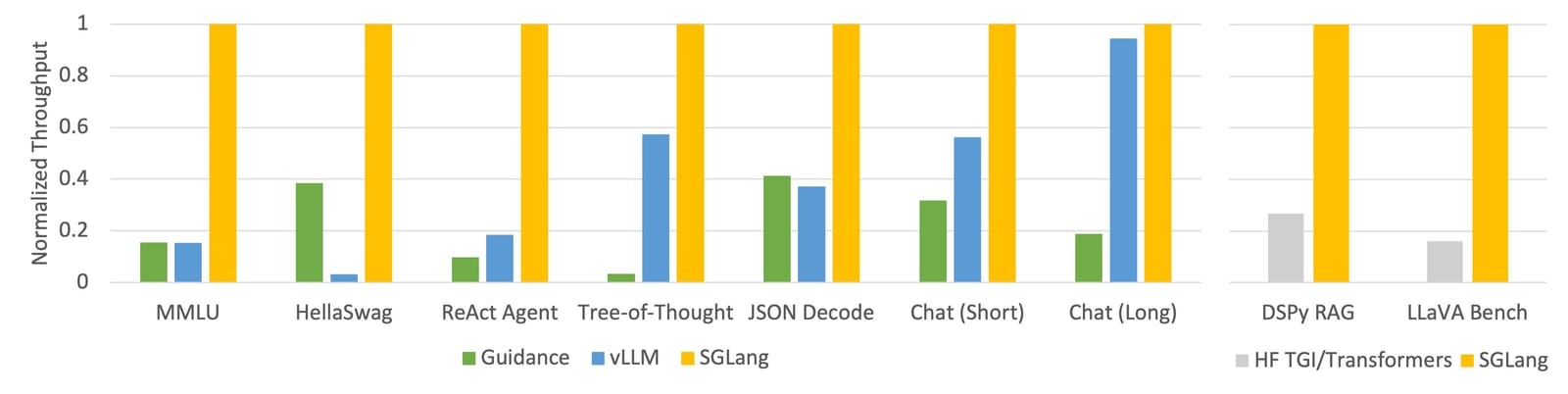
Ankündigung des erstaunlichen Durchsatzes von SGLang (siehe Blogbeitrag zur SGLang-Veröffentlichung)
vLLM ist wahrscheinlich das ausgereifteste Server-Framework mit verschiedenen Caching-Mechanismen, Parallelisierung, Kernel-Optimierung und Modellquantisierungsmethoden. SGLang ist ein neuerer Player mit ähnlicher Funktionalität wie vLLM sowie einer innovativen RadixAttention -Caching-Methode, die eine besonders beeindruckende Leistung verspricht.
Wenn Sie Ihr Modell selbst hosten, lohnt es sich durchaus, diese Frameworks und Optimierungstechniken zu verwenden, da Sie davon ausgehen können, dass sich der Durchsatz um mindestens eine Größenordnung verbessert.
Modellfeinabstimmung und Wissensdestillation
- Verbessern Sie die Effizienz der Aufgabenausführung
- Hat keinen Einfluss auf die Argumentationskosten
- Hat keinen Einfluss auf den Durchsatz
Die Feinabstimmung umfasst eine Vielzahl von Techniken zur Anpassung eines vorhandenen Modells, um eine bessere Leistung bei einer bestimmten Aufgabe zu erzielen. Als Einstieg in das Thema empfehle ich den Blick auf den Blogbeitrag von Sebastian Raschka zum Thema Feinabstimmungsmethoden . Wissensdestillation ist ein verwandtes Konzept, bei dem ein kleineres „Schüler“-Modell trainiert wird, um die Ergebnisse eines größeren „Lehrer“-Modells für die interessierende Aufgabe zu simulieren.
Einige proprietäre LLM-Anbieter, darunter OpenAI , bieten nur minimale Feinabstimmungsmöglichkeiten. Aber nur Open-Source-Modelle bieten die volle Kontrolle über den Feinabstimmungsprozess und Zugriff auf umfassende Feinabstimmungstechnologien.
Die Feinabstimmung von Modellen kann die Aufgabenleistung erheblich verbessern, ohne die Inferenzkosten oder den Durchsatz zu beeinträchtigen. Die Implementierung einer Feinabstimmung erfordert jedoch Zeit, Geschick und gute Daten, und der Schulungsprozess ist mit Kosten verbunden. Parametereffiziente Feinabstimmungstechniken (PEFT) wie LoRA sind besonders attraktiv, da sie im Verhältnis zur Menge der benötigten Ressourcen die höchsten Leistungsrenditen bieten.
Feinabstimmung und Wissensdestillation gehören zu den wirkungsvollsten Techniken zur Maximierung der Modellleistung. Solange sie korrekt umgesetzt werden, haben sie keine Nachteile, abgesehen von den anfänglichen Vorabinvestitionen, die für ihre Umsetzung erforderlich sind. Sie sollten jedoch darauf achten, dass die Feinabstimmung in einer Weise erfolgt, die mit anderen Aspekten des Systems konsistent ist, wie zum Beispiel dem Cue-Fluss und eingeschränkten Decodierungs-Ausgabestrukturen. Bei Unterschieden zwischen diesen Technologien kann es zu unerwartetem Verhalten kommen.
Modellgröße optimieren
Kleines Modell:
- Verbessern Sie den Durchsatz
- Kosten senken
- Reduzieren Sie die Leistung bei der Aufgabenausführung
Man kann es auch als „größeres Modell“ bezeichnen, mit entgegengesetzten Vor- und Nachteilen. Die wichtigsten Punkte sind:
Machen Sie Ihr Modell so klein wie möglich, behalten Sie aber dennoch genügend Kapazität bei, um die Aufgabe zu verstehen und zuverlässig zu erledigen.
Die meisten proprietären LLM-Anbieter bieten eine bestimmte Modellgröße/Fähigkeitsstufe an. Und wenn es um Open Source geht, gibt es schwindelerregende Modelloptionen in allen gewünschten Größen, mit bis zu 100 Milliarden Parametern.
Wie im Abschnitt „Multi-Runden-Konversation“ erwähnt, können wir komplexe Aufgaben vereinfachen, indem wir sie in eine Reihe besser überschaubarer Unteraufgaben aufteilen. Aber es wird immer ein Problem geben, das nicht weiter aufgeschlüsselt werden kann oder das dadurch Aspekte der Mission gefährden würde, die umfassender angegangen werden müssen. Dies hängt stark vom Anwendungsfall ab, aber die Granularität und Komplexität der Aufgabe hat einen Sweet Spot, der die richtige Größe des Modells bestimmt, wie das Erreichen einer angemessenen Aufgabenleistung bei der kleinsten Modellgröße zeigt.
Für einige Aufgaben bedeutet dies, dass Sie das größte und leistungsstärkste Modell verwenden, das Sie finden können. Für andere Aufgaben können Sie möglicherweise ein sehr kleines Modell (sogar ein Nicht-LLM) verwenden.
Entscheiden Sie sich in jedem Fall dafür, das beste Modell seiner Klasse bei jeder gegebenen Parametergröße zu verwenden. Dies lässt sich anhand öffentlicher Benchmarks und Rankings erkennen, die sich regelmäßig ändern, je nachdem, wie schnell sich die Branche entwickelt. Einige Benchmarks sind für Ihren Anwendungsfall besser geeignet als andere. Daher lohnt es sich herauszufinden, welche am besten funktionieren.
Aber denken Sie nicht, dass Sie einfach das neue Spitzenmodell austauschen und eine sofortige Leistungsverbesserung erzielen können. Verschiedene Modelle haben unterschiedliche Fehlermodi und -eigenschaften, sodass ein für ein Modell optimiertes System nicht unbedingt für ein anderes Modell funktioniert – selbst wenn es besser sein sollte.
technologische Straßenkarte
Wie bereits erwähnt, ergänzen sich alle diese Strategien und ergeben zusammen ein robustes, umfassendes System. Es bestehen jedoch Abhängigkeiten zwischen diesen Technologien, und es ist wichtig sicherzustellen, dass sie konsistent sind, um Funktionsstörungen vorzubeugen.
Die folgende Abbildung ist ein Abhängigkeitsdiagramm, das die logische Reihenfolge für die Implementierung dieser Technologien zeigt. Dies setzt voraus, dass der Anwendungsfall die Generierung einer strukturierten Ausgabe erfordert.
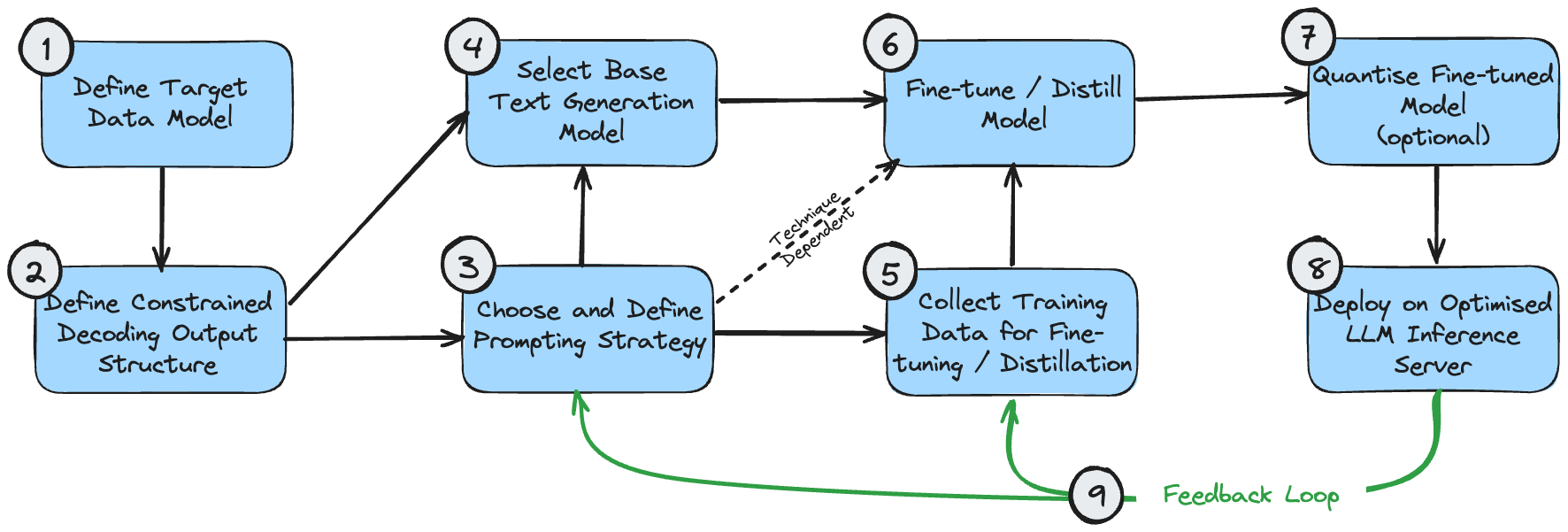
Diese Phasen können wie folgt verstanden werden:
- Das Zieldatenmodell ist die endgültige Ausgabe, die Sie erstellen möchten. Dies hängt von Ihrem Anwendungsfall und den umfassenderen Anforderungen des Gesamtsystems ab, die über die Generierung von Textverarbeitung hinausgehen.
- Die Ausgabestruktur der eingeschränkten Dekodierung kann mit Ihrem Zieldatenmodell identisch sein oder leicht geändert werden, um eine optimale Leistung bei der eingeschränkten Dekodierung zu gewährleisten. Lesen Sie meinen Artikel zur eingeschränkten Dekodierung, um zu verstehen, warum dies geschieht. Wenn es anders ist, ist eine Nachbearbeitungsphase erforderlich, um es in das endgültige Zieldatenmodell umzuwandeln.
- Sie sollten zunächst die richtige Aufforderungsstrategie für Ihren Anwendungsfall erraten. Wenn das Problem einfach ist oder nicht intuitiv aufgeklärt werden kann, wählen Sie eine Single-Prompt-Strategie. Wenn das Problem sehr komplex ist und viele feinkörnige Unterkomponenten aufweist, wählen Sie eine Strategie mit mehreren Eingabeaufforderungen.
- Bei Ihrer ersten Modellauswahl geht es in erster Linie darum, die Größe zu optimieren und sicherzustellen, dass die Modelleigenschaften den funktionalen Anforderungen des Problems entsprechen. Optimale Modellgrößen werden oben besprochen. Modelleigenschaften wie die erforderliche Kontextfensterlänge können basierend auf der erwarteten Ausgabestruktur ((1) und (2)) und der Aufforderungsstrategie (3) berechnet werden.
- Die für die Modellfeinabstimmung verwendeten Trainingsdaten müssen mit der Ausgabestruktur (2) übereinstimmen. Wenn eine Multi-Cue-Strategie verwendet wird, die die Ausgabe Schritt für Schritt aufbaut, müssen die Trainingsdaten auch jede Phase dieses Prozesses widerspiegeln.
- Die Feinabstimmung/Destillation des Modells hängt natürlich von Ihrer Modellauswahl, der Kuratierung der Trainingsdaten und dem sofortigen Ablauf ab.
- Die Quantisierung fein abgestimmter Modelle ist optional. Ihre Quantifizierungsoptionen hängen vom gewählten Basismodell ab.
- Der LLM-Inferenzserver unterstützt nur bestimmte Modellarchitekturen und Quantisierungsmethoden. Stellen Sie daher sicher, dass Ihre vorherige Auswahl mit Ihrer gewünschten Backend-Konfiguration kompatibel ist.
- Sobald Sie ein End-to-End-System eingerichtet haben, können Sie eine Feedbackschleife für kontinuierliche Verbesserungen erstellen. Sie sollten die Eingabeaufforderungen und Beispiele für wenige Aufnahmen (falls Sie diese verwenden) regelmäßig anpassen, um Beispiele zu berücksichtigen, bei denen das System keine akzeptable Ausgabe liefert. Sobald Sie eine angemessene Stichprobe von Fehlerfällen gesammelt haben, sollten Sie auch erwägen, diese Stichproben für die weitere Feinabstimmung des Modells zu verwenden.
In der Realität verläuft der Entwicklungsprozess nie vollständig linear, und je nach Anwendungsfall müssen Sie möglicherweise der Optimierung einiger dieser Komponenten Vorrang vor anderen geben. Aber es ist eine vernünftige Grundlage, um eine Roadmap zu entwerfen, die auf Ihren spezifischen Anforderungen basiert.
abschließend
Open-Source-Modelle können schneller, günstiger und besser sein als proprietäre LLMs. Dies kann durch die Entwicklung komplexerer Systeme erreicht werden, die die einzigartigen Stärken von Open-Source-Modellen nutzen und angemessene Kompromisse zwischen Durchsatz, Kosten und Missionsleistung eingehen.
Bei dieser Designwahl wird die Systemkomplexität zugunsten der Gesamtleistung getauscht. Eine gültige Alternative ist ein einfacheres, ebenso leistungsstarkes System, das auf einem proprietären LLM basiert, jedoch zu höheren Kosten und geringerem Durchsatz. Die richtige Entscheidung hängt von Ihrer Anwendung, Ihrem Budget und der Verfügbarkeit Ihrer technischen Ressourcen ab.
Aber geben Sie Open-Source-Modelle nicht zu schnell auf, ohne Ihre Technologiestrategie entsprechend anzupassen – Sie werden vielleicht überrascht sein, was sie leisten können.
Ich beschloss , auf Open-Source -Industriesoftware zu verzichten – OGG 1.0 wurde veröffentlicht, das Team von Ubuntu 24.04 LTS wurde offiziell entlassen ". Fedora Linux 40 wurde offiziell veröffentlicht. Ein bekanntes Spieleunternehmen veröffentlichte neue Vorschriften: Hochzeitsgeschenke von Mitarbeitern dürfen 100.000 Yuan nicht überschreiten. China Unicom veröffentlicht die weltweit erste chinesische Llama3 8B-Version des Open-Source-Modells. Pinduoduo wird zur Entschädigung verurteilt 5 Millionen Yuan für unlauteren Wettbewerb. Inländische Cloud-Eingabemethode – nur Huawei hat keine Sicherheitsprobleme beim Hochladen von Cloud-DatenDieser Artikel wurde zuerst auf Yunyunzhongsheng ( https://yylives.cc/ ) veröffentlicht, jeder ist herzlich willkommen.