
01
backsceneand status quo
1. Characteristics of data in the advertising field
Data in the advertising field can be divided into: continuous value features and discrete value features. Different from AI image, video, voice and other fields , the original data in the advertising field are mostly presented in the form of ID, such as user ID, advertising ID, advertising ID sequence interacting with the user, etc., and the ID scale is large, forming the advertising field The distinctive characteristics of high-dimensional sparse data.
-
There are both static (such as the user's age) and dynamic characteristics based on user behavior (such as the number of times a user clicks on an advertisement in a certain industry). -
The advantage is that it has good generalization ability. A user's preference for an industry can be generalized to other users who have the same statistical characteristics of the industry. -
不足是缺乏记忆能力导致区分度不高。 比如两个相同统计特性的用户,可能行为上也会存在显著差别。 另外,连续值特征还需要大量的人工特征工程。
-
Discrete valued features are fine-grained features. There are enumerable ones (such as user gender, industry ID), and there are also high-dimensional ones (such as user ID, advertising ID). -
The advantage is that it has strong memory and high distinction. Discrete value features can also be combined to learn cross- and collaborative information. -
The disadvantage is that the generalization ability is relatively weak.
-
One-hot Encoding -
Feature embedding (Embedding)
-
Feature conflict: If vocabulary_size is set too large, training efficiency will drop sharply and training will fail due to memory OOM. Therefore, even for billion-level user ID discrete value features, we will only set up an ID Hash space of 100,000 levels. The hash conflict rate is high, the feature information is damaged, and there is no positive benefit from offline evaluation. -
Inefficient IO: Since features such as user ID and advertising ID are high-dimensional and sparse, that is, the parameters updated during training only account for a small part of the total. Under TensorFlow's original static Embedding mechanism, model access needs to be processed The entire dense Tensor will bring huge IO overhead and cannot support the training of sparse large models.
02
Advertisement sparse large model practice
-
The TFRA API is compatible with the Tensorflow ecosystem (reusing the original optimizer and initializer, the API has the same name and consistent behavior), enabling TensorFlow to support the training and inference of ID-type sparse large models in a more native way; the cost of learning and use is low and does not change Algorithm Engineer Modeling Habits. -
Dynamic memory expansion and contraction saves resources during training; it effectively avoids Hash conflicts and ensures that feature information is lossless.
-
Static Embedding is upgraded to dynamic Embedding: For the artificial Hash logic of discrete value features, TFRA dynamic Embedding is used to store, access and update parameters, thereby ensuring that the Embedding of all discrete value features is conflict-free in the algorithm framework and ensuring that all discrete values Lossless learning of features. -
Use of high-dimensional sparse ID features: As mentioned above, when using TensorFlow's static Embedding function, user ID and advertising ID features have no profit in offline evaluation due to Hash conflicts. After the algorithm framework is upgraded, user ID and advertising ID features are re-introduced, and there are positive benefits both offline and online. -
The use of high-dimensional sparse combined ID features: Introducing the combined discrete value features of user ID and advertising coarse-grained ID, such as the combination of user ID with industry ID and App package name respectively. At the same time, combined with the feature access function, discrete features using a combination of sparser user IDs and advertising IDs are introduced.

2. Model update
-
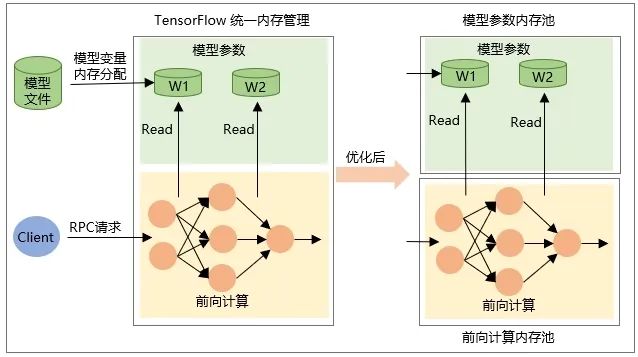
The allocation of the variable itself Tensor when the model is restored, that is, the memory is allocated when the model is loaded, and the memory is released when the model is unloaded. -
The memory of the intermediate output Tensor is allocated during network forward calculation during RPC request and is released after the request processing is completed.
03
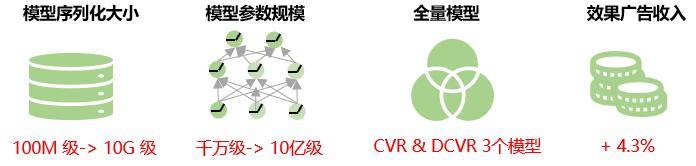
overall benefit
04
future outlook
Currently, all feature values of the same feature in the large advertising sparse model are given the same Embedding dimension. In actual business, the data distribution of high-dimensional features is extremely uneven, a very small number of high-frequency features account for a very high proportion, and the long tail phenomenon is serious; using fixed Embedding dimensions for all feature values will reduce the ability of Embedding representation learning. That is, for low-frequency features, the Embedding dimension is too large, and the model is at risk of over-fitting; for high-frequency features, because there is a wealth of information that needs to be represented and learned, the Embedding dimension is too small, and the model is at risk of under-fitting. Therefore, in the future, we will explore ways to adaptively learn the feature Embedding dimension to further improve the accuracy of model prediction.
At the same time, we will explore the solution of incremental export of the model, that is, only load the parameters that change during incremental training to TensorFlow Serving, thereby reducing the network transmission and loading time during model update, achieving minute-level updates of sparse large models, and improving The real-time nature of the model.

iQIYI Performance Advertising Dual Bidding Optimization Process
This article is shared from the WeChat public account - iQIYI Technology Product Team (iQIYI-TP).
If there is any infringement, please contact [email protected] for deletion.
This article participates in the " OSC Source Creation Plan ". You who are reading are welcome to join and share together.
{{o.name}}
{{m.name}}