
Author: Jin Xuefeng
background
Running large language models on static graphs has many benefits, including:
-
算子融合优化/整图执行带来的性能提升;如果是昇腾,还可以使用整图下沉执行,进一步提升性能,而且整图下沉执行不受host侧数据处理执行的影响,性能稳定性好;
-
Static memory orchestration enables high memory utilization, no fragmentation, increases batch size, and thus improves training performance;
-
Automatically optimize the execution sequence, and achieve good communication and calculation concurrency;
-
......
However, there are also challenges in running large language models on static images. The most prominent one is compilation performance.
The compilation process of the neural network model actually converts the nn code expressed in Python into a dataflow calculation graph:
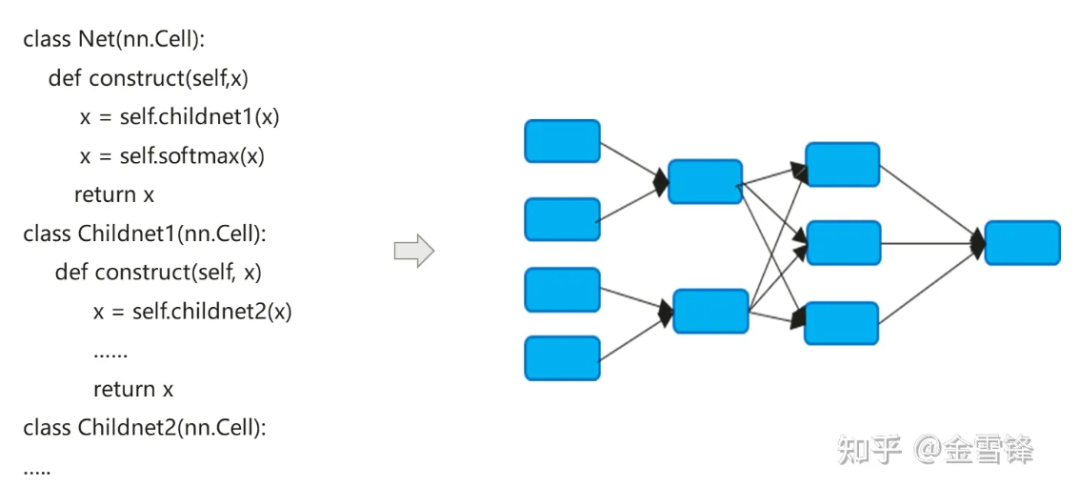
The compilation process of neural network models is a little different from traditional compilers. The default Inline method is often used to finally expand the hierarchical code expression into a flat calculation graph. On the one hand, it seeks to maximize compilation optimization opportunities, and on the other hand, it can also simplify Automatic differentiation and execution logic.
By default, the calculation graph formed after Inline includes all calculation nodes, and the nodes no longer have sub-calculation graph partitions. Therefore, in-process optimization can be performed on a larger scale, such as constant folding, node fusion, parallel analysis, etc., and It can better realize memory allocation and reduce memory application and performance overhead when calling between procedures. Even for computing units that are called repeatedly, compilers in the AI field still use the same inline strategy. While paying the price of program size expansion and executable code growth, they can maximize the use of compilation optimization methods to improve runtime performance.
As can be seen from the above description, inline optimization is very helpful in improving runtime performance; but correspondingly, excessive inline also brings compilation time burden. As the sub-computation graph is integrated into the entire graph, from a global perspective, the number of computing graph nodes that the compiler has to process is rapidly expanding. Compilers generally use the Pass mechanism to organize and arrange optimization methods. Different optimization methods are connected in series in the form of Pass, and a processing process will pass through each node of the calculation graph. The number of processing passes depends on the matching and conversion process of the node and Pass. Sometimes it takes multiple passes to complete the processing. Generally speaking, if the number of Passes is M and the number of computing graph nodes is N, the time of the entire compilation and optimization process is directly related to the value of M * N. In the era of large language models, this problem has become more prominent. There are two main reasons: first, the model structure of large language models is deep and has a large number of nodes; second, when training large language models, due to the enablement of pipeline parallelism, the model scale and nodes are reduced. The number is further increased. If the original graph size is O, then enable pipeline parallelism, and the size of the single-node graph becomes (O/X)*Y, where X is the number of stages in the pipeline and Y is the number of microbatches. In actual During the configuration process, Y is much larger than X. For example, X is 16, and Y is generally set to 64-192. In this way, after pipeline parallelization is enabled, the scale of graph compilation will further increase to 4-12 times the original size.

Taking a certain 13B network of tens of billions of language models as an example, the number of computing nodes in the calculation graph reaches 135,000, and a single compilation time can be close to 3 hours.
**1.** Optimization ideas
We have observed that the neural network structure of deep learning is composed of multiple layers. Under the large model language model, these layers are stacks of Transformer blocks. Especially when pipeline parallelism is turned on, the Layers of each micro batch are exactly the same. Therefore, we wonder if we can retain these Layer structures without Inline or Inline in advance, so that the compilation performance can be improved exponentially. For example, if we follow the micro batch as the boundary and retain the subgraph structure of the micro batch, then theoretically the compilation time can be It becomes one-fold of the original Y (Y is the number of micro batches).
Specific to the code written in the model, we can see that the way to reuse the same Layer is generally a loop or iterative call. Layer generally corresponds to an item of the sequential structure in the iterative process, often a subgraph; that is, using a loop Or iterate to call the same computing unit multiple times, as shown in the code below, block corresponds to a Layer or micro batch subgraph.
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
Therefore, if we regard the loop body as a frequently called subgraph and tell the compiler to defer inline processing by marking it as Lazy Inline, then performance gains can be obtained in most stages of compilation. For example, when the neural network calls the same subgraph structure cyclically, we do not expand the subgraph during the compilation phase; then, at the end of the compilation, Inline optimization is triggered to perform necessary optimization and conversion Pass processing. In this way, for the compiler, most of the time it is smaller-scale code instead of code that has been inline expanded, thus greatly improving compilation performance.
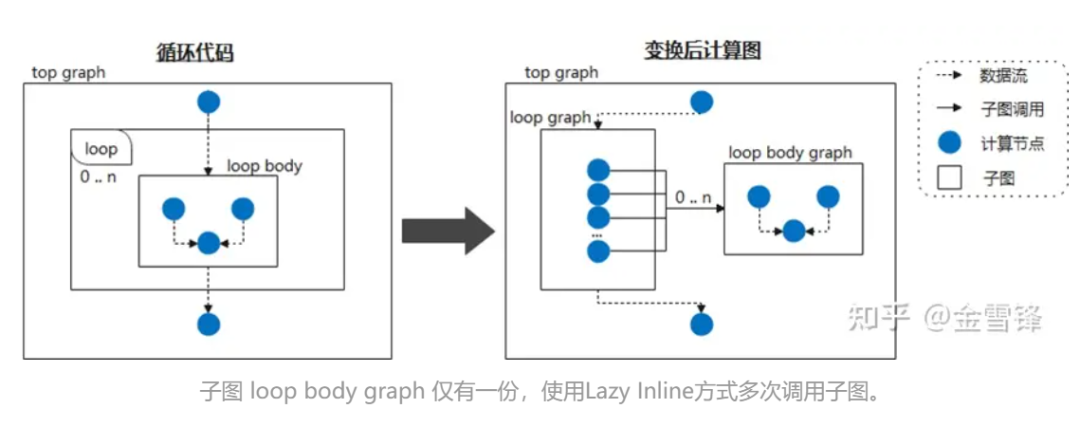
During specific implementation, you can put a mark similar to @lazy-inline on the relevant Layer class to prompt the compiler. Whether the marked Layer is called in the loop body or in other ways, it will not be included during compilation. Inline expansion is not performed until before execution.
**2、**昇思MindSpore实践
It seems that the principles and ideas of Lazy Inline are not complicated, but the existing AI graph compilation mechanism is generally not the kind of compiler that supports complete compilation features, so it is still very challenging to realize this function.
Fortunately, MindSpore's graph compiler has considered versatility when designing IR, including sub-function calls, closures and other features.
① Cell instances are compiled into reusable calculation graphs
Cell is the basic building block of MindSpore neural network and the base class of all neural networks. Cell can be a single neural network unit, such as conv2d, relu, batch_norm, etc., or it can be a combination of units that build a network. In GRAPH_MODE (static graph mode), Cell will be compiled into a calculation graph.
When you need to customize the network, you need to inherit the Cell class and override the __init__ and construct methods. The Cell class overrides the __call__ method. When a Cell class instance is called, the constructor method is executed. Define the network structure in the construction method.
In the following example, a simple network is built to implement the convolution calculation function. Operators in the network are defined in __init__ and used in the construct method. The network structure of the case is: Conv2d -> BiasAdd.
In the construction method, x is the input data, and the output is the result obtained after calculating the network structure.
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline is the decorator of Cell::__init__. Its function is to generate all parameters of __init__ into the cell_init_args attribute value of Cell, self.cell_init_args = type(self).__name__ + str(arguments). The cell_init_args attribute serves as the unique identifier of the Cell instance in MindSpore compilation. The same cell_init_args value indicates that the Cell class name and initialization parameter values are the same.
construct(self, x) defines the network structure, which is the same as the Cell class. The network structure depends on the input parameters self and x. Self contains Parameters such as weights. These weights are randomly initialized or the results of training, so these weights are different for each Cell instance. Other self attributes are determined by the __init__ parameter, and the __init__ parameter is calculated by @lazy_inline to obtain the Cell instance identification cell_init_args. Therefore, the Cell instance compilation calculation graph construct(self, x) is transformed into construct(x, self. cell_init_args, self.trainable_parameters() ).
If it is the same Cell class and the cell_init_args parameters are the same, we call these neuron instances reusable neuron instances, and the calculation graph corresponding to this neuron instance is named the reusable calculation graph reuse_construct(X, self. trainable_parameters()). It can be deduced that the calculation graph of each Cell instance can be converted into:
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
After the introduction of reusable computing graphs, neuron Cells (reusable computing graphs) with the same cell_init_args only need to be composed and compiled once. The more cells there are in the network, the better the performance may be. But everything has two sides. If the calculation graph of these cells is too small or too large, it will lead to poor compilation and optimization of certain features, such as operator fusion, memory multiplexing, whole graph sinking and multi-graph calling, etc.
Therefore, the MindSpore version currently only supports manual identification of which Cell compilation stages generate reusable calculation graphs. Subsequent versions will plan automatic strategies to generate reusable calculation graphs, such as how many operators a Cell contains, how many times a Cell is used, and other factors to weigh whether to generate a reusable calculation graph and give optimization suggestions.
The following uses the GPT structure for an abstract and simplified explanation:
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT is composed of multiple layers of Blocks. The initialization parameters of these Blocks are all the same Config, so the structures of these Blocks are the same, and will be converted internally by the compiler into the following structure:
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
With this structure, in the first half of the compilation process, it is an independent calculation graph and is not inlined into the overall calculation graph. Only the final small amount of Pass optimization is inlined into the large calculation graph.
② The combination of L****azy Inline and automatic differentiation/parallel/recalculation and other features
After adopting Lazy Inline's solution, it will have some impact on the original process and require relevant adaptations, mainly automatic differentiation, parallelism and recalculation.
For automatic differentiation, a forward node similar to call function appears, and differentiation processing needs to be provided;
For parallel processes, the main thing is that Pipeline parallel pass processing needs to be adapted to non-whole picture scenarios, because the previous Pipeline cutting was based on the whole picture, but now it needs to be cut based on the shared subgraph. The specific plan is to first color according to the Stage, split the nodes in the shared Cell according to the Stage, retain only the nodes corresponding to the Stage of the current process, and insert the Send/Recv operator, and then split the nodes outside the Shared Cell, retaining the corresponding nodes of the current process. The stage node also takes the Send/Recv operator in the shared cell out of the shared cell;
For the recalculation process, the old recalculation process processes operators on the entire graph after Inline. By searching for recalculated continuous operator blocks, the operators that need to be recalculated and the recalculation parameters are determined according to the user's recalculation configuration. The forward or reverse operator on which the calculated operator execution depends. After Lazy Inline, consecutive recalculation operators may be in different subgraphs, and no connection relationship can be found between the forward node and the reverse node, so the original search strategy based on the whole graph operator fails. .
Our adaptation plan is to process recalculated Cells or operators after automatic differentiation. The automatic differentiation process will generate a closure for the subgraph or single operator produced by Cell, which returns the forward output and backpropagation function, and we also get the relationship between each closure and the original forward part. a mapping. Through this information, based on the user's recalculation configuration, each closure is used as the basic unit, the Cell and the operator are processed uniformly, and the original forward part is copied back to the original graph, and the dependency relationship can be passed through the closure in the closure. Backpropagation function acquisition can finally achieve a recalculation scheme that does not rely on Inline of the entire graph.
③Backend processing and impact
The IR generated after turning on Lazy Inline on the front end is sent to the back end. The back end needs to slice the IR before it can be executed on the device through sub-graph sinking. However, after Lazy Inline, there will still be some problems in the execution of subgraph sinking, such as the inability to use the optimal method for memory reuse and stream allocation, the inability to use the internal cache of the graph for compilation acceleration during compilation, and the inability to do cross-graph processing. Optimization (memory optimization, communication fusion, operator fusion, etc.) and other issues.
In order to achieve optimal performance, the backend needs to process the IR of Lazy Inline into a form suitable for backend sinking execution. The main thing to do is to convert the Partial operator generated by automatic differentiation into an ordinary subgraph call, and change the captured variables into Pass it in as ordinary parameters, so that the entire graph can be sunk and the entire network can be executed.
In the entire graph sinking process, these calls have two processing methods: Inline on the graph and Inline on the execution sequence. Inline on the graph will cause the graph to expand and the subsequent compilation speed will be slower; however, inline of the execution sequence will cause the memory life cycle of part of the execution sequence Inline to be particularly long during memory reuse, and in the end the memory will not be enough.
In the end, the processing method we adopted was to reuse the execution sequence Inline process in the optimization pass, operator selection, operator compilation and other processes to make the graph size as small as possible and avoid too many graph nodes affecting the back-end compilation of the graph. time. Before executing sequence optimization, stream allocation, memory reuse and other processes, these calls are made into actual nodes Inline to obtain the optimal memory reuse effect. In addition, through some memory and communication optimization, redundant calculation elimination and other methods after graph inline, it is possible to achieve no degradation in memory and performance.
At present, it is not possible to achieve all cross-graph level optimizations. Single-point identification can only be placed in the stage after Inline, and it is impossible to save time on execution order optimization, stream allocation, and memory reuse.
④Achieve effects
Large model compilation performance optimization uses the Lazy Inline solution to improve compilation performance by 3 to 8 times. Taking the 13B network of the 10 billion large model as an example, after applying the Lazy Inline solution, the calculation graph compilation scale dropped from 130,000+ nodes to 20,000+ nodes. Node, the compilation time has been reduced from 3 hours to 20 minutes, and combined with the compilation result caching, the overall efficiency has been greatly improved.
⑤Use restrictions and next steps
1. Cell The identifier of the Cell instance is generated based on the Cell class name and the __init__ parameter value. This is based on the assumption that the parameters of init determine all properties of Cell, and that the Cell properties at the beginning of construct composition are consistent with the properties after init is executed. Therefore, the properties of Cell related to composition cannot be changed after init is executed.
2. The construct function parameters cannot have default values. If the existing MindSpore version has default values for the construct function parameters, each time it is used, it will be specialized into a new calculation graph; subsequent versions will optimize the original specialization mechanism.
3. Cell consists of multiple shared Cell_X instances, and each Cell_X consists of multiple shared Cell_Y instances. If the init of Cell_X and Cell_Y are both decorated as @lazy_inline, only the outermost Cell_X can be compiled into a reused calculation graph, and the calculation graph of the inner Cell_Y is still Inline; subsequent versions plan to support this multi-level lazy inline mechanism.
如何辅助客户写出高内聚低耦合构图代码,也是昇思MindSpore框架追求目标之一,例如在使用中存在这种Block:: __init__ 参数包含Layer index,其他参数的值都相同,由于Layer Index 每一层都不一样,导致该Block由于细微的差别不能复用。如在某个GTP 版本代码中存在以下这样的代码:
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
In order to make the Block reusable, we can optimize it, extract the calculations related to the Layer Index, and then use them as parameters of Construct to input them into the original composition, so that the init parameters of the Block are the same.
Modify the above code segment to the following code segment, delete the parts related to Init and Layer Index, and add the coeff parameter to construct.
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
在后续昇思MindSpore版本中我们规划特性识别这种有细微差别的Block,对这些Block给予优化建议以便优化改进。
A programmer born in the 1990s developed a video porting software and made over 7 million in less than a year. The ending was very punishing! Google confirmed layoffs, involving the "35-year-old curse" of Chinese coders in the Flutter, Dart and Python teams . Daily | Microsoft is running against Chrome; a lucky toy for impotent middle-aged people; the mysterious AI capability is too strong and is suspected of GPT-4.5; Tongyi Qianwen open source 8 models Arc Browser for Windows 1.0 in 3 months officially GA Windows 10 market share reaches 70%, Windows 11 GitHub continues to decline. GitHub releases AI native development tool GitHub Copilot Workspace JAVA is the only strong type query that can handle OLTP+OLAP. This is the best ORM. We meet each other too late.