
1. Introducción a los antecedentes
Las consultas parametrizadas se refieren a un tipo de consulta que tiene la misma plantilla y solo difiere en los valores de los parámetros de enlace de predicados. Se utilizan ampliamente en aplicaciones de bases de datos modernas. Realizan acciones repetidamente, lo que brinda oportunidades para optimizar el rendimiento.
Sin embargo, el método actual de manejo de consultas parametrizadas en muchas bases de datos comerciales solo optimiza la primera instancia de consulta (o instancia especificada por el usuario) en la consulta, almacena en caché su mejor plan y lo reutiliza para instancias de consulta posteriores. Aunque este método optimiza el tiempo para minimizarlo, debido a diferentes planes óptimos para diferentes instancias de consulta, la ejecución del plan almacenado en caché puede ser arbitrariamente subóptima, lo que no es aplicable en escenarios de aplicaciones reales.
La mayoría de los métodos de optimización tradicionales requieren muchas suposiciones sobre el optimizador de consultas, pero estas suposiciones a menudo no coinciden con los escenarios de aplicación reales. Afortunadamente, con el auge del aprendizaje automático, los problemas anteriores se pueden resolver de forma eficaz. Este número presentará en detalle dos artículos publicados en VLDB2022 y SIGMOD2023:
Tema 1: "Aprovechamiento de los registros de consultas y el aprendizaje automático para la optimización de consultas paramétricas"
Tema 2: "Kepler: aprendizaje sólido para una optimización de consultas paramétricas más rápida"
2. Esencia del artículo 1
"Aprovechamiento de los registros de consultas y el aprendizaje automático para la optimización de consultas paramétricas" Este documento desacopla la optimización de consultas paramétricas en dos problemas:
(1) PopulateCache: almacena en caché K planes para una plantilla de consulta
(2) getPlan: para cada instancia de consulta, selecciona el mejor plan; los planes almacenados en caché.
La arquitectura del algoritmo de este artículo se muestra en la siguiente figura. Se divide principalmente en dos módulos: PopulateCache y módulo getPlan.
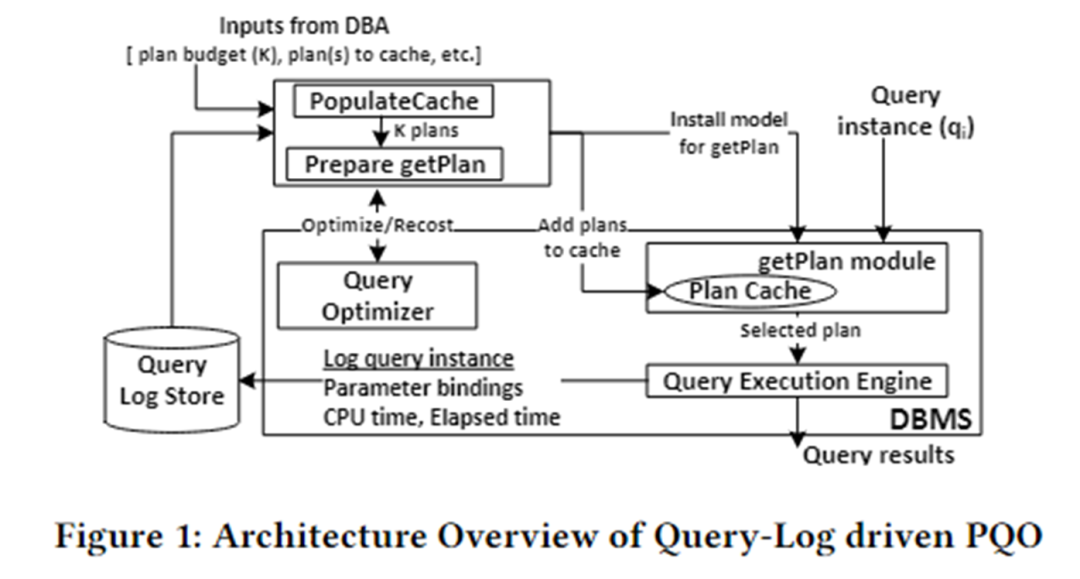
PopulateCache utiliza la información del registro de consultas para almacenar en caché los planes K para todas las instancias de consulta. El módulo getPlan primero recopila información de costos entre los planes K y las instancias de consulta interactuando con el optimizador y utiliza esta información para entrenar el modelo de aprendizaje automático. Implemente el modelo entrenado en el DBMS. Cuando llega una instancia de consulta, se puede predecir rápidamente el mejor plan para esa instancia.
Poblar caché
El módulo PolulateCache es responsable de identificar un conjunto de planes de caché para una consulta parametrizada determinada. La fase de búsqueda utiliza dos API optimizadoras:
- Llamada del optimizador: devuelve el plan seleccionado por el optimizador para una instancia de consulta;
- Llamada de nuevo costo: devuelve el costo estimado por el optimizador para una instancia de consulta y el plan correspondiente;
El flujo del algoritmo es el siguiente:
- Fase de recopilación de planes: llame al optimizador para recopilar planes candidatos para n instancias de consulta en el registro de consultas;
- Fase de plan-recosto: para cada instancia de consulta y cada plan candidato, llame a la llamada de recosto para formar una matriz de plan-recosto;
- Fase de identificación del conjunto K: adopta un algoritmo codicioso y utiliza la matriz de costo del plan para almacenar en caché los planes K para minimizar la subóptima.
obtenerPlan
El módulo getPlan es responsable de seleccionar uno de los K planes almacenados en caché para su ejecución para una instancia de consulta determinada. El algoritmo getPlan puede considerar dos objetivos: minimizar el costo estimado por el optimizador o minimizar el costo de ejecución real entre los planes de caché K.
Considere el objetivo 1: utilizar la matriz plan-recostos para entrenar un modelo de aprendizaje automático supervisado y considerar la clasificación y la regresión.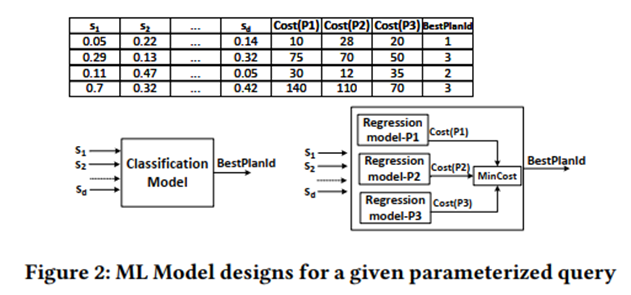
Considere el objetivo 2: utilizar el modelo de entrenamiento de aprendizaje por refuerzo basado en Multi-Armed Bandit.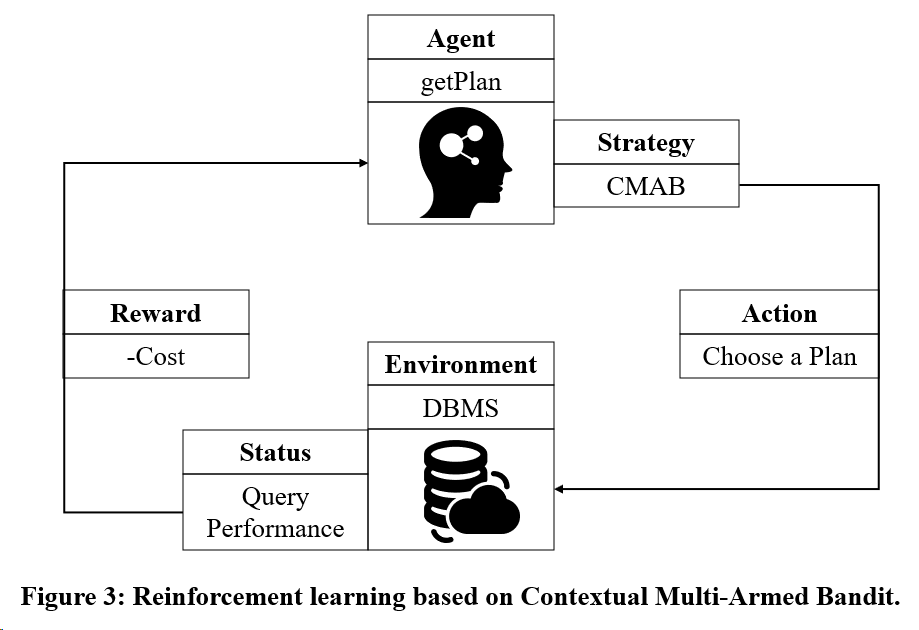
3. Esencia del artículo 2
"Kepler: aprendizaje sólido para una optimización de consultas paramétricas más rápida" Este artículo propone un método de optimización de consultas paramétricas basado en el aprendizaje de un extremo a otro, cuyo objetivo es reducir el tiempo de optimización de consultas y mejorar el rendimiento de ejecución de consultas.
La arquitectura del algoritmo es la siguiente. Kepler también desacopla el problema en dos partes: generación de planes y predicción de planes basada en el aprendizaje. Se divide principalmente en tres etapas: estrategia de generación de planes, fase de ejecución de consultas de entrenamiento y modelo de red neuronal robusto.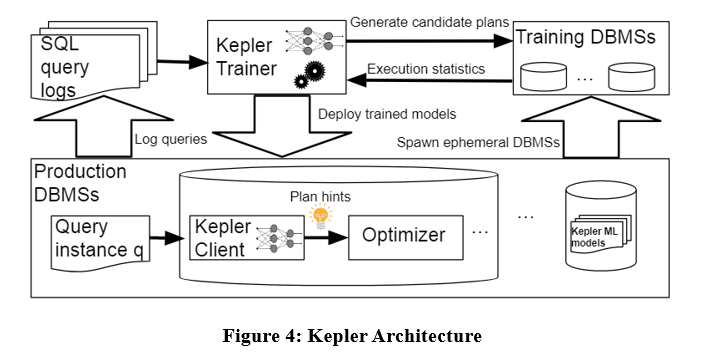
Como se muestra en la figura anterior, ingrese la instancia de consulta en el registro de consultas en Kepler Trainer. Kepler Trainer primero genera un plan candidato y luego recopila información de ejecución relacionada con el plan candidato como datos de entrenamiento para entrenar el modelo de aprendizaje automático. El modelo se implementa en el DBMS. Cuando llega una instancia de consulta, se utiliza Kepler Client para predecir el mejor plan y ejecutarlo.
Evolución del recuento de filas
Este artículo propone un algoritmo de generación de planes candidatos llamado Row Count Evolution (RCE), que genera planes candidatos perturbando la estimación de cardinalidad del optimizador.
La idea de este algoritmo proviene de: la estimación incorrecta de la cardinalidad es la causa principal de la suboptimidad del optimizador, y la etapa de generación del plan candidato solo necesita contener el plan óptimo de una instancia, en lugar de seleccionar un único plan óptimo.
El algoritmo RCE primero genera el plan óptimo para la instancia de consulta, luego perturba la cardinalidad de unión de sus subplanes dentro del rango de intervalo exponencial, lo repite varias veces y realiza múltiples iteraciones y, finalmente, utiliza todos los planes generados como planes candidatos. Los ejemplos específicos son los siguientes: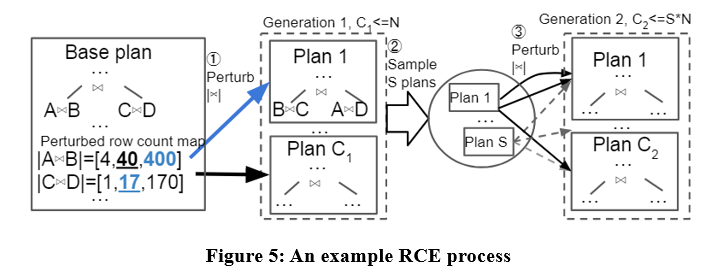
Con el algoritmo RCE, los planes candidatos generados pueden ser mejores que el plan producido por el optimizador. Debido a que el optimizador puede tener errores de estimación de cardinalidad, RCE puede producir el plan óptimo correspondiente a la cardinalidad correcta perturbando continuamente la estimación de cardinalidad.
Recopilación de datos de entrenamiento
Después de obtener el conjunto de planes candidatos, cada plan se ejecuta en la carga de trabajo para cada instancia de consulta y se recopila el tiempo de ejecución real para entrenar el modelo de predicción del plan óptimo supervisado. El proceso anterior es relativamente engorroso. Este artículo propone algunos mecanismos para acelerar la recopilación de datos de entrenamiento, como la ejecución paralela, el mecanismo de tiempo de espera adaptativo, etc.
Predicción sólida del mejor plan
Los datos de ejecución reales resultantes se utilizan para entrenar una red neuronal para predecir el plan óptimo para cada instancia de consulta. La red neuronal utilizada es un proceso neuronal gaussiano espectral normalizado. Este modelo garantiza la estabilidad de la red y la convergencia del entrenamiento, y puede proporcionar estimaciones de incertidumbre para las predicciones. Cuando la estimación de incertidumbre es mayor que un cierto umbral, le corresponde al optimizador seleccionar un plan de ejecución. Se evita hasta cierto punto la regresión del rendimiento.
4. Resumen
Los dos artículos anteriores desacoplan las consultas parametrizadas en populateCache y getPlan. La comparación entre los dos se muestra en la siguiente tabla.
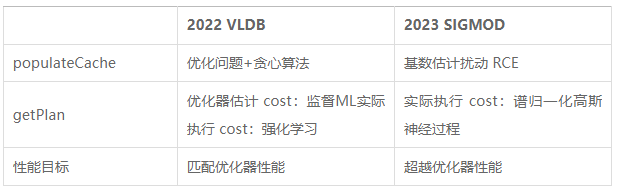
Aunque los algoritmos basados en modelos de aprendizaje automático funcionan bien en la predicción de planes, su proceso de recopilación de datos de entrenamiento es costoso y los modelos no son fáciles de generalizar y actualizar. Por lo tanto, los métodos de optimización de consultas parametrizadas existentes todavía tienen margen de mejora.
本文图示来源: 1)Kapil Vaidya y Anshuman Dutt, 《Aprovechamiento de registros de consultas y aprendizaje automático para la optimización de consultas paramétricas》, 2022 VLDB, https://dl.acm.org/doi/pdf/10.14778/3494124.3494126 2)LYRIC DOSHI & VINCENT ZHUANG, "Kepler: aprendizaje sólido para una optimización más rápida de consultas paramétricas", 2023 SIGMOD, https://dl.acm.org/doi/pdf/10.1145/3588963
Decidí renunciar al software industrial de código abierto. Eventos importantes: se lanzó OGG 1.0, Huawei contribuyó con todo el código fuente y se lanzó oficialmente Ubuntu 24.04. El equipo de la Fundación Google Python fue despedido por la "montaña de código de mierda" . ". Se lanzó oficialmente Fedora Linux 40. Una conocida compañía de juegos lanzó Nuevas regulaciones: los obsequios de boda de los empleados no deben exceder los 100.000 yuanes. China Unicom lanza la primera versión china Llama3 8B del mundo del modelo de código abierto. Pinduoduo es sentenciado a compensar 5 millones de yuanes por competencia desleal. Método de entrada en la nube nacional: solo Huawei no tiene problemas de seguridad para cargar datos en la nube.