
schreibe vorne
In diesem Artikel wird hauptsächlich das 2023 bei SIGMOD veröffentlichte Papier „Kepler: Robust Learning for Faster Parametric Query Optimization“ vorgestellt. Dieser Artikel kombiniert parametrisierte Abfrageoptimierung und Abfrageoptimierung für parametrisierte Abfragen mit dem Ziel, die Abfrageplanungszeit zu verkürzen und gleichzeitig die Abfrageleistung zu verbessern.
Zu diesem Zweck schlägt der Autor eine durchgängige, auf Deep Learning basierende parametrische Abfrageoptimierungsmethode namens Kepler (K-plan Evolution for Parametric Query Optimization: Learned, Empirical, Robust) vor.
Numerische Abfrage bezieht sich auf einen Abfragetyp, der dieselbe SQL-Struktur hat und sich nur in den gebundenen Parameterwerten unterscheidet. Betrachten Sie als Beispiel die folgende Abfragestruktur:
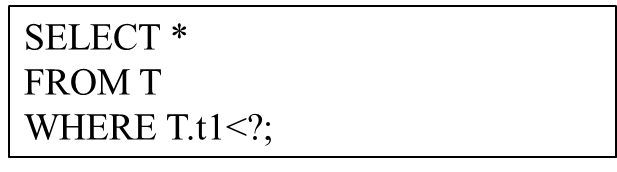
Die Abfragestruktur kann als Vorlage einer parametrisierten Abfrage betrachtet werden, und das „?“ stellt verschiedene Parameterwerte dar. Die vom Benutzer ausgeführten SQL-Anweisungen haben alle diese Abfragestruktur, die tatsächlichen Parameterwerte können jedoch unterschiedlich sein. Dies ist eine parametrisierte Abfrage. Solche parametrisierten Abfragen werden in modernen Datenbanken sehr häufig verwendet. Da dieselbe Abfragevorlage kontinuierlich und wiederholt ausgeführt wird, ergeben sich Möglichkeiten zur Verbesserung der Abfrageleistung.
Die parametrisierte Abfrageoptimierung (PQO) wird verwendet, um die Leistung der oben genannten parametrisierten Abfragen zu optimieren. Ziel ist es, die Abfrageplanungszeit so weit wie möglich zu reduzieren und gleichzeitig Leistungseinbußen zu vermeiden. Bestehende Ansätze verlassen sich zu sehr auf den integrierten Abfrageoptimierer des Systems, sodass sie der inhärenten Suboptimalität des Optimierers unterliegen. Der Autor ist der Ansicht, dass das ideale System für parametrisierte Abfragen nicht nur die Abfrageplanungszeit durch PQO verkürzen, sondern auch die Abfrageausführungsleistung des Systems durch Abfrageoptimierung (QO) verbessern sollte.
Die Abfrageoptimierung (QO) wird verwendet, um einer Abfrage dabei zu helfen, ihren optimalen Ausführungsplan zu finden. Die meisten vorhandenen Methoden zur Verbesserung der Abfrageoptimierung nutzen maschinelles Lernen, beispielsweise auf maschinellem Lernen basierende Kardinalitäts-/Kostenschätzer. Die aktuelle, auf Lernen basierende Abfrageoptimierungsmethode weist jedoch einige Mängel auf: (1) Die Inferenzzeit ist zu lang; (3) Die Leistungsverbesserung ist unklar und die Leistung kann zurückgehen.
Die oben genannten Mängel stellen lernbasierte Methoden vor Herausforderungen, da sie keine Verbesserung der Ausführungszeit von Vorhersageergebnissen garantieren können. Um die oben genannten Probleme zu lösen, schlägt der Autor Kepler vor: eine durchgängig lernbasierte parametrisierte Abfrageoptimierungsmethode.
Die Autoren entkoppeln die parametrische Abfrageoptimierung in zwei Probleme: die Erstellung von Kandidatenplänen und lernbasierte Vorhersagestrukturen. Es ist hauptsächlich in drei Schritte unterteilt: Generierung eines neuartigen Kandidatenplans, Erfassung von Trainingsdaten und Entwurf eines robusten neuronalen Netzwerkmodells. Die Kombination der drei verringert die Abfrageplanungszeit und verbessert gleichzeitig die Abfrageausführungsleistung, während gleichzeitig die Ziele von PQO und QO erreicht werden. Als nächstes stellen wir zunächst die Gesamtarchitektur von Kepler vor und erläutern dann den spezifischen Inhalt jedes Moduls im Detail.
Gesamtarchitektur
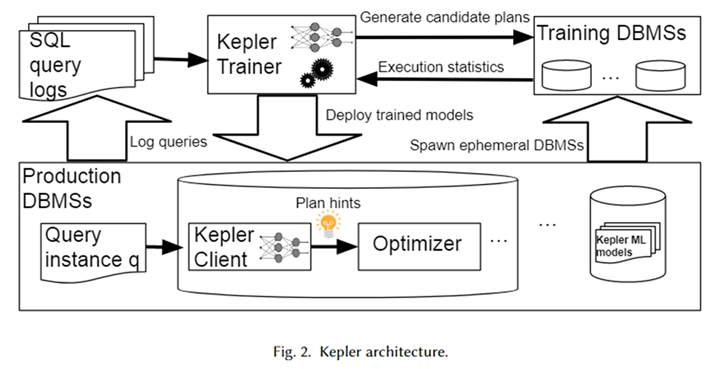
Die Gesamtarchitektur von Kepler ist in der obigen Abbildung dargestellt. Rufen Sie zunächst die parametrisierte Abfragevorlage und die entsprechende Abfrageinstanz (d. h. die Abfrage mit tatsächlichen Parameterwerten) aus dem Datenbanksystemprotokoll ab, um eine Arbeitslast zu bilden. Kepler Trainer wird verwendet, um ein neuronales Netzwerk-Vorhersagemodell für diese Arbeitslast zu trainieren. Zunächst werden Kandidatenpläne für die gesamte Arbeitslast generiert und auf einem temporären Datenbanksystem ausgeführt, um die tatsächliche Ausführungszeit der Abfrage zu ermitteln.
Nutzen Sie diese Abfragezeit, um ein neuronales Netzwerkmodell zu trainieren. Nach Abschluss des Trainings wird es im Datenbanksystem in der Produktionsumgebung namens Kepler Client bereitgestellt. Wenn der Benutzer eine Abfrageinstanz eingibt, kann Kepler Client den besten Ausführungsplan dafür vorhersagen und ihn in Form eines Planhinweises an den Optimierer übergeben, um den besten Plan zu generieren und auszuführen.
Erstellung eines Kandidatenplans: Entwicklung der Zeilenanzahl
Das Ziel der Kandidatenplangenerierung besteht darin, eine Reihe von Plänen zu erstellen, die einen nahezu optimalen Ausführungsplan für jede Abfrageinstanz in der Arbeitslast enthalten. Darüber hinaus sollte es so klein wie möglich sein, um einen übermäßigen Overhead im nachfolgenden Trainingsdatenerfassungsprozess zu vermeiden. Die beiden schränken sich gegenseitig ein, und das Ausbalancieren dieser beiden Ziele ist eine große Herausforderung bei der Erstellung von Kandidatenplänen.
Gleichung 1 formuliert spezifische Ziele für die Planerstellung. Darunter ist eine Abfrageinstanz auf Workload W, ist der vom Optimierer ausgewählte Ausführungsplan, ist der optimale Plan im Plansatz unter idealen Umständen und ExecTime ist die Ausführungszeit des entsprechenden Plans auf der Instanz. Daher ist die Konnotation von Gleichung 1 die Beschleunigung der Ausführungszeit des Kandidatenplansatzes im Vergleich zu dem vom Optimierer generierten Plansatz über die gesamte Arbeitslast. Der Algorithmus ist darauf ausgelegt, diese Beschleunigung zu maximieren.
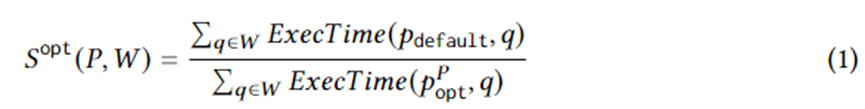
Zu diesem Zweck schlägt dieses Papier Row Count Evolution (RCE) vor, einen Algorithmus, der neue Pläne generiert, indem er die Kardinalitätsschätzung des Optimierers zufällig stört. Es generiert eine Reihe von Plänen für jede Abfrageinstanz, kombiniert zu einer Reihe von Kandidatenplänen für die gesamte Arbeitslast. Die Idee hinter diesem Algorithmus ist, dass eine falsche Schätzung der Basis der Hauptgrund für die Suboptimalität des Optimierers ist. Gleichzeitig muss in der Phase der Generierung des Kandidatenplans nicht für jede Abfrageinstanz ein bestimmter einzelner (nahezu) optimaler Plan gefunden werden, sondern es muss nur der (nahezu) optimale Plan einbezogen werden.
Der RCE-Algorithmus generiert durch Iteration kontinuierlich neue Pläne. Erstens ist der anfängliche Iterationsplan der vom Optimierer generierte Plan. Um nachfolgende Iterationen zu erstellen, ist zunächst eine einheitliche Zufallsstichprobe aus dem Plan der vorherigen Generation erforderlich. Für jeden Stichprobenplan die Kardinalität seines Join-Unterplans stören (ändern).
Bei der Störungsmethode werden Zufallsstichproben innerhalb des exponentiellen Intervalls der aktuell geschätzten Kardinalität durchgeführt. Die gestörte Kardinalität wird an den Optimierer übergeben, um den entsprechenden optimalen Plan zu generieren. Wiederholen Sie jeden Plan N-mal, um viele Ausführungspläne zu generieren. Unter diesen werden nicht erschienene Ausführungspläne als Plan der nächsten Generation beibehalten und der obige Vorgang wird wiederholt.
Wir geben ein konkretes Beispiel, um den obigen Algorithmus visuell zu veranschaulichen, wie in der folgenden Abbildung dargestellt. Zunächst einmal ist der Basisplan der beste vom Optimierer ausgewählte Plan. Er verfügt über zwei Join-Unterpläne, A für B und C für D. Ihre geschätzten Basen betragen 40 bzw. 17.
Als nächstes werden Störungssätze für die beiden Join-Unterpläne aus dem exponentiellen Intervallbereich 10-1~101 generiert, die [4,40,400] bzw. [1,17,170] sind. Aus dem Störungssatz werden Zufallsstichproben entnommen und dem Optimierer zur Planauswahl übergeben. Plan 1 ist der neue Plan, der vom Optimierer ausgewählt wird, wenn die Kardinalität 400 bzw. 17 beträgt. N-mal wiederholt, werden schließlich C1-Pläne als nächste Generation generiert. Als nächstes nehmen Sie daraus Stichproben aus S-Plänen und wiederholen den obigen Vorgang für jeden Plan, um den Plan der 2. Generation zu bilden.
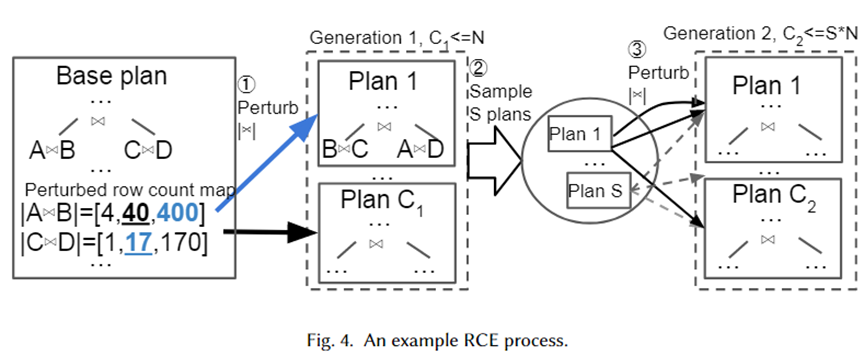
Der Grund, warum die Autoren einen exponentiellen Intervallbereich als Störungssatz gewählt haben, besteht darin, die Verteilung des Kardinalitätsschätzfehlers des Optimierers anzupassen. Aus dem obigen Algorithmus ist ersichtlich, dass, solange die Anzahl der Störungen groß genug ist, viele Kardinalitäten und die entsprechenden Pläne generiert werden. Auf diese Weise sollte es beim Eintreffen einer Abfrageinstanz einen Plan in unserem Plansatz geben, der der wahren Kardinalität nahe kommt, was als (nahezu) optimaler Plan für die Instanz angesehen werden kann.
Erfassung von Trainingsdaten
Nach der Generierung der Kandidatenpläne wird jeder Plan auf der Arbeitslast ausgeführt, und es wurden Ausführungszeitdaten für die überwachte optimale Planvorhersage generiert. Durch die Verwendung tatsächlicher Ausführungsdaten anstelle der vom Optimierer geschätzten Kosten können die durch die Suboptimalität des Optimierers verursachten Einschränkungen vermieden werden. Der Ausführungsprozess ist parallelisierbar. Allerdings ist die Umsetzung aller Pläne mit einem erheblichen Kostenaufwand verbunden. Daher schlagen die Autoren zwei Strategien vor, um die Ressourcenverschwendung durch unnötige suboptimale Planausführung zu reduzieren.
Adaptive Zeitüberschreitungen und Neuordnung der Planausführung, adaptive Zeitüberschreitungen und Neuordnung der Planausführung. Die Autoren nutzen einen Timeout-Mechanismus, um die Ausführung suboptimaler Pläne einzuschränken. Für jede Abfrageinstanz kann bei der Ausführung jedes Plans die aktuelle Mindestausführungszeit aufgezeichnet werden.
Sobald die Ausführungszeit eines Plans einen bestimmten Bereich der Mindestausführungszeit überschreitet, kann er nicht mehr ausgeführt werden, da es sich definitiv nicht um den optimalen Ausführungsplan handelt. Gleichzeitig wird die Mindestausführungszeit ständig aktualisiert. Darüber hinaus kann die Ausführung von Abfrageplänen in aufsteigender Reihenfolge der Ausführungszeit basierend auf der Ausführung jedes Plans auf anderen Abfrageinstanzen als Heuristik verwendet werden, um den Timeout-Mechanismus zu beschleunigen.
Online-Plan zum Beschneiden, Online-Plan-Set zum Beschneiden. Nachdem alle Pläne für die ersten N Abfrageinstanzen ausgeführt wurden, werden sie mithilfe des Set Cover-Problems in K Pläne zerlegt. Nachfolgende Datenerfassung und Modelltraining nutzen diese K-Pläne. Das Set-Cover-Problem ist wie unten gezeigt definiert.
Stellt im Kontext dieses Artikels alle Abfrageinstanzen dar, die als unterschiedliche Pläne dargestellt werden können, wobei jeder Plan für eine Abfrageinstanz ein nahezu optimaler Plan ist. Daher kann das Problem so formuliert werden, dass der kleinstmögliche Satz von Plänen verwendet wird, um für alle Abfrageinstanzen nahezu optimale Ergebnisse zu erzielen. Das Problem ist NP, daher verwendet der Autor einen Greedy-Algorithmus, um es zu lösen.

Robuste Best-Plan-Vorhersage
Nach dem Sammeln von Trainingsdaten zur tatsächlichen Ausführungszeit des Kandidatenplansatzes wird überwachtes maschinelles Lernen verwendet, um den besten Plan für jede Abfrageinstanz vorherzusagen. Das Trainingsziel kann logisch durch die folgende Gleichung ausgedrückt werden. Dabei stellt der beste Plan dar, der vom Modell für die Abfrageinstanz ausgewählt wurde. Die Bedeutung dieser Gleichung ist die Beschleunigung, die sich aus dem vom Modell gewählten Plan im Vergleich zu dem vom Optimierer gewählten Plan ergibt. Seine Obergrenze ist Gleichung 1. Mit anderen Worten: Das Modell sollte die Beschleunigung, die durch die von RCE generierten Kandidatenpläne entsteht, so gut wie möglich erfassen.
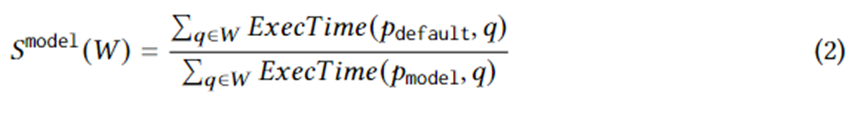
Die Struktur des Modells übernimmt ein vorwärts gerichtetes neuronales Netzwerk und wendet die neuesten Fortschritte bei der Unsicherheit des maschinellen Lernens an, nämlich spektral normalisierte neuronale Gaußsche Prozesse (SNGPs). Die Kombination mit dem neuronalen Netzwerk kann die Konvergenz des Modells verbessern und es dem neuronalen Netzwerk gleichzeitig ermöglichen, die Unsicherheit der Vorhersage auszugeben. Wenn die Unsicherheit höher als ein Schwellenwert ist, wird die Arbeit der Planvorhersage an den Optimierer zurückgegeben, der den besten Plan ermittelt.
Das Modell wird anhand der tatsächlichen Werte jedes Parameters charakterisiert. Um die tatsächlichen Werte der Parameter in das neuronale Netzwerk einzugeben, ist eine gewisse Vorverarbeitung erforderlich, insbesondere bei Daten vom Typ String. Für Daten vom Typ String verwendet der Autor ein Vokabular fester Größe und Buckets, die nicht im Vokabular enthalten sind, um sie als One-Hot-Vektor darzustellen, und fügt eine Einbettungsebene hinzu, um die Einbettung des One-Hot-Vektors zu lernen und dann zu sein Kann Daten vom Typ String verarbeiten.
Experimenteller Effekt
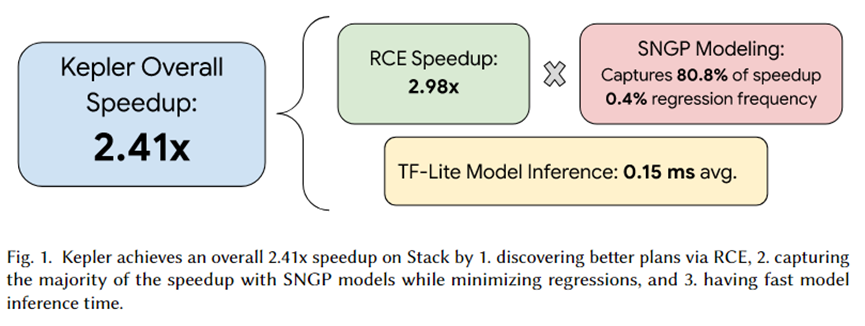
Der Autor dieses Artikels hat Kepler in PostgreSQL integriert und eine Reihe von Experimenten organisiert. Die Zusammenfassung des Experiments ist in der obigen Abbildung dargestellt. Der Gesamtbeschleunigungseffekt von Kepler beträgt das 2,41-fache. Unter diesen kann der von RCE generierte Kandidatenplansatz eine etwa 2,92-fache Beschleunigung bewirken, 80,8 % werden vom SNGP-Vorhersagemodell erfasst und nur 0,4 % der Regression werden erreicht. Darüber hinaus beträgt die Inferenzzeit des Modells im Durchschnitt nur 0,15 ms.
Zusammenfassen
In diesem Artikel wird Kepler vorgeschlagen, ein lernbasierter Ansatz, der parametrisierte Abfragen erheblich beschleunigt. Es generiert mithilfe des Row Count Evolution (RCE)-Algorithmus einen Kandidatenplan, führt ihn auf der Arbeitslast aus, um die tatsächliche Ausführungszeit zu ermitteln, und verwendet die tatsächliche Ausführungszeit zum Trainieren des Vorhersagemodells.
Das Vorhersagemodell verwendet spektral normalisierte neuronale Gauß-Prozesse (SNGPs), den neuesten Fortschritt in der Unsicherheitsschätzung des maschinellen Lernens, um die Konvergenz zu verbessern und gleichzeitig die Unsicherheit der Vorhersage auszugeben. Basierend auf dieser Unsicherheit wird ausgewählt, ob das Modell oder der Optimierer die Vorhersage vervollständigt Planvorhersage. Experimente haben gezeigt, dass RCE hohe Beschleunigungseffekte hervorrufen kann, und SNGP kann die durch RCE verursachten Beschleunigungseffekte so weit wie möglich erfassen und gleichzeitig eine Regression vermeiden. Daher werden die Ziele von PQO und QO gleichzeitig erreicht, dh bei gleichzeitiger Verkürzung der Abfrageplanungszeit wird die Abfrageausführungsleistung verbessert.
Ich beschloss , auf Open-Source -Industriesoftware zu verzichten – OGG 1.0 wurde veröffentlicht, das Team von Ubuntu 24.04 LTS wurde offiziell entlassen ". Fedora Linux 40 wurde offiziell veröffentlicht. Ein bekanntes Spieleunternehmen veröffentlichte neue Vorschriften: Hochzeitsgeschenke von Mitarbeitern dürfen 100.000 Yuan nicht überschreiten. China Unicom veröffentlicht die weltweit erste chinesische Llama3 8B-Version des Open-Source-Modells. Pinduoduo wird zur Entschädigung verurteilt 5 Millionen Yuan für unlauteren Wettbewerb. Inländische Cloud-Eingabemethode – nur Huawei hat keine Sicherheitsprobleme beim Hochladen von Cloud-Daten