Pour des échanges plus techniques et des opportunités de recherche d'emploi, veuillez prêter attention au compte officiel WeChat de ByteDance Data Platform, et répondre [1] pour entrer dans le groupe d'échange officiel
ByteHouse est un entrepôt de données cloud natif sur Volcano Engine, qui offre aux utilisateurs une expérience d'analyse extrêmement rapide et peut prendre en charge l'analyse de données en temps réel et l'analyse massive de données hors ligne ; capacités d'expansion et de contraction élastiques pratiques, performances d'analyse extrêmes et fonctionnalités riches au niveau de l'entreprise , pour accompagner la transformation digitale des clients.
Cet article présentera l'évolution de la technologie d'importation en temps réel ByteHouse basée sur différentes architectures du point de vue de la motivation de la demande, de la mise en œuvre de la technologie et de l'application pratique.
Exigences d'importation en temps réel des affaires internes
La motivation pour l'évolution de la technologie d'importation en temps réel de ByteHouse est née des besoins des activités internes de ByteDance.
À l'intérieur de Byte, ByteHouse utilise principalement Kafka comme principale source de données pour l'importation en temps réel ( cet article utilise l'importation Kafka comme exemple pour développer la description, qui ne sera pas répétée ci-dessous ). Pour la plupart des utilisateurs internes, le volume de données est relativement important ; par conséquent, les utilisateurs accordent plus d'attention aux performances de l'importation de données, à la stabilité des services et à l'évolutivité des capacités d'importation. Quant à la latence des données, la plupart des utilisateurs peuvent répondre à leurs besoins tant qu'elle est visible en quelques secondes. Sur la base d'un tel scénario, ByteHouse a réalisé une optimisation personnalisée.
Haute disponibilité sous architecture distribuée

Architecture distribuée native de la communauté
ByteHouse a d'abord suivi l'architecture distribuée de la communauté Clickhouse, mais l'architecture distribuée présente quelques défauts architecturaux naturels.Ces points douloureux se manifestent principalement sous trois aspects :
-
Panne de nœud : lorsque le nombre de machines du cluster atteint une certaine échelle, il est nécessaire de gérer manuellement les pannes de nœud chaque semaine. Pour les clusters à copie unique, dans certains cas extrêmes, la défaillance d'un nœud peut même entraîner une perte de données.
-
Conflits de lecture-écriture : en raison du couplage lecture-écriture de l'architecture distribuée, lorsque la charge du cluster atteint un certain niveau, des conflits de ressources se produiront dans les requêtes des utilisateurs et les importations en temps réel, en particulier le CPU et les E/S, les importations seront affectées, et un décalage de consommation se produira.
-
Coût d'extension : étant donné que les données de l'architecture distribuée sont essentiellement stockées localement, les données ne peuvent pas être réorganisées après l'extension. La machine nouvellement étendue n'a presque pas de données et le disque de l'ancienne machine peut être presque plein, ce qui entraîne un cluster inégal. charge. , conduisant à l'expansion ne peut pas jouer un effet efficace.
Ce sont les points faibles naturels de l'architecture distribuée, mais en raison de ses caractéristiques de concurrence naturelle et de l'optimisation extrême des performances de lecture et d'écriture de données sur disque local, on peut dire qu'il existe des avantages et des inconvénients.
Conception d'importation communautaire en temps réel
-
Mode de consommation de haut niveau : s'appuyer sur le propre mécanisme de rééquilibrage de Kafka pour l'équilibrage de la charge de consommation.
-
deux niveaux de concurrence
La conception du noyau d'importation en temps réel basée sur une architecture distribuée est en fait une simultanéité à deux niveaux :
Un cluster CH a généralement plusieurs fragments, et chaque fragment consommera et importera simultanément, ce qui correspond à la simultanéité multi-processus entre les fragments de premier niveau ;
Chaque partition peut également utiliser plusieurs threads pour consommer simultanément, afin d'obtenir un débit de haute performance.
-
Ecrire par lots
En ce qui concerne un seul thread, le mode de consommation de base consiste à écrire par lots - consommez une certaine quantité de données ou écrivez-les immédiatement après un certain laps de temps. L'écriture par lots peut mieux optimiser les performances, améliorer les performances des requêtes et réduire la pression sur le thread de fusion en arrière-plan.
besoins non satisfaits
La conception et la mise en œuvre des communautés ci-dessus ne peuvent toujours pas répondre à certains besoins avancés des utilisateurs :
-
Tout d'abord, certains utilisateurs avancés ont des exigences relativement strictes sur la distribution des données. Par exemple, ils ont des clés spécifiques pour certaines données spécifiques et espèrent que les données avec la même clé seront placées sur le même fragment (comme les exigences de clé unique). Dans ce cas, le modèle de consommation de la communauté High Level ne peut être satisfait.
-
Deuxièmement, le rééquilibrage du formulaire de consommation de haut niveau est incontrôlable, ce qui peut éventuellement conduire à une répartition inégale des données importées dans le cluster Clickhouse entre les différentes partitions.
-
Bien sûr, l'allocation des tâches de consommation est inconnue et, dans certains scénarios de consommation anormale, il devient très difficile de résoudre les problèmes ; cela est inacceptable pour une application au niveau de l'entreprise.
Moteur de consommation d'architecture distribuée auto-développé HaKafka
Afin de répondre aux exigences ci-dessus, l'équipe ByteHouse a développé un moteur de consommation basé sur l'architecture distribuée - HaKafka.
Haute disponibilité (Ha)
HaKafka hérite des avantages de consommation du moteur de table Kafka d'origine dans la communauté, puis se concentre sur l'optimisation Ha haute disponibilité.
En ce qui concerne l'architecture distribuée, en fait, il peut y avoir plusieurs copies dans chaque partition, et des tables HaKafka peuvent être créées sur chaque copie. Mais ByteHouse sélectionnera uniquement un leader via ZK, laissera le leader exécuter réellement le processus de consommation, et les autres nœuds seront dans l'état Stand by. Lorsque le nœud Leader est indisponible, ZK peut basculer le Leader vers le nœud Stand by en quelques secondes pour continuer la consommation, obtenant ainsi une haute disponibilité.
Faible—Mode de consommation de niveau
Le mode de consommation de HaKafka a été ajusté de haut niveau à bas niveau. Le mode de bas niveau peut garantir que les partitions thématiques sont distribuées à chaque partition du cluster de manière ordonnée et uniforme ; en même temps, le multi-threading peut à nouveau être utilisé à l'intérieur de la partition, permettant à chaque thread de consommer différentes partitions. Ainsi, il hérite pleinement des avantages de la concurrence à deux niveaux du moteur de table communautaire Kafka.
En mode de consommation de bas niveau, tant que les utilisateurs en amont s'assurent qu'il n'y a pas de biais de données lors de l'écriture dans le sujet, les données importées dans Clickhouse via HaKafka doivent être réparties uniformément entre les fragments.
En même temps, pour les utilisateurs avancés qui ont des exigences particulières en matière de distribution de données - écrire les données de la même clé sur le même fragment - tant que l'amont s'assure que les données de la même clé sont écrites sur la même partition, puis importez ByteHouse peut répondre pleinement aux besoins de l'utilisateur, et il est très facile de prendre en charge des scénarios tels que des clés uniques.
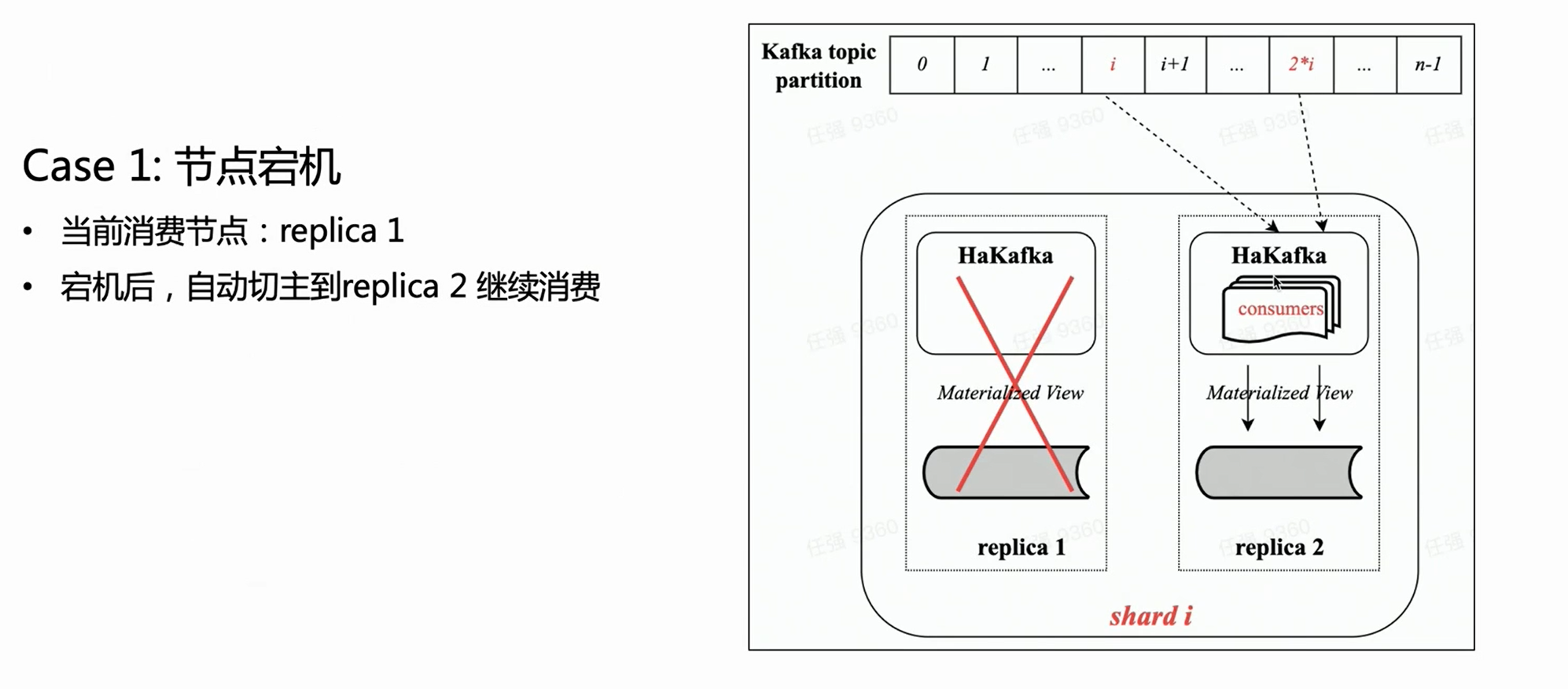
première scène :
Sur la base de la figure ci-dessus, en supposant qu'il existe une partition avec deux copies, chaque copie aura la même table HaKafka à l'état Prêt. Mais uniquement sur le nœud leader qui a réussi à élire le leader via ZK, HaKafka exécutera le processus de consommation correspondant. Lorsque le nœud leader tombe en panne, la réplique Replica 2 sera automatiquement réélue en tant que nouveau leader pour continuer la consommation, garantissant ainsi une haute disponibilité.
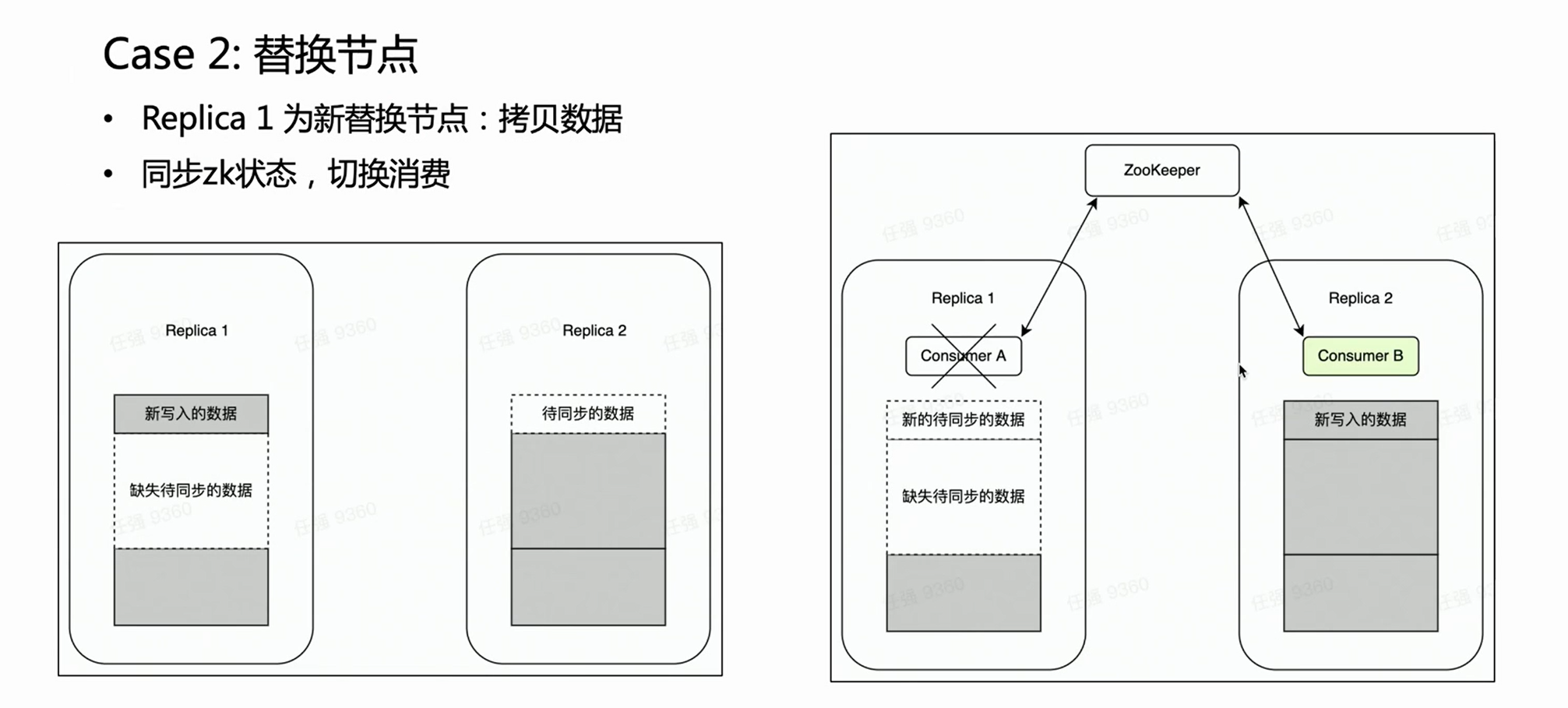
Scène deux :
Dans le cas d'une panne de nœud, il est généralement nécessaire d'effectuer le processus de remplacement du nœud. Il y a une opération très lourde pour le remplacement de nœud distribué - la copie de données.
S'il s'agit d'un cluster multi-réplica, une copie échoue et l'autre copie est intacte. Nous espérons naturellement que pendant la phase de remplacement du nœud, la consommation de Kafka est placée sur la réplique intacte Replica 2, car les anciennes données sur celle-ci sont complètes. De cette façon, la réplique 2 est toujours un ensemble de données complet et peut normalement fournir des services externes. HaKafka peut le garantir. Lorsque HaKafka élit le leader, s'il est déterminé qu'un certain nœud est en train de remplacer le nœud, il évitera d'être sélectionné comme leader.
Optimisation des performances d'importation : table de mémoire
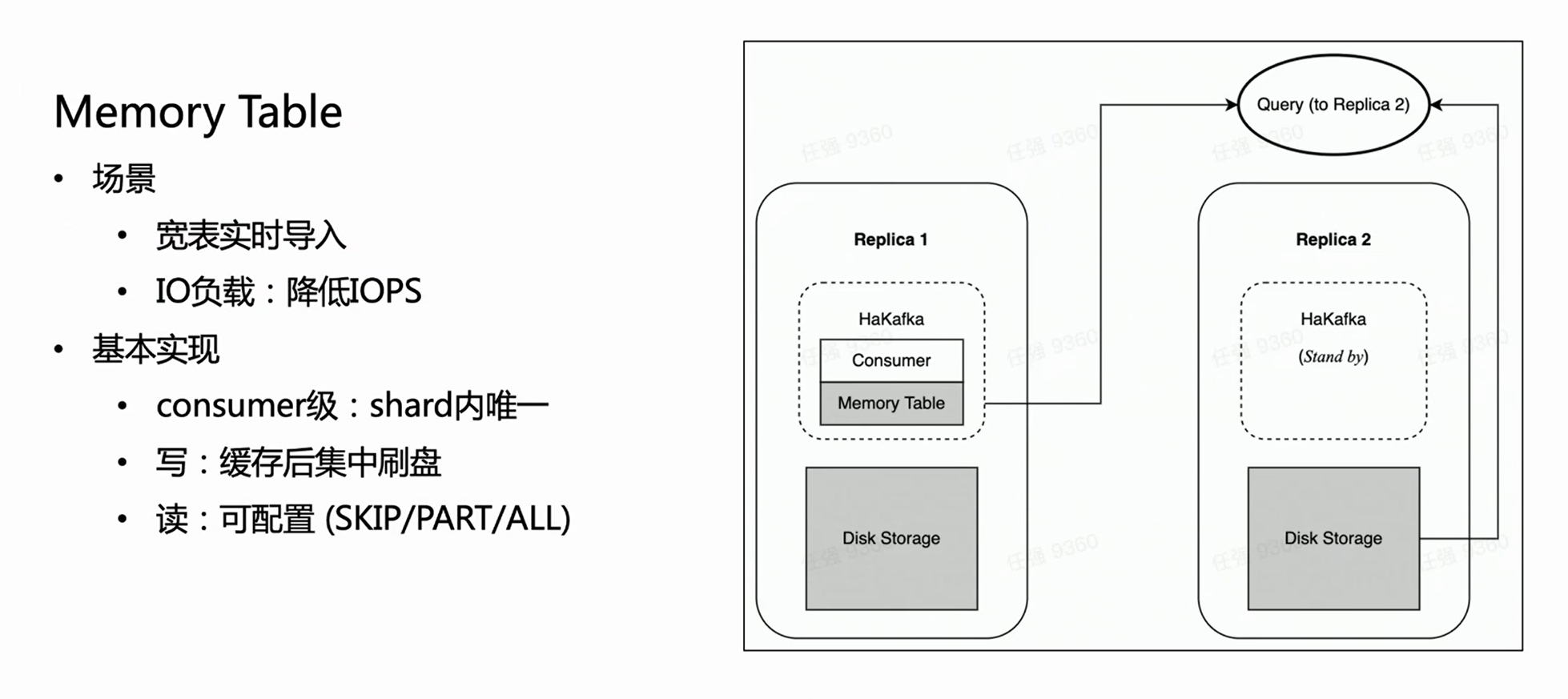
HaKafka optimise également la table de mémoire.
Considérez un tel scénario : l'entreprise dispose d'une grande et large table, qui peut avoir des centaines de champs ou des milliers de Map-Keys. Étant donné que chaque colonne de ClickHouse correspondra à un fichier spécifique, plus il y a de colonnes, plus il y aura de fichiers écrits pour chaque importation. Ensuite, dans le même temps de consommation, beaucoup de fichiers fragmentés seront écrits fréquemment, ce qui est un lourd fardeau pour les E/S de la machine, et en même temps met beaucoup de pression sur MERGE ; dans les cas graves, cela peut même rendre le cluster indisponible. Afin de résoudre ce scénario, nous avons conçu Memory Table pour optimiser les performances d'importation.
La méthode de Memory Table est qu'à chaque fois les données importées ne sont pas directement flashées, mais stockées dans la mémoire ; lorsque les données atteignent une certaine quantité, elles sont alors concentrées sur le disque pour réduire les opérations d'E/S. La table mémoire peut fournir un service de requête externe, et la requête sera acheminée vers la copie où se trouve le nœud consommateur pour lire les données dans la table mémoire, ce qui garantit que le délai d'importation des données n'est pas affecté. D'après l'expérience interne, Memory Table répond non seulement à certaines exigences d'importation professionnelles de tables volumineuses et larges, mais améliore également les performances d'importation jusqu'à 3 fois.
Nouvelle architecture cloud native
Compte tenu des défauts naturels de l'architecture distribuée décrits ci-dessus, l'équipe ByteHouse a travaillé sur la mise à niveau de l'architecture. Nous avons choisi l'architecture cloud-native qui est le courant dominant de l'entreprise.La nouvelle architecture commencera à servir les activités internes de Byte au début de 2021, et le code open source (ByConity) au début de 2023.
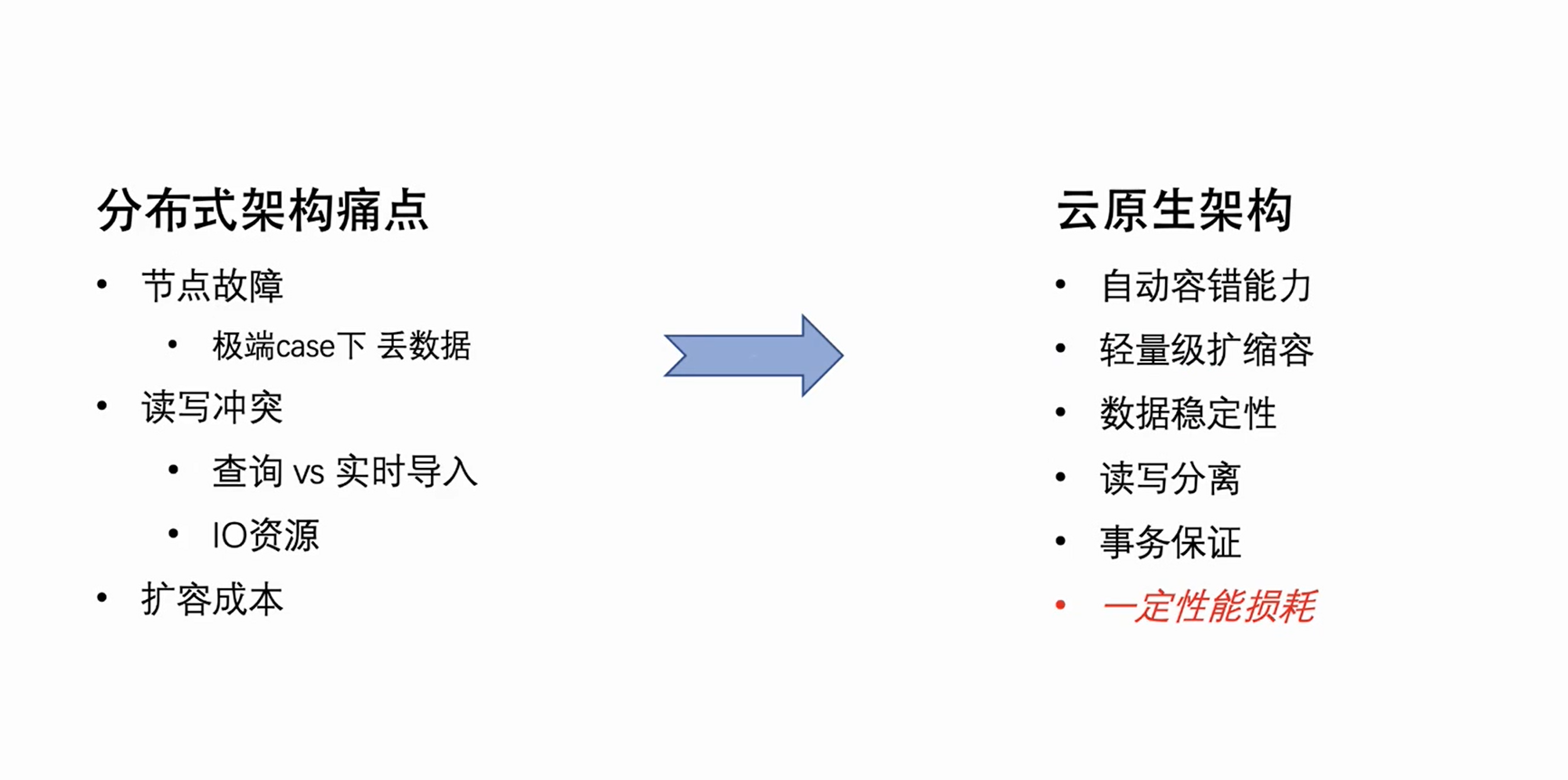
L'architecture cloud native elle-même a une tolérance aux pannes automatique naturelle et des capacités de mise à l'échelle légères. Dans le même temps, comme ses données sont stockées dans le cloud, il réalise non seulement la séparation du stockage et de l'informatique, mais améliore également la sécurité et la stabilité des données. Bien entendu, l'architecture cloud-native n'est pas sans défauts : changer la lecture et l'écriture locale d'origine en lecture et écriture à distance entraînera inévitablement une certaine perte de performances en lecture et en écriture. Cependant, échanger une certaine perte de performance contre la rationalité de l'architecture et réduire les coûts d'exploitation et de maintenance l'emportent en fait sur les inconvénients.
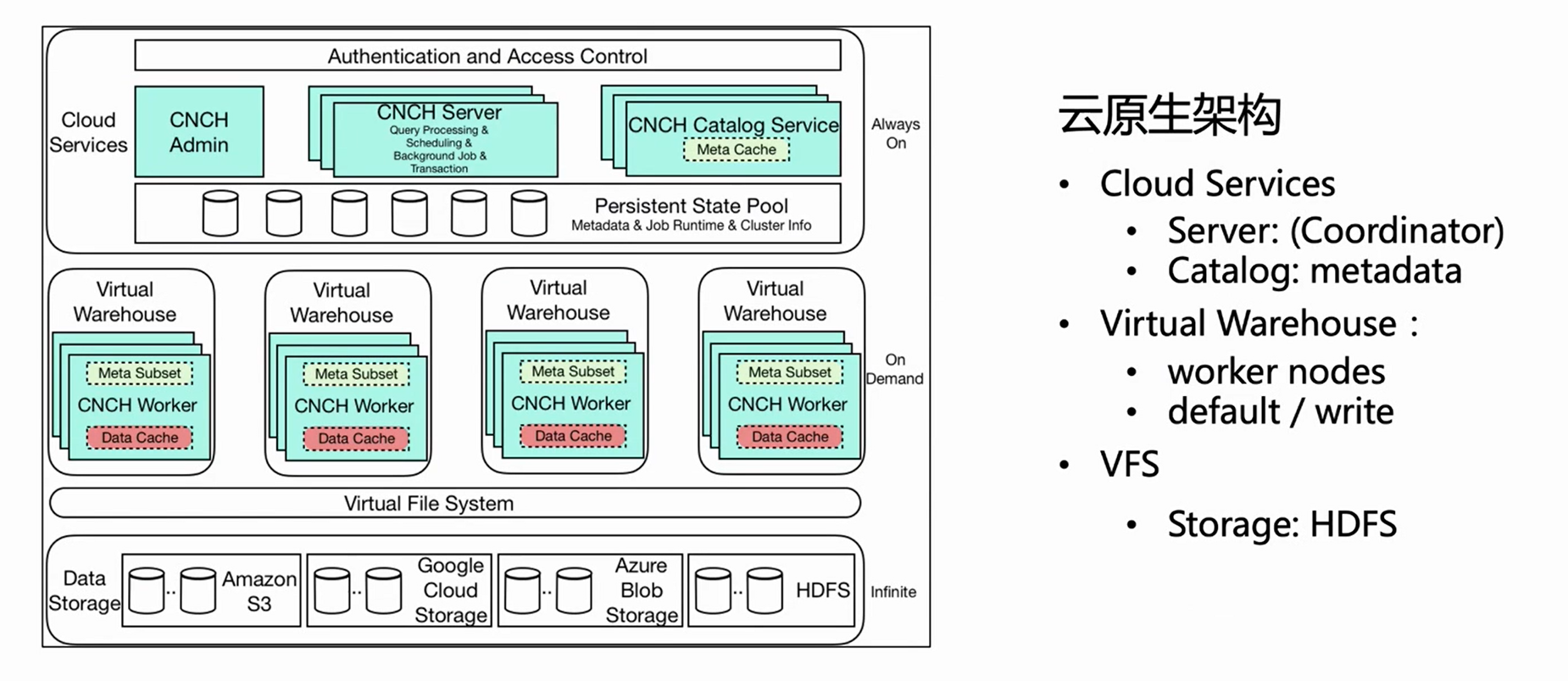
L'image ci-dessus est le diagramme d'architecture de l'architecture native du cloud de ByteHouse Cet article présente plusieurs composants connexes importants pour l'importation en temps réel.
-
Service cloud
Tout d'abord, l'architecture globale est divisée en trois couches.La première couche est Cloud Service, qui comprend principalement deux composants, Server et Catlog. Cette couche est l'entrée de service, et toutes les demandes des utilisateurs, y compris les importations de requêtes, entrent à partir du serveur. Le serveur ne fait que prétraiter la demande, mais ne l'exécute pas ; une fois que le Catlog a interrogé les méta-informations, il envoie la demande prétraitée et les méta-informations à l'entrepôt virtuel pour exécution.
-
Entrepôt virtuel
Virtual Warehouse est la couche d'exécution. Différentes entreprises peuvent avoir des entrepôts virtuels indépendants pour isoler les ressources. Désormais, Virtual Warehouse est principalement divisé en deux catégories, l'une par défaut et l'autre par écriture. La valeur par défaut est principalement utilisée pour les requêtes et l'écriture est utilisée pour l'importation afin de réaliser la séparation de la lecture et de l'écriture.
-
VFS
La couche inférieure est VFS (stockage de données), qui prend en charge les composants de stockage cloud tels que HDFS, S3 et aws.
Conception d'importation en temps réel basée sur l'architecture cloud native
Dans l'architecture cloud native, le serveur n'effectue pas d'exécution d'importation spécifique, mais gère uniquement les tâches. Par conséquent, côté serveur, chaque table de consommation aura un gestionnaire pour gérer toutes les tâches d'exécution de consommation et planifier leur exécution sur l'entrepôt virtuel.
Parce qu'il hérite du mode de consommation de bas niveau de HaKafka, le gestionnaire distribuera uniformément les partitions de sujet à chaque tâche en fonction du nombre configuré de tâches de consommation ; le nombre de tâches de consommation est configurable et la limite supérieure est le nombre de partitions de sujet.
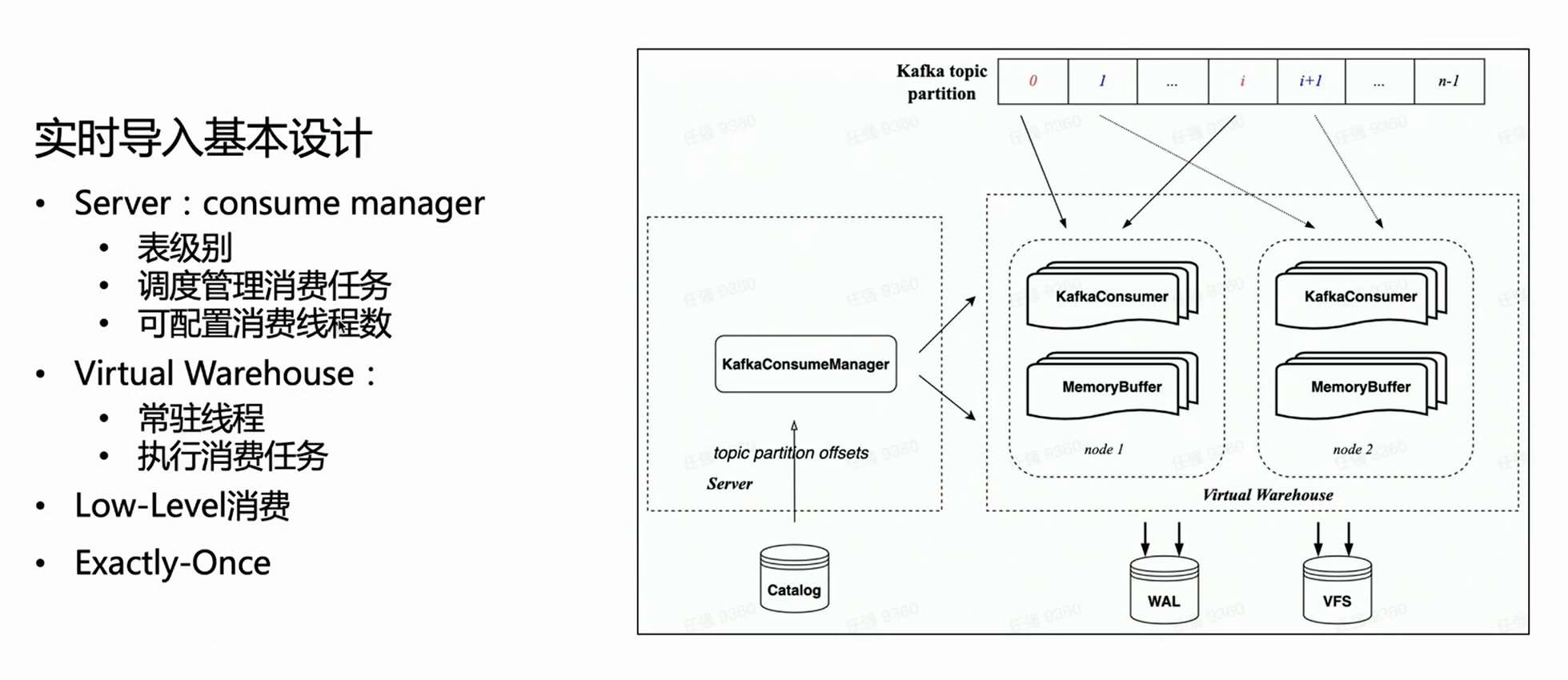
Sur la base de la figure ci-dessus, vous pouvez voir que le gestionnaire de gauche obtient le décalage correspondant à partir du catalogue, puis alloue la partition de consommation correspondante en fonction du nombre spécifié de tâches de consommation et les planifie sur différents nœuds de l'entrepôt virtuel pour exécution.
Nouveau processus d'exécution de la consommation
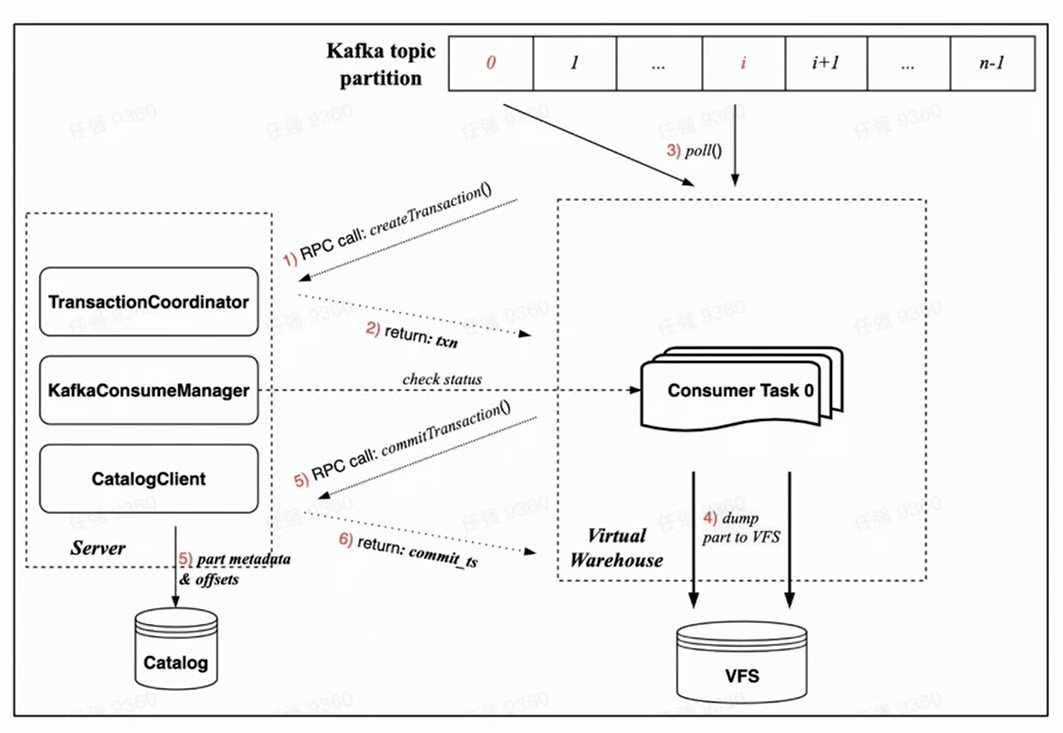
Étant donné que la nouvelle architecture cloud native est garantie par Transaction, toutes les opérations doivent être réalisées en une seule transaction, ce qui est plus rationnel.
S'appuyant sur l'implémentation de Transaction sous la nouvelle architecture cloud-native, le processus de consommation de chaque tâche de consommation comprend principalement les étapes suivantes :
-
Avant le début de la consommation, la tâche du côté Worker demandera d'abord au côté Server de créer une transaction via une requête RPC ;
-
Exécutez rdkafka::poll() pour consommer un certain temps (8s par défaut) ou un bloc de taille suffisante ;
-
Convertir le bloc en partie et le vider en VFS ( les données ne sont pas visibles pour le moment ) ;
-
Initier une demande de validation de transaction au serveur via une demande RPC
(Les données de validation dans la transaction incluent : le vidage des métadonnées de la partie terminée et le décalage Kafka correspondant)
-
La transaction est validée avec succès ( les données sont visibles )
garantie de tolérance aux pannes
D'après le processus de consommation ci-dessus, nous pouvons voir que la garantie de consommation tolérante aux pannes dans le cadre de la nouvelle architecture cloud native est principalement basée sur le rythme cardiaque bidirectionnel de Manager et Task et sur la stratégie de défaillance rapide :
-
Le gestionnaire lui-même effectuera une vérification régulière et vérifiera si la tâche planifiée est exécutée normalement via RPC ;
-
Dans le même temps, chaque tâche utilisera la requête RPC de la transaction pour vérifier sa validité lors de la consommation.Une fois la vérification échouée, elle peut être automatiquement tuée ;
-
Une fois que le gestionnaire ne parvient pas à détecter la vivacité, il démarre immédiatement une nouvelle tâche de consommation pour obtenir une garantie de tolérance aux pannes de deuxième niveau.
Pouvoir d'achat
Quant à la capacité de consommation, il est mentionné plus haut qu'elle est évolutive, et le nombre de tâches de consommation peut être configuré par l'utilisateur, jusqu'au nombre de Partitions du Topic. Si la charge de nœud dans l'entrepôt virtuel est élevée, le nœud peut également être étendu très légèrement.
Bien sûr, la tâche de planification du gestionnaire implémente la garantie d'équilibrage de charge de base - utilisez Resource Manager pour gérer et planifier les tâches.
Amélioration sémantique : Exactement—Une fois
Enfin, la sémantique de consommation sous la nouvelle architecture cloud-native a également été améliorée, de l'At-Least-Once de l'architecture du livre distribué à Exactly-Once.
Étant donné que l'architecture distribuée n'a pas de transactions, elle ne peut atteindre qu'au moins une fois, ce qui signifie qu'aucune donnée ne sera perdue en aucune circonstance, mais dans certains cas extrêmes, une consommation répétée peut se produire. Dans l'architecture cloud-native, grâce à la mise en œuvre de Transaction, chaque consommation peut faire en sorte que Part et Offset soient validés de manière atomique via des transactions, de manière à obtenir l'amélioration sémantique d'Exactly-Once.
Mémoire tampon
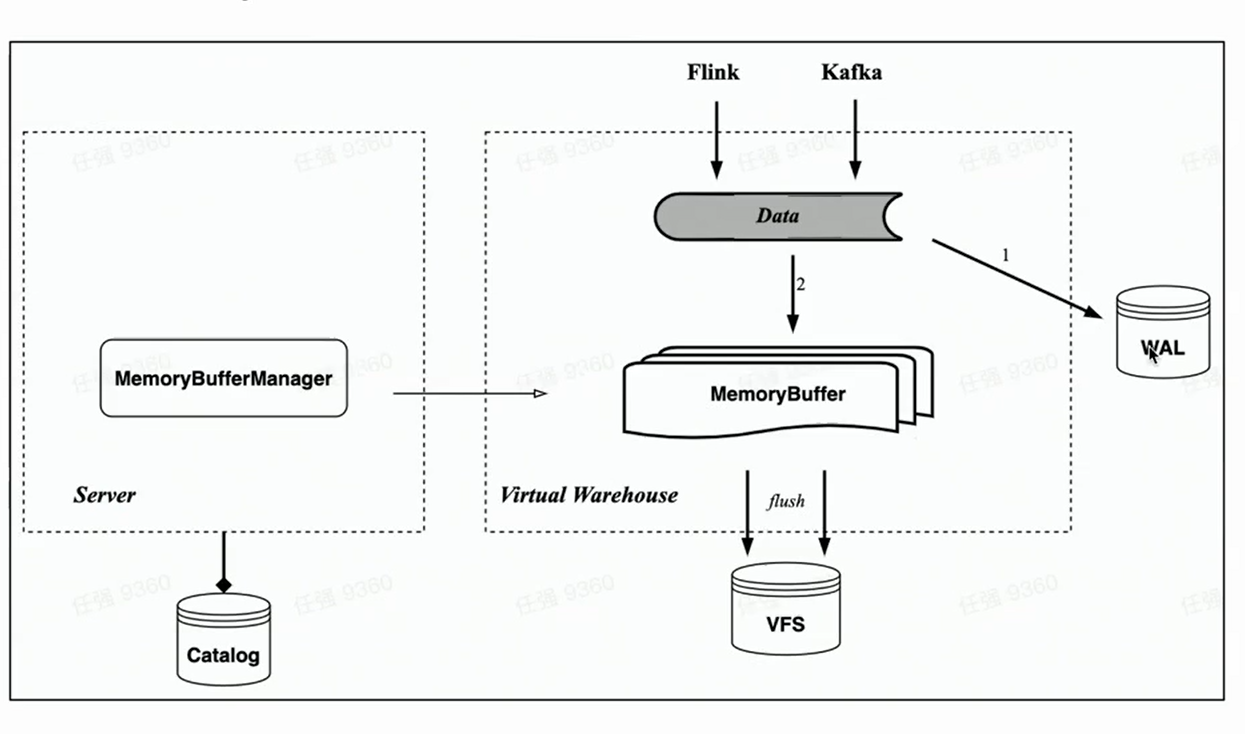
Correspondant à la table mémoire de HaKafka, l'architecture cloud native implémente également l'import du cache mémoire Memory Buffer.
Contrairement à Memory Table, Memory Buffer n'est plus lié aux tâches de consommation de Kafka, mais est implémenté comme une couche de cache pour les tables de stockage. De cette manière, Memory Buffer est plus polyvalent et peut être utilisé non seulement pour l'importation Kafka, mais également pour l'importation de petits lots comme Flink.
Dans le même temps, nous avons introduit un nouveau composant WAL. Lorsque des données sont importées, écrivez d'abord WAL, tant que l'écriture est réussie, on peut considérer que l'importation de données est réussie - lorsque le service est démarré, vous pouvez d'abord restaurer les données qui n'ont pas été flashées depuis le WAL ; puis écrivez le tampon mémoire et les données seront visibles après l'écriture réussie ——Parce que le tampon mémoire peut être interrogé par les utilisateurs. Les données de la mémoire tampon sont également périodiquement vidées et peuvent être effacées du WAL après vidage.
Application métier et réflexion sur l'avenir
Enfin, il présente brièvement l'état actuel de l'importation en temps réel dans Byte et la direction d'optimisation possible de la technologie d'importation en temps réel de nouvelle génération.
La technologie d'importation en temps réel de ByteHouse est basée sur Kafka, le débit de données quotidien est au niveau du PB et la valeur d'expérience du débit d'un seul thread importé ou d'un seul consommateur est de 10 à 20 Mo/s. (La valeur empirique est soulignée ici, car cette valeur n'est pas une valeur fixe, ni une valeur de pointe ; le débit de consommation dépend largement de la complexité de la table utilisateur, à mesure que le nombre de colonnes de la table augmente, les performances d'importation peuvent être considérablement réduit, une formule de calcul précise ne peut pas être utilisée. Par conséquent, la valeur d'expérience ici est plus la valeur d'expérience de performance d'importation de la plupart des tables à l'intérieur de l'octet.)
En plus de Kafka, Byte prend en charge l'importation en temps réel de certaines autres sources de données, notamment RocketMQ, Pulsar, MySQL (MaterializedMySQL), l'écriture directe Flink, etc.
Réflexions simples sur la prochaine génération de technologie d'importation en temps réel :
-
Une technologie d'importation en temps réel plus générale permet aux utilisateurs de prendre en charge davantage de sources de données d'importation.
-
La visibilité des données est un compromis entre la latence et les performances.
Cliquez pour accéder à l'entrepôt de données natif du cloud ByteHouse pour en savoir plus