Préface
Dans les chapitres 1 à 4, nous avons utilisé iText7 pour créer des documents PDF. Dans les chapitres 5-6, nous avons manipulé et réutilisé des documents PDF existants. Les documents PDF que nous traitons dans ces chapitres sont tous conformes à la spécification ISO 32000, qui est la norme de base des fichiers PDF. ISO 32000 n'est pas la seule norme ISO pour PDF, il existe de nombreuses sous-normes créées pour des raisons spécifiques. Dans ce chapitre, nous nous concentrons sur deux:
- ISO 14289, également appelée PDF / UA. UA signifie Accessibilité universelle. Tout le monde peut afficher les documents PDF qui utilisent la norme PDF / UA, y compris les personnes malvoyantes ou même les personnes aveugles. (Mon Dieu, est-ce si incroyable?)
- ISO 19005, également appelé PDF / A. A signifie Archivage. L'objectif est le stockage à long terme des documents numériques.
Dans ce chapitre, nous en apprendrons davantage sur PDF / A et PDF / UA en créant une série de fichiers PDF / A et PDF // UA.
Créer des documents PDF / UA
Avant de commencer l'exemple PDF / UA, examinons le problème que nous voulons résoudre. Dans le chapitre 1, nous avons créé un document avec des images. Dans la phrase «Le renard brun rapide saute par-dessus le chien paresseux», nous remplaçons «dag» et «fox» par les images correspondantes. Lorsque ce fichier est lu A ce moment, une machine ne peut pas savoir que le code de la première image est un renard, et la seconde image représente un chien, donc ce fichier sera considéré: "Quick brown jump over the paresseux".
Dans un PDF normal, le contenu sera dessiné dans le canevas. Nous pouvons utiliser des objets avancés tels que
ListetTable, mais une fois le PDF créé, ces objets ne seront pas enregistrés. L'unListest composé d' une série de lignes, mais un fragment de texte dans l'élément de liste ne sait pas qu'il fait partie de la liste. L'un estTablecomposé d'un groupe de textes à un emplacement spécifique.De même, un fragment de texte ne sait pas qu'il appartient à une ligne et une colonne spécifiques.
À moins que nous ne transformions un PDF en PDF balisé, le document ne contiendra aucune structure sémantique. Lorsqu'un document n'est pas stocké dans une structure sémantique, on dit que le PDF n'est pas accessible (n'est pas accessible). Pour être perceptible / compréhensible, ce document doit être capable de distinguer quelles parties d'une page sont du contenu réel et quelles parties ne sont pas du contenu réel (comme les en-têtes, les numéros de page). Si une ligne de texte n'en fait pas paragraphpartie, vous devez savoir si vous êtes un title, Bien sûr, il y a d'autres exigences. Nous pouvons ajouter toutes les informations à une page d'une seule manière, de cette manière est de créer 结构树(structure)et de définir le contenu comme 带标签的内容. Cela peut sembler compliqué, mais si nous utilisons les objets avancés d'iText7, nous pouvons l'utiliser efficacement setTagged()pour atteindre cet objectif.
En définissant PdfDocumentun document avec une étiquette List, Tableet des Paragraphobjets tels que la structure de la ceinture après avoir été introduite, il sera reflété dans le PDF tagué.
Bien sûr, ce n'est que pour l'une des exigences de la perception PDF (accessible, je ne sais vraiment pas quelle traduction est la meilleure, traduisez simplement en perception pour le moment). Le code suivant peut nous aider à comprendre d'autres exigences:
PdfDocument pdf = new PdfDocument(new PdfWriter(dest, new WriterProperties().addXmpMetadata()));
Document document = new Document(pdf);
//Setting some required parameters
pdf.setTagged();
pdf.getCatalog().setLang(new PdfString("en-US"));
pdf.getCatalog().setViewerPreferences(
new PdfViewerPreferences().setDisplayDocTitle(true));
PdfDocumentInfo info = pdf.getDocumentInfo();
info.setTitle("iText7 PDF/UA example");
//Fonts need to be embedded
PdfFont font = PdfFontFactory.createFont(FONT, PdfEncodings.WINANSI, true);
Paragraph p = new Paragraph();
p.setFont(font);
p.add(new Text("The quick brown "));
Image foxImage = new Image(ImageFactory.getImage(FOX));
//PDF/UA: Set alt text
foxImage.getAccessibilityProperties().setAlternateDescription("Fox");
p.add(foxImage);
p.add(" jumps over the lazy ");
Image dogImage = new Image(ImageFactory.getImage(DOG));
//PDF/UA: Set alt text
dogImage.getAccessibilityProperties().setAlternateDescription("Dog");
p.add(dogImage);
document.add(p);
document.close();
Création d'un PdfDocumentet Document, mais cette fois, nous utilisons WriterPropertiesles addXmpMetadata()métadonnées XMP d'ajouter automatiquement. Dans PDF / UA, les mêmes métadonnées doivent être stockées dans le PDF au format XML. XML ne peut pas être compressé. Les processeurs / programmes de traitement qui ne sont pas familiarisés avec le format de contenu PDF doivent être capables de détecter ces métadonnées XMP et de les traiter correctement. Un flux de données XMP est automatiquement créé dans l'entrée du dictionnaire d'informations. Ce dictionnaire d'informations est un objet PDF, qui contient des données telles que les titres des documents. En plus d'ajouter le flux de données XMP, nous devons également effectuer les opérations suivantes pour le rendre conforme à la norme PDF / UA:
- Définissez ceci
PdfDocumentcomme étiqueté (ligne 4) - Nous ajoutons un spécificateur de langue. Dans cet exemple, le fichier sait que la langue principale utilisée dans ce fichier est l'anglais américain (ligne 5)
- Modifiez les préférences du visualiseur afin que le titre du document soit toujours affiché dans la barre supérieure du visualiseur PDF
(lignes 6-7). Ensuite, nous mettons le titre dans les métadonnées du document (lignes 8-9) - Toutes les polices doivent être intégrées (ligne 11). Il existe en fait d'autres exigences pour les polices, mais il est trop tôt pour que nous en discutions.
- Tout le contenu doit être balisé. Lorsque vous rencontrez une image, nous devons utiliser un texte d'image alternatif pour fournir une description de l'image (ligne 17 et ligne 22)
Nous avons maintenant terminé le travail de création de PDF / UA. Les résultats sont présentés dans les deux figures 1 et 2. La différence n'est peut-être pas très évidente par rapport à la précédente, mais si nous ouvrons la page Balises (Adobe Acrobat Pro doit être utilisé, Adobe Acrobat Reader DC ne fonctionnera pas):
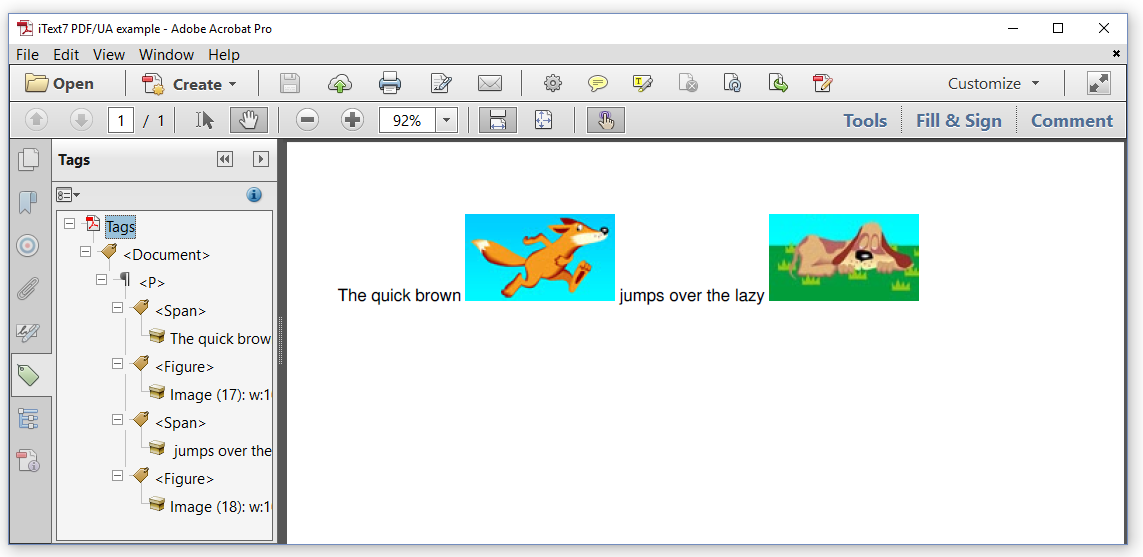
Nous pouvons voir qu'il <Document>y a des <P>balises dans les balises, et les <P>balises se composent de deux <Span>et deux <Figures>. Nous créerons des documents PDF / UA plus complexes plus loin dans ce chapitre, voyons maintenant comment créer un PDF / A.
Créer des documents PDF / A PDF / A-1
La partie 1 d'ISO 19005 a été publiée en 2005. Il est défini dans la déclaration officielle Adobe PDF 1.4 (cette déclaration n'était pas une norme ISO à l'époque). Le SO 19005-1 a introduit une série d'obligations et de restrictions:
- Toutes les ressources et informations du document doivent être stockées par elles-mêmes: toutes les polices doivent être intégrées; l'animation étendue, la vidéo, le son et les autres fichiers binaires ne sont pas autorisés.
- Les documents doivent enregistrer les métadonnées au format XMP (eXensible Metadata Platform): ISO 16684 (XMP) décrit comment enregistrer les métadonnées au format XML dans un fichier binaire, de sorte que les logiciels qui ne savent pas lire et interpréter le fichier binaire sont toujours Les métadonnées du fichier peuvent être extraites.
- Certaines fonctionnalités futures (avancées, non déclarées ou ajoutées à l'avenir) ne sont pas autorisées: le PDF ne peut pas contenir de JavaScript et ne peut pas être chiffré
La SO 19005-1: 2005 (PDF / A-1) définit deux niveaux de conformité:
- Niveau B («basique»): pour assurer l'aspect visuel des fichiers de conservation à long terme.
- Niveau A ("accessible"): non seulement assure l'apparence visuelle des fichiers de conservation à long terme, mais introduit également des fonctionnalités structurelles et sémantiques. Ce PDF doit être un PDF balisé. (Notez qu'il est similaire à PDF / UA, mais différent, la raison sera mentionnée dans l'exemple suivant)
Le code suivant montre comment transformer le PDF «Renard brun rapide» que nous avons créé précédemment en conformité avec la norme PDF / A-1b:
//Initialize PDFA document with output intent
PdfADocument pdf = new PdfADocument(new PdfWriter(dest),
PdfAConformanceLevel.PDF_A_1B,
new PdfOutputIntent("Custom", "", "http://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(INTENT)));
Document document = new Document(pdf);
//Fonts need to be embedded
PdfFont font = PdfFontFactory.createFont(FONT, PdfEncodings.WINANSI, true);
Paragraph p = new Paragraph();
p.setFont(font);
p.add(new Text("The quick brown "));
Image foxImage = new Image(ImageFactory.getImage(FOX));
p.add(foxImage);
p.add(" jumps over the lazy ");
Image dogImage = new Image(ImageFactory.getImage(DOG));
p.add(dogImage);
document.add(p);
document.close();
Nous pouvons voir que nous n'utilisons plus d' PdfDocumentinstances, à la place, nous utilisons des PdfADocumentinstances. Tout d'abord, nous créons une PdfADocumentinstance. Le PdfADocumentpremier paramètre du constructeur d'instance est un PdfWriter, le deuxième paramètre est le niveau de conformité (le voici PdfAConformanceLevel.PDF_A_1B) et le troisième paramètre est un PdfOutpuyIntext. Cette intention de sortie indique au document comment interpréter ce qui est stocké dans le document Couleur. À la ligne 10, nous nous assurons que la police est incorporée.
Le PDF généré ressemble à la figure 3 suivante:
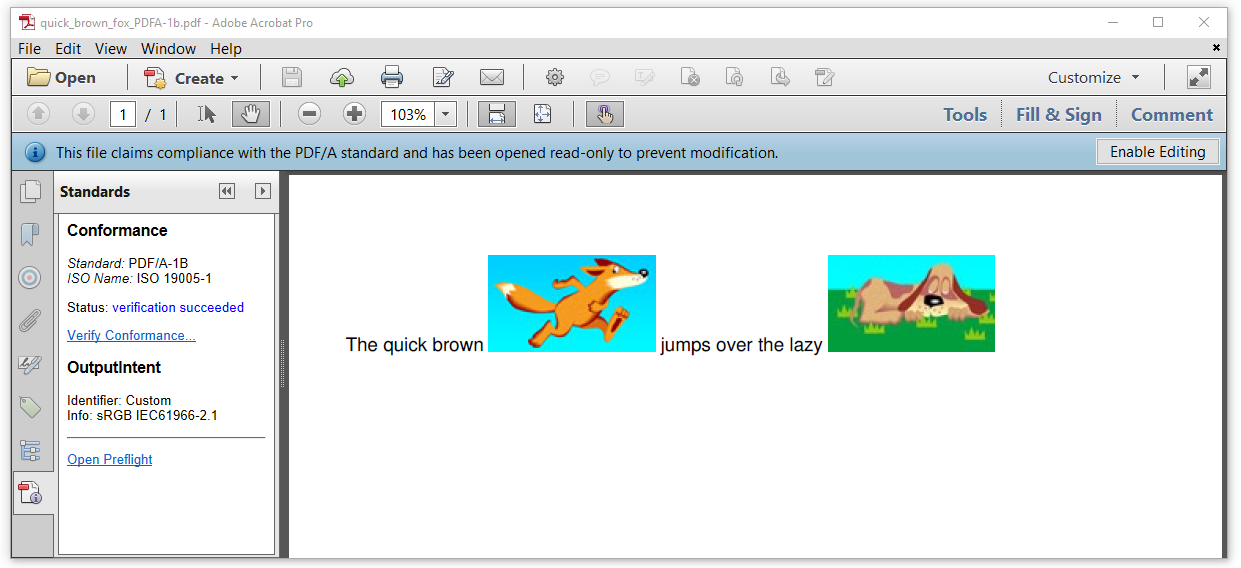
Sur l'image ci-dessus, nous pouvons voir une petite barre bleue avec "Ce fichier est conforme au standard PDF / A et a été ouvert en lecture seule pour éviter qu'il ne soit modifié". À cet égard, nous interprétons cette phrase de deux manières:
- Cette phrase ne signifie pas que le PDF est réellement conforme à la norme PDF / A, elle indique simplement que c'est possible. Afin de confirmer s'il est conforme à la norme, nous devons ouvrir le panneau "Standard" dans Adobe Acrobat, puis cliquer sur "Vérifier la conformité Link, Acrobat vérifiera si le document est le même que celui indiqué. Dans cet exemple, le résultat est "vérification réussie", de cette manière, nous allons enfin créer un document standard PDF / A-1B.
- Le document a été ouvert en lecture seule, non pas parce que la modification n'est pas autorisée (le PDF / A ne peut pas protéger le PDF contre la modification), mais Adobe Acrobat est affiché en mode lecture seule, car toute modification peut changer la conversion du PDF en non conforme PDF / Un PDF standard. Il est permis de mettre à jour PDF / A sans détruire le statut de PDF / A.
Ensuite, nous examinons comment créer un PDF / A-1a, le code est le suivant:
//Initialize PDFA document with output intent
PdfADocument pdf = new PdfADocument(new PdfWriter(dest),
PdfAConformanceLevel.PDF_A_1A,
new PdfOutputIntent("Custom", "", "http://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(INTENT)));
Document document = new Document(pdf);
//Setting some required parameters
pdf.setTagged();
//Fonts need to be embedded
PdfFont font = PdfFontFactory.createFont(FONT, PdfEncodings.WINANSI, true);
Paragraph p = new Paragraph();
p.setFont(font);
p.add(new Text("The quick brown "));
Image foxImage = new Image(ImageFactory.getImage(FOX));
//Set alt text
foxImage.getAccessibilityProperties().setAlternateDescription("Fox");
p.add(foxImage);
p.add(" jumps over the lazy ");
Image dogImage = new Image(ImageFactory.getImage(DOG));
//Set alt text
dogImage.getAccessibilityProperties().setAlternateDescription("Dog");
p.add(dogImage);
document.add(p);
document.close();
Interprétons le code. À la ligne 3, nous sommes PdfConformanceLevel.PDF_A1Bpassés à PdfConformanceLevel.PDF_A1A. À la ligne 8, transformez-le PdfADocumenten PDF balisé, puis ajoutez les informations de description textuelle de l'image. Le résultat final est illustré dans la figure 4 ci-dessous:

Lorsque nous ouvrons le panneau standard, nous pouvons voir qu'Adobe Acrobat Pro considère ce fichier comme étant PDF / A-1A et PDF / UA-1, mais cette fois il n'a pas vérifié le lien de conformité, je dois donc recourir à l'outil d'inspection pré-presse (version anglaise C'est un contrôle en amont, étourdi. Il a fallu beaucoup de temps pour trouver la version chinoise. Je vais la partager avec vous ici. On estime que tout le monde utilise le chinois. Les étapes spécifiques sont: ouvrir la norme PDF dans l'outil → inspection prépresse (ou directement à gauche Cliquez pour ouvrir l'inspection pré-presse) → recherchez la spécification PDF / A-1b sous la spécification PDF / A → analyse ), comme illustré dans la figure 5 ci-dessous:
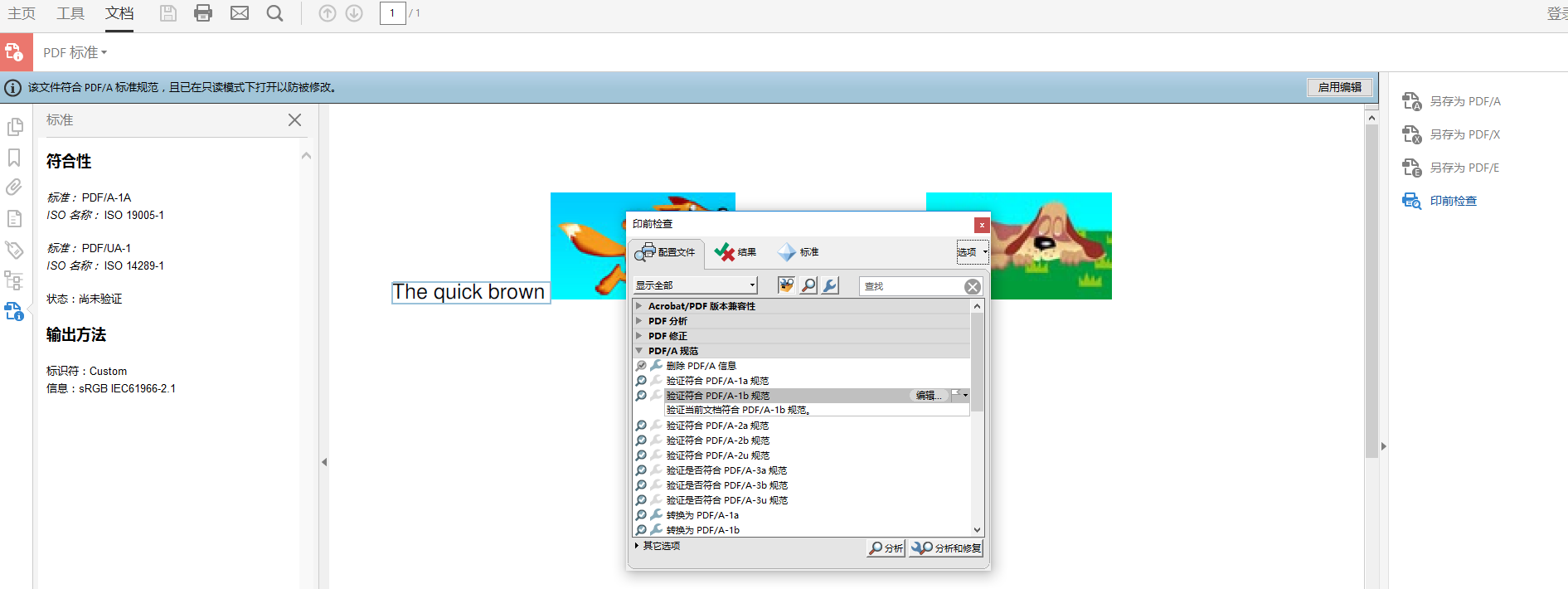
Si nous continuons à regarder l'image dans la version anglaise, nous pouvons voir qu'aucune erreur n'a été trouvée. Nous ne pouvons pas vérifier la conformité PDF / UA car PDF / UA implique certaines exigences qui ne peuvent pas être vérifiées par l'ordinateur local. Par exemple: si nous échangeons la description de l'image du renard avec la description de l'image du chien, la machine ne le remarquera pas. Cela rendra le fichier inaccessible car le fichier diffusera de fausses informations aux personnes basées sur les lecteurs d'écran. Dans tous les cas, il suffit de savoir que le document que nous avons créé ne répond pas à la norme PDF / UA, car nous avons omis certains éléments de base (comme la langue, la langue est également définie dans le premier exemple).
Dès le début, il a été déterminé que la partie accréditation d'ISO 19005 ne deviendrait jamais invalide. Les sections nouvelles et suivantes ne définiront que de nouvelles fonctions utiles. Ces définitions de suivi sont les PDF / A-2 et PDF / A-3 que nous sommes sur le point de présenter.
Créer des documents PDF / A PDF / A-2 et PDF / A-3
L'ISO 19005-2: 2011 (PDF / A-2) a été ajoutée à la norme PDF / A selon la norme ISO (pas le document PDF officiel d'Adobe). PDF / A-2 possède de nombreuses fonctionnalités et améliorations dans PDF1.5 et 1.6.1.7:
- Les fonctionnalités supplémentaires utiles sont: Prise en charge de JPEG2000, conteneur, XMP au niveau de l'objet et contenu facultatif
- Les améliorations utiles incluent une meilleure prise en charge de la transparence, des annotations de type, des annotations et des signatures numériques.
En termes de conformité, en plus des niveaux A et B d'origine, PDF / A-2 définit également des niveaux supplémentaires:
- Niveau U ("Unicode"): Assurez-vous que le commerce extérieur visuel du document peut être stocké pendant une longue période et que le format de stockage de tous les textes est UNICODE
ISO 19005-3 : 2012 (PDF / A-3) est presque identique à PDF / A-2. La seule différence est que dans PDF / A-3, la pièce jointe ne doit pas nécessairement être au format PDF / A. Vous pouvez considérer n'importe quel format de fichier comme une pièce jointe à PFA / A-3. Par exemple, vous pouvez traiter un fichier au format Excel comme le résultat du document, un fichier au format Word pour créer un document PDF, etc. Le document lui-même doit se conformer à toutes les obligations et restrictions de la spécification PDF / A, mais ces obligations et restrictions ne s'appliquent pas à ses pièces jointes.
Dans l'exemple suivant, nous allons créer des normes PDF / UA et PDF / A-3A. La raison pour laquelle nous choisissons PDF / A-3 est que nous devons utiliser des fichiers CSV pour créer un PDF. Le code est le suivant:
PdfADocument pdf = new PdfADocument(new PdfWriter(dest),
PdfAConformanceLevel.PDF_A_3A,
new PdfOutputIntent("Custom", "", "http://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(INTENT)));
Document document = new Document(pdf, PageSize.A4.rotate());
//Setting some required parameters
pdf.setTagged();
pdf.getCatalog().setLang(new PdfString("en-US"));
pdf.getCatalog().setViewerPreferences(
new PdfViewerPreferences().setDisplayDocTitle(true));
PdfDocumentInfo info = pdf.getDocumentInfo();
info.setTitle("iText7 PDF/A-3 example");
//Add attachment
PdfDictionary parameters = new PdfDictionary();
parameters.put(PdfName.ModDate, new PdfDate().getPdfObject());
PdfFileSpec fileSpec = PdfFileSpec.createEmbeddedFileSpec(
pdf, Files.readAllBytes(Paths.get(DATA)), "united_states.csv",
"united_states.csv", new PdfName("text/csv"), parameters,
PdfName.Data, false);
fileSpec.put(new PdfName("AFRelationship"), new PdfName("Data"));
pdf.addFileAttachment("united_states.csv", fileSpec);
PdfArray array = new PdfArray();
array.add(fileSpec.getPdfObject().getIndirectReference());
pdf.getCatalog().put(new PdfName("AF"), array);
//Embed fonts
PdfFont font = PdfFontFactory.createFont(FONT, true);
PdfFont bold = PdfFontFactory.createFont(BOLD_FONT, true);
// Create content
Table table = new Table(new float[]{4, 1, 3, 4, 3, 3, 3, 3, 1});
table.setWidthPercent(100);
BufferedReader br = new BufferedReader(new FileReader(DATA));
String line = br.readLine();
process(table, line, bold, true);
while ((line = br.readLine()) != null) {
process(table, line, font, false);
}
br.close();
document.add(table);
//Close document
document.close();
Expliquons le code ligne par ligne:
- Ligne 1-5: Nous avons créé
PdfADocument(le type estPdfAConformanceLevel.PDF_A_3A)) etDocument - Ligne 7: Transformez le PDF en normes PDF-PDF / UA et PDF / A-3A balisées.
- Lignes 8 à 12: Définissez la langue, le titre du document et les préférences de la visionneuse - norme PDF / UA.
- Ligne 14-20: utilisez des paramètres spécifiques pour ajouter une pièce jointe — norme PDF / A-3A.
- Lignes 26-27: Incorporer des images et des polices - normes PDF / UA et PDF / A-3A.
- Ligne 28-38: Le contenu extrait est le même que notre code précédent au chapitre 1.
- Ligne 30: fermez le document et enregistrez le contenu
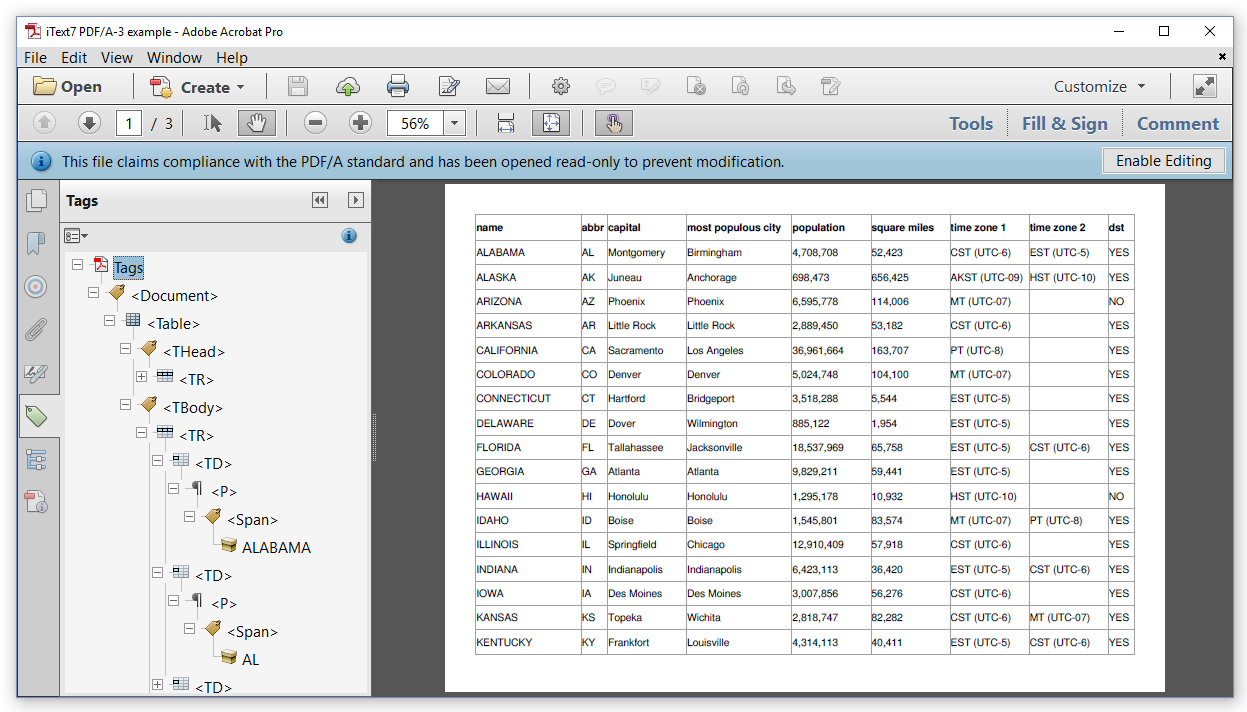
Comme le montre la figure 6 ci-dessous, nous pouvons voir que les objets que nous utilisons Tableet Cellajoutés au document dans le panneau de balises sont enregistrés avec la structure de données Table, un peu comme HTML:
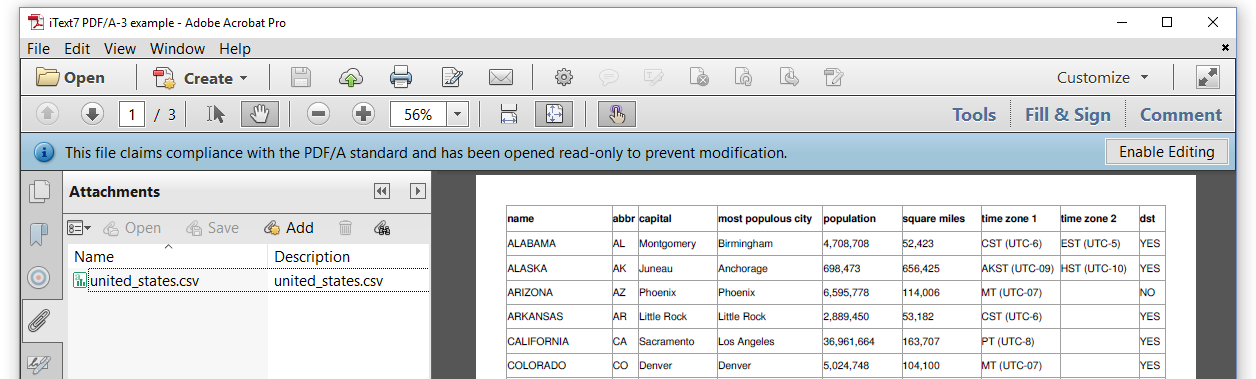
En même temps, nous ouvrons le panneau des pièces jointes, nous pouvons voir le fichier source CSV, et peut être facilement extrait, comme le montre la figure 7:
Grâce à l'exemple ci-dessus, par rapport au fichier PDF général, nous devons ajouter des informations supplémentaires lors de la création d'un document PDF / UA ou PDF / A, * "Pouvons-nous utiliser iText pour changer le document PDF ordinaire existant en Qu'en est-il des documents conformes aux normes PDF / UA ou PDF / A? "* Est la question la plus fréquemment posée dans les forums et les consultations. Nous espérons qu'à travers ce chapitre, tout le monde comprendra qu'iText ne peut pas être automatiquement converti pour les raisons suivantes:
- S'il existe un document avec une photo de renard et de chien comme auparavant, iText ne peut pas ajouter automatiquement les informations de description de remplacement manquantes à l'image, car iText n'est pas prêt à reconnaître la signification de ces images (pour le dire franchement, il n'y a pas de module d'apprentissage automatique, d'intelligence artificielle, ne peut pas Identifier le contenu)
- Si la police n'est pas incorporée et que le programme de police correspondant n'est pas fourni, iText ne saura pas à quoi ressemble la police, ni ne pourra incorporer la police dans le document.
Bien sûr, ce ne sont que deux petites raisons pour lesquelles ils ne peuvent pas être convertis automatiquement. Il est facile pour un PDF d'afficher une petite barre bleue indiquant que le document semble conforme à la norme PDF / A, mais que toutes les déclarations ne sont pas correctes.
Enfin, jetons un coup d'œil à l'assemblage de documents PDF / A.
Assemblage de documents PDF / A
Lors de l'assemblage de fichiers PDF / A, le plus digne de notre attention est que tous les documents que nous avons assemblés doivent être des fichiers PDF / A, pas un fichier PDF / A, un fichier ordinaire et le niveau de PDF / A également De même, l'un ne peut pas être A et l'autre B, car l'un a un arbre de structure et l'autre pas, les épisser ensemble entraînera un résultat erroné.
Nous avons assemblé les deux documents de niveau PDF / AA précédents, et le fichier résultant est illustré dans la figure 8 ci-dessous:
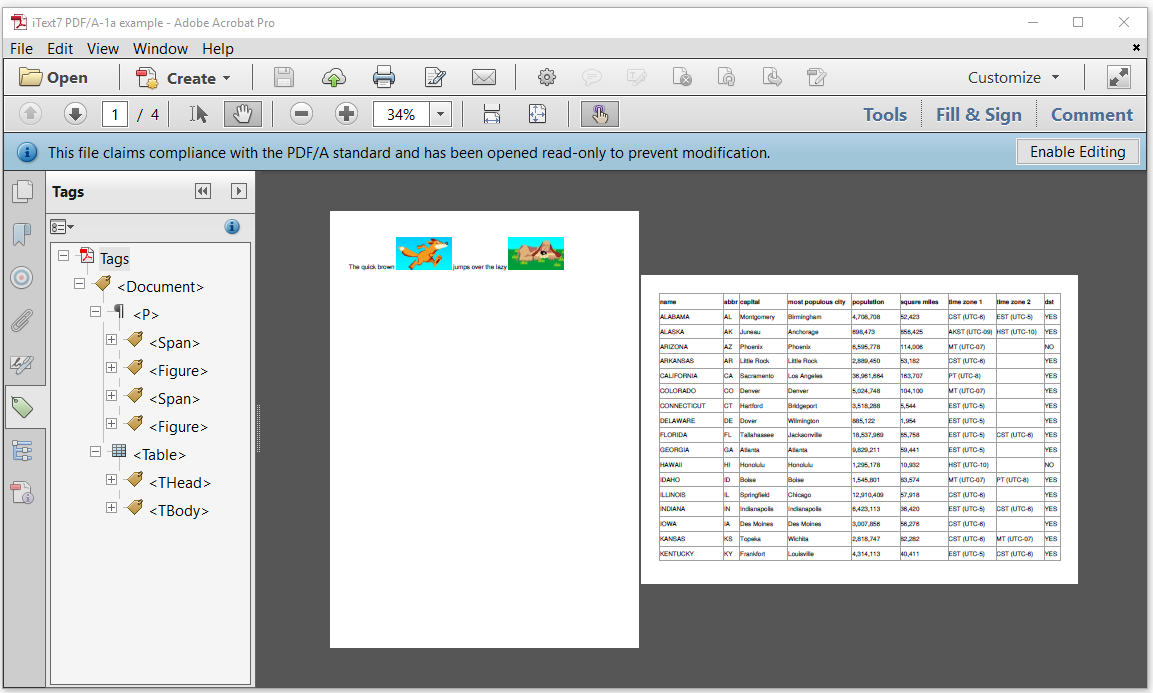
Nous en voyons un dans le panneau d'onglets <P>, suivi du <Table>code suivant montrant comment créer ce document:
PdfADocument pdf = new PdfADocument(new PdfWriter(dest),
PdfAConformanceLevel.PDF_A_1A,
new PdfOutputIntent("Custom", "", "http://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(INTENT)));
//Setting some required parameters
pdf.setTagged();
pdf.getCatalog().setLang(new PdfString("en-US"));
pdf.getCatalog().setViewerPreferences(
new PdfViewerPreferences().setDisplayDocTitle(true));
PdfDocumentInfo info = pdf.getDocumentInfo();
info.setTitle("iText7 PDF/A-1a example");
//Create PdfMerger instance
PdfMerger merger = new PdfMerger(pdf);
//Add pages from the first document
PdfDocument firstSourcePdf = new PdfDocument(new PdfReader(SRC1));
merger.addPages(firstSourcePdf, 1, firstSourcePdf.getNumberOfPages());
//Add pages from the second pdf document
PdfDocument secondSourcePdf = new PdfDocument(new PdfReader(SRC2));
merger.addPages(secondSourcePdf, 1, secondSourcePdf.getNumberOfPages());
//Merge
merger.merge();
//Close the documents
firstSourcePdf.close();
secondSourcePdf.
Dans l'ensemble, ce code peut être considéré comme très similaire à l'exemple précédent:
- Les lignes 1 à 11 ne sont pas mentionnées, il n'y a aucune différence avec le code précédent.
- Les lignes 12 à 25 sont mentionnées dans l'exemple d'épissage de prix Oscar du chapitre précédent. Lors de la création
PdfMerger, nous passons unPdfADocumentobjet, puisPdfMergerajoutons unPdfDocumenttype à cet objet . S'il s'agit d'unPdfADocumenttype, le document sera vérifié. légalité.
Il y a encore de nombreuses discussions sur les normes PDF / UA et PDF / A. Bien sûr, il existe d'autres sous-normes. Par exemple, il existe une norme de prononciation allemande ZUGFeRD dans PDF / A-3, qui sera décrite dans d'autres séries (c'est le document officiel Ça dit dedans, personnellement, ça dépend des besoins, si j'ai le temps, j'ouvrirai cette fosse)
Pour résumer
Dans ce chapitre, nous avons discuté de la création et de l'épissage de documents conformes à d'autres normes PDF, et appris à créer des documents PDF / UA et PDF / A. Cette série se termine ici. Bien sûr, nous avons besoin d'autres séries pour aller plus loin. En savoir plus sur iText7.
C'est la fin des notes d'étude d'itext7, mais itext7 produira également d'autres séries, telles que les notes d'étude et les séries de discussions actuelles d'itext7, et il existe de nombreux exemples et articles sur le site officiel d'itext7. En même temps, je porterai plus d'attention au format et au contenu des articles. Continuez à vous améliorer, continuez à soutenir ma série itext7, après avoir lu l'article, n'oubliez pas de suivre et d'aimer une vague ~