

Mit der eingehenden Erforschung groß angelegter Modellanwendungen hat die Retrieval-Augmented-Generation-Technologie große Aufmerksamkeit erhalten und wurde in verschiedenen Szenarien eingesetzt, z. B. bei Fragen und Antworten in Wissensdatenbanken, bei Rechtsberatern, Lernassistenten, Website-Robotern usw.
Viele Freunde sind sich jedoch über die Beziehung und die technischen Prinzipien von Vektordatenbanken und RAG nicht im Klaren. Dieser Artikel vermittelt Ihnen ein detailliertes Verständnis der neuen Vektordatenbank in der RAG-Ära.
01.
Das breite Einsatzspektrum von RAG und seine einzigartigen Vorteile
Ein typisches RAG-Framework kann in zwei Teile unterteilt werden: Retriever und Generator. Der Abrufprozess umfasst das Segmentieren von Daten (z. B. Dokumente), das Einbetten von Vektoren (Einbetten) und das Erstellen von Indizes (Chunks-Vektoren). Anschließend werden relevante Ergebnisse durch Vektorabruf abgerufen , und der Generierungsprozess verwendet Prompt basierend auf den Abrufergebnissen (Kontext), um LLM zu aktivieren, um Antworten (Ergebnis) zu generieren.
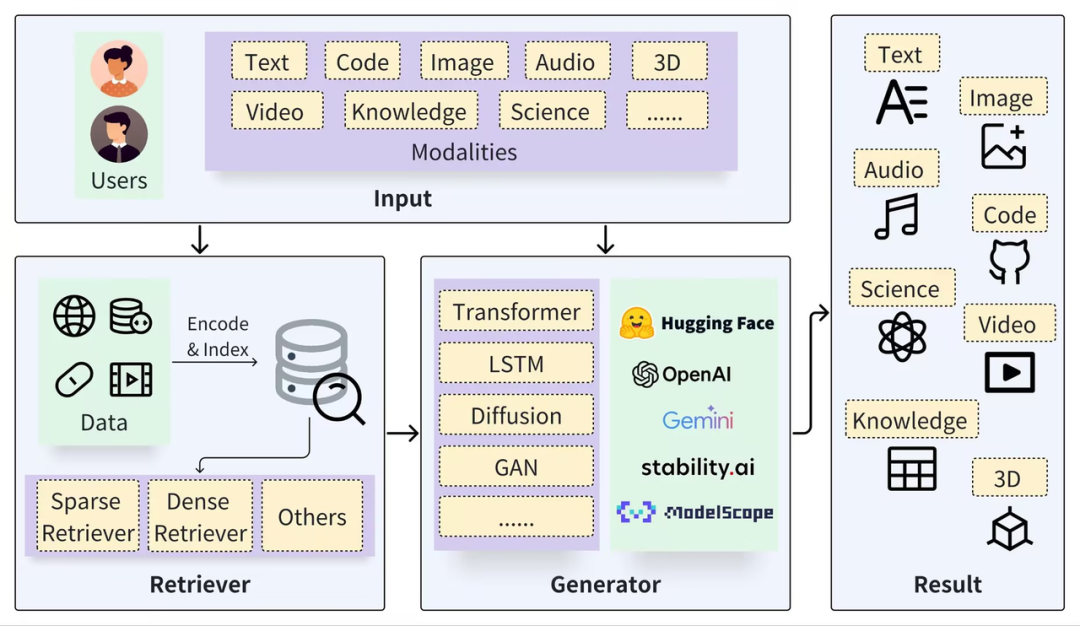
https://arxiv.org/pdf/2402.19473
Der Schlüssel zur RAG-Technologie liegt darin, dass sie das Beste aus beiden Ansätzen vereint: ein Abrufsystem, das spezifische, relevante Fakten und Daten bereitstellt, und ein generatives Modell, das flexibel Antworten erstellt und breitere Kontexte und Informationen einbezieht. Diese Kombination macht das RAG-Modell sehr effektiv bei der Verarbeitung komplexer Anfragen und der Generierung informationsreicher Antworten, was in Frage-Antwort-Systemen, Dialogsystemen und anderen Anwendungen, die das Verständnis und die Generierung natürlicher Sprache erfordern, sehr nützlich ist. Im Vergleich zu nativen Großmodellen kann die Kombination mit RAG natürliche ergänzende Vorteile bieten:
Vermeiden Sie „Halluzinations“-Probleme: RAG unterstützt große Modelle bei der Beantwortung von Fragen, indem es externe Informationen als Eingabe abruft. Diese Methode kann Fragen zu ungenau generierten Informationen erheblich reduzieren und die Nachvollziehbarkeit von Antworten erhöhen.
Datenschutz und Sicherheit: RAG kann die Wissensdatenbank als externen Anhang verwenden, um die privaten Daten eines Unternehmens oder einer Institution zu verwalten und zu verhindern, dass Daten nach dem Lernen des Modells auf unkontrollierbare Weise verloren gehen.
Echtzeitcharakter von Informationen: RAG ermöglicht den Echtzeitabruf von Informationen aus externen Datenquellen, sodass das neueste, domänenspezifische Wissen erlangt und das Problem der Aktualität des Wissens gelöst werden kann.
Obwohl sich die Spitzenforschung zu groß angelegten Modellen auch der Lösung der oben genannten Probleme widmet, etwa der Feinabstimmung auf der Grundlage privater Daten und der Verbesserung der Langtextverarbeitungsfähigkeiten des Modells selbst, tragen diese Studien dazu bei, die Weiterentwicklung groß angelegter Modelle zu fördern. maßstabsgetreue Modelltechnik. In allgemeineren Szenarien ist RAG jedoch immer noch eine stabile, zuverlässige und kostengünstige Wahl, vor allem weil RAG die folgenden Vorteile bietet:
White-Box-Modell : Im Vergleich zum „Black-Box“-Effekt der Feinabstimmung und Langtextverarbeitung ist die Beziehung zwischen RAG-Modulen klarer und enger, was bei der Effektoptimierung eine höhere Bedienbarkeit und Interpretierbarkeit bietet (Gewissheit) des abgerufenen und zurückgerufenen Inhalts nicht hoch ist, kann das RAG-System sogar das Eingreifen von LLMs verbieten und direkt mit „Weiß nicht“ antworten, anstatt Unsinn zu erfinden.
Kosten und Reaktionsgeschwindigkeit: RAG bietet im Vergleich zu fein abgestimmten Modellen die Vorteile einer kurzen Trainingszeit und niedriger Kosten sowie eine schnellere Reaktionsgeschwindigkeit und viel geringere Inferenzkosten. Im Forschungs- und Versuchsstadium sind Wirkung und Genauigkeit am attraktivsten, aber im Hinblick auf die Industrie und die industrielle Umsetzung sind die Kosten ein entscheidender Faktor, der nicht ignoriert werden darf.
Privates Datenmanagement: Durch die Entkopplung der Wissensbasis von großen Modellen bietet RAG nicht nur eine sichere und umsetzbare praktische Basis, sondern kann auch das vorhandene und neue Wissen des Unternehmens besser verwalten und das Problem der Wissensabhängigkeit lösen. Ein weiterer verwandter Aspekt ist die Zugriffskontrolle und Datenverwaltung, die für die Basisdatenbank von RAG einfach, für große Modelle jedoch schwierig ist.
Daher wird die RAG-Technologie meiner Meinung nach mit der weiteren Vertiefung der Forschung an Großmodellen nicht ersetzt werden. Im Gegenteil, sie wird noch lange eine wichtige Position behalten. Dies ist vor allem auf die natürliche Komplementarität mit LLM zurückzuführen, die es auf RAG basierenden Anwendungen ermöglicht, in vielen Bereichen zu glänzen. Der Schlüssel zur RAG-Verbesserung liegt einerseits in der Verbesserung der LLM-Fähigkeiten und andererseits in verschiedenen Verbesserungen und Optimierungen des Abrufs (Retrieval).
02.
Die Grundlage für RAG-Suchen: Vektordatenbanken
In der Industriepraxis ist der RAG-Abruf normalerweise eng mit Vektordatenbanken integriert, was auch zu einer RAG-Lösung auf Basis von ChatGPT + Vector Database + Prompt geführt hat, die als CVP-Technologie-Stack bezeichnet wird. Diese Lösung basiert auf Vektordatenbanken, um relevante Informationen zur Verbesserung großer Sprachmodelle (LLMs) effizient abzurufen. Durch die Umwandlung von Abfragen, die von LLMs generiert werden, in Vektoren kann das RAG-System schnell entsprechende Wissenseinträge in der Vektordatenbank finden. Dieser Abrufmechanismus ermöglicht es LLMs, bei bestimmten Problemen die neuesten in der Vektordatenbank gespeicherten Informationen zu nutzen und so die Probleme der Wissensaktualisierungsverzögerung und der Illusion, die LLMs innewohnen, wirksam zu lösen.
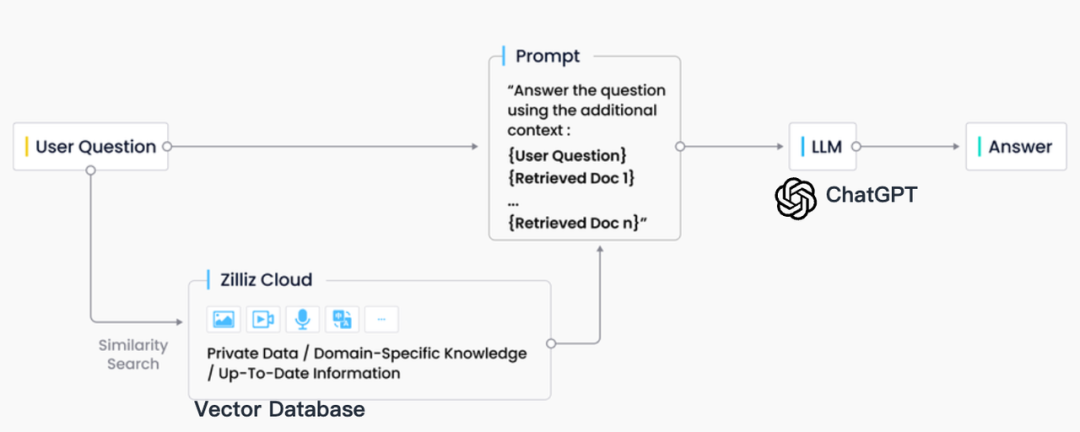
Obwohl es im Bereich des Informationsabrufs viele Speicher- und Abruftechnologien gibt, darunter Suchmaschinen, relationale Datenbanken, Dokumentdatenbanken usw., sind Vektordatenbanken in RAG-Szenarien zur ersten Wahl der Branche geworden. Hinter dieser Wahl steht die hervorragende Fähigkeit von Vektordatenbanken, große Mengen eingebetteter Vektoren effizient zu speichern und abzurufen. Diese Einbettungsvektoren werden durch Modelle des maschinellen Lernens generiert und sind nicht nur in der Lage, mehrere Datentypen wie Text und Bilder zu charakterisieren, sondern auch deren tiefe semantische Informationen zu erfassen. Im RAG-System besteht die Abrufaufgabe darin, schnell und genau die Informationen zu finden, die am besten zur Semantik der Eingabeabfrage passen, und Vektordatenbanken zeichnen sich durch ihre erheblichen Vorteile bei der Verarbeitung hochdimensionaler Vektordaten und der Durchführung schneller Ähnlichkeitssuchen aus.
Im Folgenden finden Sie einen horizontalen Vergleich von Vektordatenbanken, die durch Vektorabruf dargestellt werden, mit anderen technischen Optionen sowie eine Analyse der Schlüsselfaktoren, die sie zu einer gängigen Wahl in RAG-Szenarien machen:
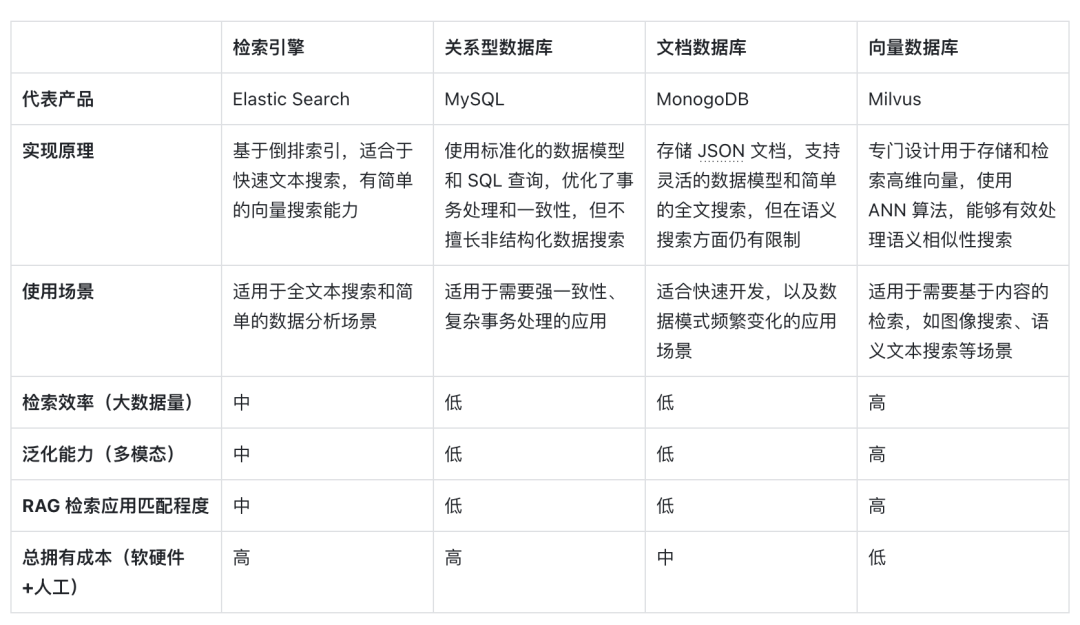
Erstens sind Vektoren im Hinblick auf die Implementierungsprinzipien die Kodierungsform des Modells für die semantische Bedeutung. Vektordatenbanken können den semantischen Inhalt von Abfragen besser verstehen, da sie die Fähigkeit von Deep-Learning-Modellen nutzen, die Bedeutung von Text zu kodieren, nicht nur den Schlüsselwortabgleich . Durch die Entwicklung von KI-Modellen verbessert sich auch die dahinter stehende semantische Genauigkeit stetig. Die Verwendung der Vektordistanzähnlichkeit zum Ausdruck der semantischen Ähnlichkeit hat sich daher zur ersten Wahl für die Verarbeitung von Informationsträgern entwickelt.
Zweitens können im Hinblick auf die Abrufeffizienz spezielle Indexoptimierungs- und Quantifizierungsmethoden zu Vektoren hinzugefügt werden, da Informationen als hochdimensionale Vektoren ausgedrückt werden können, was die Abrufeffizienz erheblich verbessern und die Speicherkosten reduzieren kann Die Vektordatenbank kann horizontal erweitert werden, wobei die Antwortzeit auf Abfragen erhalten bleibt, was für RAG-Systeme, die riesige Datenmengen verarbeiten müssen, von entscheidender Bedeutung ist, sodass Vektordatenbanken sehr große unstrukturierte Daten besser verarbeiten können.
Was die Dimension der Generalisierungsfähigkeit angeht , können die meisten herkömmlichen Suchmaschinen, relationalen oder Dokumentdatenbanken nur Text verarbeiten und verfügen über schlechte Generalisierungs- und Erweiterungsfähigkeiten. Vektordatenbanken sind nicht auf Textdaten beschränkt, sondern können auch Bilder, Audio und andere unstrukturierte Daten verarbeiten . Art des Einbettungsvektors, der das RAG-System flexibler und vielseitiger macht.
Im Hinblick auf die Gesamtbetriebskosten sind Vektordatenbanken im Vergleich zu anderen Optionen bequemer bereitzustellen und einfacher zu verwenden. Sie bieten außerdem umfangreiche APIs, wodurch sie sich leicht in bestehende Frameworks und Arbeitsabläufe für maschinelles Lernen integrieren lassen und daher beliebt sind unter ihnen ein Favorit unter vielen RAG-Anwendungsentwicklern.
Der Vektorabruf ist im Zeitalter großer Modelle aufgrund seiner semantischen Verständnisfähigkeit, seiner hohen Abrufeffizienz und der Generalisierungsunterstützung für Multimodalitäten zu einem idealen RAG-Retriever geworden. Mit der Weiterentwicklung von KI und Einbettungsmodellen könnten diese Vorteile noch stärker in den Vordergrund treten in der Zukunft.
03.
Anforderungen an Vektordatenbanken in RAG-Szenarien
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
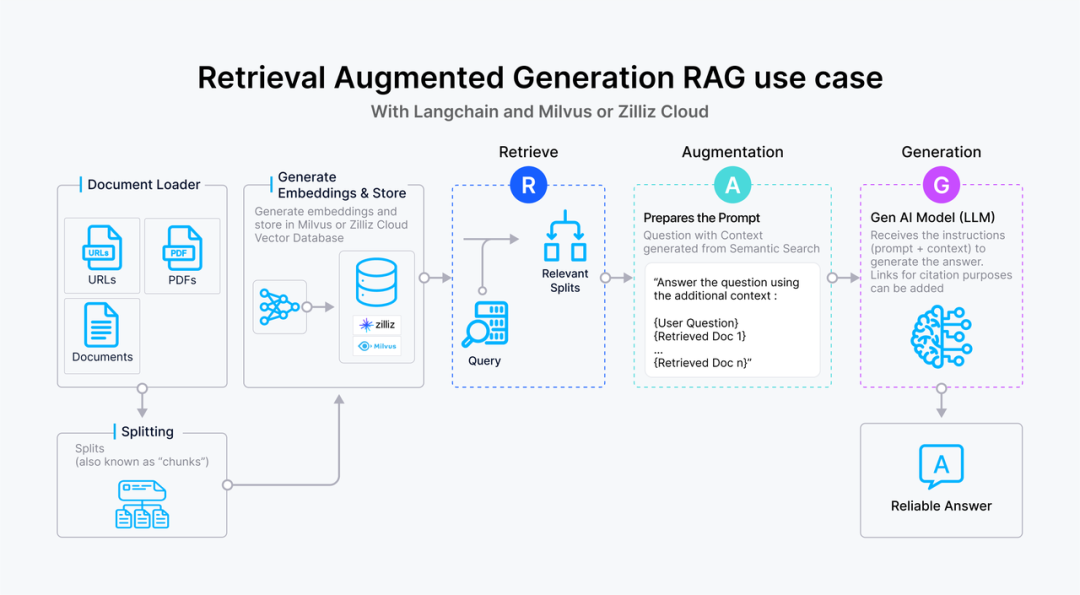
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。