

The new generation visual generation paradigm "VAR: Visual Auto Regressive" is here! The GPT-style autoregressive model surpasses the diffusion model in image generation for the first time , and the Scaling Laws scaling law and Zero-shot Task Generalization generalization ability similar to the large language model are observed :
论文标题:Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
This new work called VAR was proposed by researchers from Peking University and ByteDance . It has been on the GitHub and Paperwithcode hot lists and has received a lot of attention from peers:
Currently, the experience website, papers, codes, and models have been released:
- Experience website: https://var.vision/
- Paper link: https://arxiv.org/abs/2404.02905
- Open source code: https://github.com/FoundationVision/VAR
- Open source model: https://huggingface.co/FoundationVision/var
Background introduction
In natural language processing, the Autoregressive autoregressive model, taking large language models such as GPT and LLaMa series as examples, has achieved great success. In particular, the Scaling Law scaling law and Zero-shot Task Generalizability have very impressive zero-shot task generalization capabilities. , initially showing the potential to lead to "general artificial intelligence AGI".
However, in the field of image generation, autoregressive models generally lag behind diffusion models: DALL-E3, Stable Diffusion3, SORA and other models that have been popular recently all belong to the Diffusion family. In addition, it is still unknown whether there is a "Scaling Law" in the field of visual generation , that is, whether the cross-entropy loss of the test set can show a predictable power-law downward trend with model or training overhead remains to be explored. .
The powerful capabilities and Scaling Law of the GPT formal autoregressive model seem to be "locked" in the field of image generation:

The autoregressive model lags behind many Diffusion models in the generation effect list
Focusing on "unlocking" the ability of autoregressive models and Scaling Laws, the research team started from the inherent nature of image modalities, imitated the logical sequence of human image processing , and proposed a new "visual autoregressive" generation paradigm: VAR, Visual AutoRegressive Modeling , for the first time, GPT-style autoregressive visual generation surpasses Diffusion in terms of effect, speed, and scaling capabilities, and ushered in Scaling Laws in the field of visual generation:

The core of the VAR method: imitating human vision and redefining the image autoregressive sequence
When humans perceive images or paint, they tend to get an overview first and then delve into details. This kind of thinking from coarse to fine, from grasping the whole to finely adjusting the part is very natural:
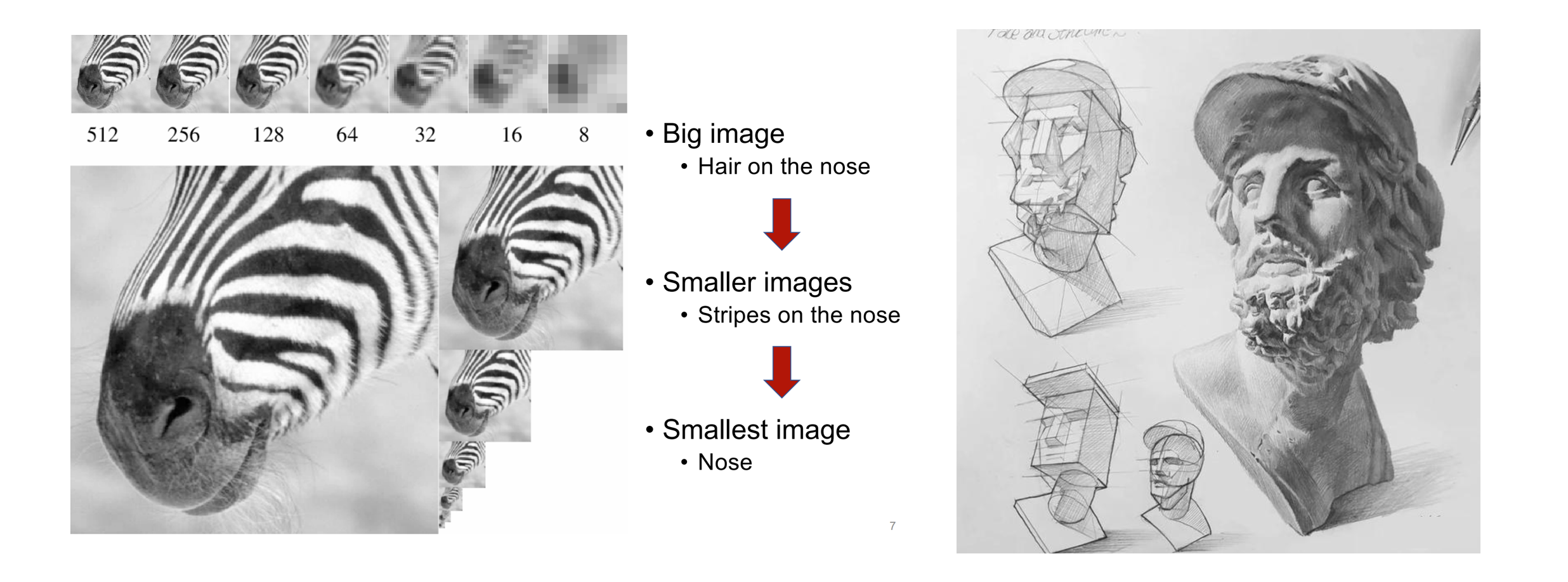
The logical sequence from coarse to fine of human perception of pictures (left) and creation of paintings (right)
However, traditional image autoregression (AR) uses an order that is not in line with human intuition (but suitable for computer processing), that is, a top-down, line-by-line raster order, to predict image tokens one by one:
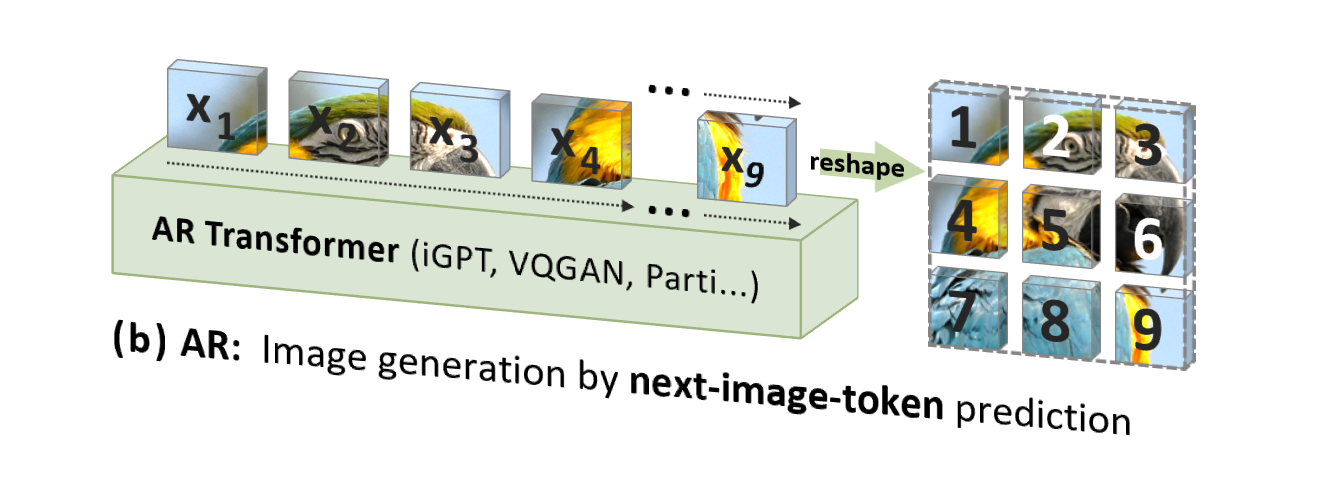
VAR is "people-oriented", imitating the logical sequence of human perception or human-created images , and gradually generates a token map using a multi-scale sequence from the whole to the details:
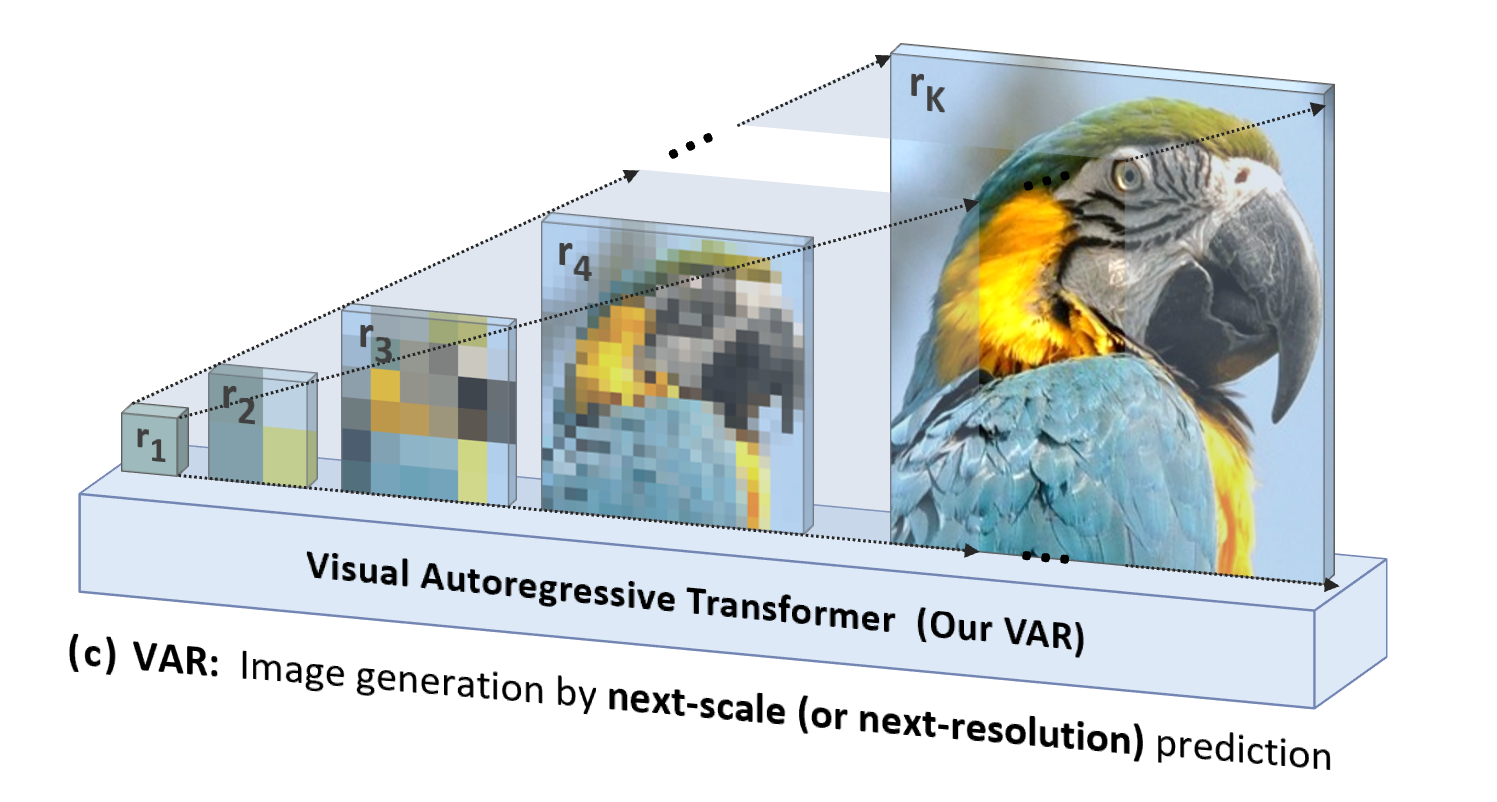
除了更自然、更符合人类直觉,VAR 带来的另一个显著优势是大幅提高了生成速度:在自回归的每一步(每一个尺度内部),所有图像 token 是一次性并行生成的;跨尺度则是自回归的。这使得在模型参数和图片尺寸相当的情况下,VAR能比传统AR快数十倍。此外,在实验中作者也观察到 VAR 相比 AR 展现出更强的性能和 Scaling 能力。
VAR method details: two-stage training
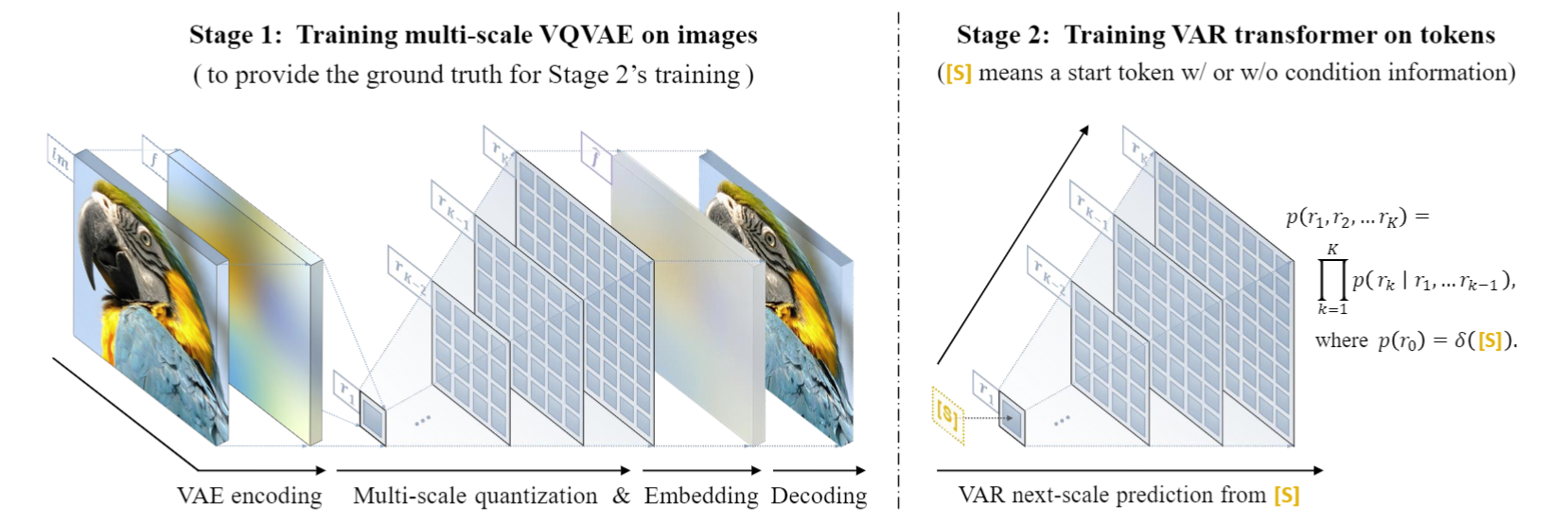
VAR trains a multi-scale quantization autoencoder (Multi-scale VQVAE) in the first stage, and trains an autoregressive Transformer consistent with the GPT-2 structure (combined with AdaLN) in the second stage.
As shown in the picture on the left, the training prequel details of VQVAE are as follows:
- Discrete coding : The encoder converts the picture into a discrete token map R=(r1, r2, ..., rk), with resolutions from small to large
- Continuousization : r1 to rk are first converted into continuous feature maps through the embedding layer, then uniformly interpolated to the maximum resolution corresponding to rk, and summed
- Continuous decoding : The summed feature map is passed through the decoder to obtain the reconstructed picture, and is trained through a mixture of three losses: reconstruction + perception + confrontation.
As shown in the figure on the right, after the VQVAE training is completed, the second stage of autoregressive Transformer training will be performed:
- The first step of autoregression is to predict the initial 1x1 token map from the starting **** token [S]
- At each subsequent step, VAR predicts the next larger scale token map based on all historical token maps.
- During the training phase, VAR uses standard cross-entropy loss to supervise the probability prediction of these token maps.
- In the testing phase, the sampled token map will be serialized, interpolated, summed, and decoded with the help of VQVAE decoder to obtain the final generated image.
The author said that the autoregressive framework of VAR is brand new, and the specific technology has absorbed the strengths of a series of classic technologies such as RQ-VAE's residual VAE, StyleGAN and DiT's AdaLN, and PGGAN's progressive training. VAR actually stands on the shoulders of giants and focuses on the innovation of the autoregressive algorithm itself.
Experimental effect comparison
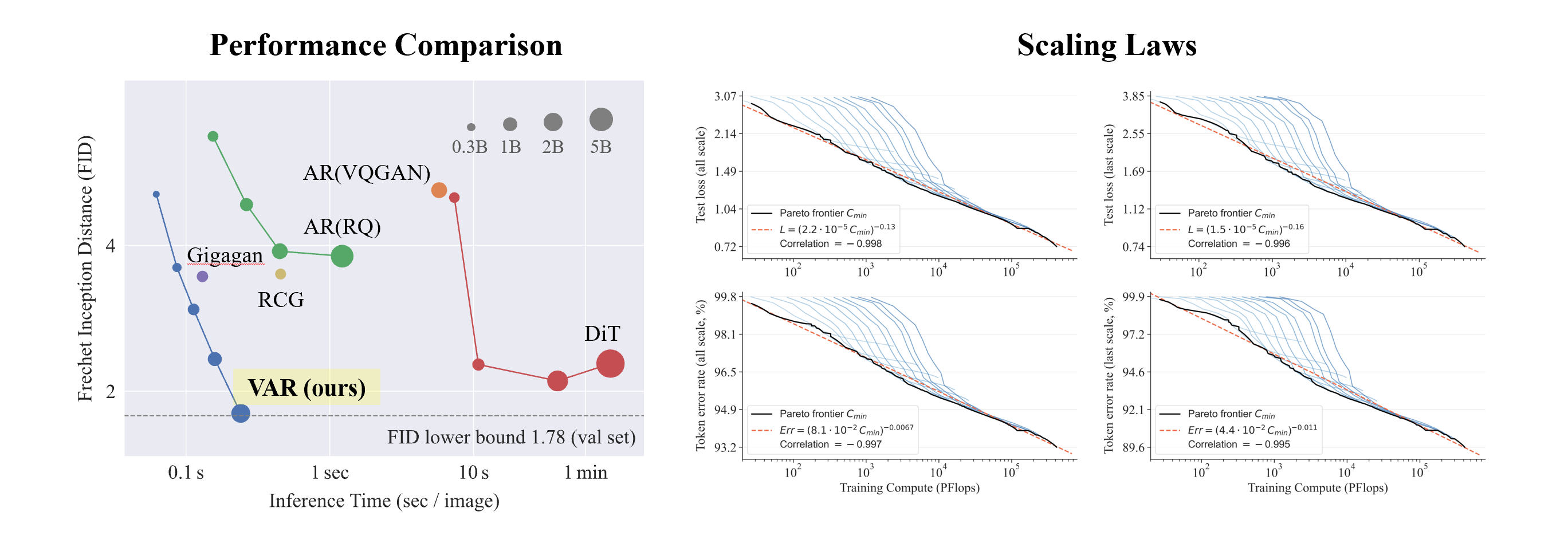
VAR experiments on Conditional ImageNet 256x256 and 512x512:
- VAR has greatly improved the effect of AR, turning AR from lagging behind Diffusion .
- VAR only requires 10 autoregressive steps, and its generation speed greatly exceeds AR and Diffusion, and even approaches the efficiency of GAN.
- By scaling up VAR to 2B/3B , VAR has reached the SOTA level, showing a new and potential family of generative models.

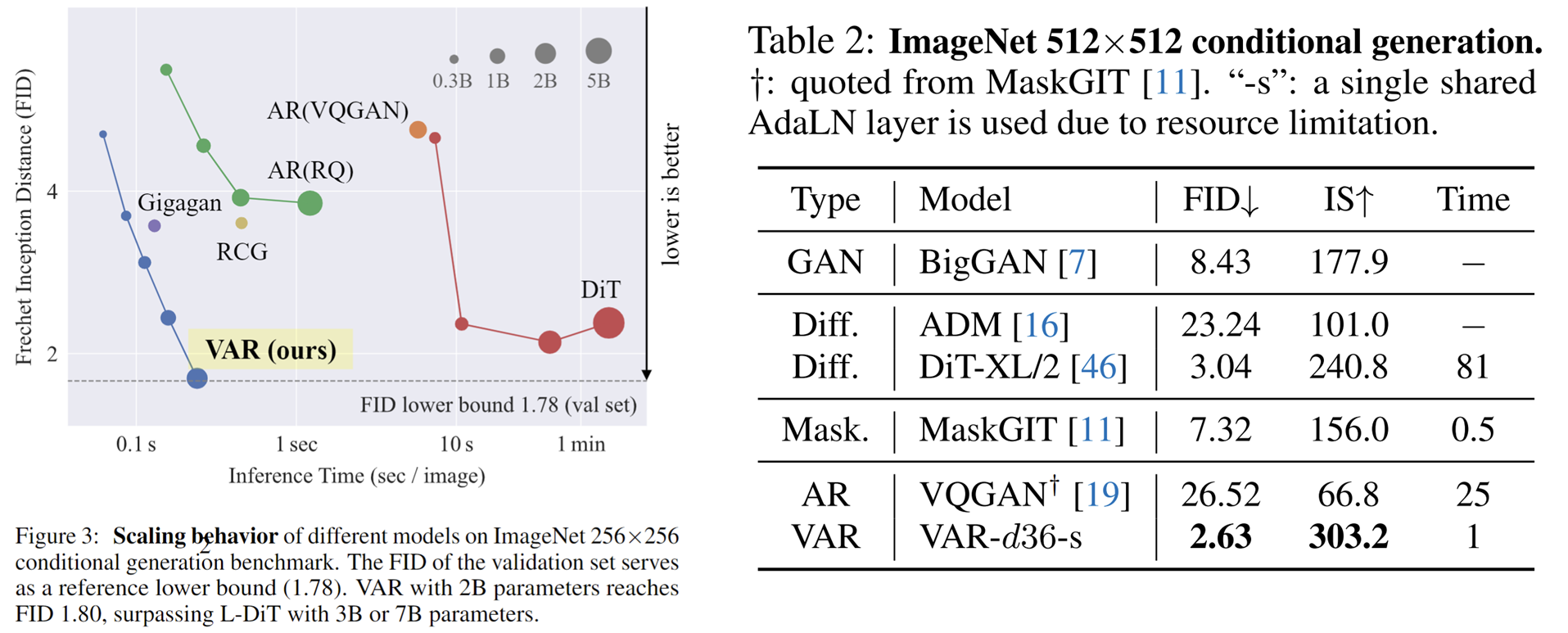
What is interesting is that, compared with SORA and Diffusion Transformer (DiT), the cornerstone model of Stable Diffusion 3 , VAR shows:
- 更好效果:经过 scale up,VAR 最终达到 FID=1.80,逼近理论上的 FID 下限 1.78(ImageNet validation set),显著优于 DiT 最优的 2.10
- Faster speed : VAR can generate a 256 image in less than 0.3 seconds , which is 45 times faster than DiT ; on 512, it is 81 times faster than DiT
- Better Scaling capabilities: As shown in the left figure, the DiT large model showed saturation after growing to 3B and 7B , and could not get closer to the FID lower limit; while VAR scaled to 2 billion parameters, its performance continued to improve, and finally touched the FID lower limit
- More efficient data utilization : VAR only requires 350 epoch training, which is more than DiT 1400 epoch training.
These evidences that it is more efficient, faster, and more scalable than DiT bring more possibilities to the next generation of visual generation infrastructure paths.
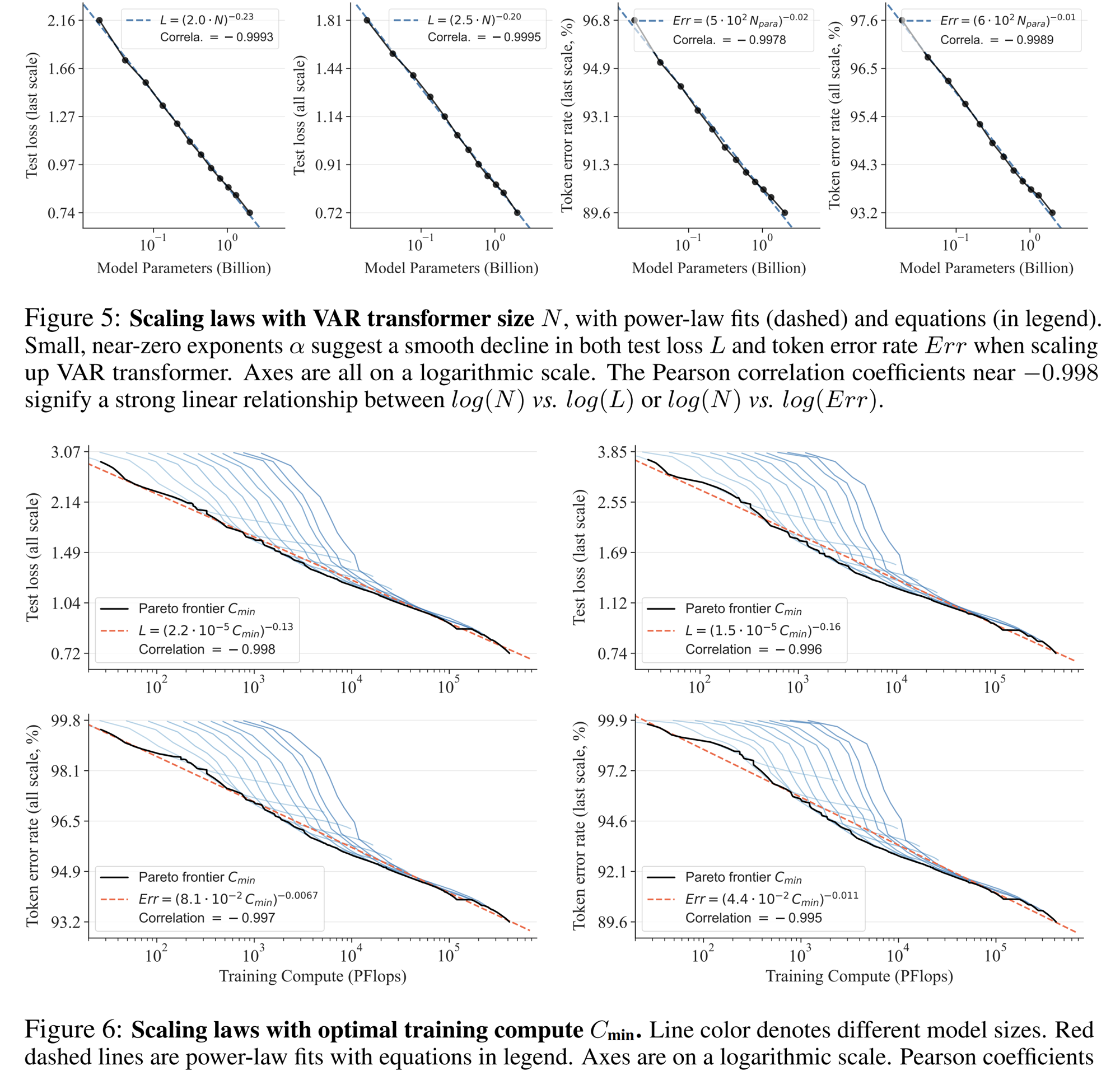
Scaling Law Experiment
Scaling law can be described as the "crown jewel" of large language models. Relevant research has determined that in the process of scaling up autoregressive large-scale language models, the cross-entropy loss L on the test set will decrease predictably with the number of model parameters N, the number of training tokens T, and the computational overhead Cmin . Expose the power-law relationship.
Scaling law not only makes it possible to predict the performance of large models based on small models, saving computing overhead and resource allocation, but also reflects the powerful learning ability of the autoregressive AR model. The test set performance increases with N, T, and Cmin.
Through experiments, researchers observed that VAR exhibits a power law Scaling Law that is almost identical to LLM : the researchers trained 12 sizes of models, with the number of scaling model parameters ranging from 18 million to 2 billion, and the total calculation amount spanned 6 orders of magnitude. , the maximum total number of tokens reaches 305 billion, and it is observed that the test set loss L or the test set error rate and N, between L and Cmin show a smooth power law relationship, and the fit is good:
In the process of scale-up model parameters and calculation volume, the model's generation ability can be seen to be gradually improved (such as the oscilloscope stripes below):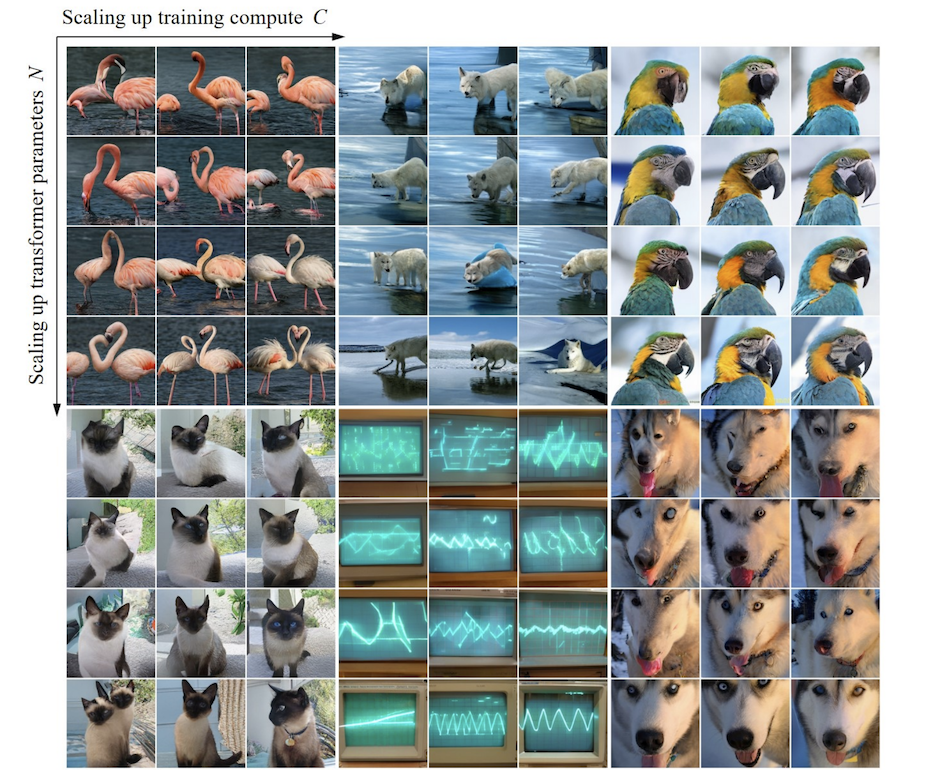
Zero-shot experiment
Thanks to the excellent property of the autoregressive model that it can use the Teacher-forcing mechanism to force certain tokens to remain unchanged, VAR also exhibits certain zero-sample task generalization capabilities. The VAR Transformer trained on the conditional generation task can generalize to some generative tasks without any fine-tuning without any fine-tuning, such as image completion (inpainting), image extrapolation (outpainting), and image editing (class-condition editing). ), and achieved certain results:
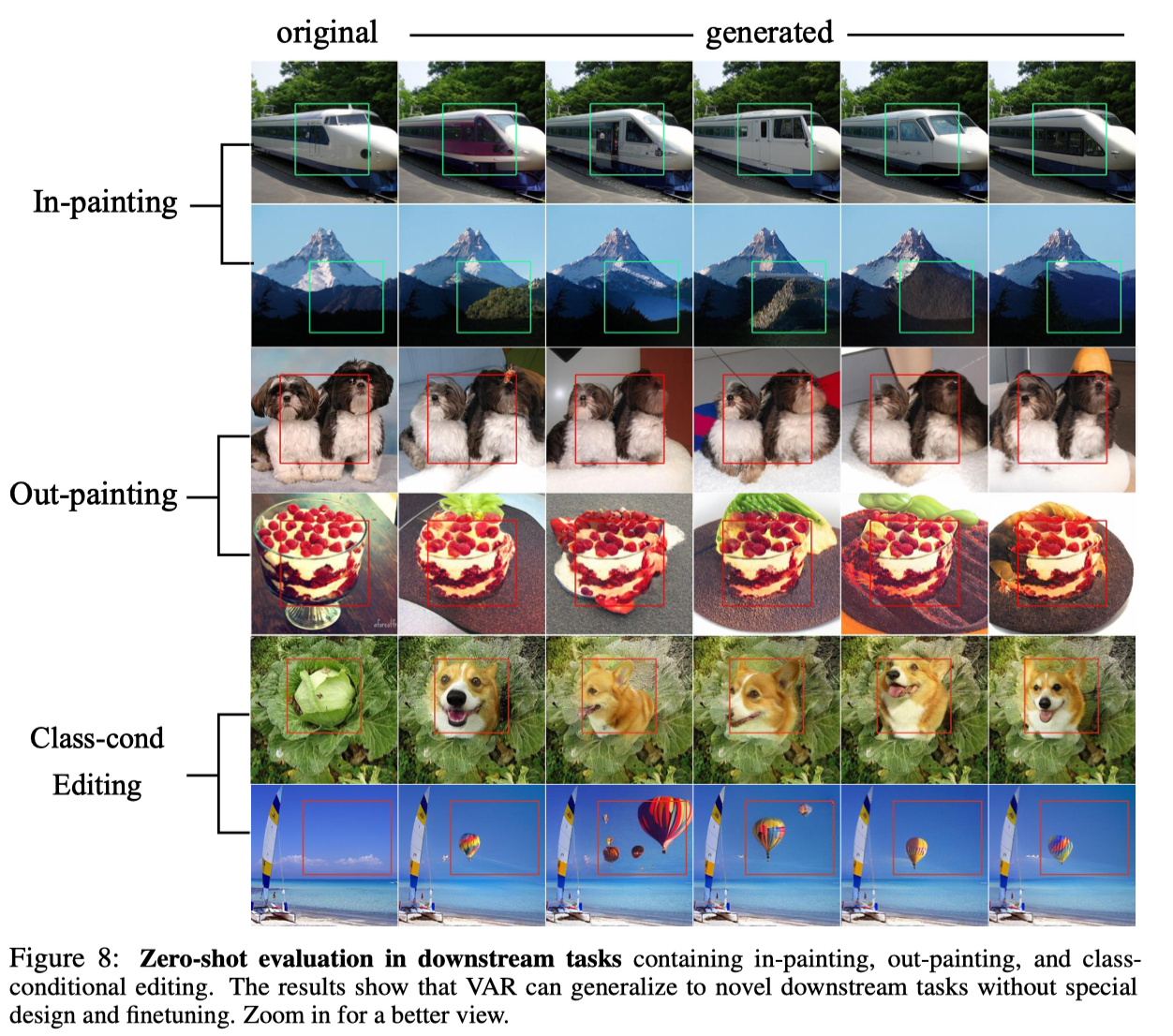
in conclusion
VAR 为如何定义图像的自回归顺序提供了一个全新的视角,即由粗到细、由全局轮廓到局部精调的顺序。在符合直觉的同时,这样的自回归算法带来了很好的效果:VAR 显著提升自回归模型的速度和生成质量,在多方面使得自回归模型首次超越扩散模型。同时 VAR 展现出类似 LLM 的 Scaling Laws、Zero-shot Generalizability。作者们希望 VAR 的思想、实验结论、开源,能够贡献社区探索自回归范式在图像生成领域的使用,并促进未来基于自回归的统一多模态算法的发展。
About Bytedance Commercialization-GenAI Team
ByteDance Commercialization-GenAI team focuses on developing advanced generative artificial intelligence technology and creating industry-leading technical solutions including text, images, and videos. By using Generative AI to realize automated creative workflow, it provides advertisers with Institutions and creators improve creative efficiency and drive value.
More positions in the team's visual generation and LLM directions are open. Welcome to pay attention to ByteDance's recruitment information.
Fellow chicken "open sourced" deepin-IDE and finally achieved bootstrapping! Good guy, Tencent has really turned Switch into a "thinking learning machine" Tencent Cloud's April 8 failure review and situation explanation RustDesk remote desktop startup reconstruction Web client WeChat's open source terminal database based on SQLite WCDB ushered in a major upgrade TIOBE April list: PHP fell to an all-time low, Fabrice Bellard, the father of FFmpeg, released the audio compression tool TSAC , Google released a large code model, CodeGemma , is it going to kill you? It’s so good that it’s open source - open source picture & poster editor tool