
Anmerkung des Herausgebers: Derzeit ist das Retrieval Enhanced Generation (RAG)-System zu einer der Schlüsseltechnologien geworden, um umfangreiches Wissen in große Modelle zu übertragen. Allerdings stellt die effiziente Verarbeitung halbstrukturierter und unstrukturierter Daten, insbesondere tabellarischer Daten in Dokumenten, immer noch ein großes Problem für RAG-Systeme dar.
Der Autor dieses Artikels schlägt eine neuartige Lösung für die Verarbeitung tabellarischer Daten vor, um dieses Problem anzugehen. Der Autor sortiert zunächst systematisch die Kerntechnologien der Tabellenverarbeitung im RAG-System, einschließlich Tabellenanalyse, Indexstrukturdesign usw., und überprüft einige vorhandene Open-Source-Lösungen. Auf dieser Grundlage schlug der Autor seine eigene Innovation vor – die Verwendung des Nougat-Tools zum genauen und effizienten Parsen des Tabelleninhalts im Dokument, die Verwendung des Sprachmodells zum Zusammenfassen der Tabelle und ihres Titels und schließlich den Aufbau einer neuen Indexstruktur für die Dokumentzusammenfassung enthält vollständige Details zur Code-Implementierung.
Der Vorteil dieser Methode besteht darin, dass sie die Tabelle effektiv analysieren und die Beziehung zwischen der Tabellenzusammenfassung und der Tabelle vollständig berücksichtigen kann. Sie erfordert nicht die Verwendung von multimodalem LLM und kann Analysekosten sparen. Lassen Sie uns die weitere Anwendung und Entwicklung dieses Schemas in der Praxis abwarten.
Autor |. Florian Juni
Zusammengestellt |. Yue Yang
Die Implementierung eines RAG-Systems ist eine anspruchsvolle Aufgabe, insbesondere wenn Tabellen in unstrukturierten Dokumenten analysiert und verstanden werden müssen. Für Dokumente, die durch Scanvorgänge digitalisiert wurden (gescannte Dokumente) oder Dokumente im Bildformat (Dokumente im Bildformat), ist es noch schwieriger, diese Vorgänge umzusetzen. Es gibt mindestens drei Herausforderungen:
- Durch Scanvorgänge digitalisierte Dokumente (gescannte Dokumente) oder Dokumente im Bildformat (Dokumente im Bildformat) sind relativ komplex , z. B. die Vielfalt der Dokumentstrukturen, das Dokument kann einige Nichttextelemente enthalten und das Dokument kann gleichzeitig vorhanden sein Handgeschriebene und gedruckte Inhalte stellen die genaue und automatisierte Extraktion von Formularinformationen vor Herausforderungen. Durch eine ungenaue Dokumentenanalyse wird die Tabellenstruktur zerstört. Die Umwandlung unvollständiger Tabelleninformationen in eine Vektordarstellung (Einbettung) kann nicht nur die semantischen Informationen der Tabelle nicht effektiv erfassen, sondern kann auch leicht zu Problemen bei der endgültigen Ausgabe von RAG führen.
- So extrahieren Sie die Titel jeder Tabelle und verknüpfen sie mit der spezifischen Tabelle, der sie entsprechen.
- So organisieren und speichern Sie wichtige semantische Informationen effizient in Tabellen durch sinnvolles Indexstrukturdesign.
In diesem Artikel wird zunächst die Verwaltung und Verarbeitung tabellarischer Daten im Retrieval Augmented Generation (RAG)-Modell vorgestellt. Anschließend werden einige bestehende Open-Source-Lösungen überprüft und schließlich eine neuartige tabellarische Datenverwaltungsmethode basierend auf der aktuellen Technologie entworfen und implementiert.
01 Einführung in Kerntechnologien im Zusammenhang mit RAG-Tabellendaten
1.1 Tabellenparsing Parsen von Tabellendaten
Die Hauptfunktion dieses Moduls besteht darin, Tabellenstrukturen aus unstrukturierten Dokumenten oder Bildern präzise zu extrahieren.
Zusätzliche Anforderungen: Es ist am besten, den entsprechenden Tabellentitel zu extrahieren, um Entwicklern das Zuordnen des Tabellentitels zur Tabelle zu erleichtern.
Nach meinem derzeitigen Verständnis gibt es mehrere Methoden, wie in Abbildung 1 dargestellt:
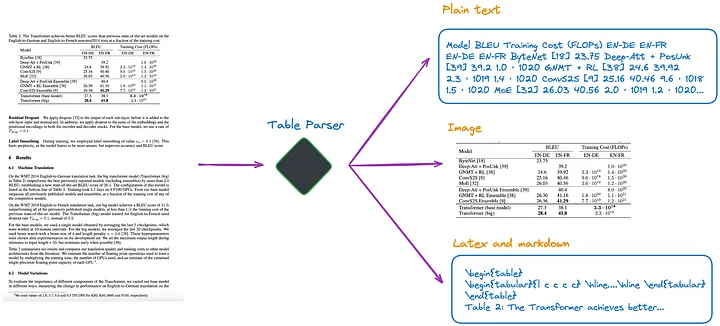
Abbildung 1: Tabellenparser. Bild vom Originalautor zur Verfügung gestellt.
(a).Verwenden Sie multimodales LLM (z. B. GPT-4V[1]), um Tabellen zu erkennen und Informationen aus jeder PDF-Seite zu extrahieren.
- Eingabe: PDF-Seite im Bildformat
- Ausgabe: Tabellarische Daten in JSON oder anderen Formaten. Wenn multimodales LLM keine tabellarischen Daten extrahieren kann, sollte es das PDF-Bild zusammenfassen und eine Zusammenfassung des Inhalts zurückgeben.
(b). Verwenden Sie professionelle Tabellenerkennungsmodelle (z. B. Table Transformer[2]), um Tabellenstrukturen zu identifizieren.
- Eingabe: PDF-Seitenbild
- Ausgabe: Tabellenbild
(c) Verwenden Sie Open-Source-Frameworks wie unstrukturiert[3] oder andere Frameworks, die ebenfalls Objekterkennungsmodelle verwenden (dieser Artikel[4] beschreibt den Tabellenerkennungsprozess von unstrukturiert). Diese Frameworks können das gesamte Dokument vollständig analysieren und tabellenbezogene Inhalte aus den analysierten Ergebnissen extrahieren.
- Eingabe: Dokument im PDF- oder Bildformat
- Ausgabe: Tabelle im Nur-Text- oder HTML-Format (erhalten durch Parsen des gesamten Dokuments)
(d). Verwenden Sie End-to-End-Modelle wie Nougat[5] und Donut[6], um das gesamte Dokument zu analysieren und tabellenbezogene Inhalte zu extrahieren. Für diesen Ansatz ist kein OCR-Modell erforderlich.
- Eingabe: Dokument im PDF- oder Bildformat
- Ausgabe: Tabelle im LaTeX- oder JSON-Format (erhalten durch Parsen des gesamten Dokuments)
Es ist zu beachten, dass unabhängig davon, welche Methode zum Extrahieren von Tabelleninformationen verwendet wird, auch der Tabellentitel extrahiert werden sollte. Denn in den meisten Fällen handelt es sich bei dem Tabellentitel um eine kurze Beschreibung der Tabelle durch den Dokument- oder Papierautor, die den Inhalt der gesamten Tabelle weitgehend zusammenfassen kann.
Von den oben genannten vier Methoden kann Methode (d) Tabellentitel bequemer abrufen. Dies ist ein großer Vorteil für Entwickler, da sie Tabellentitel mit Tabellen verknüpfen können. Die folgenden Experimente sollen dies weiter verdeutlichen.
1.2 Wie die Indexstruktur Tabellendaten indiziert
Es gibt ungefähr die folgenden Arten von Indizierungsmethoden:
(e). Nur Indextabellen im Bildformat.
(f). Nur Indextabellen im Klartext- oder JSON-Format.
(g). Nur Indextabellen im LaTeX-Format.
(h). Nur die Zusammenfassung der Tabelle wird indiziert.
(i). Von klein nach groß (Anmerkung des Übersetzers: Es umfasst sowohl eine feinkörnige Indizierung, z. B. die Indizierung jeder Zeile oder Tabellenzusammenfassung, als auch eine grobkörnige Indizierung, z. B. die Indizierung der gesamten Tabelle mit Bildern, einfachem Text oder LaTeX Geben Sie Daten ein. Bilden Sie eine hierarchische Indexstruktur von klein bis groß. Oder verwenden Sie die Tabellenzusammenfassung, um eine Indexstruktur zu erstellen, wie in Abbildung 2 dargestellt.
Der Inhalt des kleinen Blocks (Anmerkung des Übersetzers: Datenblock, der der feinkörnigen Indexebene entspricht), z. B. die Behandlung jeder Zeile der Tabelle oder Zusammenfassungsinformationen als unabhängiger kleiner Datenblock.
Der Inhalt des großen Blocks (Anmerkung des Übersetzers: Der Datenblock, der der grobkörnigen Indexebene entspricht) kann eine ganze Tabelle im Bildformat, im Nur-Text-Format oder im LaTeX-Format sein.
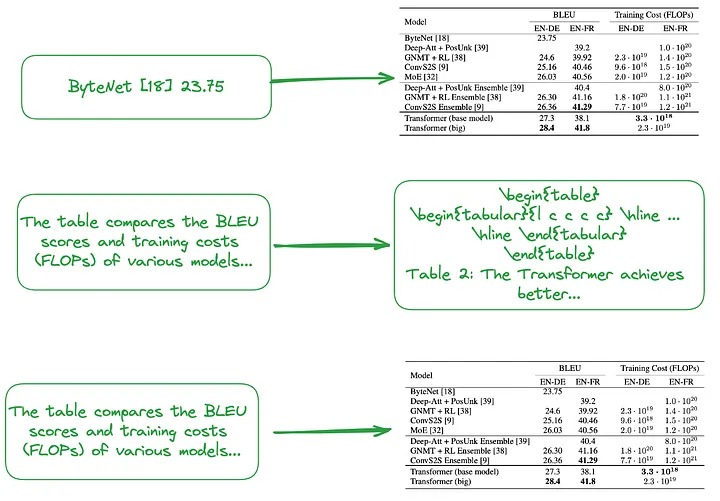
Abbildung 2: Indizierung von klein nach groß (oben) und Verwendung von Tabellenzusammenfassungen (Mitte, unten). Bild vom Originalautor zur Verfügung gestellt.
Wie oben erwähnt, werden tabellarische Zusammenfassungen typischerweise mithilfe der LLM-Verarbeitung generiert:
- Eingabe: Bildformat, Textformat oder Tabelle im LaTeX-Format
- Ausgabe: Tabellenzusammenfassung
1.3 Ein Ansatz, der kein Parsen von Tabellen, kein Erstellen von Indizes oder die Verwendung von RAG-Technologie erfordert
Einige Algorithmen erfordern kein Parsen von Tabellendaten.
(j). Senden Sie das relevante Bild (PDF-Dokumentseite) und die Anfrage des Benutzers an das VQA-Modell (z. B. DAN [7] usw.) (Anmerkung des Übersetzers: Abkürzung für Visual Question Answering Model. Es handelt sich um eine Kombination aus Computermodellen von Seh- und Verarbeitungstechniken natürlicher Sprache, die zur Beantwortung natürlichsprachlicher Fragen zu Bildinhalten verwendet werden können) oder multimodales LLM und Rückgabeantworten.
- Zu indizierender Inhalt: Dokumente im Bildformat
- Was an das VQA-Modell oder multimodale LLM gesendet werden soll: Abfrage + entsprechende Dokumentationsseite als Bild
(k). Senden Sie die PDF-Seite im relevanten Textformat und die Anfrage des Benutzers an LLM und senden Sie dann die Antwort zurück.
- Zu indizierender Inhalt: Dokumente im Textformat
- An LLM gesendeter Inhalt: Abfrage + entsprechende Dokumentationsseite im Textformat
(l). Senden Sie relevante Dokumentbilder (PDF-Dokumentseiten), Textblöcke und die Anfrage des Benutzers an multimodales LLM (z. B. GPT-4V usw.) und geben Sie die Antwort dann direkt zurück.
- Zu indizierende Inhalte: Dokumente im Bildformat und Dokumentblöcke im Textformat
- An multimodales LLM gesendeter Inhalt: Abfrage + Dokument im entsprechenden Bildformat + entsprechende Textblöcke
Darüber hinaus sind hier einige Methoden aufgeführt, die keine Indizierung erfordern, wie in den Abbildungen 3 und 4 dargestellt:
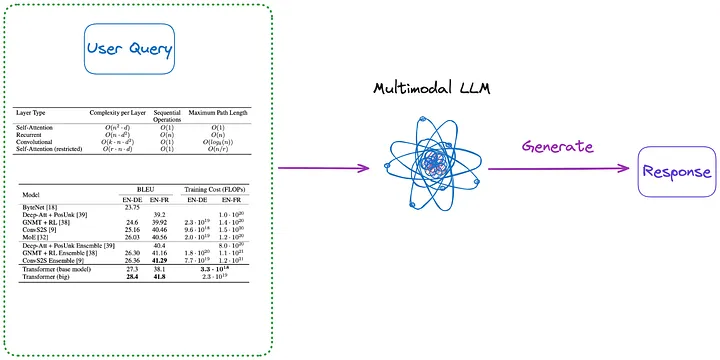
Abbildung 3: Kategorie (m) (Anmerkung des Übersetzers: Inhalt im ersten Absatz unten eingeführt). Bild vom Originalautor zur Verfügung gestellt.
(m). Analysieren Sie zunächst alle Tabellen im Dokument mit einer der Methoden von (a) bis (d) in Bildform. Anschließend werden alle Tabellenbilder und die Anfrage des Benutzers direkt an ein multimodales LLM (z. B. GPT-4V usw.) gesendet und die Antwort zurückgegeben.
- Zu indizierender Inhalt: Keiner
- An multimodales LLM gesendeter Inhalt: Abfrage + alle Tabellen, die in das Bildformat konvertiert wurden
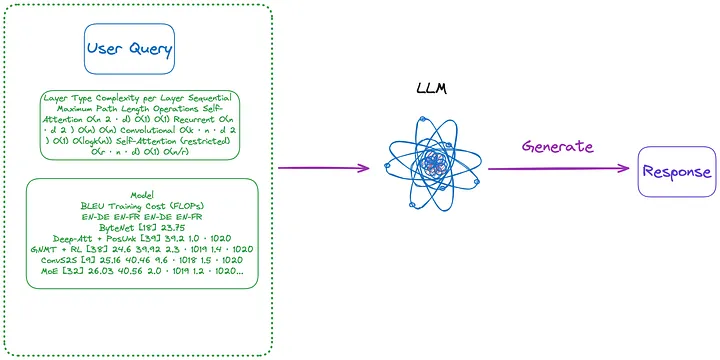
Abbildung 4: Kategorie (n) (Anmerkung des Übersetzers: Inhalt im ersten Absatz unten eingeführt). Bild vom Originalautor zur Verfügung gestellt.
(n). Verwenden Sie die Tabelle im Bildformat, das mit der (m)-Methode extrahiert wurde, und verwenden Sie dann das OCR-Modell, um den gesamten Text in der Tabelle zu identifizieren, und senden Sie dann den gesamten Text in der Tabelle und die Abfrage des Benutzers direkt an LLM , und geben Sie die Antwort direkt zurück.
- Zu indizierender Inhalt: Keiner
- An LLM gesendeter Inhalt: Benutzerabfrage + alle Tabelleninhalte (im Textformat gesendet)
Es ist zu beachten, dass bei der Verarbeitung von Tabellen in Dokumenten einige Methoden nicht die RAG-Technologie (Retrieval-Augmented Generation) verwenden:
- Der erste Methodentyp verwendet kein LLM, sondern trainiert anhand eines bestimmten Datensatzes, sodass KI-Modelle (z. B. andere Sprachmodelle, die auf der Transformer-Architektur basieren und von BERT inspiriert sind) die Verarbeitung von Tabellenverständnisaufgaben besser unterstützen können, z TAPAS [8 ].
- Die zweite Art von Methode ist die Verwendung von LLM unter Verwendung von Vortrainings-, Feinabstimmungsmethoden oder Prompt-Word-Engineering, damit LLM Tabellenverständnisaufgaben wie GPT4Table [9] erledigen kann.
02 Bestehende Open-Source-Lösungen für die Tabellenverarbeitung
Im vorherigen Abschnitt wurden die Schlüsseltechnologien für die tabellarische Datenverarbeitung in RAG-Systemen zusammengefasst und klassifiziert. Bevor wir die Lösung vorschlagen, die wir in diesem Artikel implementieren werden, schauen wir uns einige Open-Source-Lösungen an.
LlamaIndex schlägt vier Methoden vor [10], von denen die ersten drei alle multimodale Modelle verwenden.
- Rufen Sie das relevante PDF-Seitenbild ab und senden Sie es als Antwort auf die Benutzeranfrage an GPT-4V.
- Konvertieren Sie jede PDF-Seite in ein Bildformat und lassen Sie GPT-4V die Bildbeurteilung auf jeder Seite durchführen. Erstellen Sie einen Text Vector Store-Index für den Bildbegründungsprozess (Anmerkung des Übersetzers: Konvertieren Sie die aus dem Bild abgeleiteten Textinformationen in Vektorform und erstellen Sie einen Index) und verwenden Sie dann den Image Reasoning Vector Store (Anmerkung des Übersetzers: Es sollte der vorherige Index sein , Fragen Sie den zuvor erstellten Text Vector Store-Index ab, um die Antwort zu finden.
- Verwenden Sie Table Transformer, um Tabelleninformationen aus den abgerufenen Bildern zuzuschneiden, und senden Sie diese zugeschnittenen Tabellenbilder dann an GPT-4V, um Abfrageantworten zu erhalten (Anmerkung des Übersetzers: Senden Sie eine Abfrage an das Modell und erhalten Sie die vom Modell zurückgegebenen Antworten).
- Wenden Sie OCR auf das zugeschnittene Tabellenbild an und senden Sie die Daten an GPT4/GPT-3.5, um die Anfrage des Benutzers zu beantworten.
Um die oben genannten vier Methoden zusammenzufassen:
- Die erste Methode ähnelt der in diesem Artikel vorgestellten Methode (j) und erfordert keine Tabellenanalyse. Es stellt sich jedoch heraus, dass die Antwort zwar direkt im Bild zu sehen ist, aber nicht die richtige Antwort liefert.
- Die zweite Methode beinhaltet das Parsen von Tabellen und entspricht Methode (a). Der Indexinhalt kann tabellarischer Inhalt oder Inhaltszusammenfassungen sein, abhängig von den von GPT-4V zurückgegebenen Ergebnissen, die der Methode (f) oder (h) entsprechen können. Der Nachteil dieses Ansatzes besteht darin, dass die Fähigkeit von GPT-4V, Tabellen zu identifizieren und deren Inhalte aus Dokumentbildern zu extrahieren, inkonsistent ist, insbesondere wenn das Dokumentbild Tabellen, Text und andere Bilder enthält (was in PDF-Dokumenten häufig vorkommt).
- Die dritte Methode ähnelt Methode (m) und erfordert keine Indizierung.
- Die vierte Methode ähnelt Methode (n) und erfordert ebenfalls keine Indizierung. Die Ergebnisse zeigten, dass der Grund für die falschen Antworten darin lag, dass es nicht möglich war, tabellarische Informationen effektiv aus den Bildern zu extrahieren.
Durch Tests wurde festgestellt, dass die dritte Methode insgesamt die beste Wirkung hat. Den von mir durchgeführten Tests zufolge hatte die dritte Methode jedoch Schwierigkeiten, die Tabelle zu erkennen, geschweige denn den Tabellentitel und den Tabelleninhalt korrekt zu extrahieren und zuzuordnen.
Langchain schlug auch einige Lösungen für die halbstrukturierte Daten-RAG-Technologie (Semi-Structured RAG) [11] vor. Zu den Kerntechnologien gehören:
- Verwenden Sie für die Tabellenanalyse unstrukturiert, eine Methode der Klasse (c).
- Die Indexmethode ist der Dokumentzusammenfassungsindex (Anmerkung des Übersetzers: Dokumentzusammenfassungsinformationen als Indexinhalt verwenden), der zur Methode der Klasse (i) gehört. Der Datenblock, der der feinkörnigen Indexebene entspricht: Inhalt der Tabellenzusammenfassung, und der Datenblock, der der grobkörnigen Indexebene entspricht: ursprünglicher Tabelleninhalt (Textformat).
Wie in Abbildung 5 dargestellt:
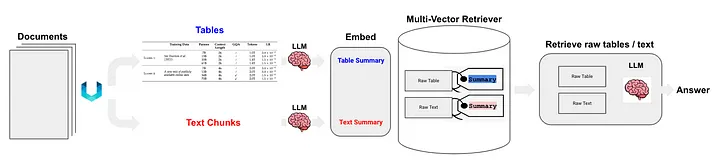
Abbildung 5: Die halbstrukturierte RAG-Lösung von Langchain. Quelle: Halbstrukturiertes RAG[11]
Die halbstrukturierte und multimodale RAG [12] schlug drei Lösungen vor, deren Architektur in Abbildung 6 dargestellt ist.
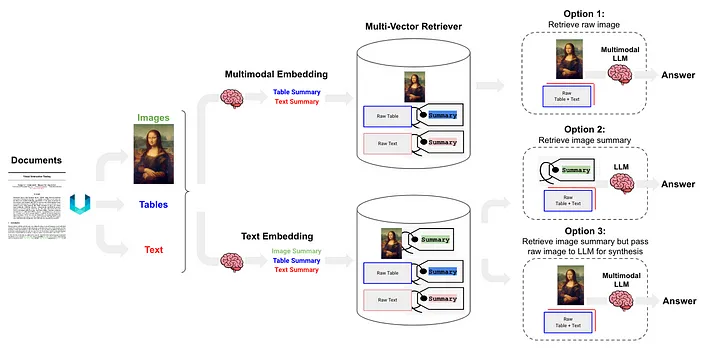
Abbildung 6: Langchains halbstrukturiertes und multimodales RAG-Schema. Quelle: Semistrukturierte und multimodale RAG[12].
Option 1 ähnelt der oben genannten Methode (l). Bei diesem Ansatz werden multimodale Einbettungen (z. B. CLIP [13]) verwendet, um Bilder und Text in Einbettungsvektoren umzuwandeln. Anschließend wird ein Ähnlichkeitssuchalgorithmus verwendet, um beide abzurufen und die unverarbeiteten Bild- und Textdaten zu konvertieren gemeinsam bearbeitet werden und Antworten auf Fragen generieren.
Option 2 verwendet multimodales LLM (wie GPT-4V[14], LLaVA[15] oder FUYU-8b[16]), um das Bild zu verarbeiten und Textzusammenfassungen zu generieren. Die Textdaten werden dann in Einbettungsvektoren umgewandelt und diese Vektoren werden zum Suchen oder Abrufen von Textinhalten verwendet, die der vom Benutzer gestellten Anfrage entsprechen, und an das LLM übergeben, um Antworten zu generieren.
- Tabellendaten werden mithilfe der unstrukturierten Methode analysiert, die zur Klasse (d) gehört.
- Die Indizierungsmethode ist der Dokumentzusammenfassungsindex (Anmerkung des Übersetzers: Dokumentzusammenfassungsinformationen werden als Indexinhalt verwendet), der zur (i) Klassenmethode gehört. Der Datenblock entspricht der feinkörnigen Indexebene: Tabellenzusammenfassungsinhalt und die Daten Block, der der grobkörnigen Indexebene entspricht: Text Tabelleninhalt formatieren.
Option 3 verwendet multimodales LLM (wie GPT-4V [14], LLaVA [15] oder FUYU-8b [16]), um Textzusammenfassungen aus Bilddaten zu generieren und diese Textzusammenfassungen dann mithilfe dieser Einbettungsvektoren in Vektoren einzubetten , Bildzusammenfassungen können effizient abgerufen werden (Abrufen). In jeder abgerufenen Bildzusammenfassung wird ein entsprechender Verweis auf das Rohbild (Referenz auf das Rohbild) beibehalten. Dies gehört schließlich zu den unverarbeiteten Bilddaten und Textblöcke werden an das multimodale LLM übergeben, um Antworten zu generieren.
03 Die in diesem Artikel vorgeschlagene Lösung
Die Schlüsseltechnologien und bestehenden Lösungen werden im vorherigen Artikel zusammengefasst, klassifiziert und diskutiert. Auf dieser Grundlage schlagen wir die folgende Lösung vor, wie in Abbildung 7 dargestellt. Der Einfachheit halber wurden einige RAG-Module wie Re-Ranking und Query Rewriting in der Abbildung weggelassen.
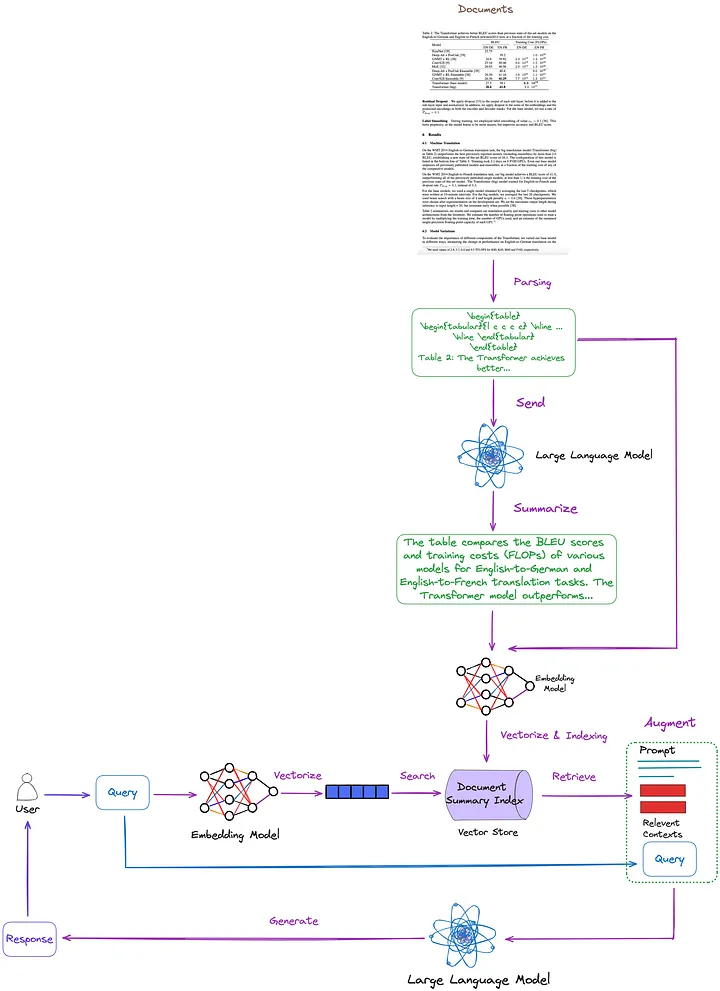
Abbildung 7: Die in diesem Artikel vorgeschlagene Lösung. Bild vom Originalautor zur Verfügung gestellt.
- Tabellenanalysetechnik: Verwendung von Nougat ((d)-Klassenmethode). Nach meinen Tests sind die Tabellenerkennungsfunktionen dieses Tools effektiver als unstrukturierte Tabellen (eine Technik vom Typ (c)). Darüber hinaus kann Nougat auch Tabellentitel sehr gut extrahieren, was die Verknüpfung mit Tabellen sehr komfortabel macht.
- Indexstruktur zum Indizieren und Abrufen von Dokumentzusammenfassungen (Methoden der Klasse (i)): Die feinkörnige Indexebene enthält tabellarische Inhaltszusammenfassungen und die grobkörnige Indexebene enthält entsprechende Tabellen im LaTeX-Format und Tabellentitel im Textformat. Wir verwenden einen Multi-Vektor-Retriever[17] (Anmerkung des Übersetzers: Ein Retriever zum Abrufen von Inhalten in einem Dokumentzusammenfassungsindex, der mehrere Vektoren gleichzeitig verarbeiten kann, um Dokumentzusammenfassungen im Zusammenhang mit der Abfrage effizient abzurufen.) zur Erfüllung.
- So erhalten Sie eine Zusammenfassung des Tabelleninhalts: Senden Sie die Tabelle und den Tabellentitel zur Inhaltszusammenfassung an LLM.
Der Vorteil dieser Methode besteht darin, dass sie die Tabelle effektiv analysieren und die Beziehung zwischen der Tabellenzusammenfassung und der Tabelle vollständig berücksichtigen kann. Eliminiert die Notwendigkeit, multimodales LLM zu verwenden, was zu Kosteneinsparungen führt.
3.1 Wie Nougat funktioniert
Nougat [18] wird auf der Grundlage der Donut-Architektur [19] entwickelt. Dieser Ansatz verwendet Algorithmen, die Text automatisch implizit erkennen können, ohne dass OCR-bezogene Eingaben oder Module erforderlich sind.
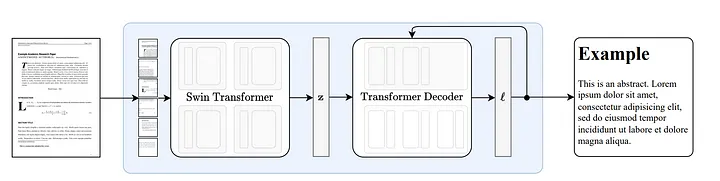
Abbildung 8: End-to-End-Architektur nach Donut [19]. Der Swin Transformer-Encoder nimmt ein Dokumentbild und wandelt es in latente Einbettungen um (Anmerkung des Übersetzers: Die Informationen des Bildes werden in einem latenten Raum codiert) und wandelt es dann auf autoregressive Weise in eine Folge von Token um. Quelle: Nougat: Neural Optical Understanding for Academic Documents.[18]
Die Fähigkeit von Nougat, Formeln zu analysieren, ist beeindruckend[20], aber auch seine Fähigkeit, Tabellen zu analysieren, ist außergewöhnlich. Wie in Abbildung 9 dargestellt, kann es mit Tabellentiteln verknüpft werden, was sehr praktisch ist:

Abbildung 9: Nougat-Laufergebnisse. Die Ergebnisdatei liegt im Mathpix-Markdown-Format vor (kann über das vscode-Plug-in geöffnet werden) und die Tabelle wird im LaTeX-Format dargestellt.
Bei einem Test, den ich mit einem Dutzend Arbeiten durchführte, stellte ich fest, dass Tabellentitel immer auf die nächste Zeile der Tabelle fixiert waren. Diese Konsistenz legt nahe, dass dies kein Zufall war. Daher interessiert uns mehr, wie Nougat diese Funktionalität erreicht.
Da es sich um ein End-to-End-Modell ohne Zwischenergebnisse handelt, hängt seine Leistung wahrscheinlich stark von seinen Trainingsdaten ab.
Basierend auf der Codeanalyse scheint der Speicherort und die Art und Weise, in der der Tabellenkopfabschnitt gespeichert wird, mit dem Organisationsformat der Tabelle in den Trainingsdaten übereinzustimmen (und diesem unmittelbar \end{table} zu folgen ).caption_parts
def format_element(
element: Element, keep_refs: bool = False, latex_env: bool = False
) -> List[str]:
"""
Formats a given Element into a list of formatted strings.
Args:
element (Element): The element to be formatted.
keep_refs (bool, optional): Whether to keep references in the formatting. Default is False.
latex_env (bool, optional): Whether to use LaTeX environment formatting. Default is False.
Returns:
List[str]: A list of formatted strings representing the formatted element.
"""
...
...
if isinstance(element, Table):
parts = [
"[TABLE%s]\n\begin{table}\n"
% (str(uuid4())[:5] if element.id is None else ":" + str(element.id))
]
parts.extend(format_children(element, keep_refs, latex_env))
caption_parts = format_element(element.caption, keep_refs, latex_env)
remove_trailing_whitespace(caption_parts)
parts.append("\end{table}\n")
if len(caption_parts) > 0:
parts.extend(caption_parts + ["\n"])
parts.append("[ENDTABLE]\n\n")
return parts
...
...
3.2 Vor- und Nachteile von Nougat
Vorteil:
- Nougat kann Abschnitte, die mit früheren Parsing-Tools nur schwer zu parsen waren, wie Formeln und Tabellen, präzise in LaTeX-Quellcode parsen.
- Das Ergebnis der Analyse von Nougat ist ein halbstrukturiertes Dokument ähnlich wie Markdown.
- Möglichkeit, Tabellentitel einfach abzurufen und sie problemlos mit Tabellen zu verknüpfen.
Mangel:
- Die Parsing-Geschwindigkeit von Nougat ist langsam, was bei großen Anwendungen zu Schwierigkeiten führen kann.
- Da es sich bei Nougats Trainingsdatensatz im Wesentlichen um wissenschaftliche Arbeiten handelt, eignet sich diese Technik gut für Dokumente mit ähnlichen Strukturen. Bei der Verarbeitung nicht-lateinischer Textdokumente nimmt die Leistung ab.
- Das Nougat-Modell trainiert immer nur auf einer Seite einer wissenschaftlichen Arbeit und verfügt nicht über Kenntnisse über andere Seiten. Dies kann zu Inkonsistenzen im analysierten Inhalt führen. Wenn der Erkennungseffekt nicht gut ist, können Sie daher erwägen, die PDF-Datei in einzelne Seiten aufzuteilen und diese Seite für Seite zu analysieren.
- Das Parsen von Tabellen in zweispaltigen Arbeiten ist nicht so gut wie in einspaltigen Arbeiten.
3.3 Code-Implementierung
Installieren Sie zunächst die relevanten Python-Pakete:
pip install langchain
pip install chromadb
pip install nougat-ocr
Nachdem die Installation abgeschlossen ist, müssen Sie die Version des Python-Pakets überprüfen:
langchain 0.1.12
langchain-community 0.0.28
langchain-core 0.1.31
langchain-openai 0.0.8
langchain-text-splitters 0.0.1
chroma-hnswlib 0.7.3
chromadb 0.4.24
nougat-ocr 0.1.17
Richten Sie eine Arbeitsumgebung ein und importieren Sie Pakete:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
Laden Sie den Artikel „Aufmerksamkeit ist alles, was Sie brauchen“ [21] in den Pfad herunter YOUR_PDF_PATH, führen Sie Nougat aus, um die PDF-Datei zu analysieren, und erhalten Sie aus den Analyseergebnissen die Tabellendaten im Latexformat und den Tabellentitel im Textformat. Wenn Sie das Programm zum ersten Mal ausführen, werden die erforderlichen Modelldateien in die lokale Umgebung heruntergeladen.
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
Die Funktion june_get_tables_from_mmd wird verwendet, um alle Inhalte aus einer mmd-Datei zu extrahieren (von \begin{table} bis \end{table}, aber auch einschließlich \end{table} der ersten Zeile danach), wie in Abbildung 10 dargestellt.

Abbildung 10: Nougat-Laufergebnisse. Die Ergebnisdatei liegt im Mathpix-Markdown-Format vor (kann über das vscode-Plug-in geöffnet werden) und der analysierte Tabelleninhalt liegt im Latex-Format vor. Die Funktion june_get_tables_from_mmd besteht darin, die Tabelleninformationen im roten Feld zu extrahieren. Bild vom Originalautor zur Verfügung gestellt.
Allerdings gibt es kein offizielles Dokument, das besagt, dass der Tabellentitel unterhalb der Tabelle platziert werden muss oder dass die Tabelle mit \begin{table} beginnen und mit \end{table} enden soll. Daher ist june_get_tables_from_mmd eine heuristische Methode.
Das Folgende sind die Ergebnisse der Tabellenanalyse des PDF-Dokuments:
Operation Completed!
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \ \hline Self-Attention & (O(n^{2}\cdot d)) & (O(1)) & (O(1)) \ Recurrent & (O(n\cdot d^{2})) & (O(n)) & (O(n)) \ Convolutional & (O(k\cdot n\cdot d^{2})) & (O(1)) & (O(log_{k}(n))) \ Self-Attention (restricted) & (O(r\cdot n\cdot d)) & (O(1)) & (O(n/r)) \ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. (n) is the sequence length, (d) is the representation dimension, (k) is the kernel size of convolutions and (r) the size of the neighborhood in restricted self-attention.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \ \hline ByteNet [18] & 23.75 & & & \ Deep-Att + PosUnk [39] & & 39.2 & & (1.0\cdot 10^{20}) \ GNMT + RL [38] & 24.6 & 39.92 & (2.3\cdot 10^{19}) & (1.4\cdot 10^{20}) \ ConvS2S [9] & 25.16 & 40.46 & (9.6\cdot 10^{18}) & (1.5\cdot 10^{20}) \ MoE [32] & 26.03 & 40.56 & (2.0\cdot 10^{19}) & (1.2\cdot 10^{20}) \ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & (8.0\cdot 10^{20}) \ GNMT + RL Ensemble [38] & 26.30 & 41.16 & (1.8\cdot 10^{20}) & (1.1\cdot 10^{21}) \ ConvS2S Ensemble [9] & 26.36 & **41.29** & (7.7\cdot 10^{19}) & (1.2\cdot 10^{21}) \ \hline Transformer (base model) & 27.3 & 38.1 & & (\mathbf{3.3\cdot 10^{18}}) \ Transformer (big) & **28.4** & **41.8** & & (2.3\cdot 10^{19}) \ \hline \hline \end{tabular}
\end{table}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c c c c c c c c|c c c c} \hline \hline & (N) & (d_{\text{model}}) & (d_{\text{ff}}) & (h) & (d_{k}) & (d_{v}) & (P_{drop}) & (\epsilon_{ls}) & train steps & PPL & BLEU & params \ \hline base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \ \hline \multirow{4}{*}{(A)} & \multicolumn{1}{c}{} & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \ & & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \ & & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \ & & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \ \hline (B) & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & 16 & & & & & 5.16 & 25.1 & 58 \ & & & & & 32 & & & & & 5.01 & 25.4 & 60 \ \hline \multirow{4}{*}{(C)} & 2 & \multicolumn{1}{c}{} & & & & & & & & 6.11 & 23.7 & 36 \ & 4 & & & & & & & & 5.19 & 25.3 & 50 \ & 8 & & & & & & & & 4.88 & 25.5 & 80 \ & & 256 & & 32 & 32 & & & & 5.75 & 24.5 & 28 \ & 1024 & & 128 & 128 & & & & 4.66 & 26.0 & 168 \ & & 1024 & & & & & & 5.12 & 25.4 & 53 \ & & 4096 & & & & & & 4.75 & 26.2 & 90 \ \hline \multirow{4}{*}{(D)} & \multicolumn{1}{c}{} & & & & & 0.0 & & 5.77 & 24.6 & \ & & & & & & 0.2 & & 4.95 & 25.5 & \ & & & & & & & 0.0 & 4.67 & 25.3 & \ & & & & & & & 0.2 & 5.47 & 25.7 & \ \hline (E) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & & & & 4.92 & 25.7 & \ \hline big & 6 & 1024 & 4096 & 16 & & 0.3 & 300K & **4.33** & **26.4** & 213 \ \hline \hline \end{tabular}
\end{table}
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c|c} \hline
**Parser** & **Training** & **WSJ 23 F1** \ \hline Vinyals & Kaiser et al. (2014) [37] & WSJ only, discriminative & 88.3 \ Petrov et al. (2006) [29] & WSJ only, discriminative & 90.4 \ Zhu et al. (2013) [40] & WSJ only, discriminative & 90.4 \ Dyer et al. (2016) [8] & WSJ only, discriminative & 91.7 \ \hline Transformer (4 layers) & WSJ only, discriminative & 91.3 \ \hline Zhu et al. (2013) [40] & semi-supervised & 91.3 \ Huang & Harper (2009) [14] & semi-supervised & 91.3 \ McClosky et al. (2006) [26] & semi-supervised & 92.1 \ Vinyals & Kaiser el al. (2014) [37] & semi-supervised & 92.1 \ \hline Transformer (4 layers) & semi-supervised & 92.7 \ \hline Luong et al. (2015) [23] & multi-task & 93.0 \ Dyer et al. (2016) [8] & generative & 93.3 \ \hline \end{tabular}
\end{table}
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014.
Verwenden Sie dann LLM, um die Tabellendaten zusammenzufassen:
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
Das Folgende ist eine Zusammenfassung des Inhalts der vier Tabellen in „Attention Is All You Need“ [21], wie in Abbildung 11 dargestellt:
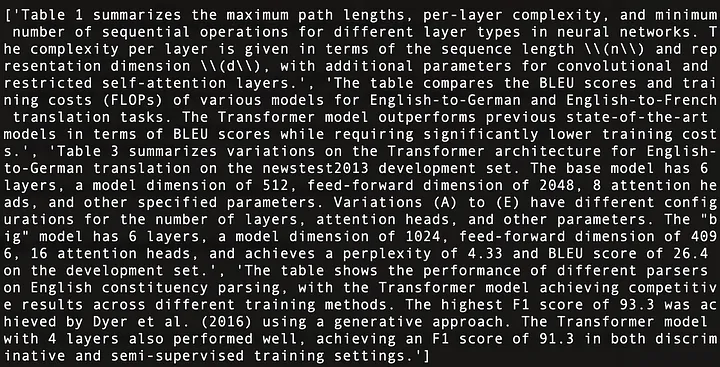
Abbildung 11: Inhaltliche Zusammenfassung der vier Tabellen in „Attention Is All You Need“ [21].
Verwenden Sie Multi-Vector Retriever (Anmerkung des Übersetzers: Ein Retriever zum Abrufen von Inhalten im Dokumentzusammenfassungsindex. Der Retriever kann mehrere Vektoren gleichzeitig verarbeiten, um Dokumentzusammenfassungen im Zusammenhang mit der Abfrage effektiv abzurufen.) Erstellen Sie eine Dokumentzusammenfassungsindexstruktur [17] (Anmerkung des Übersetzers: Eine Indexstruktur, die zum Speichern zusammenfassender Informationen von Dokumenten verwendet wird. Diese zusammenfassenden Informationen können bei Bedarf abgerufen oder abgefragt werden.)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
Sobald alles fertig ist, richten Sie eine einfache RAG-Pipeline ein und führen Sie die Abfragen des Benutzers aus:
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
Die laufenden Ergebnisse lauten wie folgt: Diese Fragen wurden korrekt beantwortet, wie in Abbildung 12 dargestellt:

Abbildung 12: Antworten auf drei Benutzeranfragen. Die erste Zeile entspricht Tabelle 1, die zweite Zeile Tabelle 2 und die dritte Zeile Tabelle 4 in Attention Is All You Need.
Der Gesamtcode lautet wie folgt:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
04 Fazit
In diesem Artikel werden Schlüsseltechnologien und bestehende Lösungen für Tabellenverarbeitungsvorgänge in RAG-Systemen erörtert und eine Lösung und deren Implementierung vorgeschlagen.
In diesem Artikel haben wir Nougat zum Parsen von Tabellen verwendet. Wir werden jedoch darüber nachdenken, Nougat zu ersetzen, wenn ein schnelleres und effizienteres Parsing-Tool verfügbar wird. Unsere Einstellung zu Werkzeugen besteht darin, zuerst die richtige Idee zu haben und dann Werkzeuge zu finden, um sie umzusetzen, anstatt uns auf ein bestimmtes Werkzeug zu verlassen.
In diesem Artikel geben wir alle Tabelleninhalte in LLM ein. In realen Szenarien müssen wir jedoch die Situation berücksichtigen, in der die Tabellengröße die LLM-Kontextlänge überschreitet. Wir können dieses Problem lösen, indem wir effiziente Chunking-Methoden verwenden.
Danke fürs Lesen!
——
Florian Juni
Als Forscher für künstliche Intelligenz schreibt er hauptsächlich Artikel über große Sprachmodelle, Datenstrukturen und Algorithmen sowie NLP.
ENDE
Verweise
[1] https://openai.com/research/gpt-4v-system-card
[2] https://github.com/microsoft/table-transformer
[3] https://unstructured-io.github.io/unstructured/best_practices/table_extraction_pdf.html
[4] https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
[5] https://github.com/facebookresearch/nougat
[6] https://github.com/clovaai/donut/
[7] https://arxiv.org/pdf/1611.00471.pdf
[8] https://aclanthology.org/2020.acl-main.398.pdf
[9] https://arxiv.org/pdf/2305.13062.pdf
[10] https://docs.llamaindex.ai/en/stable/examples/multi_modal/multi_modal_pdf_tables.html
[13] https://openai.com/research/clip
[14] https://openai.com/research/gpt-4v-system-card
[16] https://www.adept.ai/blog/fuyu-8b
[17] https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[18] https://arxiv.org/pdf/2308.13418.pdf
[19] https://arxiv.org/pdf/2111.15664.pdf
[21] https://arxiv.org/pdf/1706.03762.pdf
Dieser Artikel wurde von Baihai IDP mit Genehmigung des ursprünglichen Autors zusammengestellt. Wenn Sie die Übersetzung erneut drucken müssen, kontaktieren Sie uns bitte für die Genehmigung.
Ursprünglicher Link:
https://ai.plainenglish.io/advanced-rag-07-exploring-rag-for-tables-5c3fc0de7af6
Wie viel Umsatz kann ein unbekanntes Open-Source-Projekt bringen? Das chinesische KI-Team von Microsoft hat zusammengepackt und ist mit Hunderten von Menschen in die USA gegangen. Huawei gab offiziell bekannt, dass Yu Chengdongs Jobwechsel an der „FFmpeg-Säule der Schande“ festgenagelt wurden vor, aber heute muss er uns danken – Tencent QQ Video rächt seine vergangene Demütigung? Die Open-Source-Spiegelseite der Huazhong University of Science and Technology ist offiziell für den externen Zugriff geöffnet. Bericht: Django ist immer noch die erste Wahl für 74 % der Entwickler. Zed-Editor hat Fortschritte bei der Linux-Unterstützung gemacht brachte die Nachricht: Nachdem er von einem Untergebenen herausgefordert wurde, wurde der technische Leiter wütend und unhöflich, wurde entlassen und schwanger. Die Mitarbeiterin von Alibaba Cloud veröffentlicht offiziell Tongyi Qianwen 2.5. Microsoft spendet 1 Million US-Dollar an die Rust Foundation