1) Le processus de clustering k-means du jeu manuel des cartes à jouer:> 30 cartes, 3 types

Figure 1 Tableau statistique

Figure 2 Situation réelle du premier tour

Figure 3 Situation réelle du deuxième tour
2). * L'algorithme K-means est écrit de manière indépendante, le regroupement est effectué sur les données de longueur des pétales d'iris et affiché avec un nuage de points. (Points positifs)
ps: Le professeur d'intelligence artificielle a déjà enseigné cet algorithme, donc le code est fondamentalement le même.
Code source:
# Importer l'ensemble
de données à partir de sklearn.datasets import load_iris
import numpy as np
data = load_iris (). Data
n = len (data) # Calculer le nombre total d'échantillons
m = data.shape [1] # Le nombre d'attributs d'échantillon
k = 3 #Sélectionner la classe Le nombre de centres
dist = np.zeros ([n, k + 1]) #Initialiser la matrice de distance, la dernière colonne stocke la catégorie de chaque échantillon
center = data [: k
,: ] center_new = np.zeros ([k, m] )
tandis que True:
pour i dans la plage (n):
pour j dans la plage (k):
dist [i, j] = np.sqrt (sum ((data [i,:] - center [j ,:]) ** 2))
dist [i, k] = np.argmin (dist [i ,: k])
pour i dans la plage (k):
index = dist [:, k] == i #
center_new [i ,:] = data [index
,: ]. moyenne (axe = 0) si np.all ((centre == centre_nouveau)):
break
autrement:
center = center_new
print ("Classification de 150 échantillons \ n", dist [:, k])
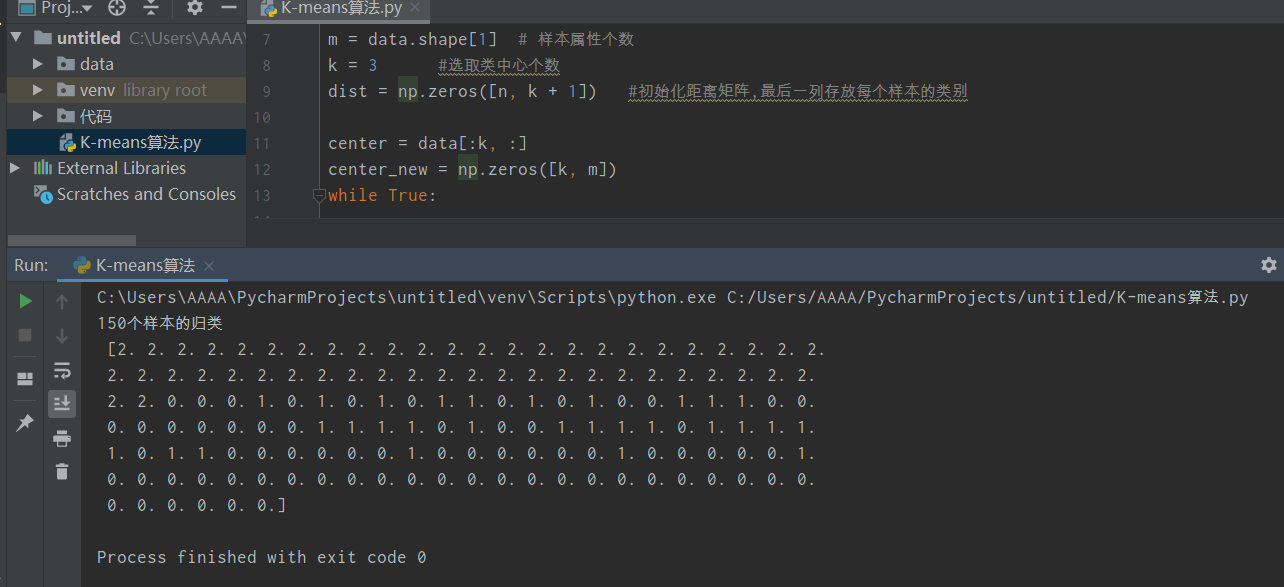
Figure 4 Résultats du clustering
3) Utilisez sklearn.cluster.KMeans et les données de longueur des pétales d'iris pour le regroupement et l'affichage avec un nuage de points.
Code source:
depuis sklearn.datasets importez load_iris depuis sklearn.cluster importez KMeans importez matplotlib.pyplot sous plt iris = load_iris () data = iris.data [:, 1] x = data.reshape (-1,1) # 平化y = KMeans (n_clusters = 3) # Introduire la construction du modèle KMeans avec un nombre centroïde de 3 y.fit (x) #Former le modèle et calculer le clustering k-means y_pre = y.predict (x) #Predict selon le modèle formé, c'est-à-dire calculer le cluster Centrer et prédire l'indice de clustering de chaque échantillon plt.scatter (x [:, 0], x [:, 0], c = y_pre, s = 50, cmap = 'rainbow') plt.show ()
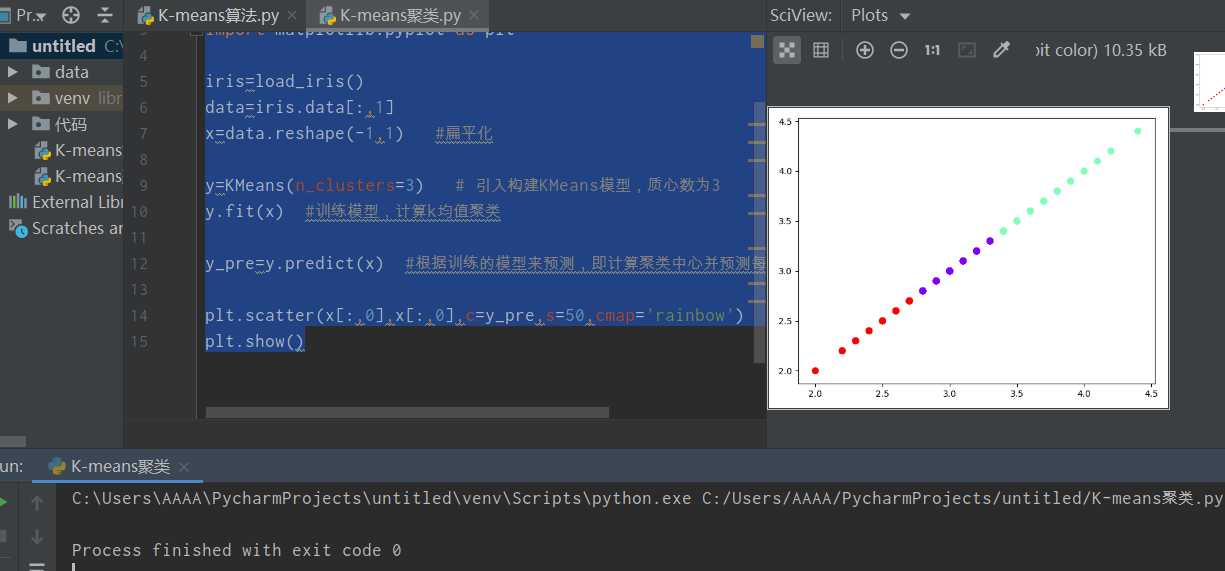
Figure 5 Code et diagramme de dispersion
4) Les données complètes des fleurs d'iris sont regroupées et affichées avec un nuage de points.
Code source:
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris = load_iris ()
x = iris.data
y = KMeans (n_clusters = 3) # Introduisez la construction du modèle KMeans avec un nombre centroïde de 3
y.fit ( x)
#Former le modèle et calculer le clustering k-means y_pre = y.predict (x) #Predict selon le modèle formé, c'est-à-dire calculer le centre du cluster et prédire l'
impression de l' index de clustering ("résultat de prédiction: \ n" , y_pre)
plt.scatter (x [:, 2], x [:, 3], c = y_pre, s = 100, cmap = 'rainbow', alpha = 0.5)
plt.show ()
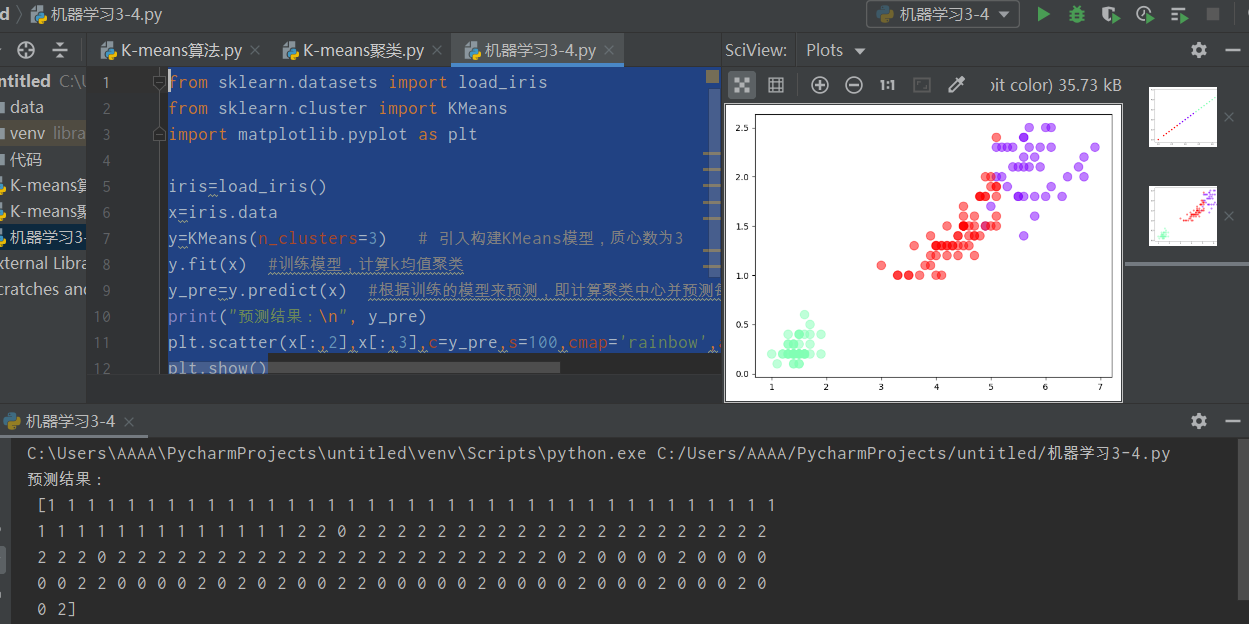
Figure 6 Résultats prévus et leurs diagrammes de dispersion
5) Pensez à ce qui est utilisé dans l'algorithme k-means?
Réponse: Le clustering k-means est l'algorithme de clustering le plus connu, et de par sa simplicité et son efficacité, il est le plus largement utilisé parmi tous les algorithmes de clustering. Étant donné un ensemble de points de données et le nombre requis de clusters k, k étant spécifié par l'utilisateur, l'algorithme k-means divise à plusieurs reprises les données en k clusters selon une certaine fonction de distance. La vie peut être utilisée pour classer et classer les choses selon certaines caractéristiques, telles que l'analyse du niveau de l'équipe de football chinoise selon les données des années précédentes, la prévision de la qualité des semences de cette année en fonction de la qualité des semences de l'année précédente et la classification des données.