1. Descriptif
Mentionnez la pertinence des cadres d'apprentissage automatique pour la recherche et l'industrie. Il y a très peu de projets aujourd'hui qui n'utilisent pas Google TensorFlow ou Meta PyTorch en raison de leur évolutivité et de leur flexibilité. Cela dit, il peut sembler contre-intuitif de passer du temps à coder un algorithme d'apprentissage automatique à partir de zéro, c'est-à-dire sans aucun cadre sous-jacent. Cependant, ce n'est pas le cas. Le codage de l'algorithme vous-même fournit une compréhension claire et solide du fonctionnement de l'algorithme et de ce que fait réellement le modèle.
Dans cette série , nous apprendrons à écrire des algorithmes d'apprentissage en profondeur indispensables tels que les convolutions, la rétropropagation, les fonctions d'activation, les optimiseurs, les réseaux de neurones profonds, etc., en utilisant uniquement du C++ simple et moderne.

Nous commencerons notre voyage à travers l'histoire en apprenant certaines fonctionnalités du langage C++ moderne et les détails de programmation associés pour coder des modèles d'apprentissage en profondeur et d'apprentissage automatique.
Découvrez d'autres histoires:
1 — Codage des convolutions 2D en C++
2 — Fonctions de coût utilisant Lambdas
3 - Mise en œuvre de la descente de gradient
... et bien d'autres à venir.
Ce que je ne peux pas créer, je ne le comprends pas. —Richard Feynman
2. Nouveau style C++ et en-têtes<algorithm><numeric>
Autrefois un langage ancien, le C++ a radicalement changé au cours de la dernière décennie. L'un des changements majeurs est la prise en charge de la programmation fonctionnelle. Cependant, plusieurs autres améliorations ont été introduites pour nous aider à développer un code d'apprentissage automatique meilleur, plus rapide et plus sûr.
Pour notre tâche ici, un ensemble pratique de routines communes est inclus dans le C++ et les en-têtes. A titre d'exemple illustratif, on peut obtenir le produit scalaire de deux vecteurs par :<numeric><algorithm>
#include <numeric>
#include <iostream>
int main()
{
std::vector<double> X {1., 2., 3., 4., 5., 6.};
std::vector<double> Y {1., 1., 0., 1., 0., 1.};
auto result = std::inner_product(X.begin(), X.end(), Y.begin(), 0.0);
std::cout << "Inner product of X and Y is " << result << '\n';
return 0;
}
et utiliser une fonction comme celle-ci :accumulatereduce
std::vector<double> V {1., 2., 3., 4., 5.};
double sum = std::accumulate(V.begin(), V.end(), 0.0);
std::cout << "Summation of V is " << sum << '\n';
double product = std::accumulate(V.begin(), V.end(), 1.0, std::multiplies<double>());
std::cout << "Productory of V is " << product << '\n';
double reduction = std::reduce(V.begin(), V.end(), 1.0, std::multiplies<double>());
std::cout << "Reduction of V is " << reduction << '\n';
L'en-tête est un grand nombre de routines utiles, telles que ,, , , , etc. Prenons un exemple illustratif :algorithmstd::transformstd::for_eachstd::countstd::uniquestd::sort
#include <algorithm>
#include <iostream>
double square(double x) {return x * x;}
int main()
{
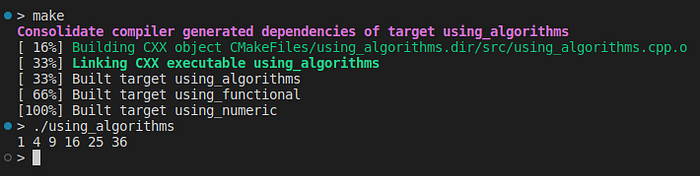
std::vector<double> X {1., 2., 3., 4., 5., 6.};
std::vector<double> Y(X.size(), 0);
std::transform(X.begin(), X.end(), Y.begin(), square);
std::for_each(Y.begin(), Y.end(), [](double y){std::cout << y << " ";});
std::cout << "\n";
return 0;
}
Il s'avère qu'en C++ moderne, nous pouvons passer des foncteurs , des lambdas et même des fonctions vanille comme arguments en utilisant des fonctions telles que , , , etc., au lieu d'utiliser explicitement une boucle ou .forwhilestd::transformstd::for_eachstd::generate_n
L'exemple ci-dessus peut être trouvé dans ce référentiel sur GitHub .
Soit dit en passant, est un lambda. Parlons maintenant de la programmation fonctionnelle et des lambdas.[](double v){...}
3. Programmation fonctionnelle
C++ est un langage de programmation multi-paradigme, ce qui signifie que nous pouvons l'utiliser pour créer des programmes qui utilisent différents "styles" tels que POO, procédural et plus récemment fonctionnel.
La prise en charge de C++ pour la programmation fonctionnelle commence par l'en-tête :<functional>
#include <algorithm> // std::for_each
#include <functional> // std::less, std::less_equal, std::greater, std::greater_equal
#include <iostream> // std::cout
int main()
{
std::vector<std::function<bool(double, double)>> comparators
{
std::less<double>(),
std::less_equal<double>(),
std::greater<double>(),
std::greater_equal<double>()
};
double x = 10.;
double y = 10.;
auto compare = [&x, &y](const std::function<bool(double, double)> &comparator)
{
bool b = comparator(x, y);
std::cout << (b?"TRUE": "FALSE") << "\n";
};
std::for_each(comparators.begin(), comparators.end(), compare);
return 0;
}
Ici, nous utilisons , , et comme exemples d'appels polymorphes au lieu de pointeurs.std::functionstd::lessstd::less_equalstd::greaterstd::greater_equal
Comme nous l'avons déjà mentionné, C++11 inclut des modifications au cœur du langage pour prendre en charge la programmation fonctionnelle. Nous en avons déjà vu un :
auto compare = [&x, &y](const std::function<bool(double, double)> &comparator)
{
bool b = comparator(x, y);
std::cout << (b?"TRUE": "FALSE") << "\n";
};Ce code définit un lambda, et un lambda définit un objet fonction , l'objet appelable.
Notez qu'il ne s'agit pas du nom lambda, mais du nom de la variable à laquelle la lambda est affectée. En fait, les lambdas sont des objets anonymes.
compare
Ce lambda se compose de 3 clauses : la liste de capture ( ), la liste de paramètres ( ) et le corps (le code entre les accolades).[&x, &y]const std::function<boll(double, double)> &comparator{...}
La liste de paramètres et la clause body fonctionnent comme n'importe quelle fonction normale. La clause capture spécifie l'ensemble des variables externes qui sont adressables dans le corps du lambda.
Les lambdas sont très utiles. Nous pouvons les déclarer et les passer comme des foncteurs à l'ancienne. Par exemple, nous pouvons définir un lambda régularisé L2 :
auto L2 = [](const std::vector<double> &V)
{
double p = 0.01;
return std::inner_product(V.begin(), V.end(), V.begin(), 0.0) * p;
};et renvoyez-le à notre couche comme argument :
auto layer = new Layer::Dense();
layer.set_regularization(L2)Par défaut, les lambdas ne provoquent pas d'effets secondaires , c'est-à-dire qu'ils ne peuvent pas modifier l'état des objets dans l'espace mémoire externe. Cependant, nous pouvons définir un lambda si nécessaire. Considérez la mise en œuvre dynamique suivante :mutable
#include <algorithm>
#include <iostream>
using vector = std::vector<double>;
int main()
{
auto momentum_optimizer = [V = vector()](const vector &gradient) mutable
{
if (V.empty()) V.resize(gradient.size(), 0.);
std::transform(V.begin(), V.end(), gradient.begin(), V.begin(), [](double v, double dx)
{
double beta = 0.7;
return v = beta * v + dx;
});
return V;
};
auto print = [](double d) { std::cout << d << " "; };
const vector current_grads {1., 0., 1., 1., 0., 1.};
for (int i = 0; i < 3; ++i)
{
vector weight_update = momentum_optimizer(current_grads);
std::for_each(weight_update.begin(), weight_update.end(), print);
std::cout << "\n";
}
return 0;
}
Chaque appel se traduira par une valeur différente, même si nous passons la même valeur que le paramètre. Cela se produit parce que nous utilisons le mot-clé .momentum_optimizer(current_grads)mutable
Pour nos besoins actuels, le paradigme de la programmation fonctionnelle est particulièrement précieux. En utilisant des fonctionnalités fonctionnelles, nous écrirons moins de code mais plus robuste et effectuerons des tâches plus complexes plus rapidement.
4. Bibliothèques de matrices et d'algèbre linéaire
Eh bien, quand je dis "pur C++", ce n'est pas tout à fait vrai. Nous implémenterons notre algorithme en utilisant une bibliothèque d'algèbre linéaire solide.
Les matrices et les tenseurs sont les éléments constitutifs des algorithmes d'apprentissage automatique. Il n'y a pas d'implémentation de matrice intégrée en C++ (il ne devrait pas y en avoir). Heureusement, il existe plusieurs bibliothèques d'algèbre linéaire matures et excellentes, telles que Eigen et Armadillo .
J'utilise Eigen depuis des années. Eigen (sous la Mozilla Public License 2.0) est un en-tête uniquement et ne dépend d'aucune bibliothèque tierce. Par conséquent, j'utiliserai Eigen comme moteur d'algèbre linéaire pour cette histoire et au-delà.
Cinq opérations matricielles courantes
L'opération matricielle la plus importante est la multiplication matrice par matrice :
#include <iostream>
#include <Eigen/Dense>
int main(int, char **)
{
Eigen::MatrixXd A(2, 2);
A(0, 0) = 2.;
A(1, 0) = -2.;
A(0, 1) = 3.;
A(1, 1) = 1.;
Eigen::MatrixXd B(2, 3);
B(0, 0) = 1.;
B(1, 0) = 1.;
B(0, 1) = 2.;
B(1, 1) = 2.;
B(0, 2) = -1.;
B(1, 2) = 1.;
auto C = A * B;
std::cout << "A:\n" << A << std::endl;
std::cout << "B:\n" << B << std::endl;
std::cout << "C:\n" << C << std::endl;
return 0;
}
Communément appelée, la complexité de calcul de cette opération est O(N³). Comme largement utilisé en apprentissage automatique, notre algorithme est fortement affecté par la taille de la matrice.mulmatmulmat
Parlons d'un autre type de multiplication matricielle. Parfois, nous avons juste besoin d'une multiplication de matrice de coefficients :
auto D = B.cwiseProduct(C);
std::cout << "coefficient-wise multiplication is:\n" << D << std::endl;Bien sûr, dans la multiplication des coefficients, les dimensions des paramètres doivent correspondre. De la même manière, on peut additionner ou soustraire des matrices :
auto E = B + C;
std::cout << "The sum of B & C is:\n" << E << std::endl;
Enfin, discutons de trois opérations matricielles très importantes : , , et :transposeinversedeterminant
std::cout << "The transpose of B is:\n" << B.transpose() << std::endl;
std::cout << "The A inverse is:\n" << A.inverse() << std::endl;
std::cout << "The determinant of A is:\n" << A.determinant() << std::endl;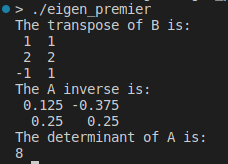
Les inverses, les transpositions et les déterminants sont à la base de la mise en œuvre de notre modèle. Un autre point clé est d'appliquer la fonction à chaque élément de la matrice :
auto my_func = [](double x){return x * x;};
std::cout << A.unaryExpr(my_func) << std::endl;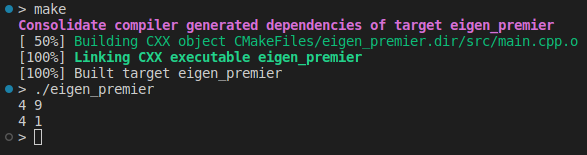
Un exemple de ce qui précède peut être trouvé ici .
Six, un mot sur la vectorisation
Les compilateurs et les architectures informatiques modernes fournissent une amélioration appelée vectorisation . En bref, la vectorisation permet d'effectuer en parallèle des opérations arithmétiques indépendantes à l'aide de plusieurs registres. Par exemple, la boucle for suivante :
for (int i = 0; i < 1024; i++)
{
A[i] = A[i] + B[i];
}Remplacez silencieusement par la version vectorisée :
for(i=0; i < 512; i += 2)
{ A[i] =
A[i] + B[i];
A[i + 1] = A[i + 1] + B[i + 1 ];
} par le compilateur. L'astuce est que les instructions s'exécutent en même temps que les instructions . Ceci est possible car les deux instructions sont indépendantes l'une de l'autre et le matériel sous-jacent dispose de ressources dupliquées, à savoir deux unités d'exécution.A[i + 1] = A[i + 1] + B[i + 1]A[i] = A[i] + B[i]
Si le matériel possède quatre unités d'exécution, le compilateur déroulera la boucle comme suit :
for(i=0; i < 256; i += 4)
{ A[i] =
A[i] + B[i] ;
A[i + 1] = A[i + 1] + B[i + 1];
A[i + 2] = A[i + 2] + B[i + 2];
A[i + 3] = A[i + 3] + B[i + 3];
}Cette version vectorisée rend le programme 4 fois plus rapide que la version originale. Il convient de noter que cette amélioration des performances n'affecte pas le comportement du programme d'origine.
Bien que la vectorisation soit effectuée sous les bois par le compilateur, l'OS et le matériel, il faut faire attention lors du codage pour permettre la vectorisation :
- Activer les drapeaux de vectorisation nécessaires à la compilation du programme
- Avant le démarrage de la boucle, les limites de la boucle doivent être connues, dynamiques ou statiques
- Les directives de corps de boucle ne doivent pas faire référence à l'état précédent. Par exemple, des choses comme celle-ci peuvent empêcher la vectorisation, car dans certains cas, le compilateur ne peut pas déterminer en toute sécurité si quelque chose est valide pendant l'appel d'instruction en cours.
A[i] = A[i — 1] + B[i]A[i-1] - Le corps de la boucle doit être composé d'un code simple et linéaire. Les appels de fonction et les fonctions précédemment vectorisées sont également autorisés. Mais la logique complexe, les sous-programmes, les boucles imbriquées et les appels de fonction empêchent souvent la vectorisation de fonctionner.
inline
Dans certains cas, suivre ces règles n'est pas facile. Compte tenu de la complexité et de la taille du code, il est parfois difficile de dire quand le compilateur a vectorisé une partie particulière du code.
En règle générale, plus le code est compact et simple, plus il est facile à vectoriser. Par conséquent, l'utilisation des fonctions standard des conteneurs , , et STL représente un code plus susceptible d'être vectorisé.<numeric>algorithmfunctional
7. Vectorisation dans l'apprentissage automatique
La vectorisation joue un rôle important dans l'apprentissage automatique. Par exemple, les lots sont souvent traités de manière vectorisée, ce qui fait que les trains avec de gros lots roulent plus rapidement que les trains avec de petits (ou pas) lots.
Étant donné que notre bibliothèque d'algèbre matricielle utilise la vectorisation de manière exhaustive, nous agrégeons souvent les données de ligne en lots pour des opérations plus rapides. Considérez l'exemple suivant :

Au lieu de faire 6 produits internes entre chacun des six vecteurs et un vecteur pour obtenir 6 sorties, etc., nous pouvons empiler les vecteurs d'entrée pour monter une matrice à six lignes et l'exécuter une fois avec une seule multiplication.XiVY0Y1MmulmatY = M*V
La sortie est un vecteur. Nous pouvons enfin dissocier ses éléments pour obtenir les 6 valeurs de sortie souhaitées.Y
8. Conclusion et prochaines étapes
Il s'agit d'un exposé introductif sur la façon d'écrire des algorithmes d'apprentissage en profondeur à l'aide du C++ moderne. Nous couvrons des aspects très importants du développement de programmes d'apprentissage automatique hautes performances, tels que la programmation fonctionnelle, le calcul algébrique et la vectorisation.
Certains sujets de programmation pertinents pour les projets ML réels, tels que la programmation GPU ou la formation distribuée, ne sont pas couverts ici. Nous aborderons ces thèmes dans de futures histoires.
Dans la prochaine histoire , nous apprendrons à coder la convolution 2D, l'opération la plus basique du deep learning.