

With the in-depth exploration of large-scale model applications, retrieval-Augmented Generation technology has received widespread attention and has been applied in various scenarios, such as knowledge base Q&A, legal advisors, learning assistants, website robots, etc.
However, many friends are not clear about the relationship and technical principles of vector databases and RAG. This article will give you an in-depth understanding of the new vector database in the RAG era.
01.
RAG’s wide range of applications and its unique advantages
A typical RAG framework can be divided into two parts: Retriever and Generator. The retrieval process includes segmenting data (such as Documents), embedding vectors (Embedding), and building indexes (Chunks Vectors), and then Relevant results are recalled through vector retrieval, and the generation process uses Prompt enhanced based on the retrieval results (Context) to activate LLM to generate answers (Result).
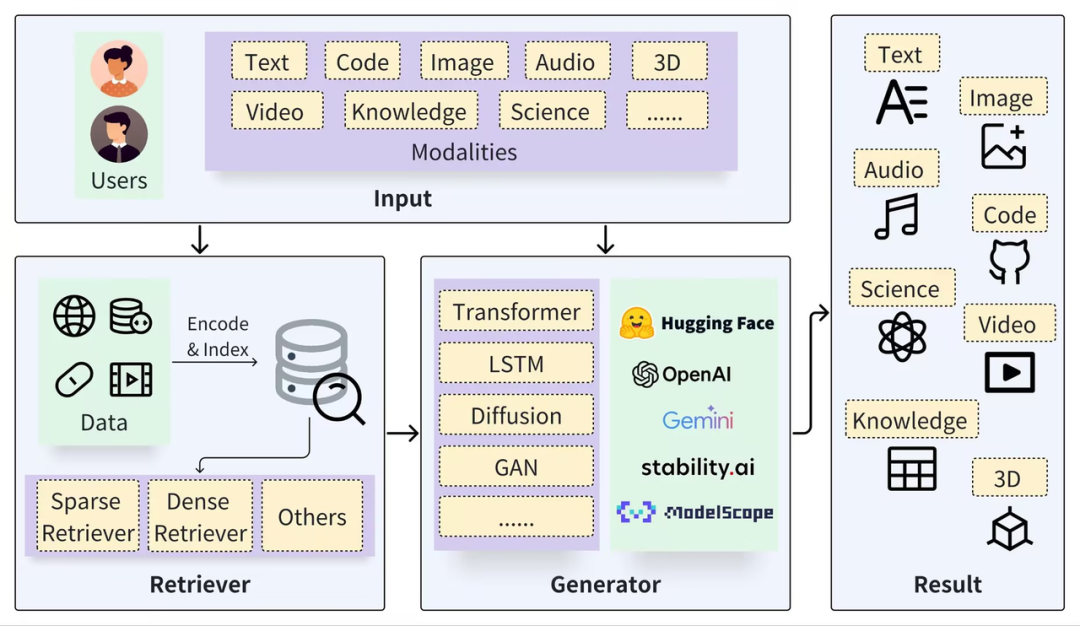
https://arxiv.org/pdf/2402.19473
The key to RAG technology is that it combines the best of both approaches: a retrieval system that provides specific, relevant facts and data, and a generative model that flexibly constructs answers and incorporates broader context and information. This combination makes the RAG model very effective at processing complex queries and generating information-rich answers, which is very useful in question answering systems, dialogue systems, and other applications that require understanding and generating natural language. Compared with native large-scale models, pairing with RAG can form natural complementary advantages:
避免“幻觉”问题:RAG 通过检索外部信息作为输入,辅助大型模型回答问题,这种方法能显著减少生成信息不准确的问题,增加回答的可追溯性。
Data privacy and security: RAG can use the knowledge base as an external attachment to manage the private data of an enterprise or institution to prevent data from being leaked in an uncontrollable manner after model learning.
Real-time nature of information: RAG allows real-time retrieval of information from external data sources, so the latest, domain-specific knowledge can be obtained and the problem of knowledge timeliness can be solved.
Although cutting-edge research on large-scale models is also dedicated to solving the above problems, such as fine-tuning based on private data and improving the long text processing capabilities of the model itself, these studies help to promote the advancement of large-scale model technology. However, in more general scenarios, RAG is still a stable, reliable and cost-effective choice, mainly because RAG has the following advantages:
White-box model : Compared with the "black box" effect of fine-tuning and long text processing, the relationship between RAG modules is clearer and closer, which provides higher operability and interpretability in effect tuning; in addition , when the quality and confidence (Certainty) of the retrieved and recalled content are not high, the RAG system can even prohibit the intervention of LLMs and directly reply "don't know" instead of making up nonsense.
Cost and response speed: RAG has the advantages of short training time and low cost compared to fine-tuned models; compared with long text processing, it has faster response speed and much lower inference cost. In the research and experimental stage, the effect and accuracy are the most attractive; but in terms of industry and industrial implementation, cost is a decisive factor that cannot be ignored.
Private data management: By decoupling the knowledge base from large models, RAG not only provides a safe and implementable practical basis, but can also better manage the existing and new knowledge of the enterprise and solve the problem of knowledge dependence. Another related angle is access control and data management, which is easy to do for RAG's base database, but difficult for large models.
Therefore, in my opinion, as the research on large-scale models continues to deepen, RAG technology will not be replaced. On the contrary, it will maintain an important position for a long time. This is mainly due to its natural complementarity with LLM, which allows applications built on RAG to shine in many fields. The key to RAG improvement is on the one hand the improvement of LLMs capabilities, and on the other hand it relies on various improvements and optimizations of retrieval (Retrieval).
02.
The foundation for RAG searches: vector databases
In industry practice, RAG retrieval is usually closely integrated with vector databases, which has also given rise to a RAG solution based on ChatGPT + Vector Database + Prompt, referred to as the CVP technology stack. This solution relies on vector databases to efficiently retrieve relevant information to enhance large language models (LLMs). By converting queries generated by LLMs into vectors, the RAG system can quickly locate corresponding knowledge entries in the vector database. This retrieval mechanism enables LLMs to utilize the latest information stored in the vector database when facing specific problems, effectively solving the problems of knowledge update delay and illusion inherent in LLMs.
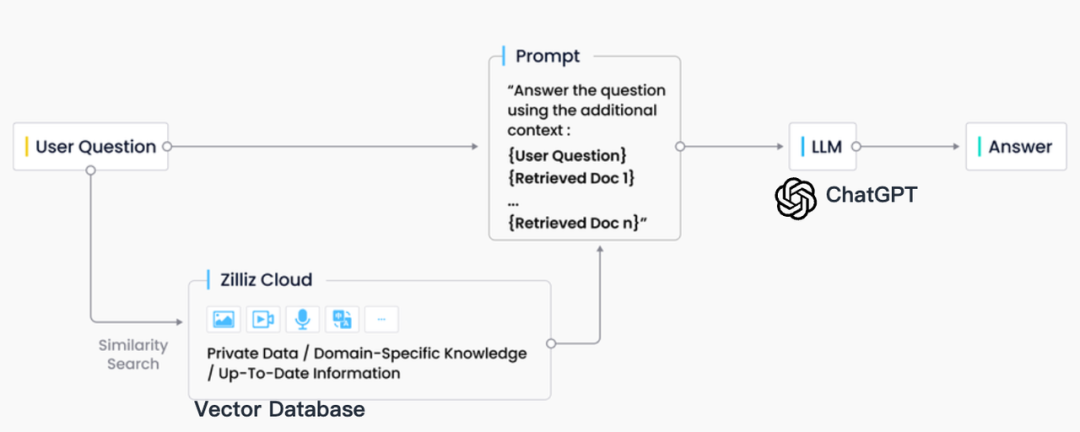
尽管信息检索领域也存在选择众多的存储与检索技术,包括搜索引擎、关系型数据库和文档数据库等,向量数据库在 RAG 场景下却成为了业界首选。这一选择的背后,是向量数据库在高效地存储和检索大量嵌入向量方面的出色能力。这些嵌入向量由机器学习模型生成,不仅能够表征文本和图像等多种数据类型,还能够捕获它们深层的语义信息。在 RAG 系统中,检索的任务是快速且精确地找出与输入查询语义上最匹配的信息,而向量数据库正因其在处理高维向量数据和进行快速相似性搜索方面的显著优势而脱颖而出。
The following is a horizontal comparison of vector databases represented by vector retrieval with other technical options, as well as an analysis of the key factors that make it a mainstream choice in RAG scenarios:
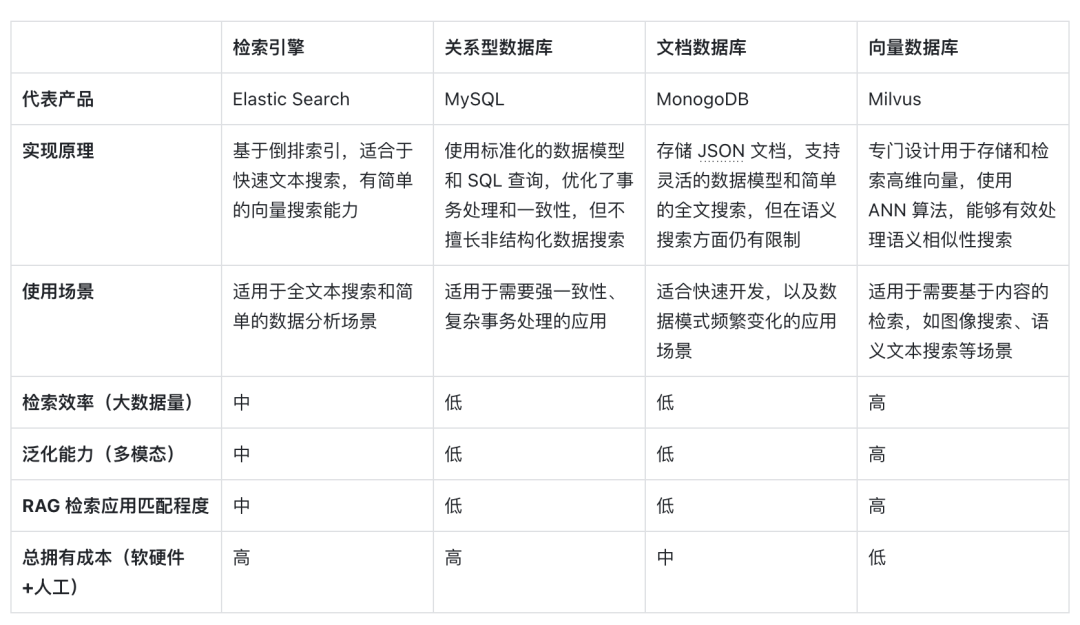
First of all, in terms of implementation principles , vectors are the model’s encoding form of semantic meaning. Vector databases can better understand the semantic content of queries because they leverage the ability of deep learning models to encode the meaning of text, not just keyword matching. Benefiting from the development of AI models, the semantic accuracy behind it is also steadily improving. Using vector distance similarity to express semantic similarity has developed into the mainstream form of NLP. Therefore, ideographic embedding has become the first choice for processing information carriers. .
Secondly, in terms of retrieval efficiency , since information can be expressed as high-dimensional vectors, special index optimization and quantification methods can be added to vectors, which can greatly improve retrieval efficiency and compress storage costs. As the amount of data increases, the vector database can be expanded horizontally , maintaining query response time, which is crucial for RAG systems that need to process massive amounts of data, so vector databases are better at processing very large-scale unstructured data.
As for the dimension of generalization ability , most traditional search engines, relational or document databases can only process text, and have poor generalization and expansion capabilities. Vector databases are not limited to text data, but can also process images, audio and other unstructured data. type of embedding vector, which makes the RAG system more flexible and versatile.
Finally, in terms of total cost of ownership , compared to other options, vector databases are more convenient to deploy and easier to use. They also provide rich APIs, making them easy to integrate with existing machine learning frameworks and workflows, so they are popular among them. A favorite among many RAG application developers.
Vector retrieval has become an ideal RAG retriever in the era of large models by virtue of its semantic understanding ability, high retrieval efficiency, and generalization support for multi-modalities. With the further development of AI and embedding models, These advantages may become more prominent in the future.
03.
Requirements for vector databases in RAG scenarios
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
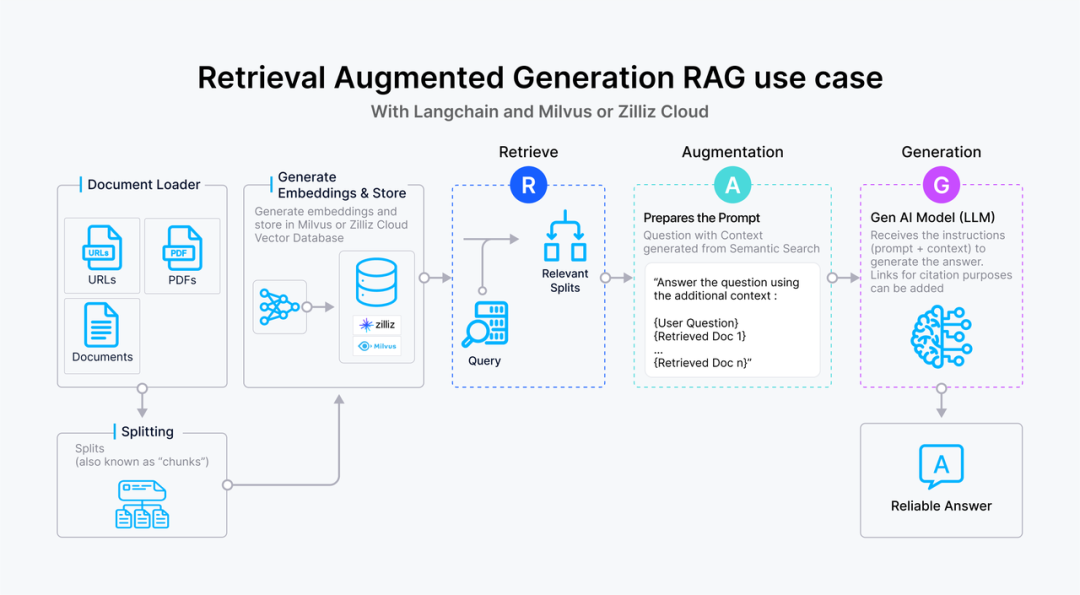
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。