Introducción a los antecedentes
Range (particionamiento) es una tecnología para la gestión de bases de datos y la organización de datos. En un sistema distribuido, podemos dividir los datos en múltiples rangos para organizarlos de acuerdo con ciertas reglas y lograr una gestión dinámica mediante la división y la fusión para optimizar el rendimiento de las consultas y ayudar a mejorar la escalabilidad y disponibilidad del sistema y el equilibrio de carga. El contenido principal de esta transmisión en vivo es: División y fusión de rango en el sistema distribuido KaiwuDB.
El siguiente es un extracto de parte del contenido. Para ver el contenido completo, haga clic para ver la versión completa >> Reproducción de video en versión completa.
División de rango KaiwuDB
Introducción a la división
splitQueue es responsable de la división del rango. Las condiciones que desencadenan la división del rango son las siguientes:
- Cree una nueva base de datos o tabla.
- El tamaño del rango excede range_max_bytes.
- El QPS de Range es demasiado alto y excede kv.range_split.load_qps_threshold (valor predeterminado 250, configurable).
- Modifique la zona Configurar del índice o partición para que sea independiente del nivel principal. En casos especiales, la división adminSplit se llamará directamente sin pasar por splitQueue.
- Al importar una gran cantidad de datos, un rango se divide automáticamente en varios rangos.
- Al importar datos, se divide previamente un rango en blanco para los datos que se pueden importar más adelante.
- División manual: modifique la división del nombre de la tabla en los valores (clave1, clave2,…); donde Valores representa el valor de la clave principal. Si es una clave principal conjunta, puede escribir varios valores y no puede exceder el número de. columnas de clave primaria.
Diagrama de flujo del algoritmo dividido
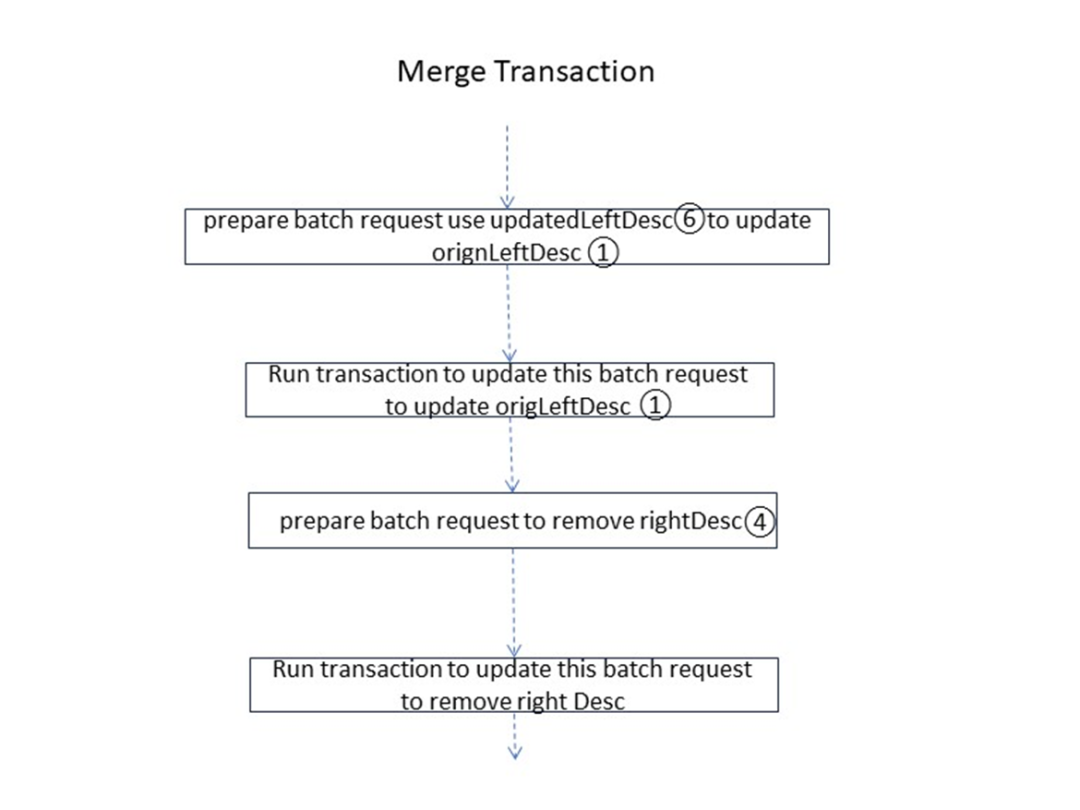
Cierto nodo en KaiwuDB tiene un hilo/trabajador separado que se ejecuta en segundo plano para manejar la división de rangos relacionados. La división del rango se divide en 2 fases: Fase 1: preparación de los parámetros de división del rango; Fase 2: actualización del rango y su estructura de índice;

Como se muestra en la figura, el proceso de la izquierda es principalmente la preparación para dividir el Rango:
Primero bloquee el valor clave de la clave del rango dividido. Después de encontrar este valor clave, el sistema ajustará el rango actual y utilizará el valor de la clave dividida como valor de la clave final de la partición.
El proceso creará un nuevo Rango para la derecha, su valor de clave inicial es el valor de clave utilizado para dividir y su valor de clave final es el valor de clave final del Rango original. Al mismo tiempo, después de dividir el Rango original, su versión se actualizará iterativamente en 1 y la versión actualizada se aplicará a los Rangos divididos izquierdo y derecho al mismo tiempo.
Cuando los parámetros divididos en los lados izquierdo y derecho del Rango están listos, el proceso ingresa a la fase de actualización de datos del sistema. En resumen, es necesario preparar solicitudes de escritura y procesar solicitudes. Este proceso está asociado con una transacción y todo. La transacción debe completar los siguientes asuntos:
Iniciar una nueva transacción, el estado está pendiente
- Actualizar rango izquierdo
- Escribir nuevo rango derecho
- Actualice la ruta de búsqueda correspondiente de la estructura de árbol de dos niveles del índice Big Mac en el rango izquierdo
- Inserte la ruta de búsqueda correspondiente de la estructura de árbol de dos niveles del índice Big Mac en el rango derecho
- El estado de la transacción de actualización es Comprometido.
- Actualice el MVCC del rango izquierdo y derecho
- Limpiar la intención de escritura
En este punto, se completa la división de todo el Rango.
Ejemplo de disparador dividido
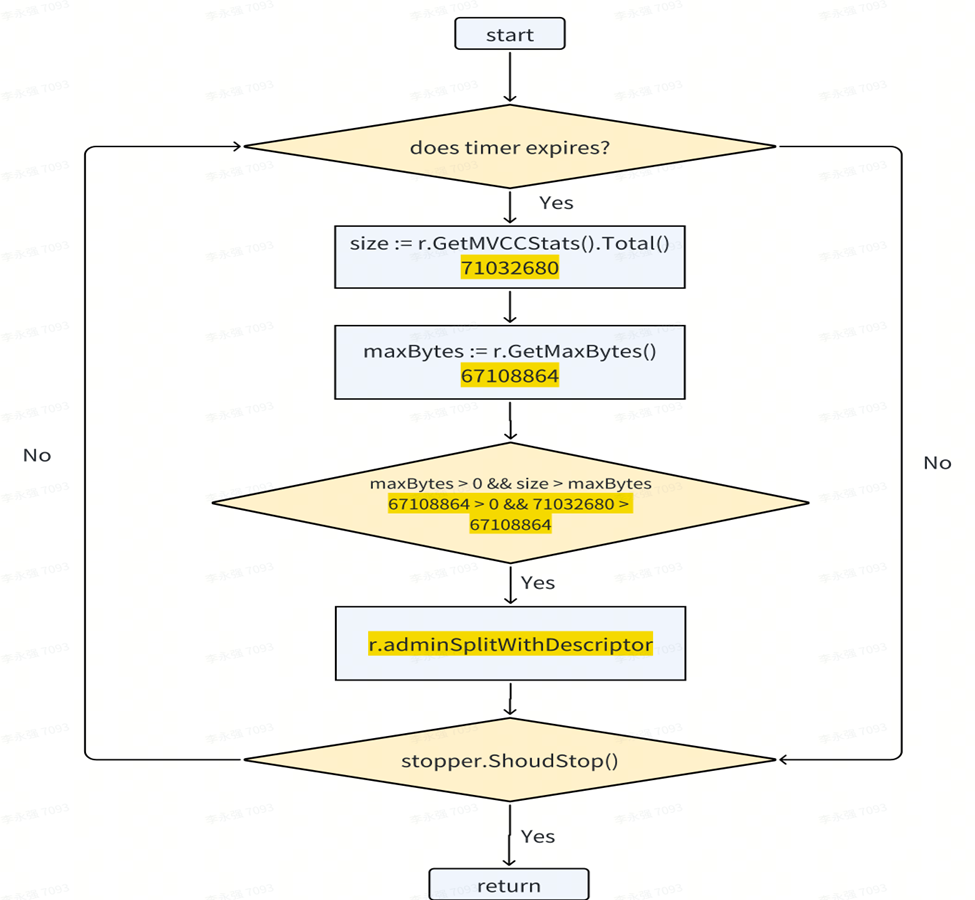
El siguiente escenario de activación de depuración ocurre después de que el tamaño del rango excede un valor crítico predeterminado. Cada rango se procesa en forma de temporizador de espera en serie. Después de que el reloj se active, se verificará el tamaño del rango. Si se encuentra que el tamaño del rango es de alrededor de 70 MB y excede el rango predeterminado de 64 M, el sistema activará la función de rango dividido para dividir el rango que excede el límite de capacidad.
El hilo o trabajador en segundo plano comprobará continuamente todos los rangos para su procesamiento en un bucle.
Fusión de rango KaiwuDB (Fusionar)
Ejemplo de fusión
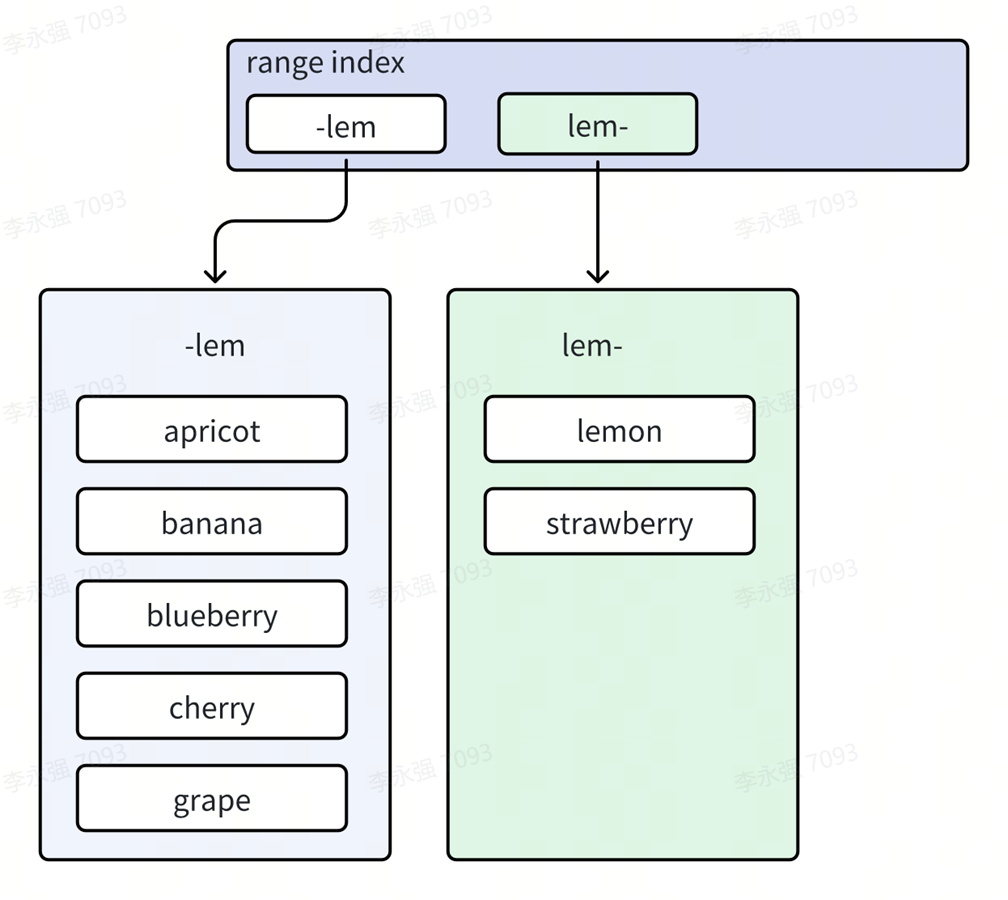
Como se muestra en la figura, cuando el usuario elimina una gran cantidad de datos, el tamaño de los dos rangos adyacentes disminuye drásticamente y el sistema los fusiona.

La siguiente figura muestra el efecto después de la fusión. Después de los dos rangos anteriores: lem-str, str- se fusionaron, str- desapareció, dejando solo lem-. Los valores clave de los dos rangos originales se fusionaron en el mismo rango lem. . En consecuencia, la estructura de datos de segundo nivel del índice Big Mac también se ha ajustado y el guisante en la estructura del índice de árbol de primer nivel ha desaparecido.
Condiciones de fusión
Las condiciones para fusionar rangos son relativamente estrictas e incluyen principalmente: La fusión no está deshabilitada Hay un siguiente rango y la misma zona de configuración El tamaño de los dos rangos que se fusionarán es menor que range_min_bytes La división del rango de QPS no se activará después de la fusión
El último significa que si el rango donde se encuentran los datos tiene datos activos, la fusión no se realizará, porque la fusión desencadenará una división, lo que hará que el sistema no funcione normalmente.
Diagrama de flujo del algoritmo de fusión
Como se muestra en la figura, la fusión, al igual que la división, también se divide en dos etapas: la primera etapa, preparación de parámetros de rango, y la segunda etapa, que habilita transacciones para el procesamiento de actualización de rango. Para ver el contenido completo, haga clic para ver el contenido de la versión completa >> [Reproducción de video de la versión completa] ( https://www.bilibili.com/video/BV11y421z7jH/?spm_id_from=333.999.0.0 )
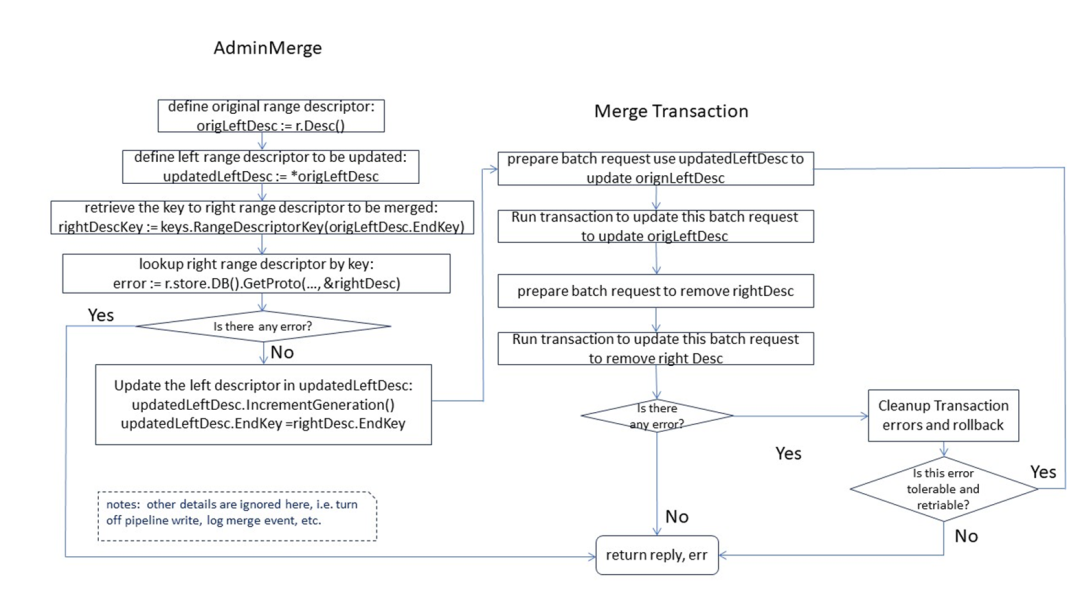
Ejemplo de depuración de fusión Los siguientes dos diagramas esquemáticos muestran el proceso específico de depuración de la fusión de rango y los parámetros relacionados con el rango correspondiente.