
En la era digital, los datos son uno de los activos más valiosos de una empresa. Sin embargo, a medida que crece la cantidad de datos, también aumenta la complejidad de la gestión de bases de datos. Una falla en la base de datos puede causar interrupciones en el negocio y provocar enormes pérdidas financieras y de reputación a la empresa. En este blog, compartiremos cómo KaiwuDB diseña herramientas de diagnóstico de fallas y demostraciones de ejemplos específicos.
01 ideas de diseño
Siga los principios básicos
- Fácil de usar: incluso los usuarios con diferentes niveles de habilidad pueden utilizar fácilmente nuestras herramientas;
- Monitoreo integral: monitoreo integral de todos los aspectos del sistema de base de datos, incluidos los indicadores de rendimiento, los recursos del sistema y la eficiencia de las consultas;
- Diagnóstico inteligente: utiliza algoritmos avanzados para identificar la causa raíz de los problemas;
- Reparaciones automatizadas: proporciona sugerencias de reparación con un solo clic y, cuando es posible, aplica estas reparaciones automáticamente;
- Extensibilidad: permite a los usuarios ampliar y personalizar la funcionalidad de la herramienta según sus necesidades específicas.
Admite la recopilación de indicadores clave
Para garantizar un diagnóstico integral, la herramienta recopilará una serie de indicadores clave, que incluyen, entre otros:
- Configuración del sistema: versión de la base de datos, sistema operativo, arquitectura y número de CPU, capacidad de memoria, tipo y capacidad del disco, punto de montaje, tipo de sistema de archivos;
- Situación de implementación: ya sea una implementación básica o de contenedor, el modo de implementación y el número de nodos de la instancia de la base de datos; organización de datos: la estructura del directorio de datos, la configuración local y del clúster, las tablas y parámetros del sistema;
- Estadísticas de bases de datos: número de bases de datos comerciales, número de tablas en cada base de datos y estructura de tablas;
- Características de las columnas: características estadísticas de columnas numéricas y columnas de enumeración, longitud y detección de caracteres especiales de columnas de cadena;
- Archivos de registro: registro de relaciones, registro de tiempos, registro de errores, registro de auditoría;
- Información PID: la cantidad de identificadores abiertos por el proceso de la base de datos, la cantidad de MMAP abiertos, estadísticas y otra información;
- Datos de rendimiento: plan de ejecución de SQL, datos de monitoreo del sistema (CPU, memoria, E/S), uso y eficiencia del índice, patrones de acceso a datos, bloqueos (conflictos de transacciones y eventos de espera), eventos del sistema, etc.
Admite diferentes modos de funcionamiento
La herramienta proporcionará dos modos de funcionamiento para satisfacer las necesidades de diferentes escenarios:
- Recopilación única: capture rápidamente el estado actual del sistema y los datos de rendimiento, adecuados para el diagnóstico inmediato de problemas;
- Recopilación programada: recopile datos periódicamente de acuerdo con un plan preestablecido para el seguimiento del rendimiento a largo plazo y el análisis de tendencias.
Adaptarse a diversos análisis de tendencias.
Los datos recopilados se utilizarán para realizar análisis de tendencias, con capacidades que incluyen:
- Tendencias de rendimiento: identifique tendencias en el rendimiento de la base de datos a lo largo del tiempo y prediga posibles cuellos de botella en el rendimiento;
- Uso de recursos: realice un seguimiento del uso de recursos del sistema y ayude a optimizar la asignación de recursos;
- Análisis de registros: analice archivos de registro para identificar patrones anormales y errores frecuentes;
- Optimización de consultas: proporcione sugerencias de optimización de consultas mediante el análisis de los planes de ejecución de SQL;
- Mejores prácticas: proporcione recomendaciones de configuración óptimas a través de un análisis integral de la distribución de datos y los recursos de hardware.
02 Arquitectura general
La herramienta de diagnóstico de fallas se divide en dos partes: recopilación y análisis:
- La parte de recopilación está conectada al sistema operativo/base de datos/servidor de monitoreo de destino, admite análisis simplificados de reglas locales y genera informes de texto sin formato;
- La parte de análisis lee y formatea los datos recopilados y los carga en el servidor de análisis para su persistencia. Admite análisis detallado y predicción de reglas en línea y genera informes detallados a través de la interfaz de usuario.
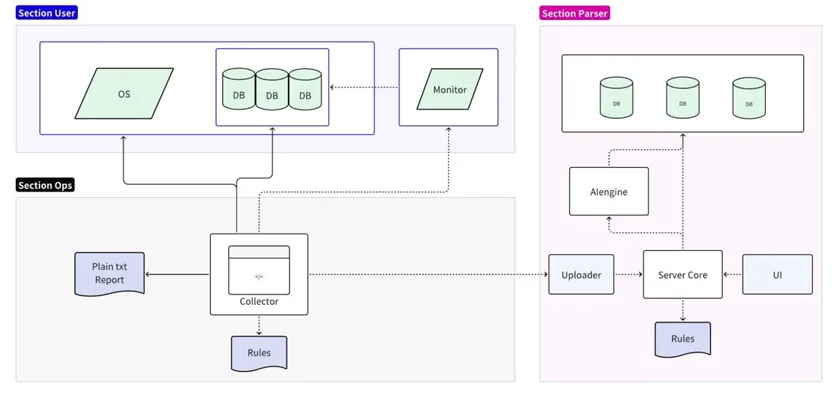
Implementación del recopilador
El recopilador es una herramienta utilizada directamente por el personal de operación y mantenimiento en el sitio. Obtiene diversa información original en el sitio a través del sistema operativo, la base de datos y los servicios de monitoreo. De forma predeterminada, se admiten la compresión y la exportación directa después de la recopilación. También puede utilizar reglas locales para realizar el análisis más básico, como buscar e imprimir todos los mensajes de error.

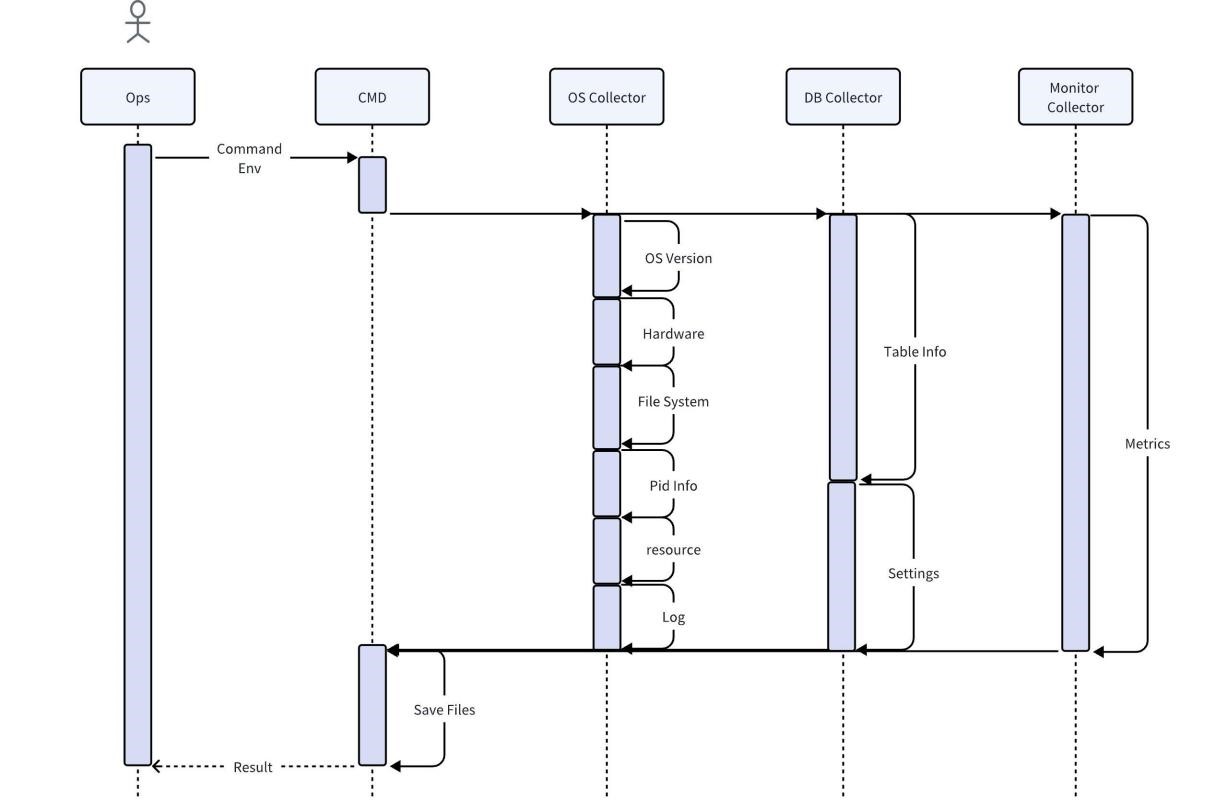
Teniendo en cuenta que la recopilación directa de datos comerciales del usuario puede generar el riesgo de exponer la información del usuario, durante el proceso de recopilación del recopilador de la base de datos, solo se capturarán las características de los datos del usuario y no se copiarán datos. Para garantizar la integridad y exactitud de otros datos, los datos recopilados no se procesarán de ninguna manera antes del análisis y se mantendrán los datos necesarios para proporcionar información completa. Para ahorrar espacio, los datos recopilados deben comprimirse. Al mismo tiempo, el recopilador debe ser compatible con la mayoría de los sistemas operativos y no requerir dependencias adicionales.
Implementación del motor de reglas
Para el análisis de datos posterior, el motor de reglas debe ser compatible con el recopilador de datos para proporcionar una salida de datos estandarizada y tener cierta escalabilidad. Por ejemplo, para analizar el aumento en el uso de la CPU cuando se ejecuta un SQL específico, es necesario generar los metadatos de la consulta SQL (como el texto SQL, el tiempo de ejecución, etc.) y los indicadores de rendimiento (como el uso de la CPU) en el formato del motor de sincronización para analizar los cuellos de botella en el rendimiento.
Para proporcionar suficiente escalabilidad y poder cubrir un conjunto de reglas en constante expansión, incluidas cuestiones funcionales como la verificación de códigos de error, el motor de reglas lee reglas de archivos externos y luego aplica estas reglas para analizar los datos. Los siguientes son algunos ejemplos de código:
Python
import pandas as pd
import json
# 加载规则
def load\_rules(rule\_file):
with open(rule_file, 'r') as file:
return json.load(file)
# 自定义规则函数,这个函数将检查特定SQL执行时CPU使用率是否有显著增加
def sql\_cpu\_bottleneck(row, threshold):
# 比较当前行的CPU使用率是否超过阈值
return row\['sql\_query'\] == 'SELECT * FROM table\_name' and row\['cpu_usage'\] > threshold
# 应用规则
def apply\_rules(data, rules\_config, custom_rules):
for rule in rules_config:
data\[rule\['name'\]\] = data.eval(rule\['expression'\])
for rule\_name, custom\_rule in custom_rules.items():
data\[rule\_name\] = data.apply(custom\_rule, axis=1)
return data
# 读取CSV数据
df = pd.read\_csv('sql\_performance_data.csv')
# 加载规则
rules\_config = load\_rules('rules.json')
# 定义自定义规则
custom_rules = {
'sql\_cpu\_bottleneck': lambda row: sql\_cpu\_bottleneck(row, threshold=80)
}
# 应用规则并得到结果
df = apply\_rules(df, rules\_config, custom_rules)
# 输出带有规则检查结果的数据
df.to\_csv('evaluated\_sql_performance.csv', index=False)
Los archivos de reglas deben ampliarse continuamente con iteraciones de versiones y admitir actualizaciones en caliente. El siguiente es un ejemplo de un archivo de configuración de reglas en formato JSON. Las reglas se definen como objetos JSON, cada uno de los cuales contiene un nombre y una expresión entendida por Pandas DataFrame.
JSON
\[
{
"name": "high\_execution\_time",
"expression": "execution_time > 5"
},
{
"name": "general\_high\_cpu_usage",
"expression": "cpu_usage > 80"
},
{
"name": "slow_query",
"expression": "query_time > 5"
},
{
"name": "error\_code\_check",
"expression": "error_code not in \[0, 200, 404\]"
}
// 其他规则可以在此添加
\]
Predicción realizada
Las herramientas de diagnóstico se pueden conectar a motores de predicción para detectar riesgos potenciales con antelación. El siguiente ejemplo utiliza el clasificador de árbol de decisión scikit-learn para entrenar un modelo y utiliza el modelo para hacer predicciones:
Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.model\_selection import train\_test_split
from sklearn.metrics import accuracy_score
# 读取CSV数据
df = pd.read\_csv('performance\_data.csv')
# 假设我们已经有了一个标记了性能问题的列 'performance_issue'
# 这个列可以通过规则引擎或历史数据分析得到
# 特征和标签
X = df\[\['cpu\_usage', 'disk\_io', 'query_time'\]\]
y = df\['performance_issue'\]
# 分割数据集为训练集和测试集
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42)
# 创建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X\_train, y\_train)
# 预测测试集
y\_pred = model.predict(X\_test)
# 打印准确率
print(f'Accuracy: {accuracy\_score(y\_test, y_pred)}')
# 保存模型,以便以后使用
import joblib
joblib.dump(model, 'performance\_predictor\_model.joblib')
# 若要使用模型进行实时预测
def predict\_performance(cpu\_usage, disk\_io, query\_time):
model = joblib.load('performance\_predictor\_model.joblib')
prediction = model.predict(\[\[cpu\_usage, disk\_io, query_time\]\])
return 'Issue' if prediction\[0\] == 1 else 'No issue'
# 示例:使用模型预测一个新的数据点
print(predict_performance(85, 90, 3))
03 Demostración de muestra
Escenario hipotético: usted es un experto en TI en una empresa de Internet de las cosas y descubre que el tiempo de respuesta de la consulta de la base de datos de series temporales para procesar datos de estado del dispositivo es muy lento en ciertos períodos.
recopilación de datos
La herramienta de diagnóstico de la base de datos que utiliza comienza a recopilar los siguientes datos:
1. Registro de consultas: se encuentra una consulta que aparece con frecuencia y el tiempo de ejecución es mucho más largo que otras consultas.
Plaintext
SELECT avg(temperature) FROM device_readings
WHERE device_id = ? AND time > now() - interval '1 hour'
GROUP BY time_bucket('5 minutes', time);Plaintext
2. Plan de ejecución: el plan de ejecución de esta consulta muestra que este SQL escaneará toda la tabla y luego filtrará el ID del dispositivo.
3. Uso del índice: el id_dispositivo en la tabla lecturas_dispositivos no tiene un índice TAG.
4. Uso de recursos: CPU y E/S alcanzan su punto máximo al ejecutar esta consulta.
5. Eventos de bloqueo y espera: no se encontraron eventos de bloqueo anormales.
Análisis y reconocimiento de patrones.
Las herramientas de diagnóstico analizan consultas y planes de ejecución para identificar los siguientes patrones:
- Los escaneos frecuentes de tablas completas provocan un aumento de las cargas de E/S y de CPU;
- Sin índices adecuados, las consultas no pueden localizar los datos de manera eficiente.
Diagnóstico de problemas
La herramienta utiliza reglas integradas que coinciden con el siguiente diagnóstico: La ineficiencia de las consultas se debe a la falta de índices adecuados.
Generación de sugerencias
Según este patrón, la herramienta de diagnóstico genera la siguiente recomendación: Cree un índice TAG en el campo device_id de la tabla device_readings.
Implementar recomendaciones
El administrador de la base de datos ejecuta la siguiente instrucción SQL para crear el índice:
SQL
ALTER TABLE device\_readings ADD TAG device\_id;
Resultados de la validación
Después de crear el índice, la herramienta de diagnóstico de la base de datos recopiló los datos nuevamente y descubrió:
- El tiempo de ejecución de esta consulta en particular se redujo significativamente;
- Las cargas de CPU y E/S caen a niveles normales durante la ejecución de consultas;
- El tiempo de carga de la página del catálogo de productos del sitio web ha vuelto a la normalidad.
Descripción del algoritmo
En este ejemplo, la herramienta de diagnóstico utiliza el siguiente algoritmo y lógica:
- Reconocimiento de patrones: detecta la frecuencia de las consultas y el tiempo de ejecución;
- Análisis de correlación: correlacione consultas de largo tiempo de ejecución con planes de ejecución y uso de índices;
- Árbol de decisión o motor de reglas: si se encuentra un escaneo completo de la tabla y el campo correspondiente no tiene un índice, se recomienda crear un índice;
- Monitoreo de cambios de desempeño: después de crear el índice, monitoree la mejora del desempeño para determinar la efectividad de las recomendaciones.