1. Données de séries chronologiques et leurs caractéristiques
Les données de séries chronologiques sont une série de données de surveillance d'indicateurs qui sont générées en continu sur la base d'une fréquence relativement stable, comme l'indice Dow Jones sur un an, la température mesurée à différents moments d'une journée, etc. Les données de séries chronologiques présentent les caractéristiques suivantes :
- Invariance des données historiques
- Disponibilité des données
- Actualité des données
- données structurées
- volume de données
Deuxièmement, la structure de base de la base de données de séries chronologiques
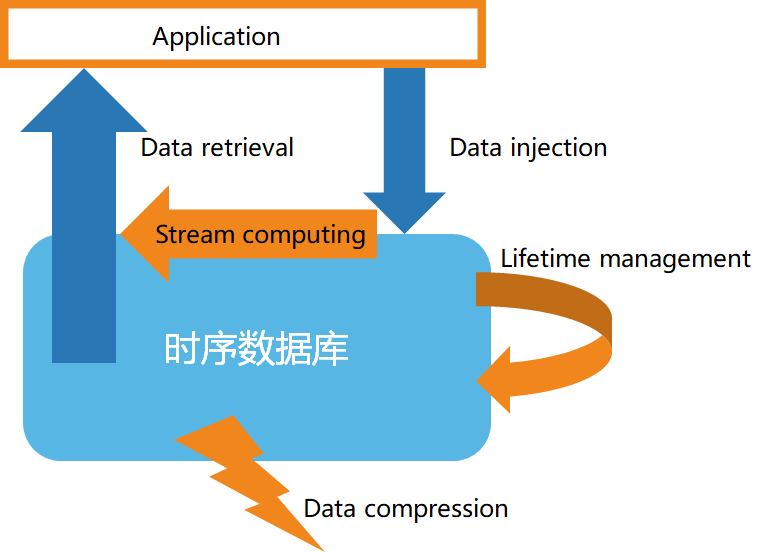
Selon les caractéristiques des données de séries chronologiques, les bases de données de séries chronologiques présentent généralement les caractéristiques suivantes :
- Stockage de données à grande vitesse
- Gestion du cycle de vie des données
- Traitement de flux de données
- Interrogation efficace des données
- Compression de données personnalisée
3. Introduction au Stream Computing
L'informatique de flux fait principalement référence à l'acquisition en temps réel de données massives à partir de différentes sources de données, ainsi qu'à l'analyse et au traitement en temps réel pour obtenir des informations précieuses. Les scénarios commerciaux courants incluent une réponse rapide aux événements en temps réel, des alarmes en temps réel pour les changements du marché, une analyse interactive des données en temps réel, etc. Le Stream Computing comprend généralement les fonctions suivantes :
1) Filtrage et conversion (filtre & carte)
2) Fonctions d'agrégation et de fenêtrage (reduce, aggregation/window)
3) Fusion de plusieurs flux de données et correspondance de modèles (regroupement et détection de modèles)
4) Du flux au traitement des blocs
4. Prise en charge de la base de données de séries chronologiques pour le calcul de flux
-
Cas 1 : utilisez une API de calcul de flux personnalisée, comme illustré dans l'exemple suivant :
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
-
Cas 2 : Utilisez des instructions de type SQL pour créer le calcul de flux et définir des règles de calcul de flux, comme suit :
CREATE STREAM current_stream
TRIGGER AT_ONCE
INTO current_stream_output_stb AS
SELECT
_wstart as start,
_wend as end,
max(current) as max_current
FROM meters
WHERE voltage <= 220
INTEVAL (5S) SLIDING (1s);