
Invitado compartido:
Fu Qingwu, arquitecto de big data del grupo de arquitectura de datos OPPO
En la aplicación real de OPPO, combinamos a la perfección el Shuttle de desarrollo propio con Alluxio, lo que mejoró significativamente el rendimiento de todo el Servicio Shuttle, básicamente duplicándolo. A través de esta optimización, redujimos con éxito la presión del sistema a aproximadamente la mitad y duplicamos directamente el rendimiento. Esta combinación no sólo resuelve los problemas de rendimiento, sino que también inyecta nueva vitalidad al sistema de servicios de OPPO.
Versión de texto completo compartiendo contenido↓
Tema compartido: "La práctica de Alluxio en la integración de almacenes y lagos de datos e inteligencia artificial"
Arquitectura de almacén de lago de datos integrada de datos e inteligencia artificial
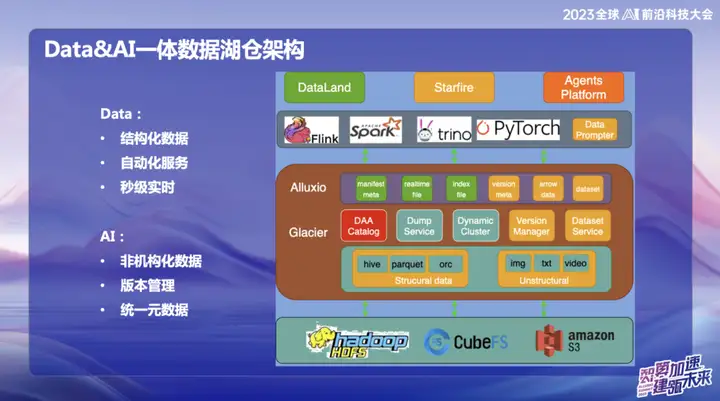
La imagen de arriba muestra la arquitectura general actual de OPPO, que se divide principalmente en dos partes:
1 、 Datos
2 、 IA
En el campo de los datos, OPPO se centra principalmente en datos estructurados, es decir, datos que normalmente se procesan mediante SQL. En el campo de la IA, la atención se centra principalmente en los datos no estructurados. Para lograr una gestión unificada de datos estructurados y no estructurados, OPPO ha establecido un sistema llamado Datos y Catálogo, que se gestiona en forma de metadatos de catálogo. Al mismo tiempo, este también es un servicio de lago de datos, en el que la capa superior de acceso a datos utiliza el caché distribuido de Alluxio.
¿Por qué elegimos utilizar Alluxio?
Debido a la gran escala de la sala de ordenadores doméstica de OPPO, la cantidad de memoria inactiva en los nodos informáticos es considerable. Estimamos que, en promedio, alrededor de 1 PB de memoria está inactivo cada día y esperamos aprovecharlo por completo a través de este sistema de administración de memoria distribuida. La parte naranja representa la gestión de datos no estructurados. Nuestro objetivo es utilizar servicios de lago de datos para que los datos no estructurados sean tan fáciles de gestionar como los estructurados y proporcionar aceleración para el entrenamiento de IA.
Catálogo DAA
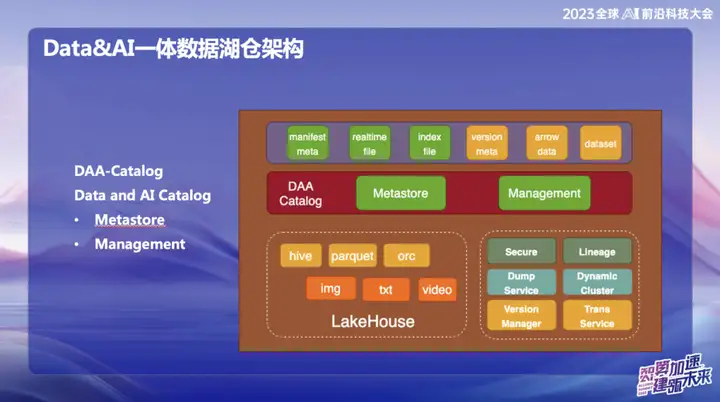
DAA-Catalog, o Catálogo de Datos e IA, es el objetivo que persigue nuestro equipo en la base de la arquitectura de datos. Elegimos este nombre porque OPPO está comprometido a competir con las mejores empresas de la industria. Actualmente creemos que Databricks es una de las empresas más destacadas en el campo del Data&AI. Ya sea tecnología, conceptos avanzados o modelos de negocio, Databricks ha tenido un buen desempeño.
Inspirándonos en Unicatalog de Databricks, vemos que los datos del servicio y el proceso de capacitación de IA de Databricks giran principalmente en torno a Unity Catalog. Por lo tanto, decidimos crear DAA-Catalog para perseguir nuestro objetivo de competir con los mejores de la industria en el espacio de almacenamiento de lagos de datos.
En concreto, esta funcionalidad se divide en dos módulos principales:
- Metastore (almacenamiento de metadatos) : esta parte es responsable de la gestión de metadatos y la capa subyacente se basa en la gestión de metadatos de Iceberg. Incluye confirmaciones simultáneas y gestión del ciclo de vida. Al mismo tiempo, utilizamos Down Service para la administración, porque nuestros datos ingresarán primero al enorme grupo de memoria caché de Alluxio y realizarán la inserción y consulta en tiempo real de cada registro.
- Gestión : esta parte es el servicio DOM. ¿Por qué elegir Down Service? Debido a que los datos se almacenan primero en la memoria de Alluxio después de ingresarlos, logra un rendimiento en tiempo real de segundo nivel. Durante todo el proceso, los datos se enviarán automáticamente a Iceberg a través del Catálogo una vez que ingresen, y los metadatos están básicamente en Alluxio.
¿Por qué necesitamos implementar una función en tiempo real de segundo nivel?
Principalmente porque encontramos un problema grave al usar Iceberg antes. Básicamente, se requiere una confirmación cada 5 minutos. Cada confirmación generará una gran cantidad de archivos pequeños, lo que ejerce mucha presión sobre el sistema informático Flink y los metadatos de HDFS. Al mismo tiempo, estos archivos también deben limpiarse y fusionarse manualmente. A través del servicio Alluxio se pueden introducir datos directamente en la memoria, y también se gestiona el Servicio Down a través del Catálogo. Durante todo el proceso, los datos se hundirán automáticamente en Iceberg después de ingresarlos, y los metadatos están básicamente todos en Alluxio.
Dado que OPPO coopera mucho con Alluxio, realizamos algunos ajustes basados en la versión 2.9 y el rendimiento ha mejorado enormemente. La lectura y escritura de archivos de transmisión se implementan en el lago de datos. Cada dato se puede tratar como una confirmación sin la necesidad de confirmar todo el archivo.
Aceleración de datos estructurados
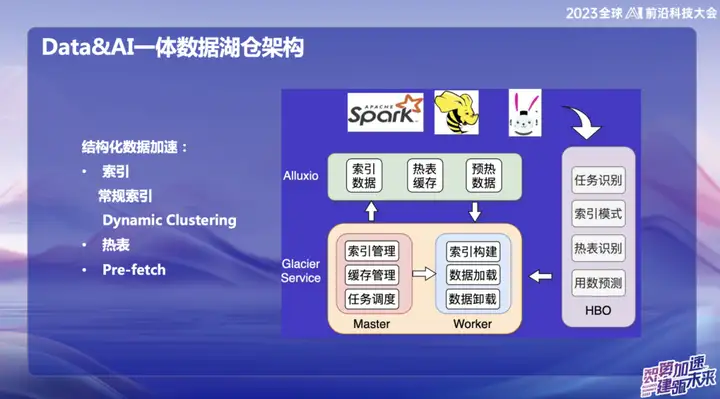
Con el desarrollo del big data, muchas infraestructuras se han vuelto bastante completas y resuelven problemas en muchos escenarios diferentes. Sin embargo, nuestra atención se centra en cómo utilizar los recursos y la memoria inactivos de manera más eficiente. Por lo tanto, nos comprometemos a partir de dos aspectos: uno es la aceleración del caché y el otro es la optimización de índices y tablas activas.
Propusimos un concepto llamado "Dynamic Cluster", que es una función de agregar datos dinámicamente, inspirado en una tecnología de Databricks. Aunque la curva Hallway también se usa internamente, implementamos algoritmos de clasificación de "orden" y "orden incremental" encima, fusionándolos para formar un clúster dinámico. Esta innovación puede agregar datos dinámicamente después de la entrada de datos para mejorar la eficiencia de las consultas. En comparación con la curva Hallway, el algoritmo de "orden" es más eficiente, pero la curva Hallway es superior en cambios en tiempo real. Esta integración nos proporciona una forma más flexible y eficiente de consultar y agregar datos.
Gestión de datos no estructurados
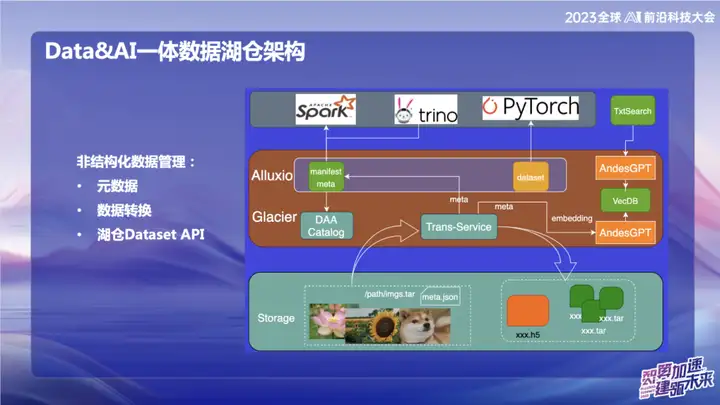
La imagen de arriba muestra algunos de nuestros trabajos en el campo de datos no estructurados, principalmente relacionados con el campo de la IA. Dentro de OPPO, las herramientas utilizadas para el entrenamiento de IA al principio son relativamente antiguas. Los datos generalmente se leen directamente a través de scripts o los datos se almacenan en un almacenamiento de objetos en forma de archivos de texto sin formato o archivos de imagen sin formato. Con el servicio de transferencia, podemos importar datos automáticamente al lago de datos y cortar los datos de la imagen empaquetada en un formato de conjunto de actualización. En el campo de la IA, especialmente en el campo del procesamiento de imágenes, el conjunto de actualización es una interfaz de conjunto de datos eficiente. No solo es compatible con la interfaz del conjunto de datos web, sino que también se puede convertir al formato H5.
Nuestro objetivo es hacer que la gestión de datos no estructurados sea tan conveniente como los datos estructurados mediante el procesamiento de metadatos. Durante el proceso de conversión de datos, los metadatos de los datos no estructurados se escriben en el catálogo. Al mismo tiempo, lo combinamos con el modelo grande y escribimos parte de la información de los metadatos en la base de datos vectorial para facilitar la consulta de los datos en el almacén del lago utilizando el modelo grande o el lenguaje natural. El objetivo de este trabajo de integración es mejorar la eficiencia de la gestión de datos no estructurados y hacerlo más consistente con la gestión de datos estructurados.
Datos no estructurados: ejemplo de gestión de metadatos
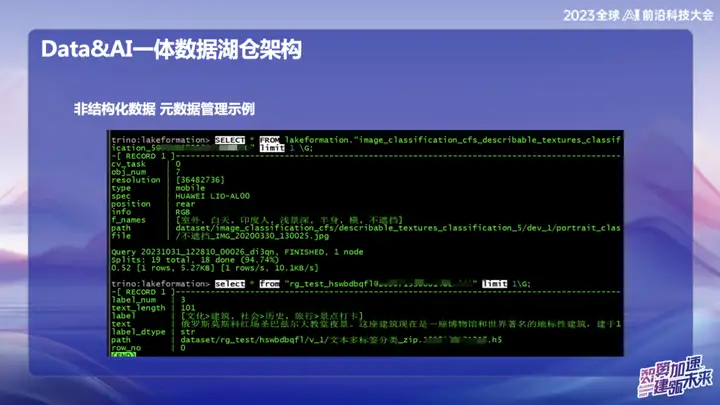
La imagen de arriba es un ejemplo de la gestión de datos no estructurados de OPPO, que puede buscar la ubicación de texto e imágenes como SQL.
Indicador de datos
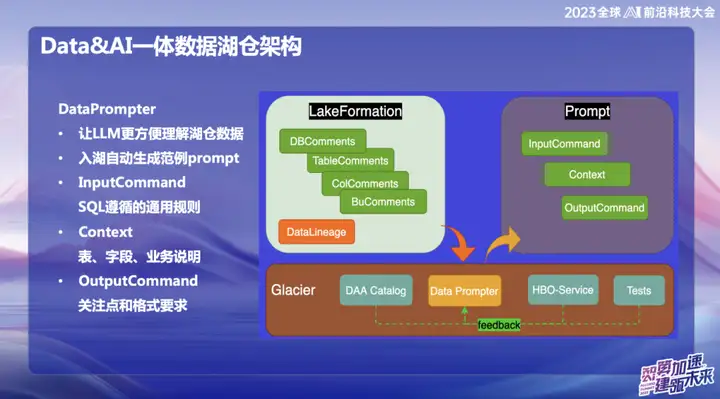
La intención original de elegir construir DataPrompter surge de la búsqueda de una mejor utilización de modelos grandes. OPPO apuesta por el campo de combinar datos con modelos de gran tamaño y ha lanzado un producto llamado Data Chart. A través de un software de chat interno, los usuarios pueden consultar fácilmente todos los datos. Por ejemplo, los usuarios pueden comprobar fácilmente el volumen de ventas de teléfonos móviles ayer, o comparar la diferencia de ventas con las ventas de teléfonos móviles Xiaomi y realizar análisis de datos mediante lenguaje natural.
Durante el proceso de creación del producto, las tablas de datos en cada campo requieren que personal comercial profesional ingrese el Prompter. Esto plantea desafíos para la promoción de todo el almacén o producto del lago de datos, porque el Prompter de cada tabla lleva mucho tiempo. Por ejemplo, si desea ingresar datos de una tabla financiera, debe completar en detalle información profesional y técnica, como los campos de la tabla, el significado del dominio comercial y las tablas de dimensiones ampliadas.
Nuestro objetivo final es permitir que el modelo grande comprenda fácilmente los datos de nivel superior después de que los datos ingresan al almacén del lago. Durante el proceso de entrada de datos al lago, la empresa necesita mostrar cierta información prescrita, combinada con nuestra experiencia acumulada en Data Prompter, y utilizar algunas consultas comunes proporcionadas por el servicio HBO para finalmente generar una plantilla de Prompter que haga que el modelo grande sea fácil de entender. . Esta combinación tiene como objetivo permitir que el modelo comprenda mejor los datos comerciales y facilitar la integración de Hucang y los modelos grandes.
Alluxio ayuda a entrar al lago en tiempo real en segundos
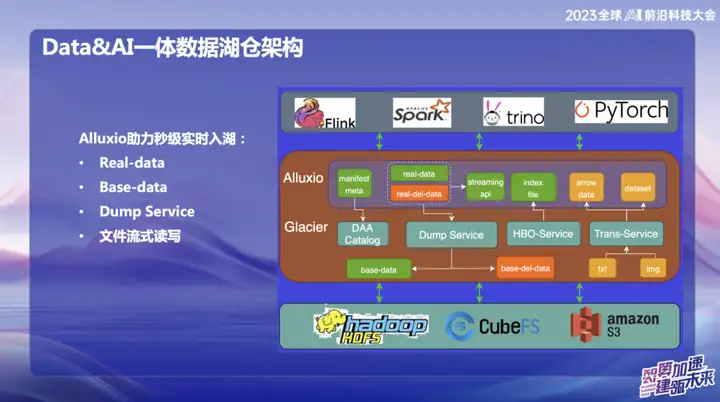
Alluxio ayuda a ingresar al lago en tiempo real en segundos, que se divide principalmente en:
1 、 datos reales
2、Datos base
3、Servicio de volcado
4. Lectura y escritura de transmisión de archivos
La práctica de Alluxio en la arquitectura de Hucang
Alluxio combinado con Spark RSS
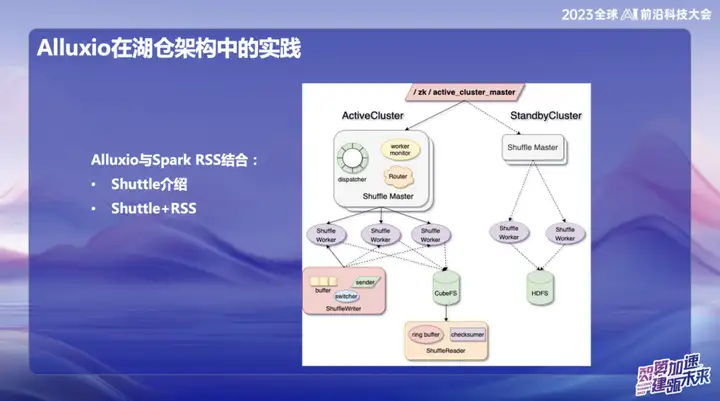
Inicialmente elegimos combinar Alluxio con el servicio Spark RSS a través del servicio Spark Shuttle de desarrollo propio y abrirlo en nombre de Shuttle. Inicialmente, nuestra base subyacente se basaba en un sistema de archivos distribuido, pero luego encontramos algunos problemas de rendimiento, por lo que encontramos Alluxio.
La combinación perfecta de Shuttle y Alluxio ha mejorado significativamente el rendimiento de todo el Servicio Shuttle, prácticamente duplicando el rendimiento. A través de esta optimización, redujimos con éxito la presión del sistema a aproximadamente la mitad y duplicamos directamente el rendimiento. Esta combinación no sólo resuelve el problema de rendimiento, sino que también inyecta nueva vitalidad a nuestro sistema de servicio.
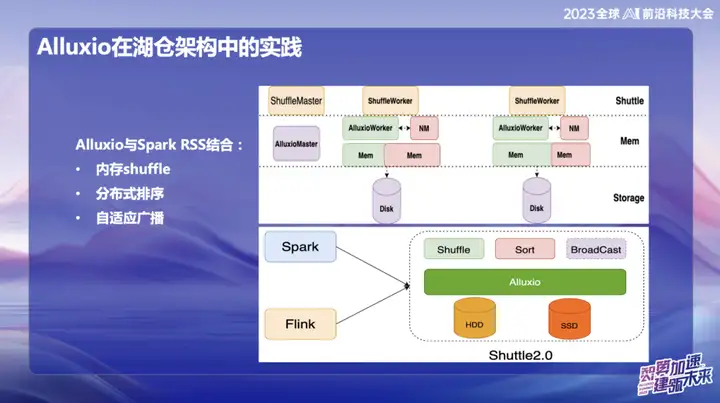
En la investigación y el desarrollo posteriores de OPPO, el marco basado en Alluxio+Shuttle ha logrado más innovaciones. Optimizamos tanto el operador de Shuttle como el operador de transmisión al nivel de datos de la memoria A través de una interacción eficiente de los datos de la memoria, especialmente cuando se procesa Reducción de un solo punto, cuando los datos están sesgados, se puede migrar la operación de clasificación que originalmente tomó hasta 50 minutos. Después de adoptar la nueva solución, el tiempo de procesamiento se redujo con éxito a menos de 10 minutos. Esta optimización no solo mejora en gran medida la eficiencia del procesamiento, sino que también alivia eficazmente el impacto de la distorsión de los datos en el rendimiento del sistema.
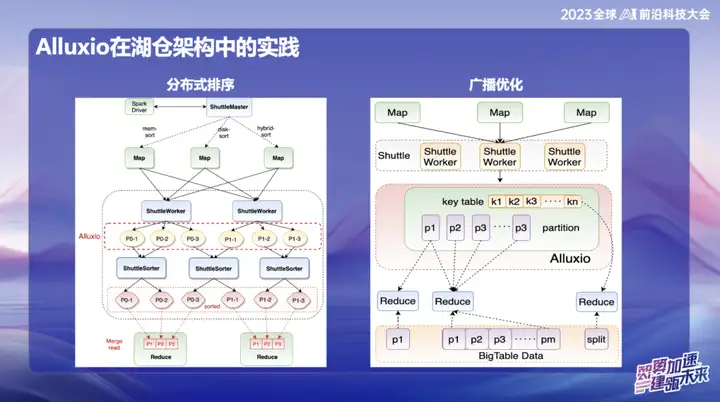
Los resultados de la transmisión son muy significativos, especialmente en Spark. El tamaño de transmisión predeterminado es 10 M. Debido a que todos los datos de transmisión deben almacenarse en el lado de Java, es propenso a expandirse después de la serialización de Java, lo que a su vez causa problemas de OOM (memoria insuficiente). . Esto sucede mucho en entornos en línea.
Para resolver este problema, actualmente almacenamos datos de transmisión en Alluxio. Esto permite transmitir datos de casi cualquier tamaño, hasta 10 gigabytes. Esta innovación se ha implementado con éxito en múltiples casos en línea en OPPO y ha tenido un impacto significativo en la mejora de la eficiencia.
Práctica de aplicaciones de Alluxio en nube pública/nube híbrida
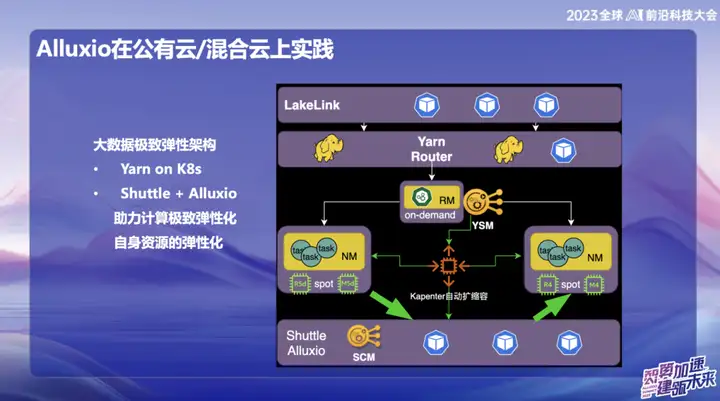
En el sistema de big data en la nube pública de OPPO, especialmente en Singapur, utilizamos principalmente AWS como infraestructura. En las primeras etapas, utilizamos el servicio de computación elástica (EMR) proporcionado por AWS. Sin embargo, en los últimos años, la situación económica general de la industria ha sido menos optimista y muchas empresas buscan reducir costos y mejorar la eficiencia. Frente a esta tendencia, hemos propuesto soluciones de desarrollo propio en el campo de la nube pública en el extranjero, utilizando recursos elásticos en la nube para construir una nueva arquitectura. El núcleo de esta innovadora solución se basa en la combinación de Alluxio+Shuttle, que proporciona un soporte clave para nuestro sistema de big data.

La ventaja significativa de la solución Alluxio+Shuttle es que el clúster Alluxio no es exclusivo de Shuttle y puede brindar soporte para otros servicios, incluido el almacenamiento en caché de datos y el almacenamiento en caché de metadatos. En la nube pública, sabemos que las operaciones de List en S3 consumen mucho tiempo durante el envío. Al combinar Alluxio y las soluciones Magic commit y Shuttle de código abierto, hemos logrado efectos de reducción de costos significativos, reduciendo los costos informáticos en aproximadamente un 80%. .
En un entorno de nube híbrida, brindamos servicios a equipos de IA. Dado que hay almacenamiento de objetos en el fondo del lago de datos, utilizamos la tarjeta GPU en Alibaba Cloud durante el proceso de capacitación y también la combinamos con recursos de GPU de construcción propia. Debido al ancho de banda limitado y al alto costo de las líneas dedicadas, se requiere una capa de caché eficaz para copiar datos. Inicialmente, adoptamos una solución proporcionada por el equipo de almacenamiento, pero su escalabilidad y rendimiento no eran los ideales. Después de presentar Alluxio, hemos logrado una aceleración de IO varias veces en múltiples escenarios, brindando un soporte más eficiente para el procesamiento de datos.
panorama

La escala del clúster de OPPO ha alcanzado decenas de miles de unidades en China, formando una escala bastante grande. Planeamos profundizar en los recursos de memoria en el futuro para utilizar más plenamente el espacio de almacenamiento interno. El equipo tiene tanto el marco de computación en tiempo real Flink como el marco de procesamiento fuera de línea Spark. Los dos pueden aprender de la experiencia de la aplicación de Alluxio de cada uno para lograr un desarrollo integrado en profundidad de Alluxio y el lago de datos.
En la ola de combinar big data y aprendizaje automático, nos mantenemos al día con las tendencias de la industria. Integre profundamente la arquitectura de datos con la inteligencia artificial (IA) desde abajo para brindar servicios de alta calidad para la IA como máxima prioridad. Esta integración no es sólo un avance tecnológico, sino también un plan estratégico para el desarrollo futuro.
Finalmente, exploraremos más a fondo las ventajas de Alluxio para ayudarnos a reducir costos en entornos de nube pública. Esto no sólo implica una optimización técnica, sino que también incluye una gestión más eficaz de los recursos de computación en la nube, proporcionando un sólido apoyo al desarrollo sostenible de la empresa.
Los recursos pirateados de "Qing Yu Nian 2" se cargaron en npm, lo que provocó que npmmirror tuviera que suspender el servicio unpkg: No queda mucho tiempo para Google. Sugiero que todos los productos sean de código abierto. time.sleep(6) aquí juega un papel. ¡Linus es el más activo en "comer comida para perros"! El nuevo iPad Pro utiliza 12 GB de chips de memoria, pero afirma tener 8 GB de memoria. People's Daily Online revisa la carga estilo matrioska del software de oficina: Sólo resolviendo activamente el "conjunto" podremos tener un futuro para Flutter 3.22 y Dart 3.4 . nuevo paradigma de desarrollo para Vue3, sin necesidad de `ref/reactive `, sin necesidad de `ref.value` Lanzamiento del manual chino de MySQL 8.4 LTS: le ayudará a dominar el nuevo ámbito de la gestión de bases de datos Tongyi Qianwen Precio del modelo principal de nivel GPT-4 reducido en un 97%, 1 yuan y 2 millones de tokens