Para obtener más intercambios técnicos y oportunidades de búsqueda de empleo, preste atención a la cuenta oficial de WeChat de ByteDance Data Platform y responda [1] para ingresar al grupo de intercambio oficial.
ByteHouse es un almacén de datos nativo de la nube en Volcano Engine, que brinda a los usuarios una experiencia de análisis extremadamente rápida y puede admitir análisis de datos en tiempo real y análisis masivo de datos fuera de línea; convenientes capacidades elásticas de expansión y contracción, rendimiento de análisis extremo y características ricas de nivel empresarial , para ayudar a los clientes a la transformación digital.
Este artículo presentará la evolución de la tecnología de importación en tiempo real de ByteHouse basada en diferentes arquitecturas desde las perspectivas de la motivación de la demanda, la implementación de la tecnología y la aplicación práctica.
Requisitos de importación en tiempo real de negocios internos
La motivación para la evolución de la tecnología de importación en tiempo real de ByteHouse se originó a partir de las necesidades del negocio interno de ByteDance.
Dentro de Byte, ByteHouse utiliza principalmente Kafka como principal fuente de datos para la importación en tiempo real ( este artículo utiliza la importación de Kafka como ejemplo para ampliar la descripción, que no se repetirá a continuación ). Para la mayoría de los usuarios internos, el volumen de datos es relativamente grande; por lo tanto, los usuarios prestan más atención al rendimiento de la importación de datos, la estabilidad de los servicios y la escalabilidad de las capacidades de importación. En cuanto a la latencia de datos, la mayoría de los usuarios pueden satisfacer sus necesidades siempre que sea visible en segundos. Basado en tal escenario, ByteHouse ha llevado a cabo una optimización personalizada.
Alta disponibilidad bajo arquitectura distribuida

Arquitectura distribuida nativa de la comunidad
ByteHouse primero siguió la arquitectura distribuida de la comunidad Clickhouse, pero la arquitectura distribuida tiene algunos defectos arquitectónicos naturales. Estos puntos débiles se manifiestan principalmente en tres aspectos:
-
Falla de nodo: cuando la cantidad de máquinas del clúster alcanza una escala determinada, es necesario manejar manualmente las fallas de nodo cada semana. Para los clústeres de una sola copia, en algunos casos extremos, la falla del nodo puede incluso provocar la pérdida de datos.
-
Conflictos de lectura y escritura: debido al acoplamiento de lectura y escritura de la arquitectura distribuida, cuando la carga del clúster alcanza un cierto nivel, se producirán conflictos de recursos en las consultas de los usuarios y las importaciones en tiempo real, especialmente CPU e IO, las importaciones se verán afectadas y se producirá un retraso en el consumo.
-
Costo de expansión: dado que los datos en la arquitectura distribuida se almacenan básicamente localmente, los datos no se pueden reorganizar después de la expansión. La máquina recién expandida casi no tiene datos y el disco en la máquina anterior puede estar casi lleno, lo que da como resultado un clúster desigual. carga. , lo que lleva a la expansión no puede tener un efecto efectivo.
Estos son los puntos débiles naturales de la arquitectura distribuida, pero debido a sus características de concurrencia natural y la optimización extrema del rendimiento de la lectura y escritura de datos del disco local, se puede decir que existen ventajas y desventajas.
Diseño de importación en tiempo real de la comunidad
-
Modo de consumo de alto nivel: confíe en el propio mecanismo de reequilibrio de Kafka para equilibrar la carga de consumo.
-
dos niveles de concurrencia
El diseño del núcleo de importación en tiempo real basado en la arquitectura distribuida es en realidad una concurrencia de dos niveles:
Un clúster CH generalmente tiene varios fragmentos, y cada fragmento consumirá e importará simultáneamente, que es la simultaneidad de procesos múltiples entre los fragmentos de primer nivel;
Cada fragmento también puede usar varios subprocesos para consumir simultáneamente, a fin de lograr un rendimiento de alto rendimiento.
-
Escribir en lotes
En lo que respecta a un solo subproceso, el modo de consumo básico es escribir en lotes: consumir una cierta cantidad de datos o escribirlos de una vez después de un cierto período de tiempo. La escritura por lotes puede lograr mejor la optimización del rendimiento, mejorar el rendimiento de las consultas y reducir la presión sobre el subproceso Merge en segundo plano.
necesidades no satisfechas
El diseño y la implementación de las comunidades anteriores aún no pueden satisfacer algunas necesidades avanzadas de los usuarios:
-
En primer lugar, algunos usuarios avanzados tienen requisitos relativamente estrictos sobre la distribución de datos. Por ejemplo, tienen claves específicas para algunos datos específicos y esperan que los datos con la misma clave se coloquen en el mismo fragmento (como requisitos de clave únicos). En este caso, no se puede satisfacer el modelo de consumo de la comunidad Nivel Alto.
-
En segundo lugar, el reequilibrio del formulario de consumo de alto nivel es incontrolable, lo que eventualmente puede conducir a una distribución desigual de los datos importados en el clúster de Clickhouse entre los diversos fragmentos.
-
Por supuesto, se desconoce la asignación de tareas de consumo y, en algunos escenarios de consumo anormal, se vuelve muy difícil solucionar problemas; esto es inaceptable para una aplicación de nivel empresarial.
Motor de consumo de arquitectura distribuida de desarrollo propio HaKafka
Para resolver los requisitos anteriores, el equipo de ByteHouse desarrolló un motor de consumo basado en la arquitectura distribuida: HaKafka.
Alta disponibilidad (Ha)
HaKafka hereda las ventajas de consumo del motor de tablas Kafka original en la comunidad y luego se enfoca en la optimización Ha de alta disponibilidad.
En lo que respecta a la arquitectura distribuida, de hecho, puede haber varias copias en cada fragmento y se pueden crear tablas HaKafka en cada copia. Pero ByteHouse solo seleccionará un líder a través de ZK, dejará que el líder ejecute el proceso de consumo y los otros nodos estarán en estado de espera. Cuando el nodo líder no está disponible, ZK puede cambiar el líder al nodo Stand by en segundos para continuar con el consumo, logrando así una alta disponibilidad.
Bajo—Modo de consumo de nivel
El modo de consumo de HaKafka se ha ajustado de nivel alto a nivel bajo. El modo de nivel bajo puede garantizar que las particiones de temas se distribuyan a cada fragmento del clúster de manera ordenada y uniforme; al mismo tiempo, se pueden usar subprocesos múltiples dentro del fragmento nuevamente, lo que permite que cada subproceso consuma particiones diferentes. Por lo tanto, hereda completamente las ventajas de la concurrencia de dos niveles del motor de tablas de la comunidad Kafka.
En el modo de consumo de bajo nivel, siempre que los usuarios ascendentes se aseguren de que no haya datos sesgados al escribir en el tema, los datos importados en Clickhouse a través de HaKafka deben distribuirse uniformemente entre los fragmentos.
Al mismo tiempo, para usuarios avanzados que tienen requisitos especiales de distribución de datos (escribir los datos de la misma clave en el mismo fragmento), siempre que el flujo ascendente garantice que los datos de la misma clave se escriben en la misma partición, luego importa ByteHouse puede satisfacer completamente las necesidades del usuario, y es muy fácil escenarios de soporte Bueno como claves únicas.
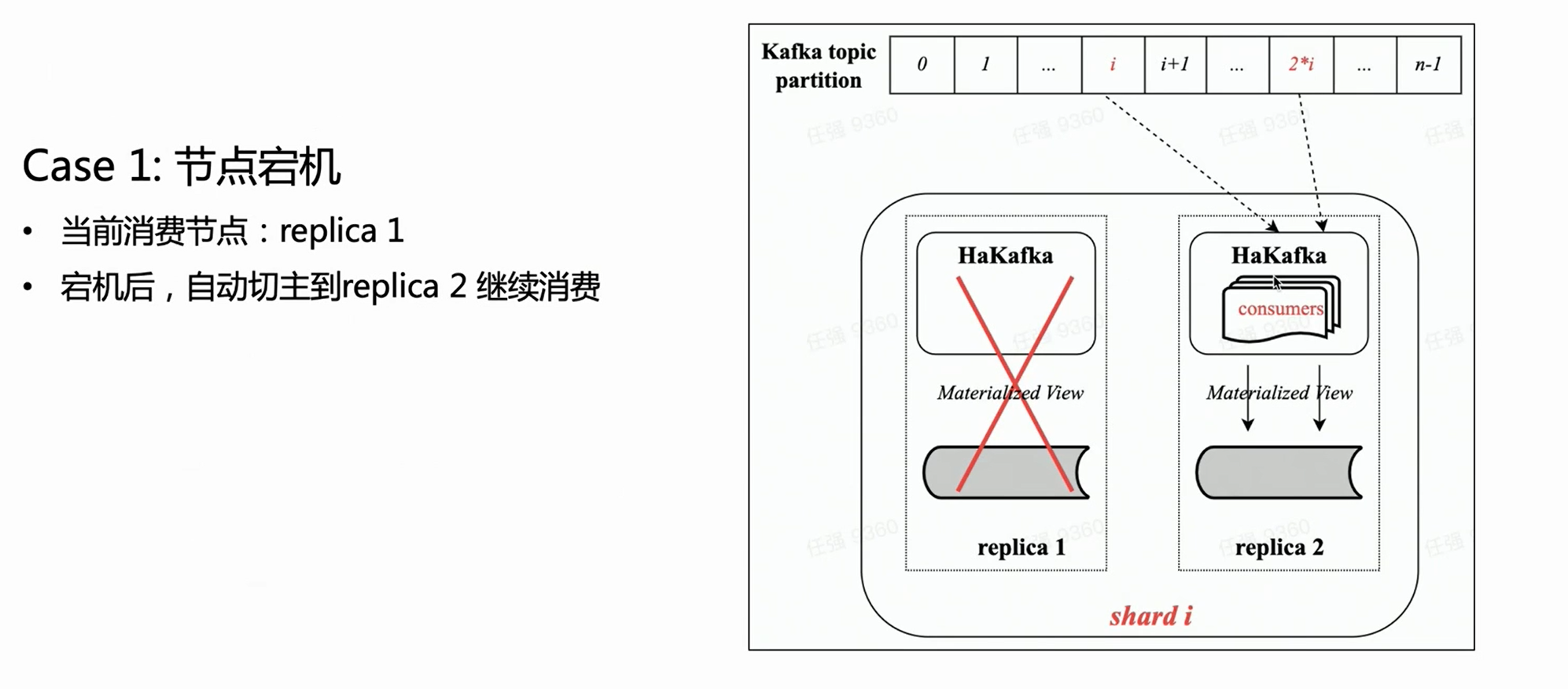
escena uno:
Según la figura anterior, suponiendo que haya un fragmento con dos copias, cada copia tendrá la misma tabla HaKafka en el estado Listo. Pero solo en el nodo líder que haya elegido con éxito al líder a través de ZK, HaKafka ejecutará el proceso de consumo correspondiente. Cuando el nodo líder deja de funcionar, la réplica Réplica 2 se reelige automáticamente como nuevo líder para continuar con el consumo, lo que garantiza una alta disponibilidad.
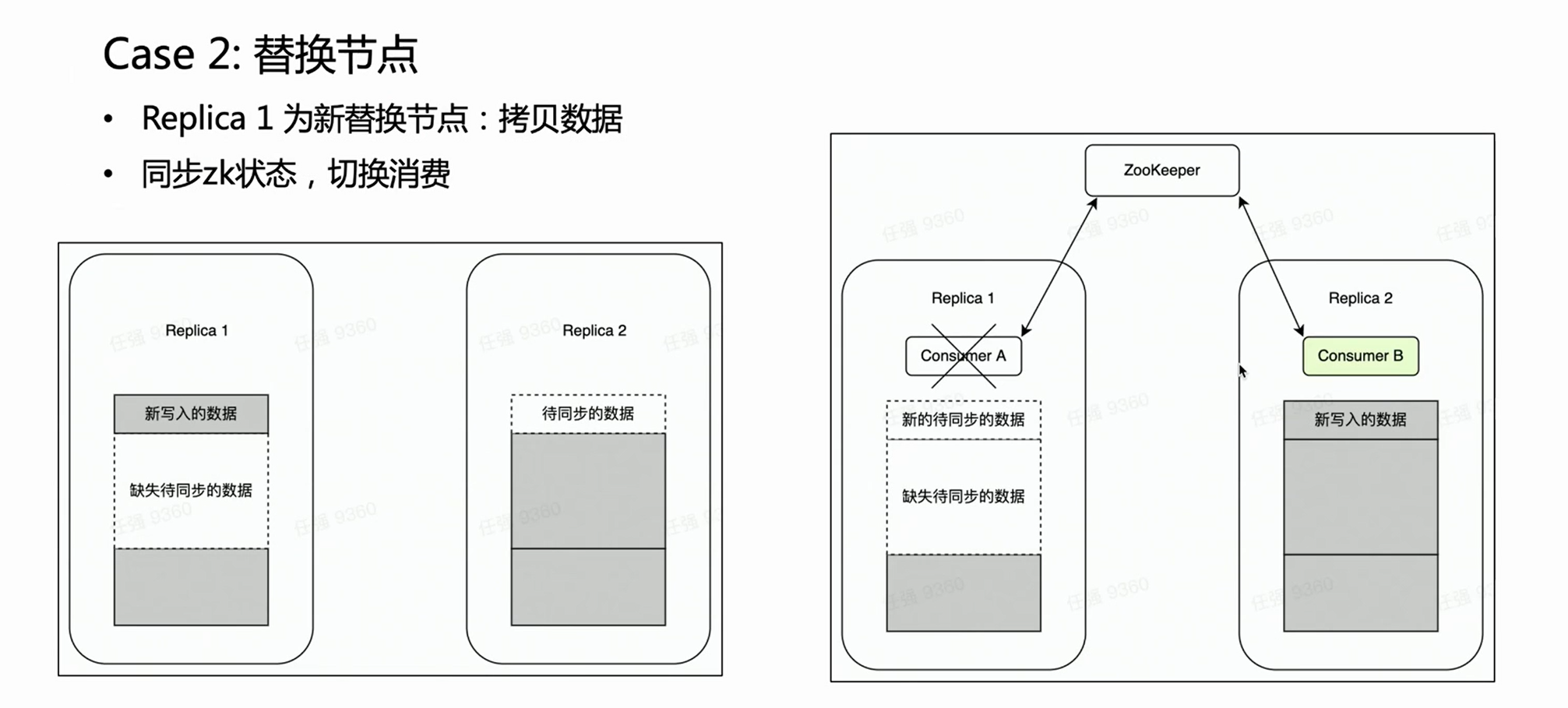
Escena dos:
En caso de falla de un nodo, generalmente es necesario realizar el proceso de reemplazo del nodo. Hay una operación muy pesada para el reemplazo de nodos distribuidos: copiar datos.
Si se trata de un clúster de varias réplicas, una copia falla y la otra copia está intacta. Naturalmente, esperamos que durante la fase de reemplazo de nodos, el consumo de Kafka se coloque en la réplica intacta Réplica 2, porque los datos antiguos están completos. De esta forma, la Réplica 2 es siempre un conjunto de datos completo y puede proporcionar servicios externos con normalidad. HaKafka puede garantizar esto. Cuando HaKafka elige al líder, si se determina que cierto nodo está en proceso de reemplazar el nodo, evitará ser seleccionado como líder.
Optimización del rendimiento de importación: tabla de memoria
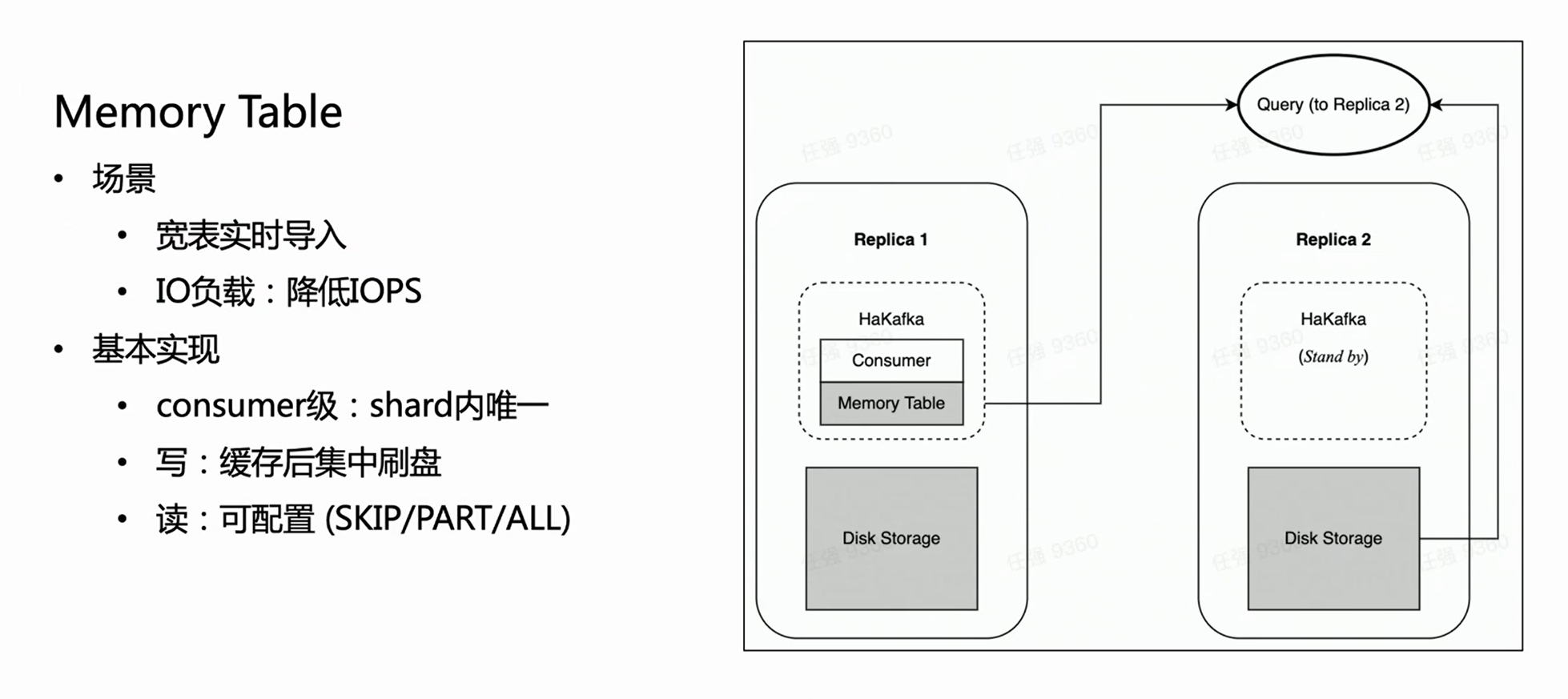
HaKafka también optimiza la tabla de memoria.
Considere tal escenario: la empresa tiene una tabla grande y ancha, que puede tener cientos de campos o miles de Map-Keys. Dado que cada columna de ClickHouse corresponderá a un archivo específico, cuantas más columnas haya, más archivos se escribirán para cada importación. Luego, dentro del mismo tiempo de consumo, se escribirán con frecuencia muchos archivos fragmentados, lo que es una carga pesada para el IO de la máquina y, al mismo tiempo, ejerce mucha presión sobre MERGE; en casos severos, puede incluso hacer que el clúster no esté disponible. Para resolver este escenario, diseñamos Memory Table para optimizar el rendimiento de la importación.
El método de la tabla de memoria es que cada vez que los datos importados no se flashean directamente, sino que se almacenan en la memoria; cuando los datos alcanzan una cierta cantidad, se concentran en el disco para reducir las operaciones de E/S. Memory Table puede proporcionar un servicio de consulta externo, y la consulta se enrutará a la copia donde se encuentra el nodo del consumidor para leer los datos en la tabla de memoria, lo que garantiza que la demora de la importación de datos no se vea afectada. Según la experiencia interna, Memory Table no solo satisface algunos requisitos de importación comercial de tablas grandes y anchas, sino que también mejora el rendimiento de la importación hasta 3 veces.
Nueva arquitectura nativa de la nube
En vista de las fallas naturales de la arquitectura distribuida descrita anteriormente, el equipo de ByteHouse ha estado trabajando para actualizar la arquitectura. Hemos elegido la arquitectura nativa de la nube que es la corriente principal del negocio. La nueva arquitectura comenzará a servir al negocio interno de Byte a principios de 2021 y abrirá el código (ByConity) a principios de 2023.
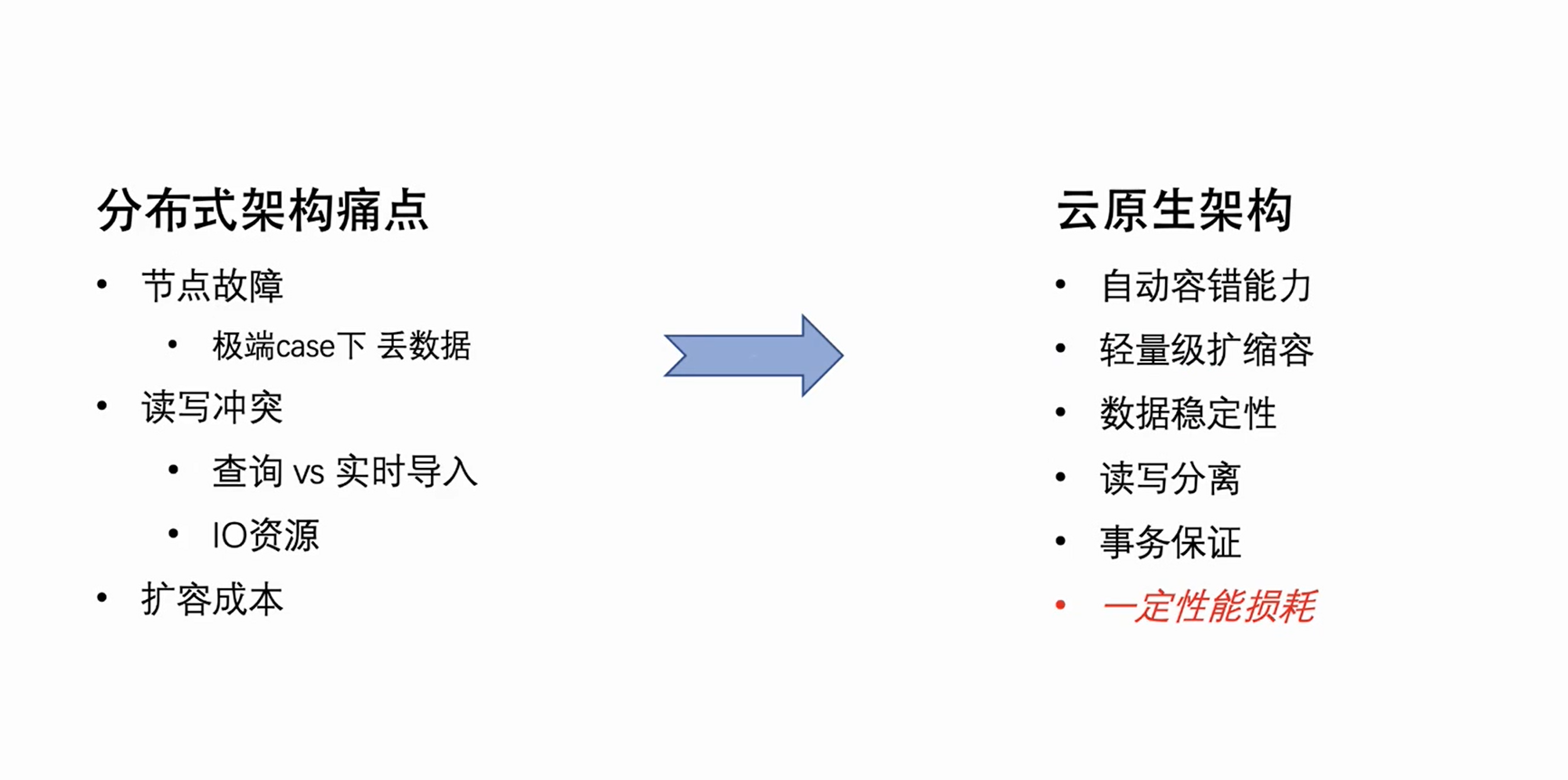
La arquitectura nativa de la nube en sí misma tiene una tolerancia a fallas automática natural y capacidades de escalado ligero. Al mismo tiempo, debido a que sus datos se almacenan en la nube, no solo realiza la separación del almacenamiento y la informática, sino que también mejora la seguridad y la estabilidad de los datos. Por supuesto, la arquitectura nativa de la nube no está exenta de deficiencias: cambiar la lectura y escritura local original a lectura y escritura remota inevitablemente provocará una cierta pérdida en el rendimiento de lectura y escritura. Sin embargo, intercambiar una cierta pérdida de rendimiento por la racionalidad de la arquitectura y reducir el costo de operación y mantenimiento en realidad supera las desventajas.
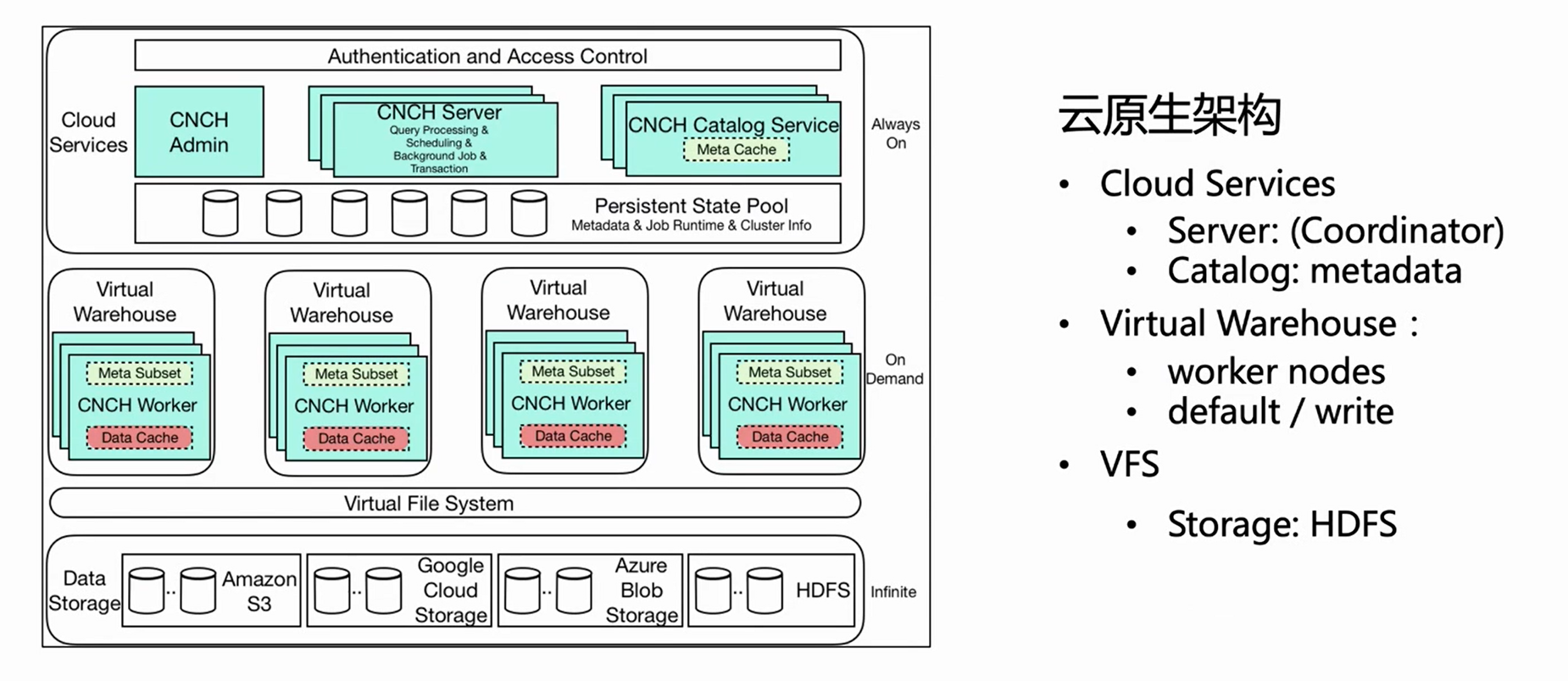
La imagen de arriba es el diagrama de arquitectura de la arquitectura nativa en la nube de ByteHouse.Este artículo presenta varios componentes relacionados importantes para la importación en tiempo real.
-
Servicio de almacenamiento en la nube
En primer lugar, la arquitectura general se divide en tres capas. La primera capa es el Servicio en la nube, que incluye principalmente dos componentes, Servidor y Catlog. Esta capa es la entrada del servicio y todas las solicitudes de los usuarios, incluidas las importaciones de consultas, ingresan desde el servidor. El servidor solo preprocesa la solicitud, pero no la ejecuta; después de que Catlog consulta la metainformación, envía la solicitud preprocesada y la metainformación al Almacén Virtual para su ejecución.
-
Almacén Virtual
El almacén virtual es la capa de ejecución. Diferentes negocios pueden tener Almacenes Virtuales independientes para lograr el aislamiento de recursos. Ahora Virtual Warehouse se divide principalmente en dos categorías, una es Predeterminada y la otra es Escribir. La opción predeterminada se usa principalmente para consultas y la Escritura se usa para importar para realizar la separación de lectura y escritura.
-
VFS
La capa inferior es VFS (almacenamiento de datos), que admite componentes de almacenamiento en la nube como HDFS, S3 y aws.
Diseño de importación en tiempo real basado en arquitectura nativa de la nube
Bajo la arquitectura nativa de la nube, el servidor no realiza una ejecución de importación específica, sino que solo administra tareas. Por lo tanto, del lado del servidor, cada mesa de consumo tendrá un Gerente para administrar todas las tareas de ejecución de consumo y programarlas para que se ejecuten en el Almacén Virtual.
Debido a que hereda el modo de consumo de bajo nivel de HaKafka, Manager distribuirá de manera uniforme las particiones de temas a cada tarea de acuerdo con la cantidad configurada de tareas de consumo; la cantidad de tareas de consumo es configurable y el límite superior es la cantidad de particiones de temas.
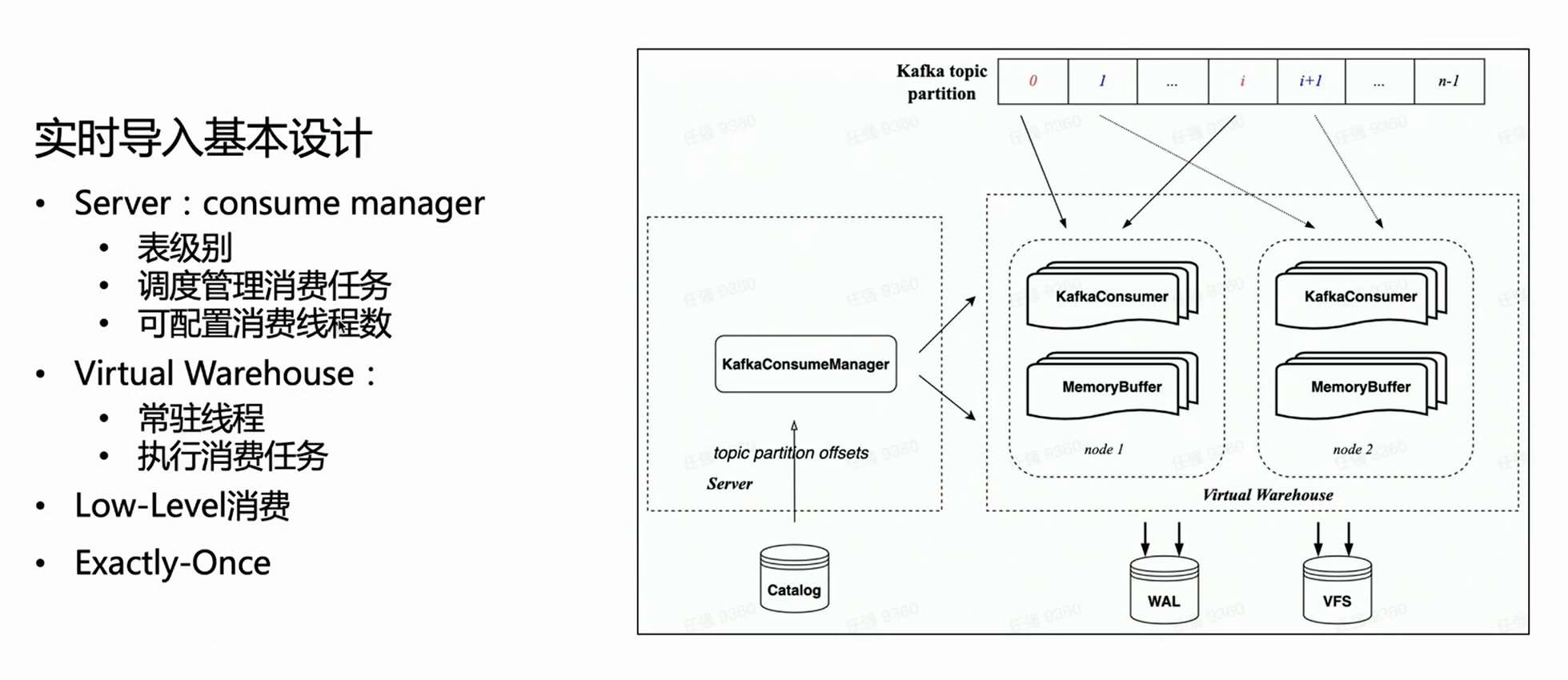
Según la figura anterior, puede ver que el Administrador de la izquierda obtiene la Compensación correspondiente del catálogo y luego asigna la Partición de consumo correspondiente de acuerdo con el número especificado de tareas de consumo y las programa en diferentes nodos del Almacén virtual para ejecución.
Proceso de Ejecución de Nuevos Consumos
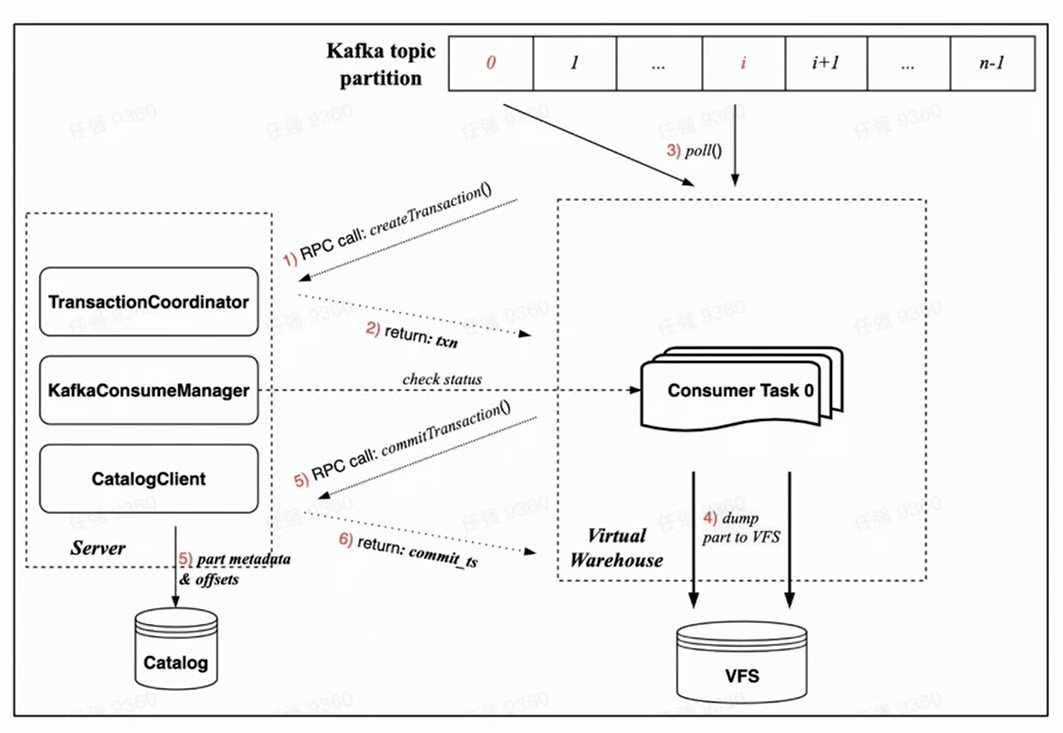
Debido a que Transaction garantiza la nueva arquitectura nativa de la nube, se espera que todas las operaciones se completen en una sola transacción, lo que es más racional.
Basándose en la implementación de Transaction bajo la nueva arquitectura nativa de la nube, el proceso de consumo de cada tarea de consumo incluye principalmente los siguientes pasos:
-
Antes de que comience el consumo, la tarea del lado del trabajador primero solicitará al lado del servidor que cree una transacción a través de una solicitud RPC;
-
Ejecute rdkafka::poll() para consumir una cierta cantidad de tiempo (8s por defecto) o un bloque de tamaño suficiente;
-
Convertir bloque a Parte y volcar a VFS ( los datos no están visibles en este momento );
-
Iniciar una solicitud de confirmación de transacción al servidor a través de una solicitud RPC
(Los datos de confirmación en la transacción incluyen: volcar los metadatos de la pieza completada y la correspondiente compensación de Kafka)
-
La transacción se ha confirmado con éxito ( los datos son visibles )
garantía de tolerancia a fallos
Del proceso de consumo anterior, podemos ver que la garantía de consumo tolerante a fallas bajo la nueva arquitectura nativa de la nube se basa principalmente en el latido bidireccional de Manager y Task y la estrategia de falla rápida:
-
El Administrador en sí tendrá un sondeo regular y verificará si la Tarea programada se está ejecutando normalmente a través de RPC;
-
Al mismo tiempo, cada Tarea utilizará la solicitud RPC de la transacción para verificar su validez durante el consumo. Una vez que la verificación falla, puede eliminarse automáticamente;
-
Una vez que el administrador no detecta actividad, inmediatamente comenzará una nueva tarea de consumo para lograr una garantía de tolerancia a fallas de segundo nivel.
Poder adquisitivo
En cuanto a la capacidad de consumo, se menciona anteriormente que es escalable, y el número de tareas de consumo puede ser configurado por el usuario, hasta el número de Particiones del Topic. Si la carga del nodo en el Almacén virtual es alta, el nodo también se puede expandir muy ligeramente.
Por supuesto, la tarea de programación de Manager implementa la garantía básica de equilibrio de carga: use Resource Manager para administrar y programar tareas.
Mejora semántica: Exactamente, una vez
Finalmente, la semántica de consumo bajo la nueva arquitectura nativa de la nube también se ha mejorado, desde At-Least-Once de la arquitectura de libros distribuidos hasta Exactly-Once.
Debido a que la arquitectura distribuida no tiene transacciones, solo puede lograr un At-Least-Once, lo que significa que no se perderán datos bajo ninguna circunstancia, pero en algunos casos extremos, puede ocurrir un consumo repetido. En la arquitectura nativa de la nube, gracias a la implementación de Transaction, cada consumo puede hacer que Part and Offset se comprometa atómicamente a través de transacciones, para lograr la mejora semántica de Exactly-Once.
Búfer de memoria
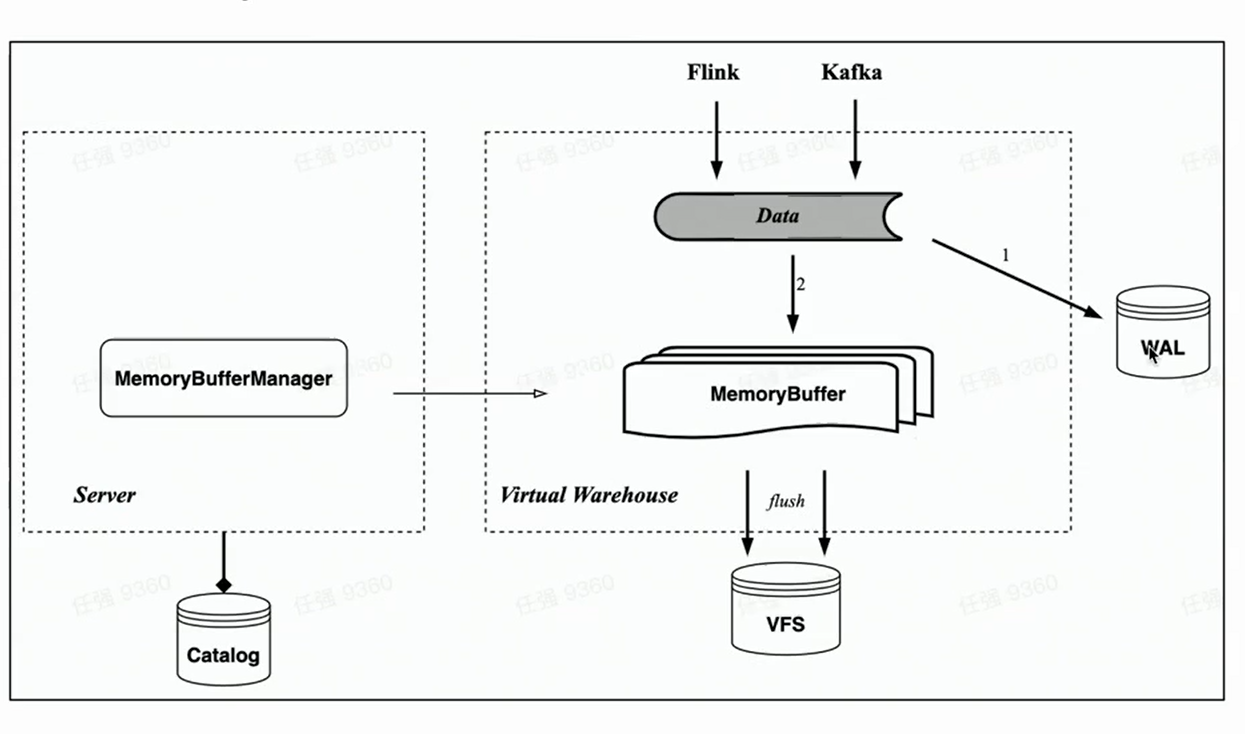
En correspondencia con la tabla de memoria de HaKafka, la arquitectura nativa de la nube también implementa la importación de memoria caché Memory Buffer.
A diferencia de Memory Table, Memory Buffer ya no está vinculado a las tareas de consumo de Kafka, sino que se implementa como una capa de caché para las tablas de almacenamiento. De esta manera, Memory Buffer es más versátil. Puede usarse no solo para la importación de Kafka, sino también para la importación de lotes pequeños como Flink.
Al mismo tiempo, presentamos un nuevo componente WAL. Cuando se importan datos, primero escriba WAL, siempre que la escritura sea exitosa, se puede considerar que la importación de datos fue exitosa; cuando se inicia el servicio, primero puede restaurar los datos que no se han flasheado desde WAL; luego escriba el búfer de memoria, y los datos serán visibles después de la escritura exitosa ——Porque los usuarios pueden consultar el búfer de memoria. Los datos del búfer de memoria también se vacían periódicamente y se pueden borrar de la WAL después del vaciado.
Aplicación empresarial y pensamiento futuro.
Finalmente, presenta brevemente el estado actual de la importación en tiempo real en Byte y la posible dirección de optimización de la tecnología de importación en tiempo real de próxima generación.
La tecnología de importación en tiempo real de ByteHouse se basa en Kafka, el rendimiento diario de datos está en el nivel de PB y el valor de la experiencia del rendimiento de un solo hilo importado o de un solo consumidor es de 10-20 MiB/s. (El valor empírico se enfatiza aquí, porque este valor no es un valor fijo, ni es un valor máximo; el rendimiento del consumo depende en gran medida de la complejidad de la tabla del usuario, a medida que aumenta el número de columnas de la tabla, el rendimiento de la importación puede ser significativamente menor). reducido, no se puede usar una fórmula de cálculo precisa. Por lo tanto, el valor de experiencia aquí es más el valor de experiencia de rendimiento de importación de la mayoría de las tablas dentro del byte).
Además de Kafka, Byte admite la importación en tiempo real de otras fuentes de datos, como RocketMQ, Pulsar, MySQL (MaterializedMySQL), escritura directa de Flink, etc.
Pensamientos simples sobre la próxima generación de tecnología de importación en tiempo real:
-
Una tecnología de importación en tiempo real más general permite a los usuarios admitir más fuentes de datos de importación.
-
La visibilidad de los datos es una compensación entre la latencia y el rendimiento.
Haga clic para ir al almacén de datos nativo en la nube de ByteHouse para obtener más información