
escribir delante
Este artículo presenta principalmente el artículo "Kepler: aprendizaje robusto para una optimización de consultas paramétricas más rápida" publicado en SIGMOD en 2023. Este artículo combina la optimización de consultas parametrizadas y la optimización de consultas para consultas parametrizadas, con el objetivo de reducir el tiempo de planificación de consultas y al mismo tiempo mejorar el rendimiento de las consultas.
Con este fin, el autor propone un método de optimización de consultas paramétricas basado en el aprendizaje profundo de un extremo a otro llamado Kepler (K-plan Evolution for Parametric Query Optimization: Learned, Empirical, Robust).
La consulta numérica se refiere a un tipo de consulta que tiene la misma estructura SQL y solo difiere en los valores de los parámetros vinculados. Como ejemplo, considere la siguiente estructura de consulta:
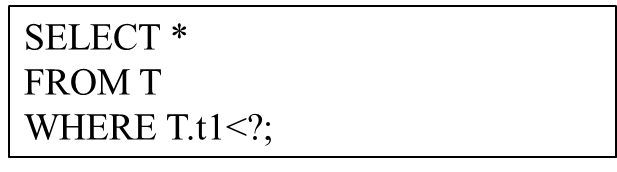
La estructura de la consulta puede considerarse como una plantilla de una consulta parametrizada y el "?" representa diferentes valores de parámetros. Todas las declaraciones SQL ejecutadas por el usuario tienen esta estructura de consulta, pero los valores de los parámetros reales pueden ser diferentes. Esta es una consulta parametrizada. Estas consultas parametrizadas se utilizan con mucha frecuencia en las bases de datos modernas. Debido a que ejecuta continuamente la misma plantilla de consulta repetidamente, brinda oportunidades para mejorar el rendimiento de la consulta.
La optimización de consultas parametrizadas (PQO) se utiliza para optimizar el rendimiento de las consultas parametrizadas mencionadas anteriormente. El objetivo es reducir el tiempo de planificación de consultas tanto como sea posible evitando la regresión del rendimiento. Los enfoques existentes dependen demasiado del optimizador de consultas integrado en el sistema, lo que los hace sujetos a la suboptimidad inherente del optimizador. El autor cree que el sistema ideal para consultas parametrizadas no solo debería reducir el tiempo de planificación de consultas mediante PQO, sino también mejorar el rendimiento de ejecución de consultas del sistema mediante la optimización de consultas (QO).
La optimización de consultas (QO) se utiliza para ayudar a que una consulta encuentre su plan de ejecución óptimo. La mayoría de los métodos existentes para mejorar la optimización de consultas aplican el aprendizaje automático, como los estimadores de cardinalidad/costos basados en el aprendizaje automático. Sin embargo, el método actual de optimización de consultas basado en el aprendizaje tiene algunas deficiencias: (1) el tiempo de inferencia es demasiado largo (2) la capacidad de generalización es deficiente (3) la mejora del rendimiento no es clara; y el rendimiento puede volver a disminuir.
Las deficiencias anteriores plantean desafíos para los métodos basados en el aprendizaje, ya que no pueden garantizar la mejora en el tiempo de ejecución de los resultados de la predicción. Para resolver los problemas anteriores, el autor propone Kepler: un método de optimización de consultas parametrizadas basado en el aprendizaje de un extremo a otro.
Los autores desacoplan la optimización de consultas paramétricas en dos problemas: generación de planes candidatos y estructuras de predicción basadas en el aprendizaje. Se divide principalmente en tres pasos: generación de planes de candidatos novedosos, recopilación de datos de entrenamiento y diseño de modelos de redes neuronales robustos. La combinación de los tres reduce el tiempo de planificación de consultas al tiempo que mejora el rendimiento de la ejecución de consultas y cumple con los objetivos de PQO y QO. A continuación, primero presentamos la arquitectura general de Kepler y luego explicamos en detalle el contenido específico de cada módulo.
Arquitectura general
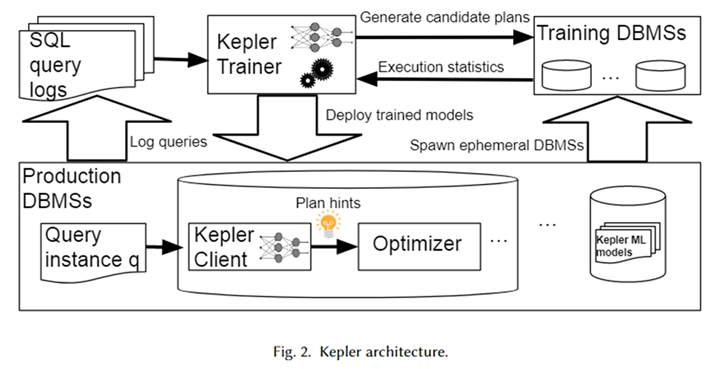
La arquitectura general de Kepler se muestra en la figura anterior. Primero, obtenga la plantilla de consulta parametrizada y la instancia de consulta correspondiente (es decir, la consulta con valores de parámetros reales) del registro del sistema de la base de datos para formar una carga de trabajo. Kepler Trainer se utiliza para entrenar un modelo predictivo de red neuronal para esta carga de trabajo. Primero genera planes candidatos para toda la carga de trabajo y los ejecuta en un sistema de base de datos temporal para obtener el tiempo real de ejecución de la consulta.
Utilice este tiempo de consulta para entrenar un modelo de red neuronal. Una vez completada la capacitación, se implementa en el sistema de base de datos en el entorno de producción, llamado Kepler Client. Cuando el usuario ingresa una instancia de consulta, Kepler Client puede predecir el mejor plan de ejecución para ella y entregárselo al optimizador en forma de sugerencia de plan para generar y ejecutar el mejor plan.
Generación de plan candidato: evolución del recuento de filas
El objetivo de la generación de planes candidatos es construir un conjunto de planes que contenga un plan de ejecución casi óptimo para cada instancia de consulta en la carga de trabajo. Además, debe ser lo más pequeño posible para evitar una sobrecarga excesiva en el proceso posterior de recopilación de datos de entrenamiento. Los dos se limitan entre sí, y cómo equilibrar estos dos objetivos es un desafío importante en la generación de planes candidatos.
La ecuación 1 formula objetivos específicos de generación de planes. Entre ellos, se encuentra una instancia de consulta en la carga de trabajo W, es el plan de ejecución seleccionado por el optimizador, es el plan óptimo en el plan establecido en circunstancias ideales y ExecTime es el tiempo de ejecución del plan correspondiente en la instancia. Por lo tanto, la connotación de la Ecuación 1 es la aceleración en el tiempo de ejecución del conjunto de planes candidatos en comparación con el conjunto de planes generado por el optimizador durante toda la carga de trabajo. El algoritmo está diseñado para maximizar esta aceleración.
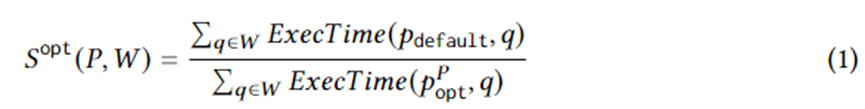
Con este fin, este artículo propone Row Count Evolution (RCE), un algoritmo que genera nuevos planes perturbando aleatoriamente la estimación de cardinalidad del optimizador. Genera una serie de planes para cada instancia de consulta, combinados en un conjunto de planes candidatos para toda la carga de trabajo. La idea detrás de este algoritmo es que la estimación incorrecta de la base es la razón principal de la suboptimidad del optimizador. Al mismo tiempo, la etapa de generación del plan candidato no necesita encontrar un plan único (casi) óptimo específico para cada instancia de consulta, sino que solo necesita incluir el plan (casi) óptimo.
El algoritmo RCE genera continuamente nuevos planes mediante iteración. Primero, el plan de iteración inicial es el plan generado por el optimizador. Para construir iteraciones posteriores, primero se requiere un muestreo aleatorio uniforme del plan de generación anterior. Para cada plan muestreado, altere (cambie) la cardinalidad de su subplan de unión.
El método de perturbación consiste en muestrear aleatoriamente dentro del intervalo exponencial de su cardinalidad estimada actual. La cardinalidad perturbada se entrega al optimizador para generar el plan óptimo correspondiente. Repita cada plan N veces para generar muchos planes de ejecución, entre los cuales los planes de ejecución que no han aparecido se conservan como el plan de próxima generación y se repite el proceso anterior.
Damos un ejemplo específico para ilustrar visualmente el algoritmo anterior, como se muestra en la siguiente figura. En primer lugar, el Plan Base es el mejor plan seleccionado por el optimizador. Tiene dos subplanes de unión, A une B y C une D. Sus bases estimadas son 40 y 17 respectivamente.
A continuación, se generan conjuntos de perturbaciones para los dos subplanos de unión del rango de intervalo exponencial 10-1~101, que son [4,40,400] y [1,17,170] respectivamente. Se toman muestras aleatorias del conjunto de perturbaciones y se entregan al optimizador para la selección del plan. El plan 1 es el nuevo plan seleccionado por el optimizador cuando la cardinalidad es 400 y 17 respectivamente. Repetidos N veces, los planes C1 finalmente se generan como la próxima generación. A continuación, tome una muestra de los planes S y repita el proceso anterior para cada plan para formar el plan de segunda generación.
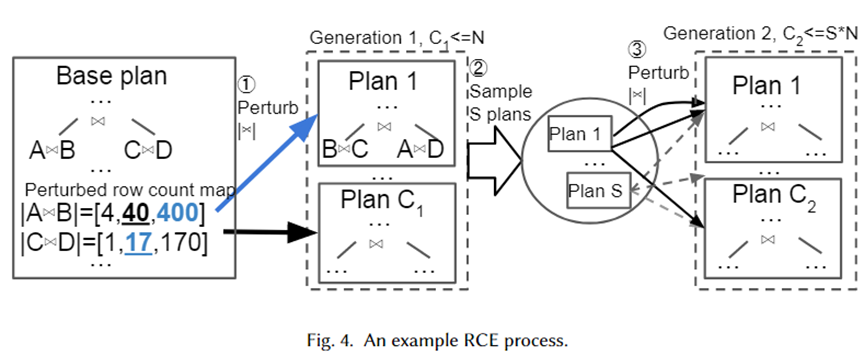
La razón por la que los autores adoptaron un rango de intervalo exponencial como conjunto de perturbaciones es para ajustar la distribución del error de estimación de cardinalidad del optimizador. Del algoritmo anterior se puede ver que siempre que el número de perturbaciones sea lo suficientemente grande, se generarán muchas cardinalidades y sus planes correspondientes. De esta manera, cuando llega una instancia de consulta, debe haber un plan en nuestro conjunto de planes que esté cerca de la cardinalidad verdadera, que puede considerarse como el plan (casi) óptimo para la instancia.
Recopilación de datos de entrenamiento
Después de generar el conjunto de planes candidatos, cada plan se ejecuta en la carga de trabajo y se generan datos del tiempo de ejecución para la predicción del plan óptimo supervisado. El uso de datos de ejecución reales en lugar del costo estimado por el optimizador puede evitar las limitaciones causadas por la suboptimidad del optimizador. El proceso de ejecución es paralelizable. Sin embargo, ejecutar todos los planes supone un gasto importante. Por lo tanto, los autores proponen dos estrategias para reducir el desperdicio de recursos causado por una ejecución innecesaria y subóptima del plan.
Tiempos de espera adaptativos y reordenamiento de ejecución del plan, tiempos de espera adaptativos y reordenamiento de ejecución del plan. Los autores emplean un mecanismo de tiempo de espera para limitar la ejecución de planes subóptimos. Para cada instancia de consulta, al ejecutar cada plan, se puede registrar el tiempo mínimo de ejecución actual.
Una vez que el tiempo de ejecución de un plan excede un cierto rango del tiempo mínimo de ejecución, ya no se puede ejecutar porque definitivamente no es el plan de ejecución óptimo. Al mismo tiempo, el tiempo mínimo de ejecución se actualiza constantemente. Además, la ejecución de planes de consulta en orden ascendente de tiempo de ejecución en función de la ejecución de cada plan en otras instancias de consulta se puede utilizar como heurística para acelerar el mecanismo de tiempo de espera.
Plan online que cubre poda, poda de conjunto de planes online. Una vez que se han ejecutado todos los planes para las primeras N instancias de consulta, se recortan en K planes mediante el problema Establecer cobertura. La recopilación de datos posterior y el entrenamiento del modelo utilizan estos planes K. El problema de Establecer cobertura se define como se muestra a continuación.
En el contexto de este artículo, representa todas las instancias de consulta, que se pueden representar como planes diferentes, siendo cada plan un plan casi óptimo para alguna instancia de consulta. Por lo tanto, el problema se puede formular utilizando el conjunto de planes más pequeño posible para proporcionar una optimización casi óptima para todas las instancias de consulta. El problema es NP, por lo que el autor utiliza un algoritmo codicioso para resolverlo.

Predicción sólida del mejor plan
Después de recopilar datos de entrenamiento sobre el tiempo de ejecución real del conjunto de planes candidatos, se utiliza el aprendizaje automático supervisado para predecir el mejor plan para cualquier instancia de consulta. El objetivo del entrenamiento se puede expresar lógicamente mediante la siguiente ecuación. donde representa el mejor plan elegido por el modelo para la instancia de consulta. El significado de esta ecuación es la aceleración resultante del plan elegido por el modelo respecto al plan elegido por el optimizador. Su límite superior es la Ecuación 1. En otras palabras, el modelo debería capturar en la mayor medida posible la aceleración aportada por los planes candidatos generados por RCE.
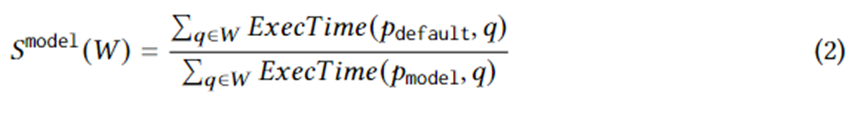
La estructura del modelo adopta una red neuronal directa y aplica los últimos avances en la incertidumbre del aprendizaje automático, a saber, los procesos neuronales gaussianos normalizados espectralmente (SNGP). Combinarlo en la red neuronal puede mejorar la convergencia del modelo y al mismo tiempo permitir que la red neuronal genere la incertidumbre de la predicción. Cuando la incertidumbre es superior a un umbral, el trabajo de predicción del plan se devuelve al optimizador, que determina el mejor plan.
El modelo se caracteriza utilizando los valores reales de cada parámetro. Para ingresar los valores reales de los parámetros en la red neuronal, se requiere algún procesamiento previo, especialmente para datos de tipo cadena. Para datos de tipo cadena, el autor utiliza un vocabulario de tamaño fijo y depósitos que no están en el vocabulario para representarlos como un vector one-hot, y agrega una capa de incrustación para aprender la incrustación del vector one-hot y luego capaz de manejar datos de tipo cadena.
efecto experimental
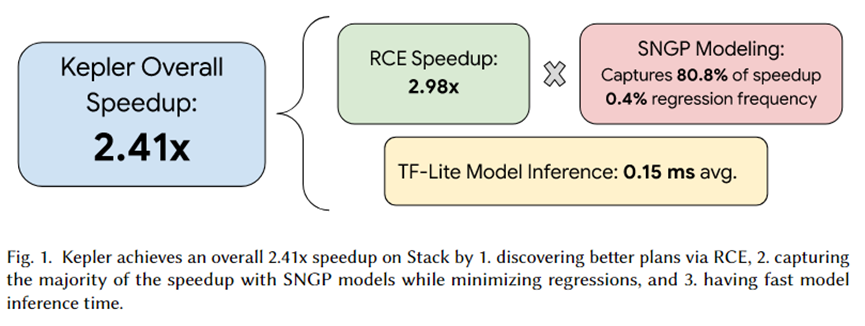
El autor de este artículo integró Kepler en PostgreSQL y organizó una serie de experimentos. El resumen del experimento se muestra en la figura anterior. El efecto de aceleración total provocado por Kepler es 2,41 veces. Entre ellos, el conjunto de planes candidatos generado por RCE puede generar una aceleración de aproximadamente 2,92 veces, el modelo de predicción SNGP captura el 80,8% y solo se logra el 0,4% de la regresión. Además, el tiempo de inferencia del modelo es de sólo 0,15 ms en promedio.
Resumir
Este artículo propone Kepler, un enfoque basado en el aprendizaje que acelera de manera sólida las consultas parametrizadas. Genera un plan candidato establecido a través del algoritmo Row Count Evolution (RCE), lo ejecuta en la carga de trabajo para obtener el tiempo de ejecución real y utiliza el tiempo de ejecución real para entrenar el modelo de predicción.
El modelo de predicción adopta procesos neuronales gaussianos normalizados espectralmente (SNGP), el último avance en la estimación de la incertidumbre del aprendizaje automático, para mejorar la convergencia y al mismo tiempo generar la incertidumbre de la predicción. En función de esta incertidumbre, se selecciona si el modelo o el optimizador completan la predicción. predicción del plan. Los experimentos han demostrado que RCE puede generar efectos de alta aceleración, y SNGP puede capturar los efectos de aceleración generados por RCE tanto como sea posible evitando la regresión. Por lo tanto, los objetivos de PQO y QO se logran al mismo tiempo, es decir, al tiempo que se reduce el tiempo de planificación de consultas, se mejora el rendimiento de la ejecución de consultas.
Decidí renunciar al software industrial de código abierto. Eventos importantes: se lanzó OGG 1.0, Huawei contribuyó con todo el código fuente y se lanzó oficialmente Ubuntu 24.04. El equipo de la Fundación Google Python fue despedido por la "montaña de código de mierda" . ". Se lanzó oficialmente Fedora Linux 40. Una conocida compañía de juegos lanzó Nuevas regulaciones: los obsequios de boda de los empleados no deben exceder los 100.000 yuanes. China Unicom lanza la primera versión china Llama3 8B del mundo del modelo de código abierto. Pinduoduo es sentenciado a compensar 5 millones de yuanes por competencia desleal. Método de entrada en la nube nacional: solo Huawei no tiene problemas de seguridad para cargar datos en la nube.