1. Descriptif
Dans la dernière histoire , nous avons couvert certains des aspects de codage les plus pertinents de l'apprentissage automatique, tels que la programmation fonctionnelle , la vectorisation et la programmation d'algèbre linéaire .
Dans cet article, commençons par implémenter un modèle pratique d'apprentissage en profondeur d'encodage utilisant des convolutions 2D. commençons.
2. À propos de cette série
Nous apprendrons à coder des algorithmes d'apprentissage en profondeur indispensables tels que les convolutions, la rétropropagation, les fonctions d'activation, les optimiseurs, les réseaux de neurones profonds, etc., en utilisant uniquement du C++ simple et moderne.

Découvrez d'autres histoires:
0 — Principes de base de la programmation d'apprentissage en profondeur C++ moderne
2 — Fonction de coût utilisant Lambda
3 - Mise en œuvre de la descente de gradient
... et bien d'autres à venir.
3. Convolution
La convolution est un vieil ami du domaine du traitement du signal. A l'origine, il était défini comme suit :

En termes d'apprentissage automatique :
- I (... souvent appelé entrée
- K(... comme noyau, et
- F(...) comme carte de caractéristiques de I(x) sachant K.
Considérant un domaine discret multidimensionnel, nous pouvons transformer l'intégrale en la sommation suivante :
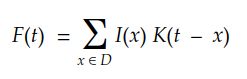
Enfin, pour les images numériques 2D, on peut réécrire ceci comme :

Une façon plus simple de comprendre la convolution est le diagramme suivant :
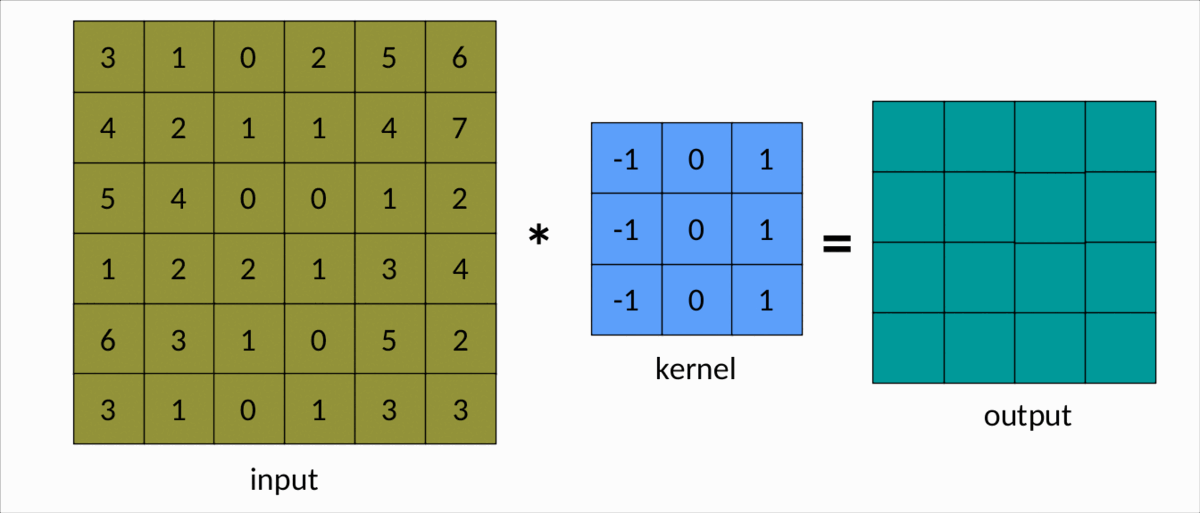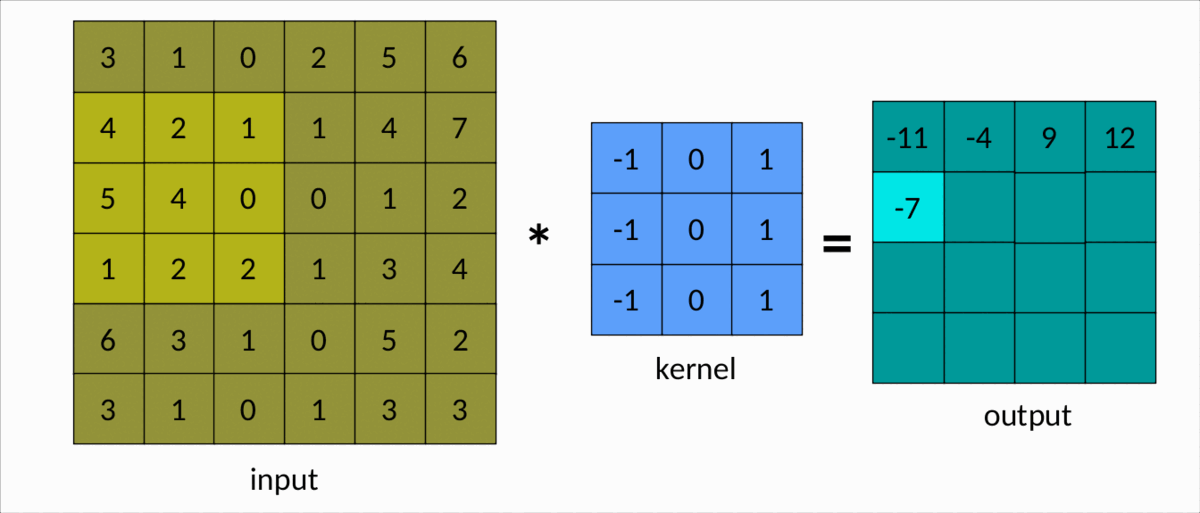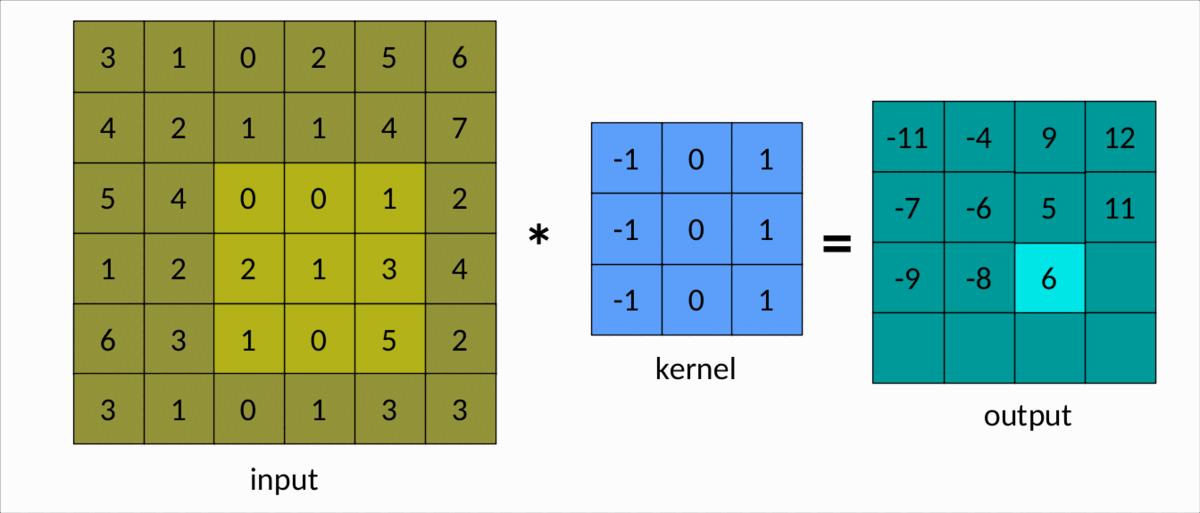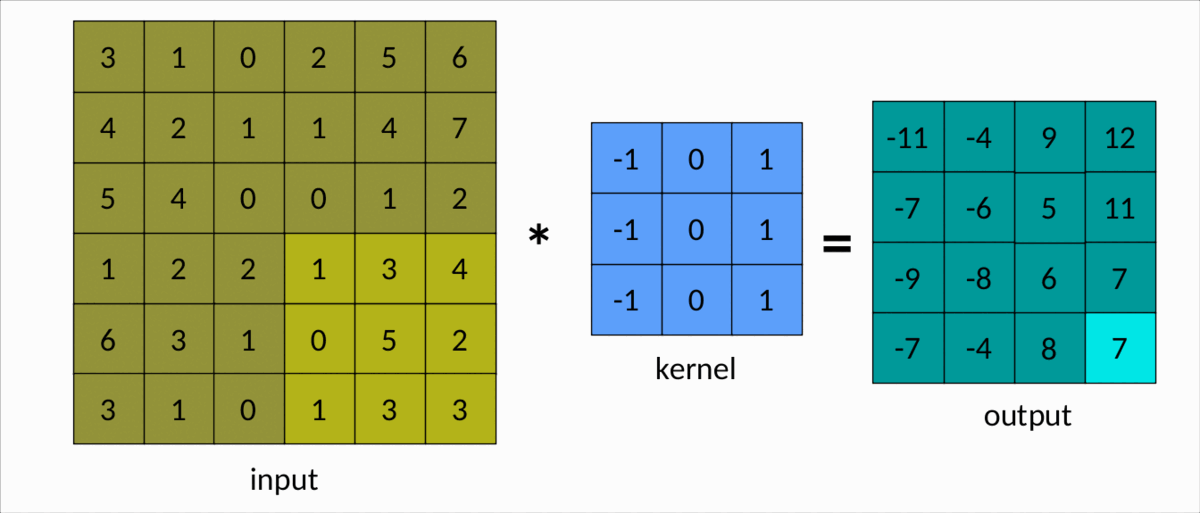
Nous pouvons facilement voir le noyau glisser sur la matrice d'entrée, produisant une autre matrice en sortie. Il s'agit d'un cas simple de convolution, appelé convolution efficace . Dans ce cas, les dimensions de la matrice sont données par :Output
dim(Output) = (m-k+1, n-k+1)
ici:
msont le nombre de lignes et de colonnes dans la matrice d'entrée, respectivement, etnkest la taille du noyau carré.
Maintenant, encodons notre première convolution 2D.
4. Encodage de convolutions 2D à l'aide de boucles
La façon la plus intuitive d'implémenter la convolution est d'utiliser une boucle :
auto Convolution2D = [](const Matrix &input, const Matrix &kernel)
{
const int kernel_rows = kernel.rows();
const int kernel_cols = kernel.cols();
const int rows = (input.rows() - kernel_rows) + 1;
const int cols = (input.cols() - kernel_cols) + 1;
Matrix result = Matrix::Zero(rows, cols);
for (int i = 0; i < rows; ++i)
{
for (int j = 0; j < cols; ++j)
{
double sum = input.block(i, j, kernel_rows, kernel_cols).cwiseProduct(kernel).sum();
result(i, j) = sum;
}
}
return result;
};Il n'y a pas de secrets ici. Nous glissons le noyau sur les colonnes et les lignes, en appliquant un produit interne pour chaque étape. Maintenant, nous pouvons simplement l'utiliser comme ceci :
#include <iostream>
#include <Eigen/Core>
using Matrix = Eigen::MatrixXd;
auto Convolution2D = ...;
int main(int, char **)
{
Matrix kernel(3, 3);
kernel <<
-1, 0, 1,
-1, 0, 1,
-1, 0, 1;
std::cout << "Kernel:\n" << kernel << "\n\n";
Matrix input(6, 6);
input << 3, 1, 0, 2, 5, 6,
4, 2, 1, 1, 4, 7,
5, 4, 0, 0, 1, 2,
1, 2, 2, 1, 3, 4,
6, 3, 1, 0, 5, 2,
3, 1, 0, 1, 3, 3;
std::cout << "Input:\n" << input << "\n\n";
auto output = Convolution2D(input, kernel);
std::cout << "Convolution:\n" << output << "\n";
return 0;
}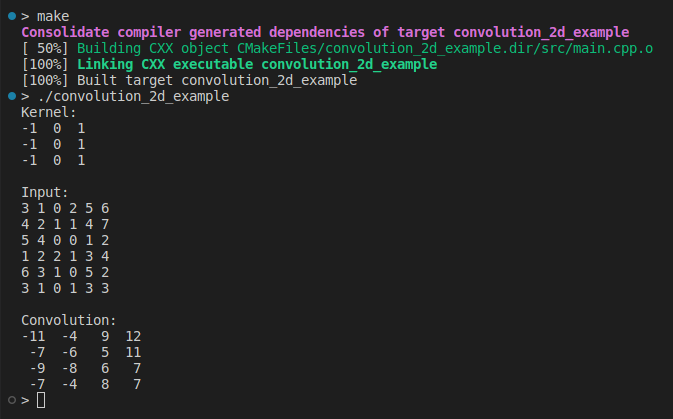
Il s'agit de notre première implémentation de la convolution en 2D, conçue pour être facile à comprendre. Pendant un certain temps, nous ne nous sommes pas souciés des performances ou de la validation des entrées. Passons à autre chose pour plus d'informations.
Dans la prochaine histoire, nous apprendrons comment implémenter la convolution à l'aide de Fast Fourier Transform et Toeplitz matrix .
5. Remplissage
Dans l'exemple précédent, nous avons remarqué que la matrice de sortie est toujours plus petite que la matrice d'entrée. Parfois, cette réduction est bonne et parfois mauvaise. Nous pouvons éviter cette réduction en ajoutant du padding autour de la matrice d'entrée :

Image d'entrée remplie avec 1
Le résultat du rembourrage dans la convolution ressemble à ceci :
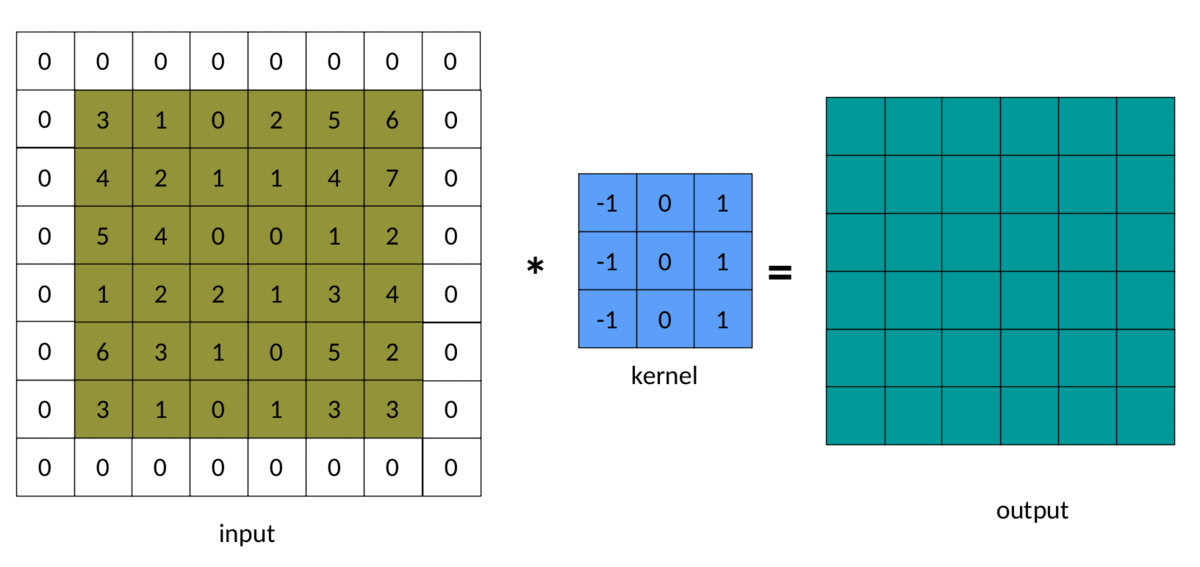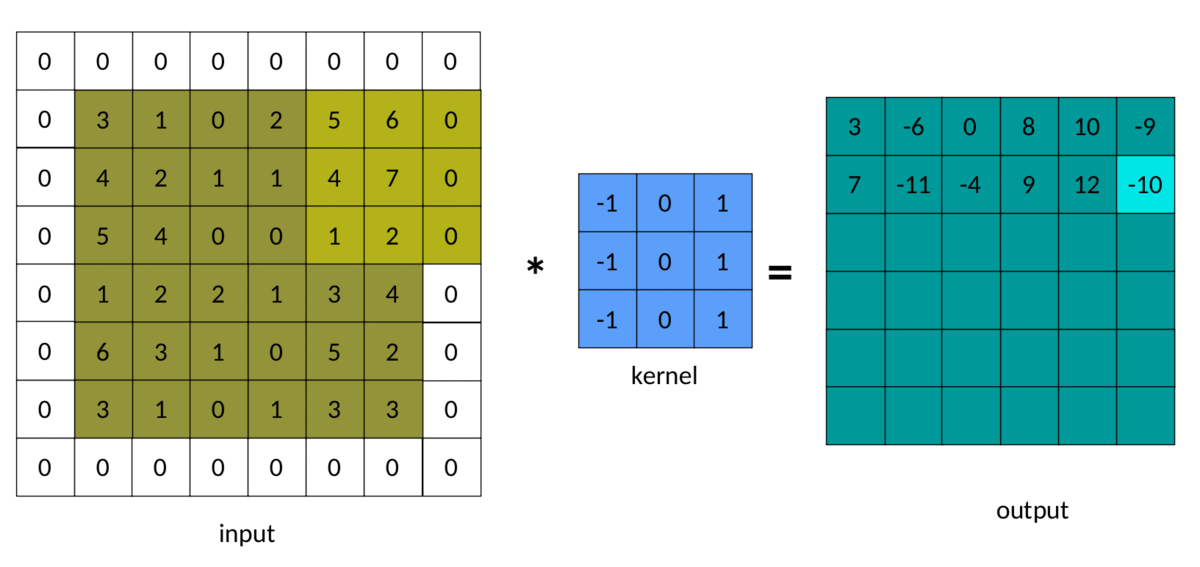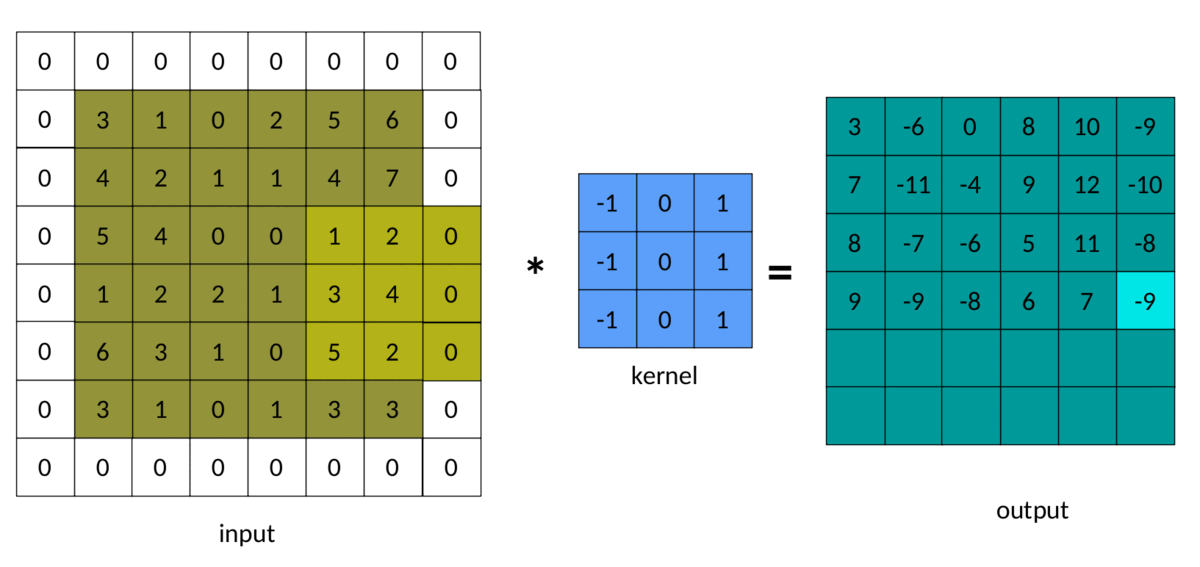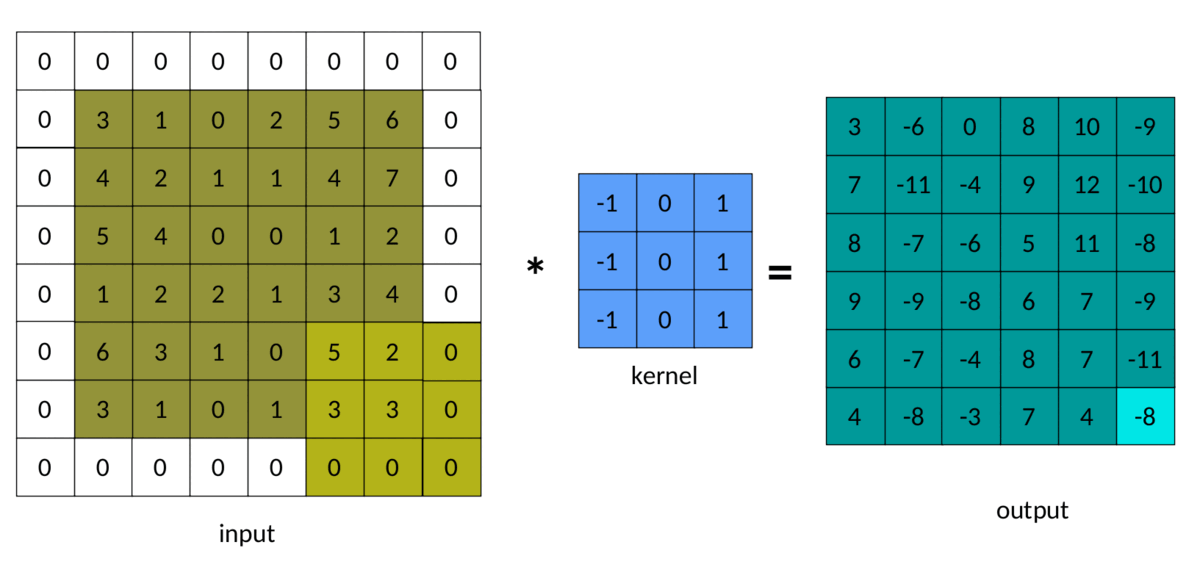
Convolution rembourrée — Image de l'auteur
Une manière simple (et brutale) d'implémenter une convolution rembourrée est la suivante :
auto Convolution2D = [](const Matrix &input, const Matrix &kernel, int padding)
{
int kernel_rows = kernel.rows();
int kernel_cols = kernel.cols();
int rows = input.rows() - kernel_rows + 2*padding + 1;
int cols = input.cols() - kernel_cols + 2*padding + 1;
Matrix padded = Matrix::Zero(input.rows() + 2*padding, input.cols() + 2*padding);
padded.block(padding, padding, input.rows(), input.cols()) = input;
Matrix result = Matrix::Zero(rows, cols);
for(int i = 0; i < rows; ++i)
{
for(int j = 0; j < cols; ++j)
{
double sum = padded.block(i, j, kernel_rows, kernel_cols).cwiseProduct(kernel).sum();
result(i, j) = sum;
}
}
return result;
};Ce code est simple, mais très coûteux en termes d'utilisation de la mémoire. Notez que nous faisons une copie complète de la matrice d'entrée pour créer une version rembourrée :
Matrix padded = Matrix::Zero(input.rows() + 2*padding, input.cols() + 2*padding);
padded.block(padding, padding, input.rows(), input.cols()) = input;Une meilleure solution pourrait utiliser des pointeurs pour contrôler les limites des tranches et du noyau :
auto Convolution2D_v2 = [](const Matrix &input, const Matrix &kernel, int padding)
{
const int input_rows = input.rows();
const int input_cols = input.cols();
const int kernel_rows = kernel.rows();
const int kernel_cols = kernel.cols();
if (input_rows < kernel_rows) throw std::invalid_argument("The input has less rows than the kernel");
if (input_cols < kernel_cols) throw std::invalid_argument("The input has less columns than the kernel");
const int rows = input_rows - kernel_rows + 2*padding + 1;
const int cols = input_cols - kernel_cols + 2*padding + 1;
Matrix result = Matrix::Zero(rows, cols);
auto fit_dims = [&padding](int pos, int k, int length)
{
int input = pos - padding;
int kernel = 0;
int size = k;
if (input < 0)
{
kernel = -input;
size += input;
input = 0;
}
if (input + size > length)
{
size = length - input;
}
return std::make_tuple(input, kernel, size);
};
for(int i = 0; i < rows; ++i)
{
const auto [input_i, kernel_i, size_i] = fit_dims(i, kernel_rows, input_rows);
for(int j = 0; size_i > 0 && j < cols; ++j)
{
const auto [input_j, kernel_j, size_j] = fit_dims(j, kernel_cols, input_cols);
if (size_j > 0)
{
auto input_tile = input.block(input_i, input_j, size_i, size_j);
auto input_kernel = kernel.block(kernel_i, kernel_j, size_i, size_j);
result(i, j) = input_tile.cwiseProduct(input_kernel).sum();
}
}
}
return result;
}; Ce nouveau code est bien meilleur car ici nous n'allouons pas de mémoire temporaire pour contenir l'entrée peuplée. Cependant, il peut encore être amélioré. Les coûts d'appel et de mémoire sont également élevés.input.block(…)kernel.block(…)
Une solution aux appels consiste à les remplacer par CwiseNullaryOp .
block(…)
Nous pouvons exécuter une convolution rembourrée de la manière suivante :
#include <iostream>
#include <Eigen/Core>
using Matrix = Eigen::MatrixXd;
auto Convolution2D = ...; // or Convolution2D_v2
int main(int, char **)
{
Matrix kernel(3, 3);
kernel <<
-1, 0, 1,
-1, 0, 1,
-1, 0, 1;
std::cout << "Kernel:\n" << kernel << "\n\n";
Matrix input(6, 6);
input <<
3, 1, 0, 2, 5, 6,
4, 2, 1, 1, 4, 7,
5, 4, 0, 0, 1, 2,
1, 2, 2, 1, 3, 4,
6, 3, 1, 0, 5, 2,
3, 1, 0, 1, 3, 3;
std::cout << "Input:\n" << input << "\n\n";
const int padding = 1;
auto output = Convolution2D(input, kernel, padding);
std::cout << "Convolution:\n" << output << "\n";
return 0;
}
Notez que maintenant, les matrices d'entrée et de sortie ont les mêmes dimensions. Par conséquent, cela s'appelle le rembourrage. Le mode de remplissage par défaut, qui est sans remplissage, est souvent appelé remplissage. Notre code autorise , ou tout rembourrage non négatif.samevalidsamevalid
6. Noyau
Dans les modèles d'apprentissage en profondeur, le noyau est généralement une matrice d'ordre impair, telle que , , etc. Certains noyaux sont très connus, comme le filtre de Sobel :3x35x511x11
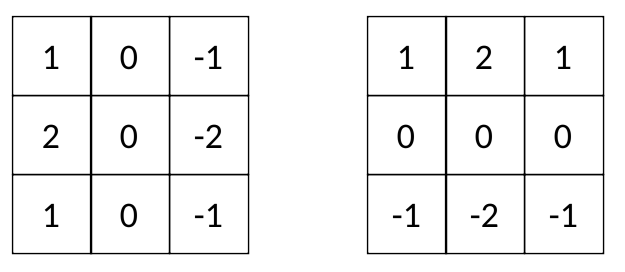
Il est plus facile de voir l'effet de chaque filtre Sobel sur l'image :

Le code pour utiliser le filtre Sobel est ici .
Gy met en évidence les bords horizontaux, Gx met en évidence les bords verticaux. Par conséquent, les noyaux de Sobel Gx et Gy sont souvent appelés "détecteurs de bord".
Les bords sont les caractéristiques originales d'une image, telles que la texture, la luminosité, la couleur, etc. Un point clé de la vision par ordinateur moderne est d'utiliser des algorithmes pour trouver automatiquement des noyaux directement à partir des données, comme les filtres Sobel. Ou, pour utiliser un meilleur terme, adapter le noyau à travers un processus de formation itératif.
Il s'avère que le processus d'apprentissage enseigne aux programmes informatiques comment effectuer des tâches complexes, telles que reconnaître et détecter des objets, comprendre le langage naturel, etc... L'apprentissage du noyau sera présenté dans la prochaine histoire.
7. Conclusion et prochaines étapes
Dans cette histoire, nous codons notre première convolution 2D et utilisons un filtre Sobel comme exemple illustratif d'application de cette convolution à une image. Les convolutions jouent un rôle central dans l'apprentissage en profondeur. Ils sont largement utilisés dans tous les modèles d'apprentissage automatique du monde réel aujourd'hui. Nous reviendrons sur les convolutions pour apprendre à améliorer notre implémentation et couvrirons certaines fonctionnalités telles que les foulées.