

-
La lógica de usar el caché es muy general. Básicamente, primero se verifica el caché y, si hay alguno, se devuelve directamente sin verificar la base de datos y luego se coloca en el caché. Esta lógica general está dispersa por todo el sistema, violando el principio de alta cohesión y bajo acoplamiento. -
El código de almacenamiento en caché y el código de lógica empresarial están profundamente acoplados, lo que no solo reduce la legibilidad del código, sino que también aumenta la complejidad del sistema. -
Si desea cambiar el caché (MDB->LDB) o actualizar la API, es necesario cambiar todos los códigos involucrados. -
Si desea resolver problemas comunes como la penetración de caché, la penetración de caché, la caché en cascada, etc., debe resolverlos a través del marco.

Lea los datos del caché primero y regrese directamente si hay datos. Si no se leen datos, lea los datos de la base de datos y luego actualice el caché después de que se devuelvan los datos.
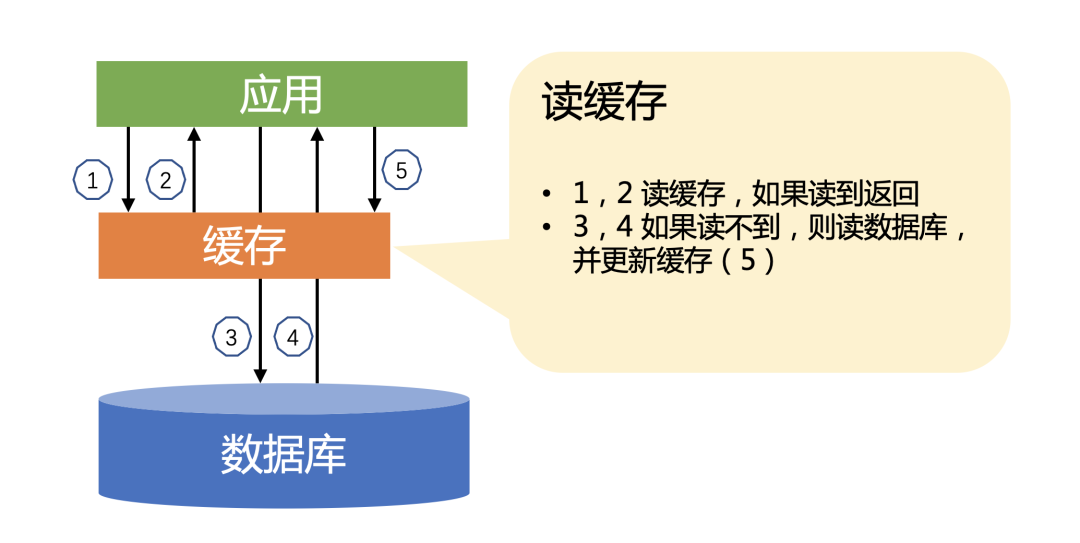
Este escenario es muy común en la codificación diaria y es demasiado simple, pero el código real es muy diferente. Aquí hay algunos ejemplos:
▐Escritura tradicional
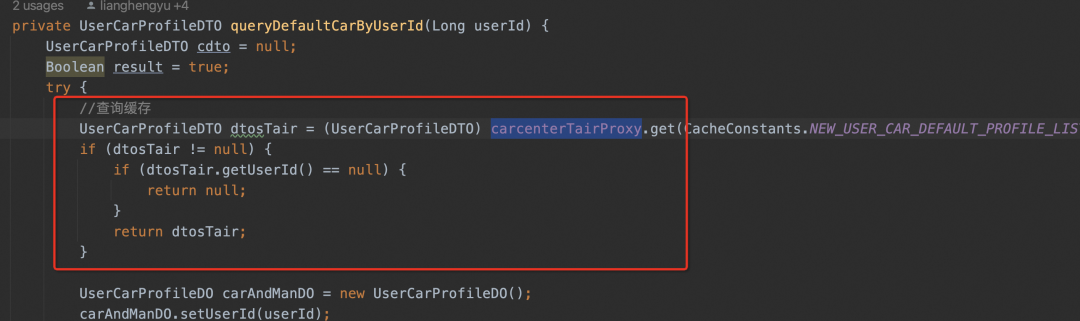
Cualquiera que sea el caché que se utilice, úselo directamente e incorpórelo en el código comercial. Este tipo de código es algo que no quiero ver, ya sea para revisar el código o cuando las generaciones futuras aprendan el código comercial. La razón es muy simple y no tiene nada que ver con las funciones comerciales reales. No quiero saber qué caché. usas o cómo codificas el código de caché.

▐Una forma más avanzada de escribir
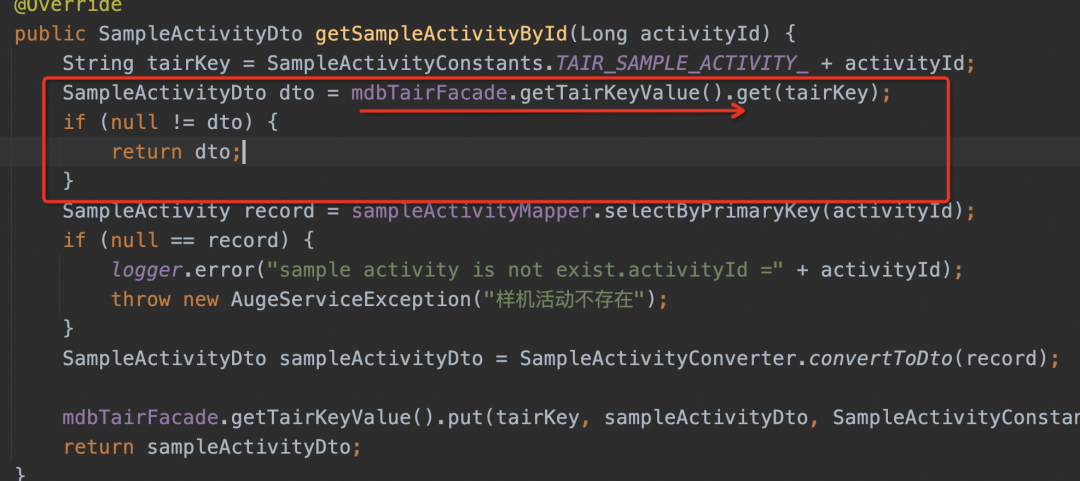
En comparación con el método de escritura tradicional, para resolver el problema del almacenamiento en caché de varios formatos de datos (lista, mapa, etc.) y la serialización de varios objetos (java, json), el equipo puede encapsular el almacenamiento en caché en una API simple para que todos la usen. . Es más fácil de usar, pero el código todavía está incrustado en el código comercial y no se ha eliminado.
▐Cómo escribir anotaciones


Spring cache utiliza un proxy dinámico para procesar operaciones relacionadas con el caché en la clase de proxy y, al mismo tiempo, llama a métodos en la clase de proxy, de modo que el código que opera el caché y el código comercial se pueden separar, y cuando se necesita la capacidad del caché Para fortalecerlo más adelante, solo modifique el método en la clase proxy.
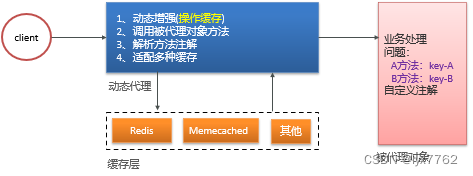
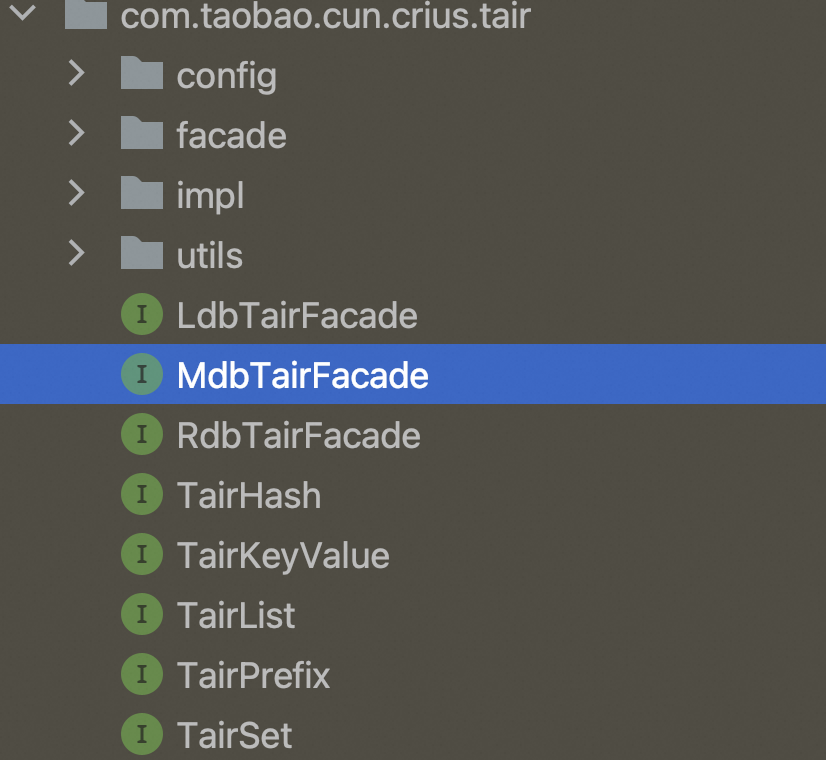
▐Directorio de códigos
▐Mapa de anotaciones
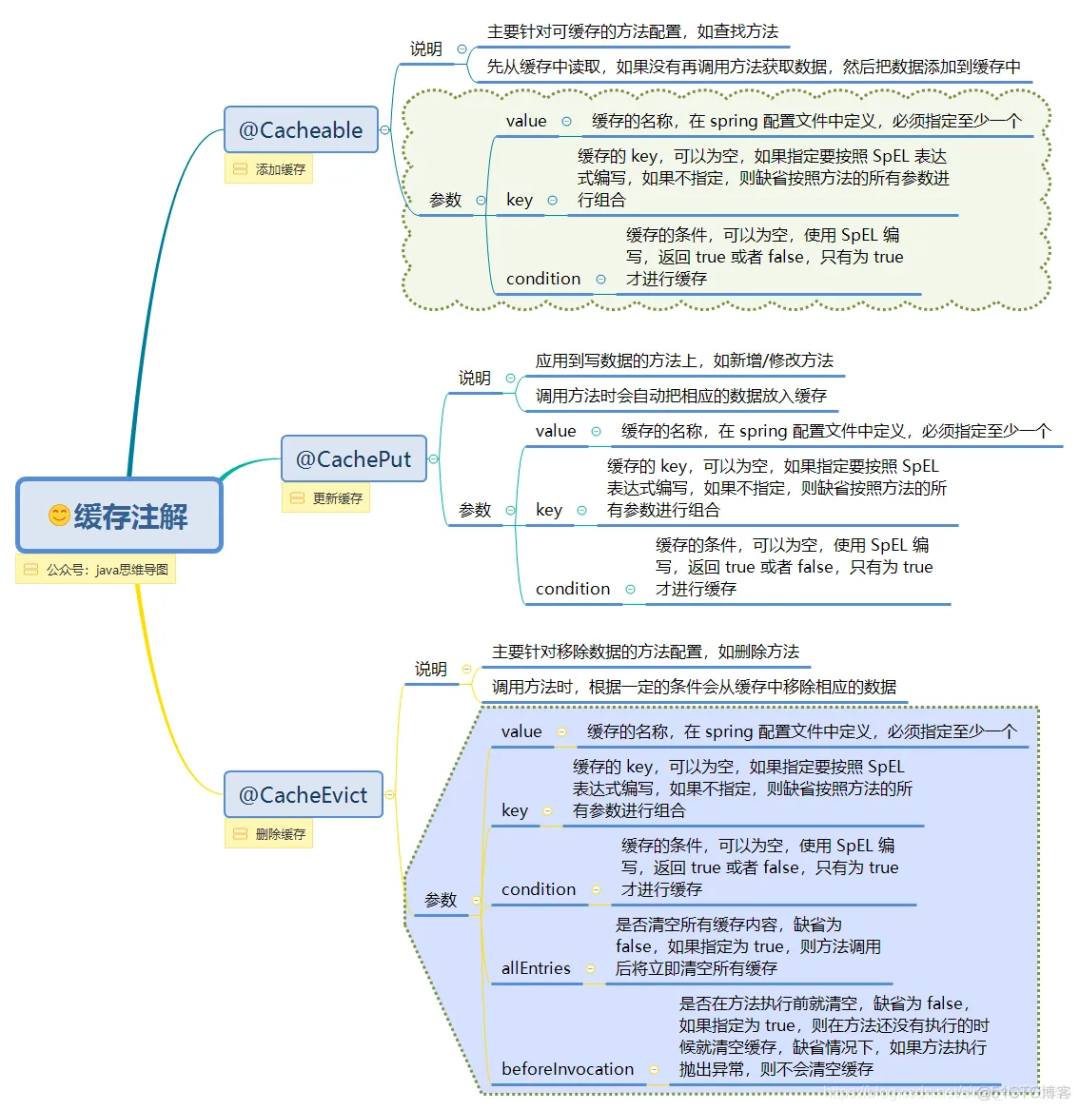
▐Ejemplo de uso de anotaciones
@Cacheable(value = "user_cache", unless = "#result == null")public User getUserById(Long id) {return userMapper.getUserById(id);}@CachePut(value = "user_cache", key = "#user.id", unless = "#result == null")public User updateUser(User user) {userMapper.updateUser(user);return user;}@CacheEvict(value = "user_cache", key = "#id")public void deleteUserById(Long id) {userMapper.deleteUserById(id);}
▐Análisis del programa
-
Caché multinivel; -
La caché se actualiza periódicamente; -
lista de caché; -
Mecanismo de protección de caché cpp; -
Recuento de caché.
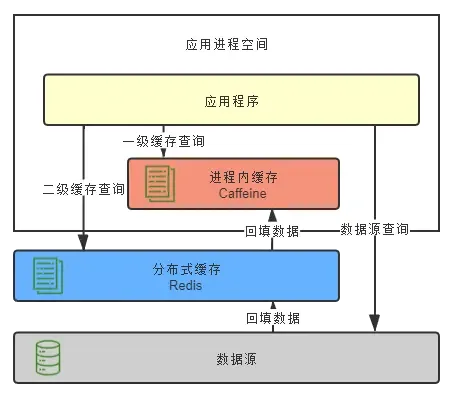

Conozca la solución del marco de caché de Spring e implemente un marco de caché personalizado, que no solo conserva las ventajas del marco de caché de Spring, sino que también implementa muchas capacidades faltantes de Spring Cache, como desglose de caché, protección contra penetración de caché, caché multinivel, etc. .
▐Ejemplo de código de anotación

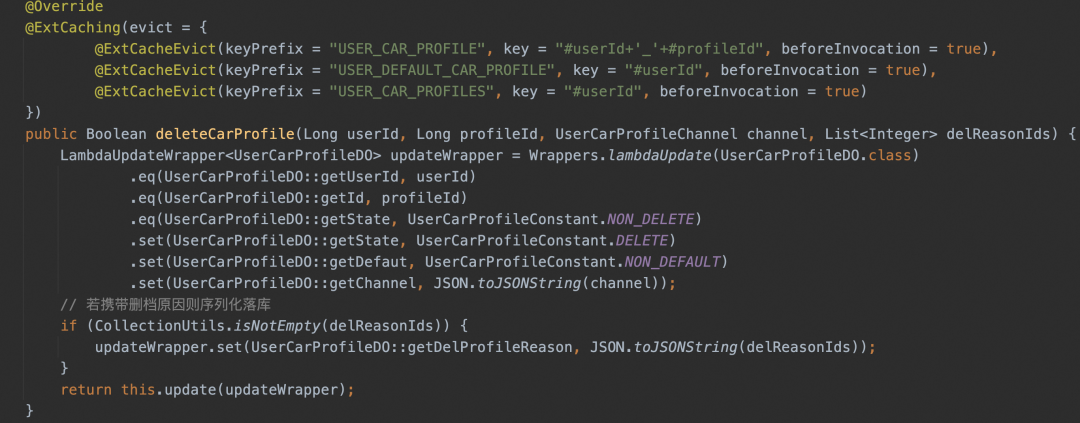
▐Estructura del proyecto
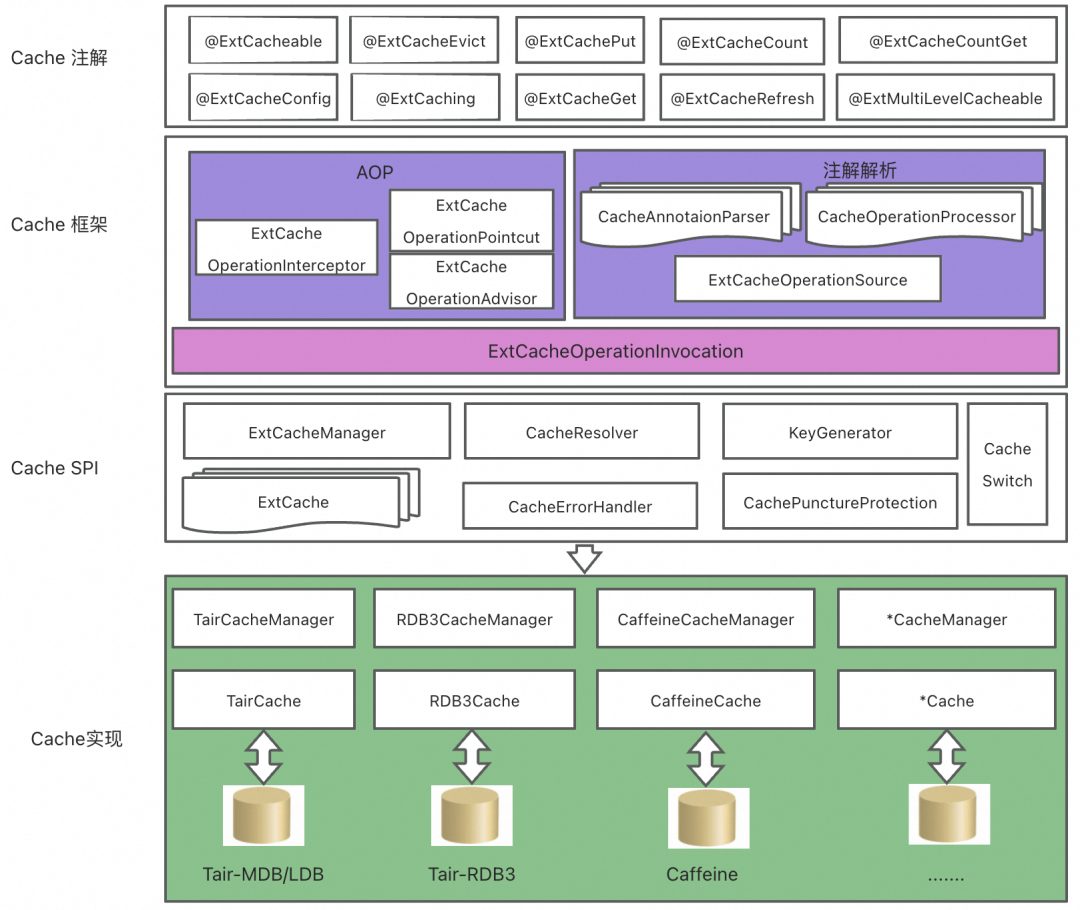

Con la ayuda de la implementación de Spring Cache, construimos un marco de caché personalizado y ampliamos muchas anotaciones, como recuento, actualización de caché, caché de lista, bloqueo distribuido, caché multinivel, etc., que no solo realiza la separación del código de caché y código comercial, pero también expande la capacidad de almacenamiento en caché de Spring, lo que mejora en gran medida la legibilidad del código y reduce la eficiencia del mantenimiento del código en caché.

La misión del equipo de tecnología automotriz de Tmall es experimentar la mejor vida de las personas y los automóviles, remodelar la industria automotriz y ser un administrador de automóviles atento a su alrededor. Todos ellos están formando la mente de los consumidores para ver, comprar y mantener automóviles en línea y digitalizarlos. e integrar verticalmente la industria automotriz y, a través de los avances del modelo, aprovechar la integración de productos y efectos, mejorar la eficiencia de la industria y crear dividendos en la industria.
Tecnología del lado del servidor | Calidad técnica | Algoritmo de datos
Este artículo se comparte desde la cuenta pública de WeChat: Big Taobao Technology (AlibabaMTT).
Si hay alguna infracción, comuníquese con [email protected] para eliminarla.
Este artículo participa en el " Plan de creación de fuentes OSC ". Los que están leyendo pueden unirse y compartir juntos.