
Autor: equipo técnico de SelectDB
Hoy en día, las necesidades de consulta de datos de las empresas aumentan constantemente. Cuando comparten el mismo clúster, a menudo necesitan enfrentar consultas simultáneas de múltiples líneas de negocios o múltiples cargas de análisis al mismo tiempo. En condiciones de recursos limitados, la apropiación de recursos entre tareas de consulta provocará una degradación del rendimiento e incluso inestabilidad del clúster. Por lo tanto, la importancia de la gestión de la carga es evidente.
A partir del escenario empresarial, los requisitos para la gestión de la carga de usuarios provienen principalmente de los siguientes aspectos:
- Cuando varios departamentos comerciales o inquilinos pueden compartir el mismo clúster, para evitar la interacción de carga entre diferentes inquilinos, es necesario garantizar la independencia del uso de recursos y la estabilidad del rendimiento de cada inquilino.
- Diferentes empresas tienen diferentes requisitos en cuanto a la capacidad de respuesta y la prioridad de las tareas de consulta. Para empresas clave o tareas de alta prioridad, como análisis de datos en tiempo real, transacciones en línea, etc., es necesario garantizar que estas tareas puedan obtener recursos suficientes y. ejecutarse con prioridad para evitar la competencia de recursos. Tener un impacto en el rendimiento de la consulta.
- Los usuarios no sólo se preocupan por la asignación y gestión de recursos, sino que también prestan atención al control de costes y la utilización de recursos. La solución de gestión de carga debe cumplir con los requisitos de aislamiento y al mismo tiempo satisfacer las demandas del usuario de bajo costo de uso y alta utilización de recursos.
En las primeras versiones, Apache Doris lanzó una solución de aislamiento basada en etiquetas de recursos, incluida la división de grupos de recursos a nivel de nodo dentro del clúster y límites de recursos para consultas individuales, logrando el aislamiento físico de los recursos entre diferentes usuarios. Para brindar a los usuarios una solución de administración de carga más completa, Apache Doris ha lanzado una solución de administración basada en Workload Group desde la versión 2.0, que implementa el límite suave de los recursos de la CPU y proporciona a los usuarios una mayor utilización de los recursos. La versión 2.1 recientemente lanzada se basa en la tecnología CGroup proporcionada por el kernel de Linux, que implementa límites estrictos en los recursos de la CPU y proporciona a los usuarios una mejor estabilidad de las consultas.
Solución de aislamiento físico basada en Resource Tag
Hay dos tipos de nodos en Apache Doris, FE y BE. El nodo FE es responsable del almacenamiento de metadatos, la gestión del clúster, el acceso a solicitudes de usuarios, el análisis del plan de consultas, etc., mientras que el nodo BE es responsable del almacenamiento y cálculo de datos. El principal consumo de recursos involucrado en el proceso de ejecución de consultas es el nodo BE, por lo que la solución de aislamiento de carga Apache Doris está diseñada para el nodo BE.
En la solución de aislamiento físico de recursos de Resource Tag, puede configurar etiquetas en nodos BE en el mismo clúster. Los nodos BE con las mismas etiquetas formarán un grupo de recursos (Grupo de recursos), y el grupo de recursos puede considerarse como una unidad de almacenamiento de datos. y computación. Cuando se ingresan datos en la base de datos, se escribirán copias de los datos en diferentes grupos de recursos de acuerdo con la configuración del grupo de recursos. Al realizar consultas, los recursos informáticos en el grupo de recursos correspondiente se utilizarán para el cálculo de acuerdo con la división de los grupos de recursos.
Documentación de referencia: https://doris.apache.org/zh-CN/docs/2.0/admin-manual/resource-admin/multi-tenant
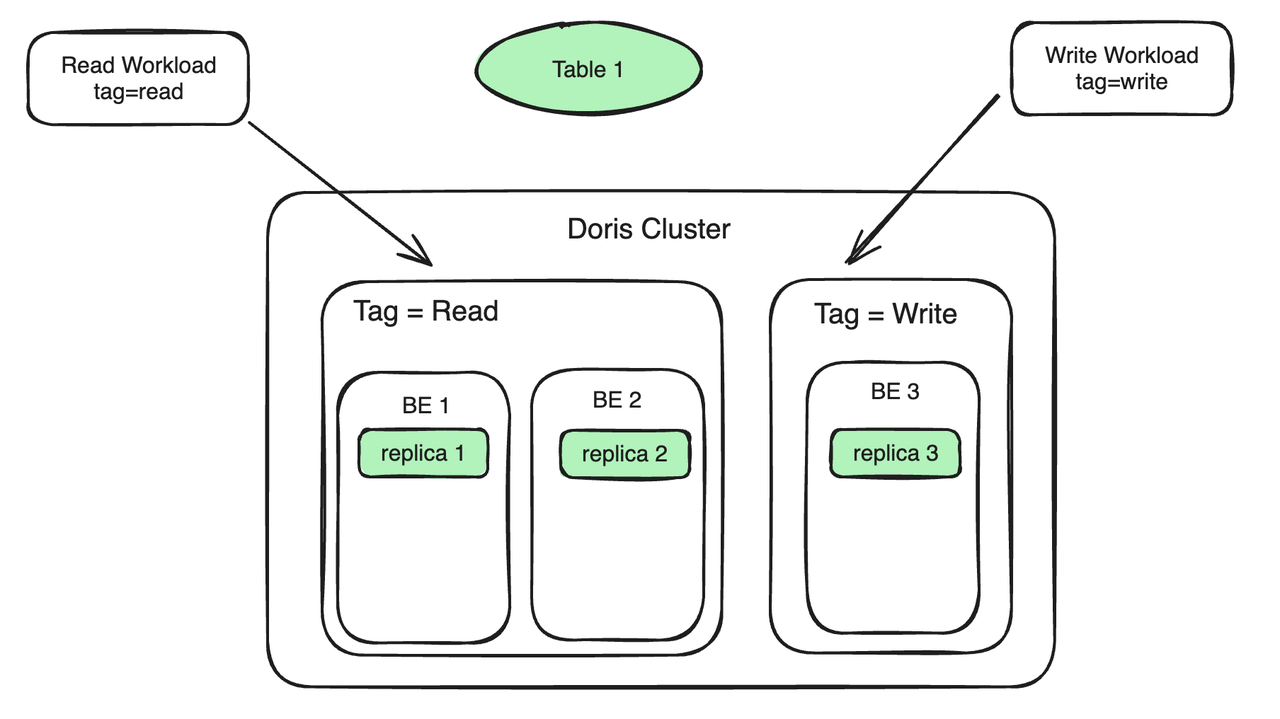
Tomemos como ejemplo un escenario común de análisis de lectura y escritura. Supongamos que hay 3 BE en el clúster. Los pasos de uso específicos son los siguientes:
- Enlace de nodo BE Etiqueta de recurso: enlace dos BE a Tag Read para atender la carga de lectura; enlace un BE a Tag Write para atender la carga de escritura. Las cargas de trabajo de lectura y escritura se ubican en diferentes máquinas para lograr el aislamiento de lectura y escritura.
- Las copias de datos están vinculadas a la etiqueta de recurso: la Tabla 1 tiene tres copias, dos copias están vinculadas a la etiqueta de lectura y una copia está vinculada a la etiqueta de escritura. Los datos escritos en la réplica 3 se sincronizarán automáticamente con la réplica 1 y la réplica 2. El proceso de sincronización no ocupará demasiados recursos informáticos de BE 1 y BE 2.
- La carga de trabajo está vinculada a la etiqueta de recurso: si la etiqueta que lleva la consulta SQL es leída, la consulta se enrutará automáticamente a la máquina (BE 1, BE 2) con la etiqueta como leída para su ejecución si se importa la carga de flujo; en la carga y la etiqueta especificada es Write, entonces la carga de flujo se enrutará a la máquina cuya etiqueta es Write (BE 3). En este proceso, además de la sobrecarga generada durante la sincronización de réplicas, ya no hay competencia por los recursos entre la consulta y la importación.
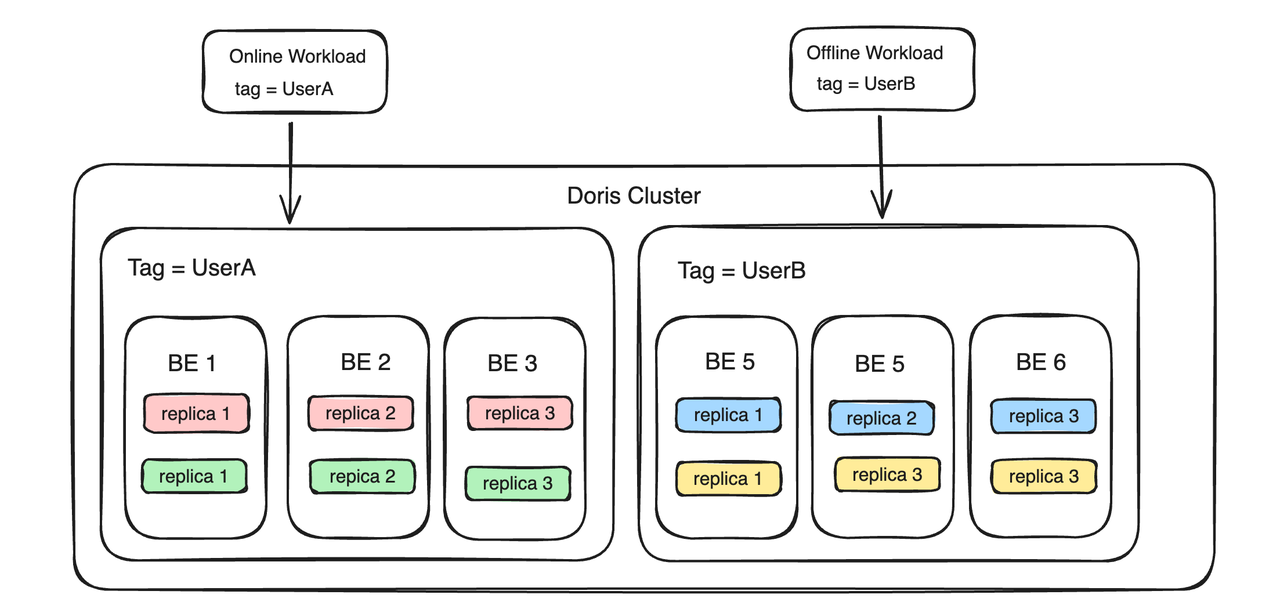
Resource Tag también puede implementar funciones multiinquilino. Por ejemplo, hay dos usuarios, UsuarioA y UsuarioB, que desean crear inquilinos independientes para evitar la influencia mutua. Luego, puede vincular los recursos informáticos y de almacenamiento del UsuarioA a una etiqueta denominada UsuarioA y vincular los recursos informáticos y de almacenamiento del UsuarioB a una etiqueta denominada UsuarioA. es la etiqueta del UsuarioB, entonces los dos usuarios logran el aislamiento de recursos entre los inquilinos en el lado BE.
La esencia de Resource Tag es lograr el aislamiento de recursos agrupando nodos BE. Las ventajas de esta solución son:
- Buen aislamiento, varios inquilinos están aislados a través de máquinas físicas y se logra un aislamiento completo de CPU, memoria e IO;
- Aislamiento de fallas: cuando ocurre un problema en un inquilino (como una falla en el proceso), el otro inquilino no se ve afectado en absoluto;
Con base en esta tecnología, algunos usuarios colocan diferentes grupos de recursos en diferentes salas de computadoras físicas para lograr el funcionamiento activo-activo de dos salas de computadoras en la misma ciudad.
Pero también existen ciertas limitaciones:
- En el escenario de aislamiento de lectura y escritura, cuando se detiene la carga de escritura, la máquina con Tag Write estará en un estado inactivo, lo que reducirá la utilización de recursos de todo el clúster, lo que obviamente no puede cumplir con las expectativas del usuario sobre la utilización completa de los recursos.
- En un escenario de múltiples inquilinos, las cargas de múltiples partes comerciales dentro del mismo inquilino también se afectarán entre sí. Incluso si se puede lograr el aislamiento configurando máquinas físicas separadas para cada parte del negocio, esto traerá problemas como un alto costo y una baja utilización de recursos.
- La flexibilidad es pobre. La cantidad de inquilinos en realidad está vinculada a la cantidad de réplicas. Si desea establecer 5 inquilinos, necesita al menos 5 réplicas, lo que provoca una pérdida de espacio de almacenamiento hasta cierto punto.
Solución de gestión de carga basada en Workload Group
Para resolver los problemas anteriores, Apache Doris lanzó una solución de administración basada en Workload Group, que admite un mecanismo de aislamiento de recursos más detallado: aislamiento de recursos dentro del proceso, lo que significa que varias salas de consultas en el mismo BE también pueden lograr un Hasta cierto punto, el aislamiento evita efectivamente la competencia de recursos dentro del proceso y mejora la utilización de los recursos.
Workload Group gestiona cargas de trabajo en grupos para lograr una gestión y un control refinados de la memoria y los recursos de la CPU. Limite el porcentaje de recursos de CPU y memoria de una única consulta en un único nodo BE asociando la consulta ejecutada por el usuario con el grupo de carga de trabajo. Al mismo tiempo, puede configurar y habilitar límites de recursos de memoria. Cuando los recursos del clúster son escasos, las consultas con un uso elevado de memoria en el grupo finalizarán automáticamente para aliviar la presión. Cuando los recursos están inactivos, varios grupos de cargas de trabajo comparten recursos inactivos y superan automáticamente los límites para garantizar una ejecución estable de las consultas.
Los límites de los recursos de la CPU se pueden subdividir en límites flexibles y límites estrictos. Los límites flexibles de la CPU tienen las características de una mayor utilización de recursos y permiten una asignación flexible de recursos cuando los recursos están inactivos, mientras que los límites estrictos de la CPU se centran más en garantizar la estabilidad del rendimiento y garantizar que los grupos estarán activos. no interfieran entre sí debido a cambios de carga.
( Los dos métodos de aislamiento de límite estricto de CPU y límite flexible pueden coincidir con diferentes escenarios de uso, pero no se pueden aplicar al mismo tiempo. Los usuarios pueden elegir de manera flexible según sus propias necesidades)
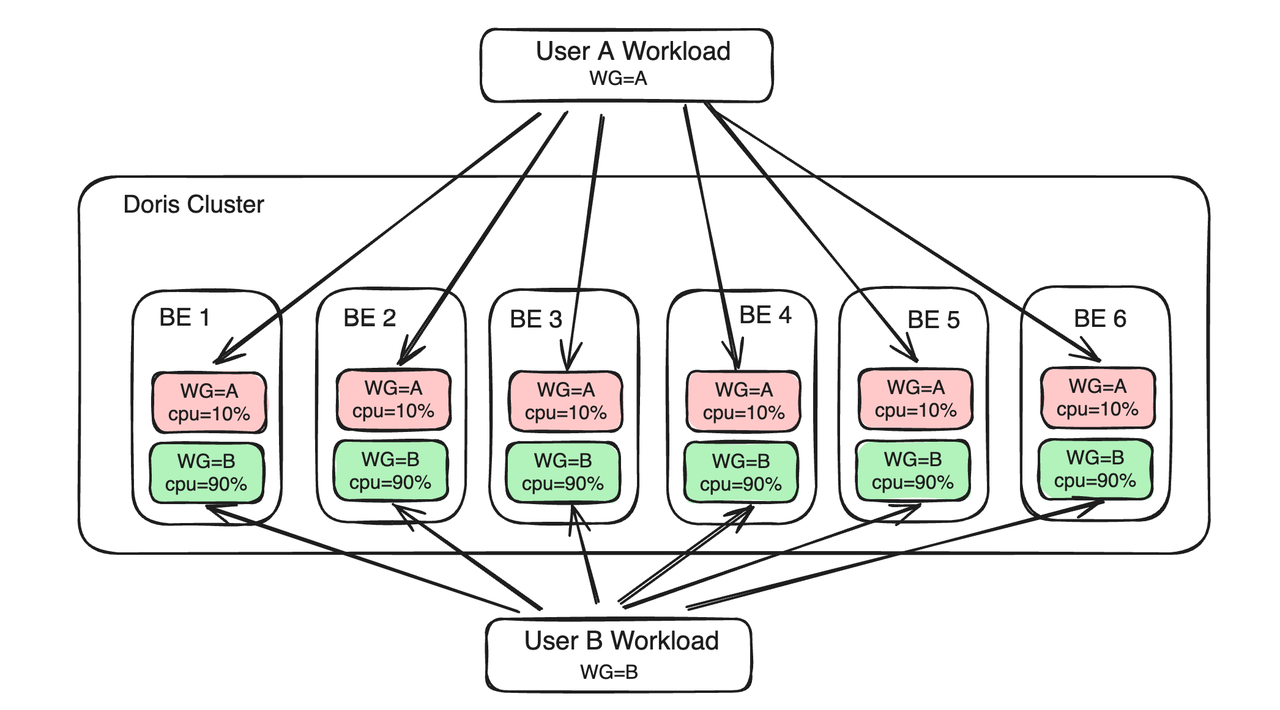
Las principales diferencias entre las soluciones Workload Group y Resource Tag son las siguientes:
- Desde la perspectiva de los recursos informáticos, el grupo de cargas de trabajo divide aún más los recursos de CPU y memoria dentro del proceso BE. Varios grupos de cargas de trabajo deben competir por los recursos en el mismo BE. Las etiquetas de recursos agrupan los nodos BE y las cargas de diferentes partes comerciales se envían a BE en diferentes grupos para lograr el aislamiento de recursos. No habrá competencia directa de recursos entre cargas comerciales en diferentes grupos BE.
- Desde la perspectiva de los recursos de almacenamiento, Workload Group no necesita prestar atención a los recursos de almacenamiento, solo se centra en la asignación de recursos informáticos dentro de un único BE. Resource Tag requiere agrupar copias de datos para garantizar que los datos del lado comercial que deben aislarse se distribuyan en diferentes BE.
01 límite suave de CPU
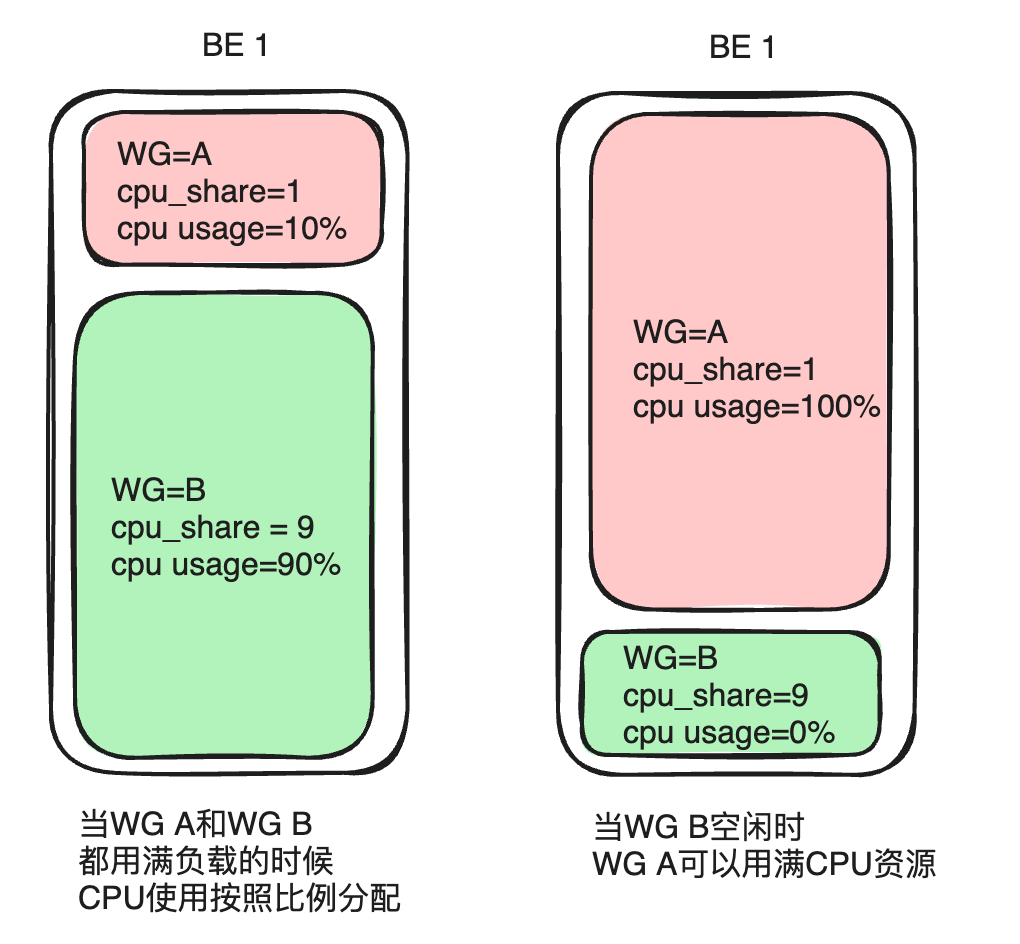
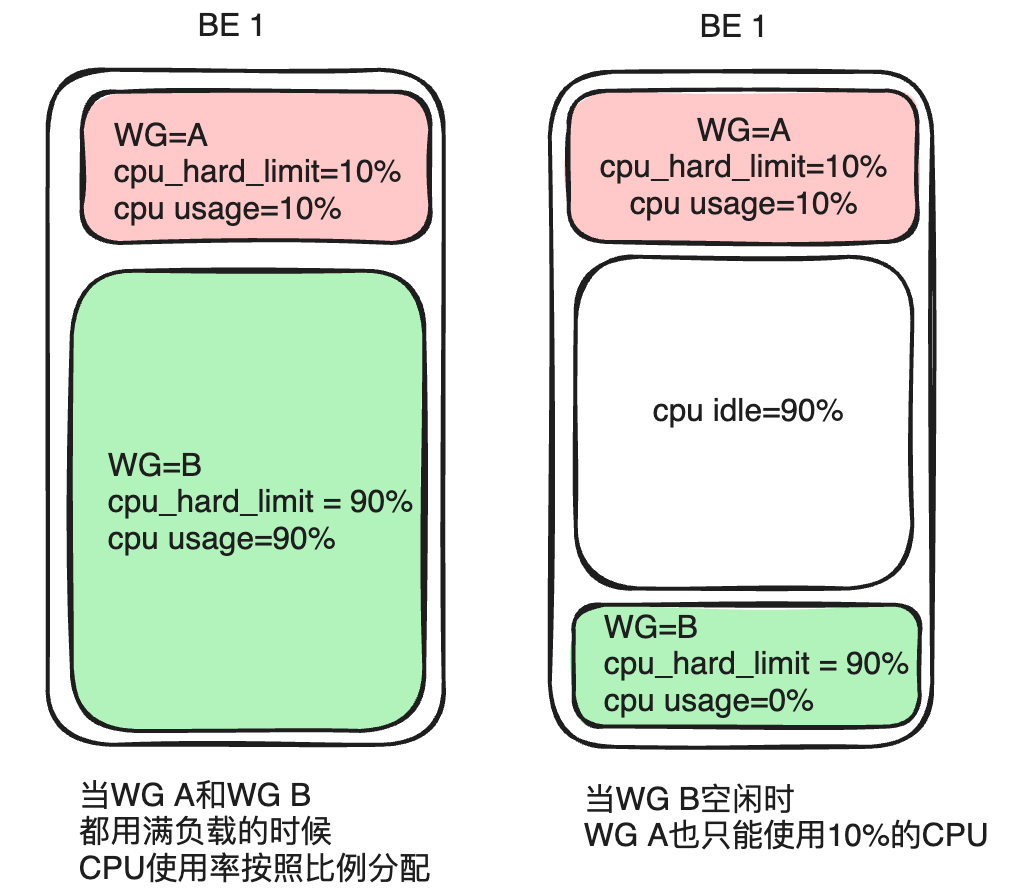
La prioridad de la CPU se refleja principalmente cpu_sharea través de parámetros, que se pueden comparar con el concepto de peso. En el mismo período de tiempo, un grupo con mayor peso puede obtener más tiempo de CPU.
Tome el Grupo A y el Grupo B como ejemplo. Si el Grupo A está configurado cpu_sharecomo 1 y el Grupo B está configurado cpu_sharecomo 9, se proporciona un período de tiempo de 10 segundos. Cuando ambas cargas están saturadas, el grupo B con un peso mayor puede obtener tiempo de CPU durante 9 segundos (90 % de todos los recursos) y el grupo A puede obtener tiempo de CPU durante 1 segundo (10 % de todos los recursos). En el uso real, no todos los servicios se ejecutan a plena carga. Si la carga del Grupo B es baja o no tiene carga, el Grupo A puede monopolizar el tiempo de la CPU durante 10 segundos. Este método puede proporcionar una mayor flexibilidad de asignación de recursos, mejorando así la utilización general de los recursos de CPU del clúster.
02 límite estricto de CPU
El uso del límite de tiempo flexible de la CPU puede provocar fluctuaciones en el rendimiento de las consultas si la carga del sistema es alta o los recursos de la CPU son escasos. Para cumplir con los altos requisitos de los usuarios para un rendimiento de consulta estable, Apache Doris ha implementado el límite estricto de CPU del grupo de carga de trabajo en la última versión 2.1: independientemente de si la CPU general de la máquina física actual está inactiva, el uso máximo de CPU de el grupo configurado con el límite estricto no puede exceder el valor límite preconfigurado.
Tome el Grupo A y el Grupo B como ejemplo . Si configura el Grupo A cpu_hard_limit=10%, el Grupo B. cpu_hard_limit=90%Cuando los recursos de CPU de ambas máquinas individuales alcanzan la saturación, la utilización de CPU del grupo A es del 10% y la utilización de CPU del grupo B es del 90%, que es lo mismo que el límite flexible de CPU. Sin embargo, cuando la carga del Grupo B disminuye o no hay carga, incluso si el Grupo A aumenta la carga de consultas, su utilización máxima de CPU todavía está estrictamente limitada al 10% y no puede obtener más recursos. Aunque este enfoque sacrifica la flexibilidad de la asignación de recursos, también garantiza la estabilidad del rendimiento de las consultas.
03 Limitaciones de recursos de memoria
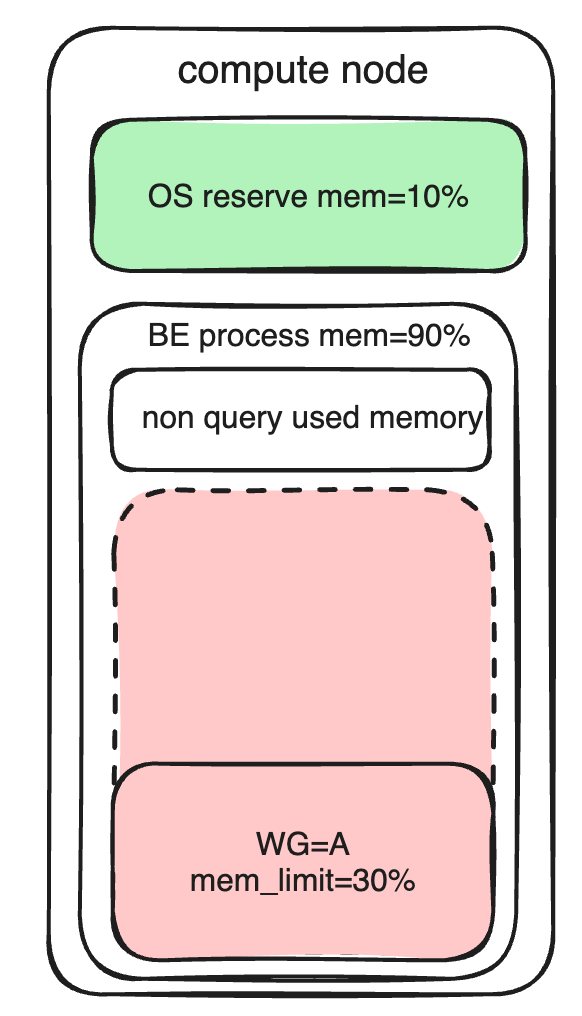
Instrucciones de uso: la memoria del nodo BE se divide principalmente en las siguientes partes:
- El sistema operativo reserva memoria
- La parte de la memoria que no es de consulta en el proceso BE no puede ser contada por el grupo de carga de trabajo por el momento.
- El grupo de carga de trabajo puede contar y administrar la memoria de la parte de consulta dentro del proceso BE (incluidas las operaciones de importación).
Los límites de recursos de memoria están limitados principalmente memory_limitpor parámetros (estableciendo el porcentaje de memoria BE que se puede utilizar). No solo puede configurar el uso de la memoria preconfigurada, sino que también puede afectar la prioridad de devolución de la memoria después de una sobrecompromiso.
En el estado inicial, a los grupos de recursos de alta prioridad se les asignará más memoria y a los grupos de recursos de baja prioridad se les asignará menos memoria. Para mejorar la utilización de la memoria, puede enable_memory_overcommithabilitar el límite flexible de memoria del grupo de recursos. Si el sistema tiene recursos de memoria libres, se pueden usar más allá del límite.
Para garantizar el funcionamiento estable del sistema, cuando los recursos de memoria generales del sistema sean insuficientes, el sistema dará prioridad a cancelar tareas que ocupan grandes cantidades de memoria para recuperar recursos de memoria comprometidos en exceso. Durante este proceso, el sistema intentará reservar los recursos de memoria de los grupos de recursos de alta prioridad y el exceso de memoria de los grupos de recursos de baja prioridad se recuperará más rápido.
04 Cola de consultas
Cuando la carga comercial excede el límite superior del sistema, continuar enviando nuevas consultas no solo no se ejecutará de manera efectiva, sino que también afectará las consultas en ejecución. Para evitar este problema, Workload Group admite colas de consultas. Cuando la consulta alcance la simultaneidad máxima preestablecida, el nuevo plan de envío ingresará a la lógica de cola. Cuando la cola esté llena o se agote el tiempo de espera, la consulta será rechazada para aliviar la presión sobre el sistema bajo carga alta.
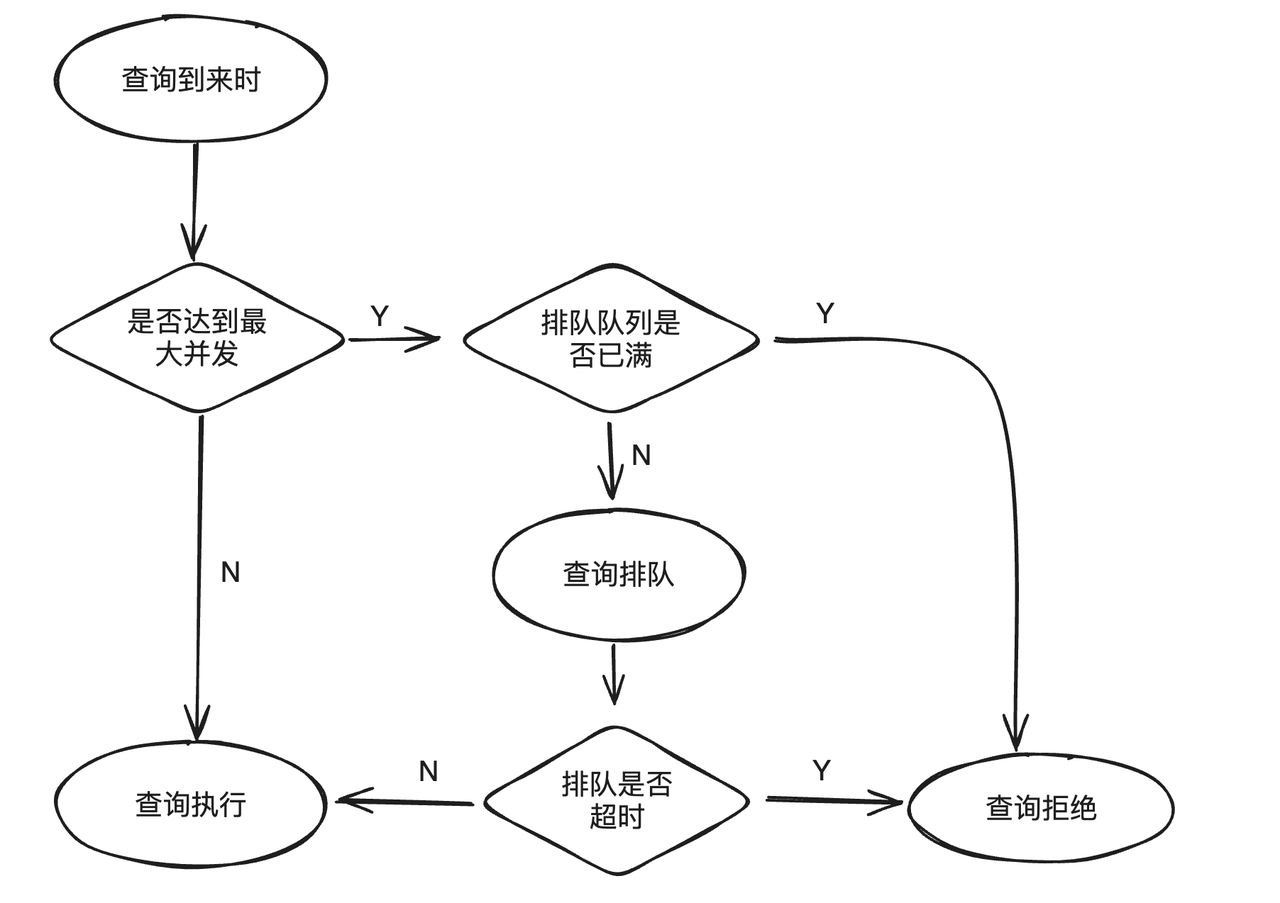
La función de cola de consultas tiene principalmente tres atributos:
max_concurrency: El número máximo de sentencias SQL permitidas para ejecutarse simultáneamente en el grupo actual. Si se excede el número máximo, se ingresará la lógica de cola.max_queue_size: el número máximo de consultas permitidas en la cola. Si la cola está llena, la consulta será rechazada y la ejecución fallará.queue_timeout: El límite de tiempo para hacer cola en la cola si se agota, fallará directamente. La unidad es milisegundos.
Documentación de referencia: https://doris.apache.org/zh-CN/docs/admin-manual/workload-group
Prueba de uso del grupo de cargas de trabajo
A continuación, realizamos pruebas detalladas sobre el límite flexible y estricto de la CPU del grupo de carga de trabajo para demostrar claramente a los usuarios el efecto de administración de carga y el rendimiento de estos dos límites en las mismas condiciones de hardware.
- Entorno de prueba: máquina física única con memoria de 16 núcleos y 64 G
- Método de implementación: 1 FE, 1 BE
- Conjunto de datos de prueba: Clickbench, TPCH
- Herramienta de medición de estrés: JMeter
01 prueba de límite suave de CPU
Inicie dos clientes (1, 2) para probar el efecto del límite suave de la CPU en la administración de carga sin usar/usar el límite suave de la CPU respectivamente. Cabe señalar que en esta prueba, Page Cache afectará los resultados de la prueba y es necesario desactivar Page Cache para lograr los resultados ideales de la prueba.
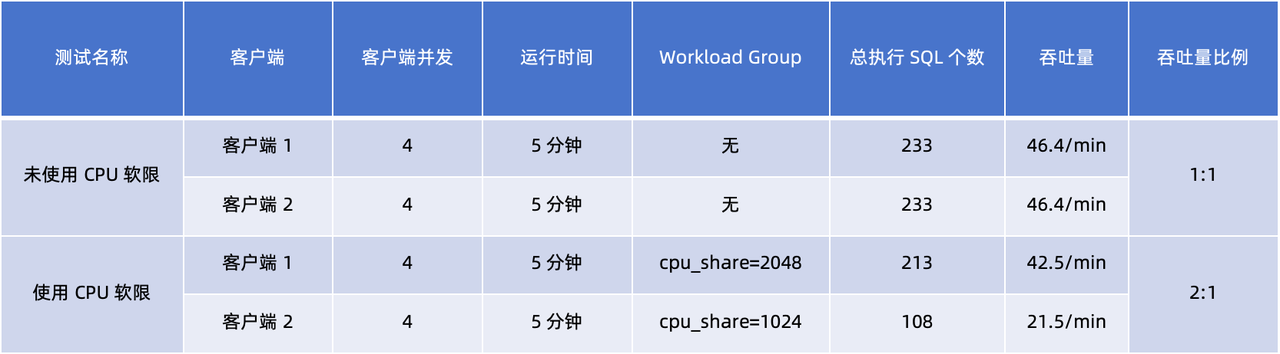
Al comparar y analizar los datos de rendimiento del cliente en las dos pruebas, podemos sacar las siguientes conclusiones:
- Sin Workload Group , la relación de rendimiento de los dos clientes es 1:1, lo que indica que reciben los mismos recursos de CPU durante el mismo tiempo de ejecución.
- Después de usar Workload Group y
cpu_shareconfigurarlos en 2048 y 1024 respectivamente , los resultados muestran que la relación de rendimiento pasa a ser 2:1. Esto muestra quecpu_shareel cliente 1 con parámetros más grandes obtiene una mayor proporción de recursos de CPU en el mismo tiempo de ejecución .
02 prueba de límite estricto de CPU
Como se puede ver en la introducción anterior, el límite estricto de la CPU puede garantizar un buen aislamiento cuando la carga es alta. Por lo tanto, usamos un límite estricto para limitar el uso de la CPU al 50% ( cpu_hard_limit=50%) y usamos el mismo cliente para ejecutar la prueba de consulta q23 cuando el número de concurrencias es 1, 2 y 4 (simulando cargas diferentes). durante 5 minutos. .

De los resultados de las pruebas anteriores, podemos ver que a medida que aumenta el número de consultas simultáneas, la utilización de la CPU siempre se mantiene estable en alrededor del 800% (en una máquina de 16 núcleos, 800% significa usar 8 núcleos y la utilización real de la CPU es 50 % ). Debido a que los recursos de la CPU están muy limitados, se espera que la latencia de tp99 aumente a medida que aumenta la simultaneidad.
03 Simular pruebas del entorno de producción
En entornos de producción reales, los usuarios suelen prestar más atención al rendimiento de la latencia de consultas que al rendimiento puro. Para estar más cerca de los escenarios de aplicaciones reales y evaluar con precisión el rendimiento, seleccionamos una serie de consultas SQL con una latencia de aproximadamente 1 segundo (incluidos q15, q17, q23 de CKBench y q3, q7, q19 de TPCH) para formar un conjunto de SQL. Estas consultas cubren varias características, como la agregación de una sola tabla y el cálculo de uniones, y el tamaño del conjunto de datos TPCH utilizado es 100G.
Diseñamos dos conjuntos de pruebas para simular escenarios sin Workload Group y con Workload Group respectivamente. Se realizaron cuatro pruebas en el Cliente 1 y el Cliente 2, centrándose en la latencia de tp90 y tp99.
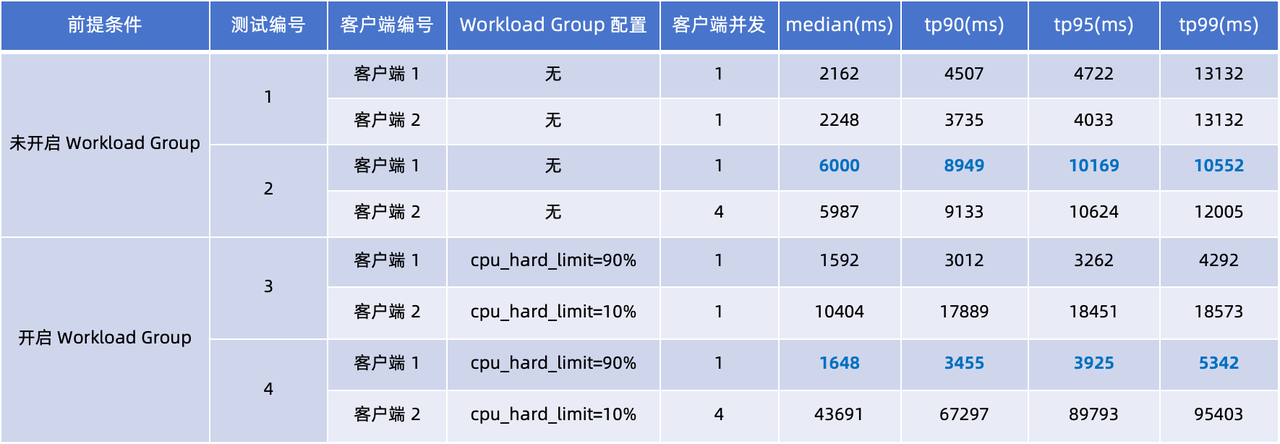
Al observar los retrasos en las consultas en las cuatro pruebas de la tabla anterior, podemos sacar las siguientes conclusiones:
- No se utiliza el grupo de carga de trabajo (pruebas 1 y 2) : cuando la concurrencia del cliente 2 aumenta de 1 a 4, los retrasos en las consultas de los clientes 1 y 2 aumentan significativamente. Al comparar el rendimiento del cliente 1, los tiempos de respuesta de consultas medianas, tp90 y tp95 han aumentado de 2 a 3 veces.
- Usando Workload Group (Prueba 3, 4): Se aplicaron límites estrictos de CPU en estas dos pruebas: Set Client 1
cpu_hard_limit=90%, Client 2cpu_hard_limit=90%. Se puede ver en los resultados de la prueba que incluso si aumenta la concurrencia del cliente 2, el retraso de la consulta del cliente 1 solo aumenta ligeramente, lo que es significativamente mejor que el rendimiento en la prueba 2. Este resultado demuestra plenamente la eficacia de Workload Group en el aislamiento de carga y la garantía de estabilidad del rendimiento.
Conclusión
En la actualidad, las funciones Etiqueta de recursos y Grupo de carga de trabajo se han lanzado en los servicios de producción de múltiples usuarios de la comunidad y se han verificado a gran escala. Se recomiendan para usuarios con necesidades de aislamiento de recursos.
Ya sea una etiqueta de recurso o un grupo de carga de trabajo, el objetivo es equilibrar la independencia del aislamiento y la utilización de recursos. El primero adopta una solución de aislamiento más completa, mientras que el segundo logra el aislamiento al tiempo que garantiza la utilización total de los recursos y garantiza aún más la estabilidad del sistema. escenarios de alta carga de trabajo a través de colas de consultas y mecanismos de cola de tareas.
En el uso real del aislamiento de recursos, recomendamos que las dos soluciones se puedan combinar y aplicar de acuerdo con los escenarios comerciales:
- Si el mismo clúster se comparte entre sistemas/departamentos de negocios y desea lograr el aislamiento físico de los recursos y datos, puede adoptar la solución Resource Tag;
- Si enfrenta varios tipos de cargas de consultas al mismo tiempo en el mismo clúster, puede distinguir diferentes cargas a través del Grupo de cargas de trabajo y asegurarse de que varias cargas de consultas puedan obtener los recursos adecuados mediante la asignación flexible de recursos;
Todavía tenemos muchos planes para mejoras funcionales posteriores:
- El límite de memoria actual se utiliza para liberar memoria mediante Cancelar consulta. En el futuro, la ubicación del operador puede mejorar aún más la estabilidad de consultas grandes y evitar fallas en las tareas de consulta cuando los recursos son escasos.
- Actualmente, en el modelo de memoria del proceso BE, parte de la memoria que no es de consulta no se cuenta, lo que puede provocar diferencias entre la memoria del proceso BE y la memoria utilizada por el grupo de carga de trabajo vista por los usuarios. Intentaremos resolver este problema. problema en futuras versiones.
- La función de cola de consultas solo admite colas basadas en el número máximo de consultas simultáneas. En el futuro, el número máximo de consultas simultáneas estará restringido por el uso de recursos de BE, lo que generará una contrapresión automática sobre el cliente y mejorará la disponibilidad de Doris. cuando el cliente continúa sometiendo cargas elevadas.
- La función de etiqueta de recurso es dividir los recursos de la máquina BE y el grupo de carga de trabajo es dividir los recursos dentro de un solo proceso de máquina. Ambos métodos de división de recursos exponen el concepto de nodos BE a los usuarios. Cuando los usuarios utilizan la función de gestión de recursos, básicamente solo necesitan prestar atención a la cantidad de recursos disponibles y la prioridad de asignación de recursos para sus propias cargas de trabajo en todo el conjunto. En el futuro, se explorarán nuevas formas de dividir los recursos para reducir los costos de comprensión y uso de los usuarios.
Expresiones de gratitud
La función Workload Group es un proyecto desarrollado conjuntamente por la comunidad de código abierto. Gracias a los siguientes estudiantes por sus contribuciones: Luo Zenglin (luozenglin), Liu Lijia (liutang123), Zhao Liwei (levy5307).
Decidí renunciar al código abierto Hongmeng Wang Chenglu, el padre del código abierto Hongmeng: El código abierto Hongmeng es el único evento de software industrial de innovación arquitectónica en el campo del software básico en China: se lanza OGG 1.0, Huawei contribuye con todo el código fuente. Google Reader es asesinado por la "montaña de mierda de códigos" Fedora Linux 40 se lanza oficialmente Ex desarrollador de Microsoft: el rendimiento de Windows 11 es "ridículamente malo" Ma Huateng y Zhou Hongyi se dan la mano para "eliminar rencores" Compañías de juegos reconocidas han emitido nuevas regulaciones : los regalos de boda de los empleados no deben exceder los 100.000 yuanes Ubuntu 24.04 LTS lanzado oficialmente Pinduoduo fue sentenciado por competencia desleal Compensación de 5 millones de yuanes