
01 Antecedentes de un vistazo
En el escenario donde se escriben datos de series de tiempo en la base de datos, debido a problemas como retrasos en la red, puede suceder que la marca de tiempo de los datos a escribir sea menor que la marca de tiempo máxima de los datos que se han escrito. Los datos se denominan colectivamente datos desordenados. La generación de datos desordenados es casi inevitable. Al mismo tiempo, la escritura de datos desordenados afectará la clasificación y consulta de todos los datos. Por lo tanto, debemos admitir la escritura de datos desordenados. ordenar datos y también respaldar bien la consulta de datos fuera de orden.
02 Descripción general del proceso
Al procesar datos desordenados, los datos desordenados dentro de un período de tiempo específico (como 10 minutos o 1 hora) se procesarán y almacenarán de acuerdo con la estrategia de deduplicación, y los datos desordenados fuera de ese tiempo. La ventana será descartada. La siguiente figura es el proceso básico de escribir datos desordenados:

Entre ellos, es necesario aclarar 3 puntos clave:
- La ventana de tiempo se refiere a un período de tiempo anterior al punto de tiempo de la última marca de tiempo de datos en la tabla. Cuando no se escriben datos nuevos en la tabla, su ventana de tiempo no cambiará.
- Hay un parámetro en el archivo de configuración: ts_st_iot_disorder_interval, que se utiliza para admitir la ventana de tiempo para escribir datos desordenados, unidad: segundos. El valor de este elemento de configuración no puede exceder el valor del intervalo de partición.
- La base para juzgar si los datos están desordenados es que la marca de tiempo de los datos escritos es menor o igual a la marca de tiempo máxima de todos los datos almacenados en el objeto de tabla escrita.
03 Ejemplo de escenario
1. Proceso de escritura normal
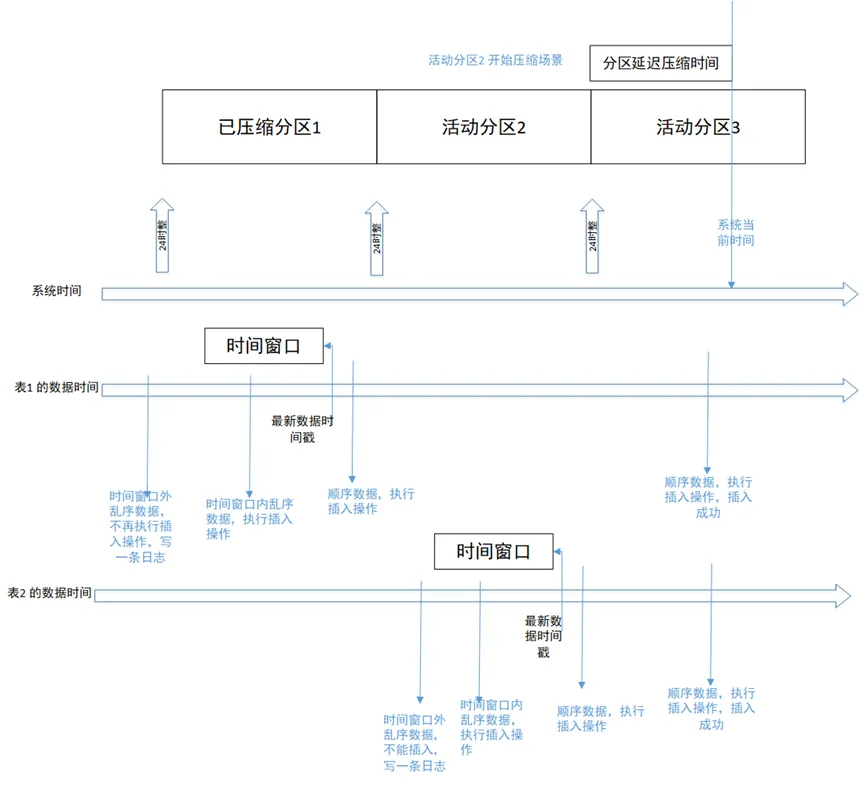
La hora se divide en dos líneas: hora del sistema y hora de los datos. La hora de los datos es diferente para cada tabla, por lo que se divide en dos líneas: la hora de los datos de la Tabla 1 y la hora de los datos de la Tabla 2.
-
Escenario 1: El escenario de escritura secuencial de datos hace dos días es como se muestra en la figura anterior. El escenario de la Tabla 1 escribiendo secuencialmente en la partición histórica 1. Los datos secuenciales escritos se almacenarán en la partición histórica correspondiente. la partición falla y arroja mal.
-
Escenario 2: Escritura de datos desordenados dentro de la ventana de tiempo Como se muestra en la figura anterior, la Tabla 2 escribe datos desordenados dentro de la ventana de tiempo. Los datos escritos se almacenarán en la partición activa 2, que se está procesando. en otro hilo, la compresión de la partición también tendrá éxito.
-
Escenario 3: Escritura de datos desordenados que exceden la ventana de tiempo Cuando la base de datos activa la función de compresión y configura la ventana de tiempo desordenada en 1 hora, se escriben datos desordenados que son 1 hora antes. que la marca de tiempo del último registro en la tabla fallará. Los datos escritos se filtrarán y se escribirán en el registro.
2. Proceso de importación de datos
También puede haber datos desordenados en los datos importados. En este escenario, el procesamiento de datos desordenados es consistente con el proceso de escritura normal.
-
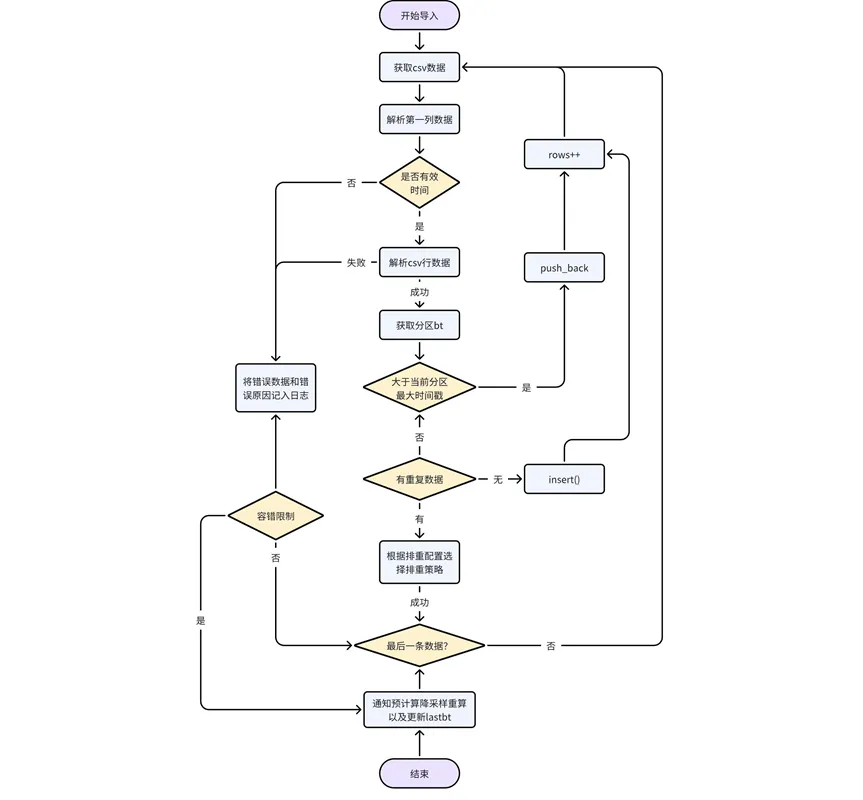
Procesamiento de los datos en sí: analiza los datos en el archivo CSV línea por línea, determina si la primera columna de datos es un tipo de hora/marca de tiempo válido y, en caso contrario, devuelve un error, si son datos de tiempo válidos, determina la partición; a la que pertenecen los datos y obtener la partición bt. Si la marca de tiempo de los datos es mayor que la marca de tiempo máxima de los datos existentes en la partición actual, retroceda directamente; de lo contrario, los datos desordenados deben procesarse de acuerdo con la lógica de configuración de deduplicación.
-
Adapte la lógica de reducción de resolución y cálculo previo: durante el proceso de importación de datos, debe actualizar el estado del registro de la URL en la tabla de tareas del sistema kaiwudb_jobs para que caduque después de que se complete la importación, notificar el cálculo previo o reducción de resolución, recalcular o procesar los datos involucrados; espere al siguiente paso. Una tarea de precálculo se vuelve a calcular cuando la programa el sistema.
Una vez completada la importación, se notifica el cálculo previo y la reducción de resolución para recalcular o actualizar los resultados y actualizar el último.
3. Proceso de reducción de resolución
Una vez escritos los datos desordenados, los resultados de la reducción de resolución deben actualizarse en función de los datos más recientes.

-
Procesamiento de datos desordenados importados en particiones históricas: al importar datos desordenados que pertenecen a particiones históricas, actualice el estado del registro de url=[base de datos/partición/nombre_tabla] en la tabla de tareas del sistema kaiwudb_jobs a caducado, y luego, la tabla de particiones se volverá a descargar en consecuencia.
-
Procese la inserción y escritura de datos de partición históricos: al descomprimir la partición histórica de la tabla de datos de inserción, actualice el estado del registro de url=[base de datos/partición/nombre_tabla] en la tabla de tareas del sistema kaiwudb_jobs a caducado, y la tabla de particiones volverá a ser correspondió en el futuro. Procesamiento de reglas de reducción de resolución.
4. Después de escribir los datos desordenados en el proceso de cálculo previo, los resultados del cálculo previo deben actualizarse en función de los datos más recientes.
-
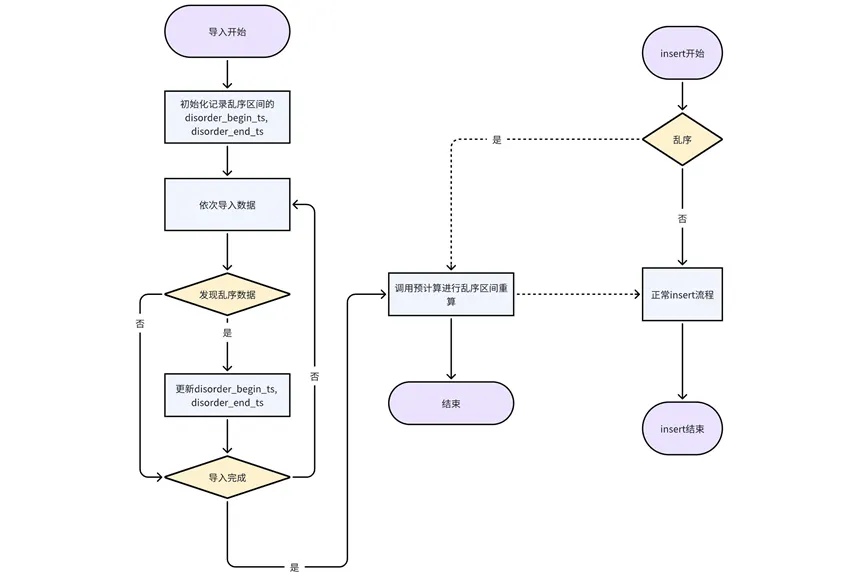
Procese la inserción y escriba datos desordenados: inserte cada vez que aparezca un dato desordenado en la inserción. Este método puede garantizar en mayor medida la precisión de los resultados del cálculo previo.
-
Procesamiento de datos desordenados importados: la importación se procesa actualmente en unidades de tablas de partición. Durante el proceso de importación de cada tabla de partición, se registran la marca de tiempo de inicio y la marca de tiempo de finalización desordenadas después de la importación actual. Una vez completada la tabla de particiones, se llama a la interfaz de precálculo para volver a calcularla.
04 Resumen
En el escenario de procesamiento de datos desordenado, hay muchas funciones y módulos de enlace involucrados que deben sincronizarse y actualizarse. Cuando la base de datos tiene un procesamiento de datos completamente desordenado, puede adaptarse mejor a los escenarios comerciales del usuario y mejorar en gran medida la aplicabilidad de la base de datos en múltiples escenarios.
Decidí renunciar al software industrial de código abierto. Eventos importantes: se lanzó OGG 1.0, Huawei contribuyó con todo el código fuente y se lanzó oficialmente Ubuntu 24.04. El equipo de la Fundación Google Python fue despedido por la "montaña de código de mierda" . ". Se lanzó oficialmente Fedora Linux 40. Una conocida compañía de juegos lanzó Nuevas regulaciones: los obsequios de boda de los empleados no deben exceder los 100.000 yuanes. China Unicom lanza la primera versión china Llama3 8B del mundo del modelo de código abierto. Pinduoduo es sentenciado a compensar 5 millones de yuanes por competencia desleal. Método de entrada en la nube nacional: solo Huawei no tiene problemas de seguridad para cargar datos en la nube.