
1. Hintergrundeinführung
Parametrisierte Abfragen beziehen sich auf einen Abfragetyp, der dieselbe Vorlage hat und sich nur in den Werten der Prädikatbindungsparameter unterscheidet. Sie werden in modernen Datenbankanwendungen häufig verwendet. Sie führen Aktionen wiederholt aus, was Möglichkeiten zur Leistungsoptimierung bietet.
Die aktuelle Methode zur Verarbeitung parametrisierter Abfragen in vielen kommerziellen Datenbanken optimiert jedoch nur die erste Abfrageinstanz (oder die vom Benutzer angegebene Instanz) in der Abfrage, speichert ihren besten Plan zwischen und verwendet ihn für nachfolgende Abfrageinstanzen wieder. Obwohl diese Methode die Zeit zur Minimierung optimiert, kann die Ausführung des zwischengespeicherten Plans aufgrund unterschiedlicher optimaler Pläne für verschiedene Abfrageinstanzen willkürlich suboptimal sein, was in tatsächlichen Anwendungsszenarien nicht anwendbar ist.
Die meisten herkömmlichen Optimierungsmethoden erfordern viele Annahmen über den Abfrageoptimierer, diese Annahmen stimmen jedoch häufig nicht mit tatsächlichen Anwendungsszenarien überein. Glücklicherweise können die oben genannten Probleme mit dem Aufkommen des maschinellen Lernens effektiv gelöst werden. In dieser Ausgabe werden zwei in VLDB2022 und SIGMOD2023 veröffentlichte Artikel ausführlich vorgestellt:
Seite 1: „Nutzung von Abfrageprotokollen und maschinellem Lernen zur parametrischen Abfrageoptimierung“.
Seite 2: „Kepler: Robustes Lernen für eine schnellere parametrische Abfrageoptimierung“.
2. Essenz von Papier 1
„Nutzung von Abfrageprotokollen und maschinellem Lernen zur parametrischen Abfrageoptimierung“ Dieses Dokument entkoppelt die parametrisierte Abfrageoptimierung in zwei Probleme:
(1) PopulateCache: speichert K Pläne für eine Abfragevorlage im Cache;
(2) getPlan: wählt für jede Abfrageinstanz den besten Plan aus die zwischengespeicherten Pläne.
Die Algorithmusarchitektur dieses Artikels ist in der folgenden Abbildung dargestellt. Es ist hauptsächlich in zwei Module unterteilt: das PopulateCache- und das getPlan-Modul.
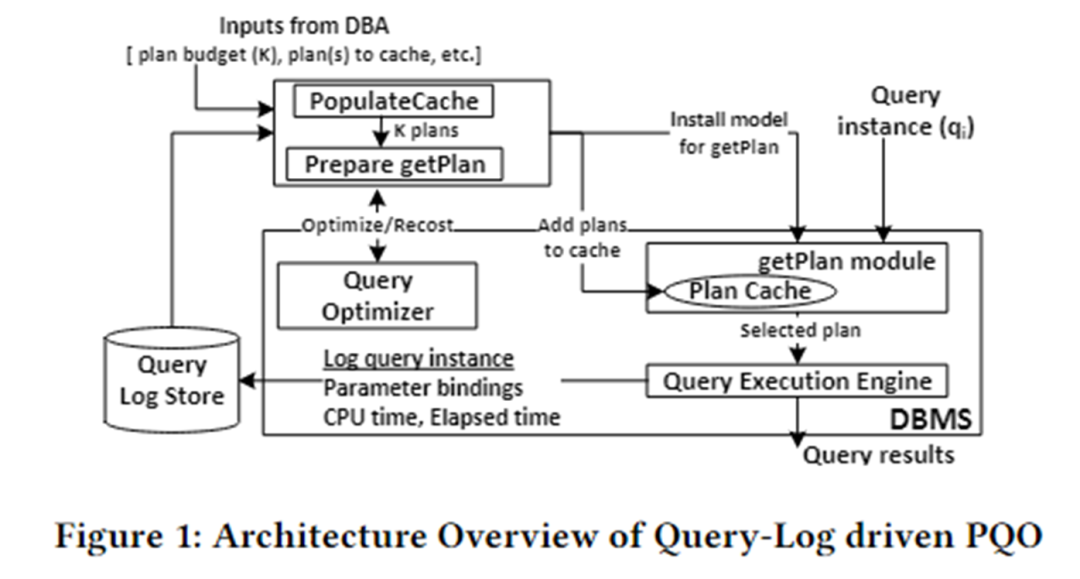
PopulateCache verwendet die Informationen im Abfrageprotokoll, um K-Pläne für alle Abfrageinstanzen zwischenzuspeichern. Das getPlan-Modul sammelt zunächst Kosteninformationen zwischen K-Plänen und Abfrageinstanzen durch Interaktion mit dem Optimierer und verwendet diese Informationen zum Trainieren des maschinellen Lernmodells. Stellen Sie das trainierte Modell im DBMS bereit. Wenn eine Abfrageinstanz eintrifft, kann der beste Plan für diese Instanz schnell vorhergesagt werden.
PopulateCache
Das PolulateCache-Modul ist für die Identifizierung einer Reihe von Cache-Plänen für eine bestimmte parametrisierte Abfrage verantwortlich. Die Suchphase nutzt zwei Optimierer-APIs:
- Optimiereraufruf: Gibt den vom Optimierer für eine Abfrageinstanz ausgewählten Plan zurück;
- Recost-Aufruf: Gibt die vom Optimierer geschätzten Kosten für eine Abfrageinstanz und den entsprechenden Plan zurück;
Der Algorithmusablauf ist wie folgt:
- Planerfassungsphase: Optimiereraufruf aufrufen, um Kandidatenpläne für n Abfrageinstanzen im Abfrageprotokoll zu sammeln;
- Plan-Neukostenphase: Rufen Sie für jede Abfrageinstanz und jeden Kandidatenplan den Neukostenaufruf auf, um eine Plan-Neukosten-Matrix zu bilden.
- K-Set-Identifikationsphase: Verwendet einen Greedy-Algorithmus und nutzt die Plan-Recost-Matrix, um K-Pläne zwischenzuspeichern und so Suboptimalität zu minimieren.
getPlan
Das getPlan-Modul ist für die Auswahl eines der K zwischengespeicherten Pläne zur Ausführung für eine bestimmte Abfrageinstanz verantwortlich. Der getPlan-Algorithmus kann zwei Ziele berücksichtigen: Minimierung der vom Optimierer geschätzten Kosten oder Minimierung der tatsächlichen Ausführungskosten zwischen K-Cache-Plänen.
Betrachten Sie Ziel 1: Verwenden Sie die Plan-Recost-Matrix, um ein überwachtes ML-Modell zu trainieren, und berücksichtigen Sie Klassifizierung und Regression.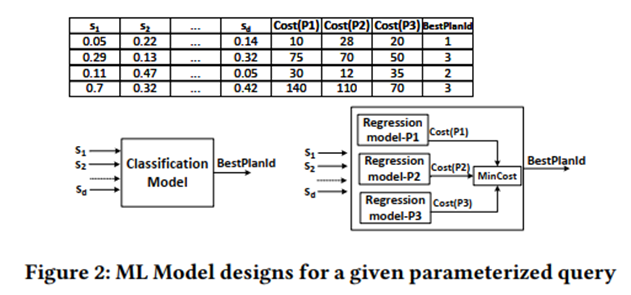
Betrachten Sie Ziel 2: Verwenden Sie ein auf Multi-Armed Bandit basierendes Reinforcement-Learning-Trainingsmodell.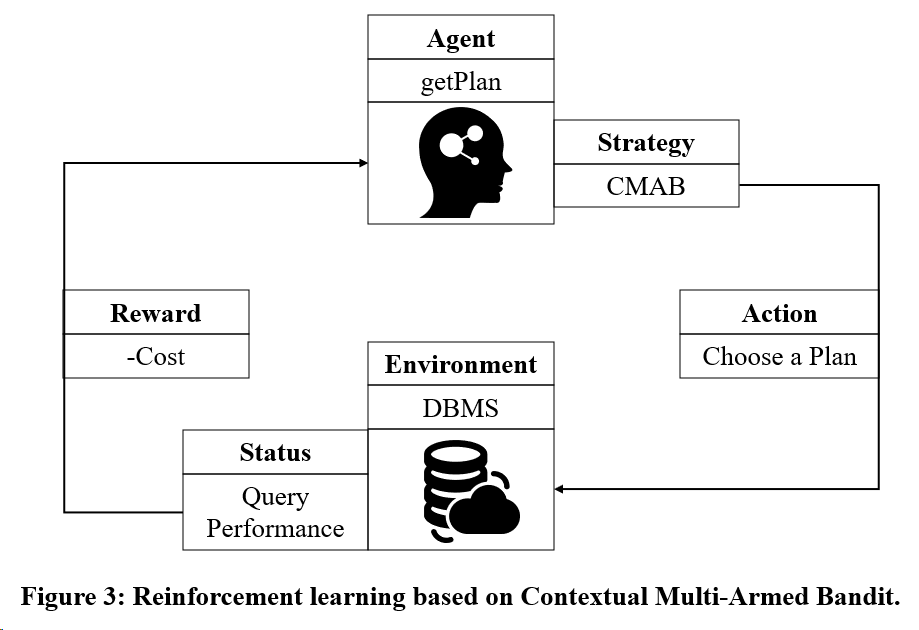
3. Essenz von Papier 2
„Kepler: Robustes Lernen für eine schnellere parametrische Abfrageoptimierung“ In diesem Artikel wird eine durchgängige, lernbasierte parametrische Abfrageoptimierungsmethode vorgeschlagen, die darauf abzielt, die Abfrageoptimierungszeit zu verkürzen und die Abfrageausführungsleistung zu verbessern.
Die Algorithmusarchitektur ist wie folgt: Kepler unterteilt das Problem in zwei Teile: Plangenerierung und lernbasierte Planvorhersage. Es ist hauptsächlich in drei Phasen unterteilt: Plangenerierungsstrategie, Trainingsabfrageausführungsphase und robustes neuronales Netzwerkmodell.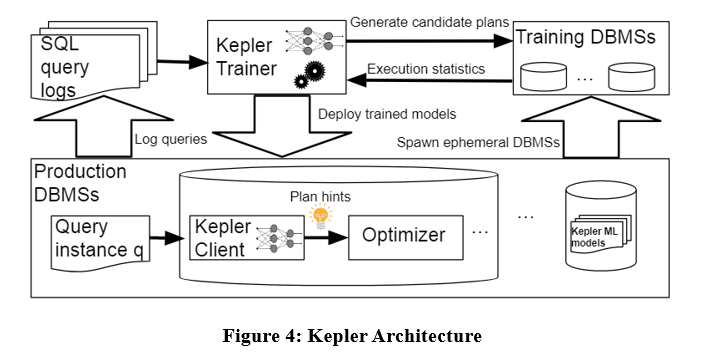
Geben Sie, wie in der Abbildung oben gezeigt, die Abfrageinstanz in das Abfrageprotokoll ein, um Kepler Trainer zunächst einen Kandidatenplan zu generieren und dann Ausführungsinformationen im Zusammenhang mit dem Kandidatenplan als Trainingsdaten zu sammeln, um das Modell für maschinelles Lernen zu trainieren. Das Modell wird im DBMS bereitgestellt. Wenn eine Abfrageinstanz eintrifft, wird Kepler Client verwendet, um den besten Plan vorherzusagen und ihn auszuführen.
Entwicklung der Zeilenanzahl
In diesem Artikel wird ein Algorithmus zur Generierung von Kandidatenplänen namens Row Count Evolution (RCE) vorgeschlagen, der Kandidatenpläne durch Störung der Kardinalitätsschätzung des Optimierers generiert.
Die Idee dieses Algorithmus kommt von: Eine falsche Schätzung der Kardinalität ist die Hauptursache für die Suboptimalität des Optimierers, und die Phase der Generierung des Kandidatenplans muss nur den optimalen Plan einer Instanz enthalten, anstatt einen einzelnen optimalen Plan auszuwählen.
Der RCE-Algorithmus generiert zunächst den optimalen Plan für die Abfrageinstanz, stört dann die Join-Kardinalität seiner Unterpläne innerhalb des exponentiellen Intervallbereichs, wiederholt ihn mehrmals und führt mehrere Iterationen durch und verwendet schließlich alle generierten Pläne als Kandidatenpläne. Konkrete Beispiele sind wie folgt: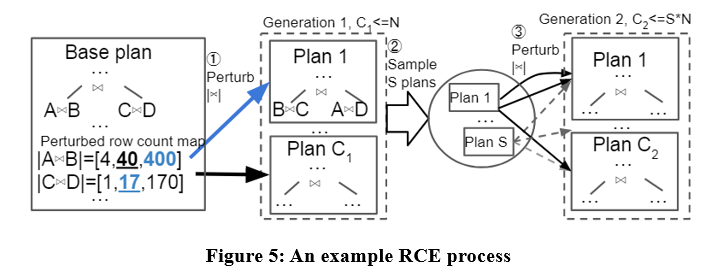
Mit dem RCE-Algorithmus sind die generierten Kandidatenpläne möglicherweise besser als der vom Optimierer erstellte Plan. Da der Optimierer möglicherweise Kardinalitätsschätzungsfehler aufweist, kann RCE durch kontinuierliche Störung der Kardinalitätsschätzung den optimalen Plan entsprechend der korrekten Kardinalität erstellen.
Trainingsdatenerfassung
Nach Erhalt des Kandidatenplansatzes wird jeder Plan auf der Arbeitslast für jede Abfrageinstanz ausgeführt und die tatsächliche Ausführungszeit für das Training des überwachten optimalen Planvorhersagemodells erfasst. Der obige Prozess ist relativ umständlich. In diesem Artikel werden einige Mechanismen vorgeschlagen, um die Erfassung von Trainingsdaten zu beschleunigen, z. B. die parallele Ausführung, der adaptive Timeout-Mechanismus usw.
Robuste Best-Plan-Vorhersage
Die resultierenden tatsächlichen Ausführungsdaten werden verwendet, um ein neuronales Netzwerk zu trainieren, um den optimalen Plan für jede Abfrageinstanz vorherzusagen. Das verwendete neuronale Netzwerk ist ein spektral normalisierter Gaußscher neuronaler Prozess. Dieses Modell gewährleistet die Stabilität des Netzwerks und die Konvergenz des Trainings und kann Unsicherheitsschätzungen für Vorhersagen liefern. Wenn die Unsicherheitsschätzung größer als ein bestimmter Schwellenwert ist, bleibt es dem Optimierer überlassen, einen Ausführungsplan auszuwählen. Leistungsrückgänge werden bis zu einem gewissen Grad vermieden.
4. Zusammenfassung
Die beiden oben genannten Artikel entkoppeln parametrisierte Abfragen in populateCache und getPlan. Der Vergleich zwischen den beiden ist in der folgenden Tabelle dargestellt.
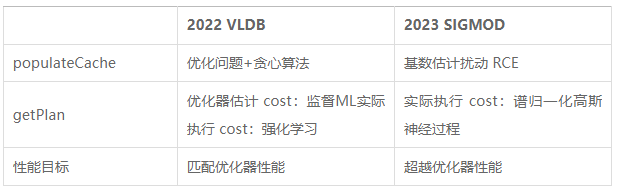
Obwohl Algorithmen, die auf Modellen des maschinellen Lernens basieren, bei der Planvorhersage eine gute Leistung erbringen, ist ihr Trainingsdatenerfassungsprozess teuer und die Modelle lassen sich nicht einfach verallgemeinern und aktualisieren. Daher besteht bei den bestehenden parametrisierten Abfrageoptimierungsmethoden noch Raum für Verbesserungen.
本文图示来源: 1)Kapil Vaidya & Anshuman Dutt, „Leveraging Query Logs and Machine Learning for Parametric Query Optimization“, 2022 VLDB, https://dl.acm.org/doi/pdf/10.14778/3494124.3494126 2)LYRIC DOSHI & VINCENT ZHUANG, „Kepler: Robust Learning for Faster Parametric Query Optimization“, 2023 SIGMOD, https://dl.acm.org/doi/pdf/10.1145/3588963
Ich beschloss , auf Open-Source -Industriesoftware zu verzichten – OGG 1.0 wurde veröffentlicht, das Team von Ubuntu 24.04 LTS wurde offiziell entlassen ". Fedora Linux 40 wurde offiziell veröffentlicht. Ein bekanntes Spieleunternehmen veröffentlichte neue Vorschriften: Hochzeitsgeschenke von Mitarbeitern dürfen 100.000 Yuan nicht überschreiten. China Unicom veröffentlicht die weltweit erste chinesische Llama3 8B-Version des Open-Source-Modells. Pinduoduo wird zur Entschädigung verurteilt 5 Millionen Yuan für unlauteren Wettbewerb. Inländische Cloud-Eingabemethode – nur Huawei hat keine Sicherheitsprobleme beim Hochladen von Cloud-Daten