Compiler et construire Hive3.1.3 à partir du code source
Instructions de compilation
L'utilisation du package d'installation précompilé officiellement fourni par Hive est la manière la plus courante et recommandée d'utiliser Hive, qui convient à la plupart des utilisateurs. Ces packages précompilés ont été testés et vérifiés pour fonctionner correctement dans de nombreux environnements différents.
Dans certains cas spécifiques, il peut être nécessaire de compiler Hive à partir des sources au lieu d'utiliser un package d'installation précompilé.
Les scénarios et les raisons de compiler le code source de Hive sont les suivants :
1. Paramétrage personnalisé :
Si vous souhaitez apporter une personnalisation ou une modification de configuration spécifique à Hive, telle que la modification des paramètres par défaut, l'ajout d'un nouveau backend de stockage de données, l'intégration d'un nouveau moteur d'exécution, etc., la compilation du code source pourra modifier et personnaliser la configuration de Hive.
2. Extension de fonction :
Si vous avez besoin d'étendre les fonctions de Hive, telles que l'ajout d'UDF personnalisé (fonction définie par l'utilisateur), UDAF (fonction d'agrégation définie par l'utilisateur), UDTF (fonction de génération de table définie par l'utilisateur), etc., la compilation du code source ajoutera et créez ces fonctions personnalisées.
3. Débogage et modification des bogues :
Si vous rencontrez des problèmes lors du processus d'utilisation de Hive, ou si vous trouvez un bogue et que vous souhaitez le déboguer et le corriger, la compilation du code source permettra d'obtenir le code source d'exécution, puis de le déboguer et de le modifier.
4. Dernières fonctionnalités et améliorations :
Si vous souhaitez utiliser les dernières fonctionnalités, améliorations et optimisations de Hive, mais que ces fonctionnalités n'ont pas été publiées dans le package précompilé officiel, vous pouvez compiler la dernière version à partir du code source pour obtenir et utiliser ces fonctions.
5. Participez aux contributions de la communauté :
Si vous êtes intéressé par Hive et que vous souhaitez contribuer à son développement, en compilant le code source, vous pouvez obtenir un environnement de développement complet, comprenant des outils de construction, des frameworks de test et du code source, afin que vous puissiez développer et contribuer au code avec Hive. communauté.
Compiler Hive3.1.3
Lorsque vous utilisez Spark comme moteur d'exécution de Hive, mais que la version Spark prise en charge par Hive3.1.3 elle-même est 2.3, Hive doit donc être recompilé pour que Hive prenne en charge une version plus récente de Spark. Prévoyez de compiler Hive pour prendre en charge Spark3.4.0, Hadoop version 3.1.3
Modifier la configuration Maven
Modifiez le fichier maven settings.xmlet décidez d'ajouter ou non l'adresse d'entrepôt suivante en fonction de la situation, à titre de référence uniquement :
<!-- 阿里云仓库 -->
<mirror>
<id>aliyun-central</id>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/central</url>
<mirrorOf>*</mirrorOf>
</mirror>
<!-- 中央仓库 -->
<mirror>
<id>repo</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>https://repo.maven.apache.org/maven2</url>
</mirror>
télécharger le code source
Téléchargez le code source de la version Hive qui doit être compilée, ici nous prévoyons de recompiler Hive3.1.3
wget https://archive.apache.org/dist/hive/hive-3.1.3/pache-hive-3.1.3-src.tar.gz
IDEA ouvre pache-hive-3.1.3-srcle projet, et après l'ouverture du projet, il deviendra certainement populaire, ne vous inquiétez pas
Modifier le projet pom.xml
1. Modifier la version Hadoop
La version Hadoop prise en charge par Hive3.1.3 est 3.1.10, mais rappelez-vous qu'il existe une gamme de prise en charge entre Hive et Hadoop, donc les opérations liées à Hadoop dépendent de l'évolution des exigences.
<hadoop.version>3.1.0</hadoop.version>
<hadoop.version>3.1.3</hadoop.version>
Rappelez-vous clairement que Hadoop3.1.3 utilise la version de journal 1.7.25
<slf4j.version>1.7.10</slf4j.version>
<slf4j.version>1.7.25</slf4j.version>
2. Modifier la version goyave
Étant donné que les dépendances Hadoop sont chargées lors de l'exécution de Hive, il est nécessaire de modifier la version goyave dans Hive en version goyave dans Hadoop. Même s'il n'y a pas de changement ici, en fait, il est possible de remplacer la version goyave lors de l'utilisation de Hive (la différence de version n'est pas grande et il n'est pas nécessaire de la remplacer)
<guava.version>19.0</guava.version>
<guava.version>27.0-jre</guava.version>
3. Modifier la version d'étincelle
Le Spark par défaut pris en charge par Hive 3.1.3 est 2.3.0, et cette étape est également le cœur pour le faire prendre en charge Spark 3.4.0, qui est une version plus récente, selon les exigences. De plus, précisez clairement que Spark3.4.0 utilise la version Scala2.13, et modifiez-la ensemble
<spark.version>2.3.0</spark.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.8</scala.version>
# 原计划编译spark3.4.0 特么的太多坑了 后面不得不放弃
<spark.version>3.4.0</spark.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.17</scala.version>
# 掉坑里折腾惨了,降低spark版本
<spark.version>3.2.4</spark.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.17</scala.version>
Modifier le code source de la ruche
Modifier le descriptif
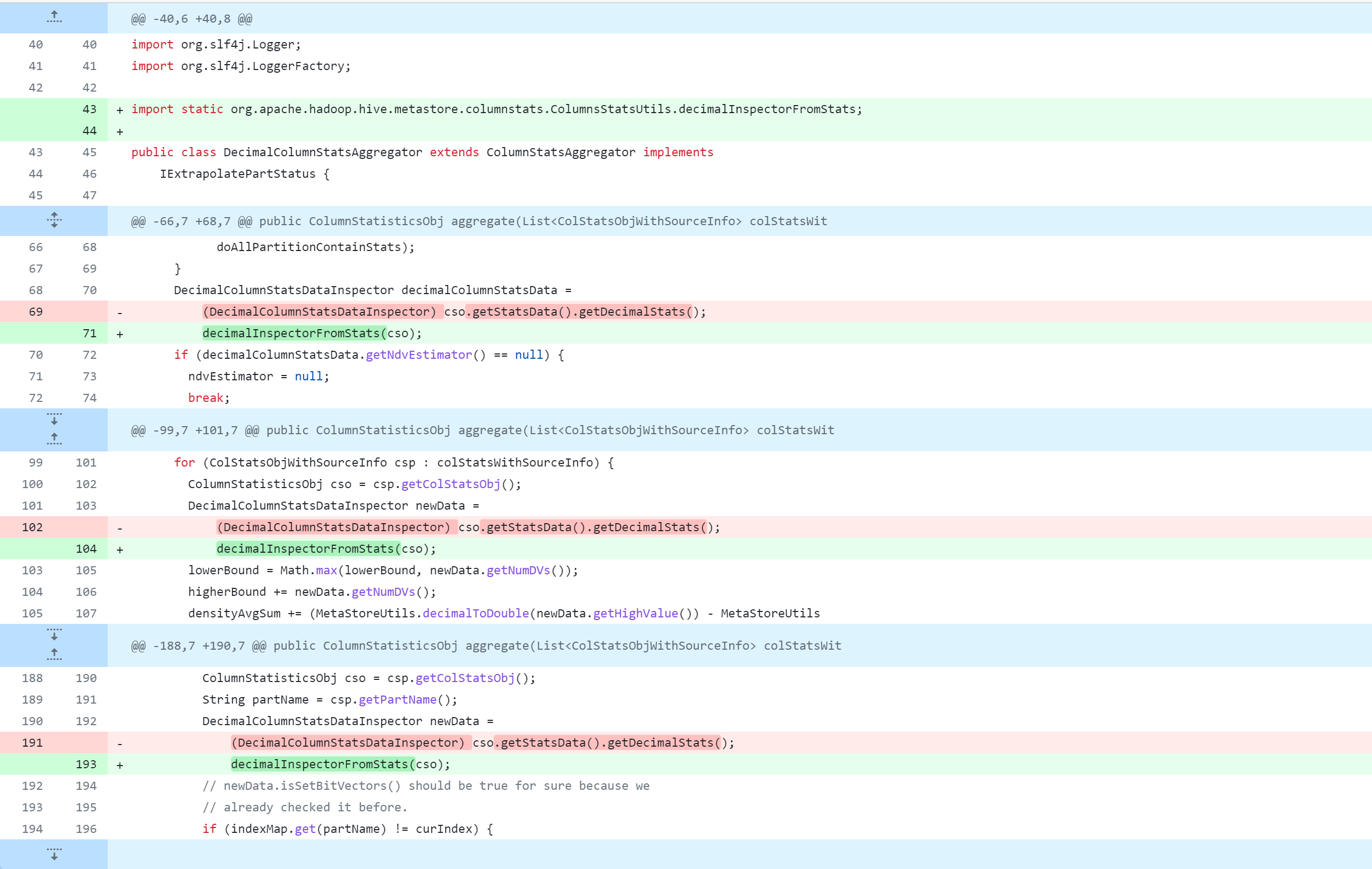
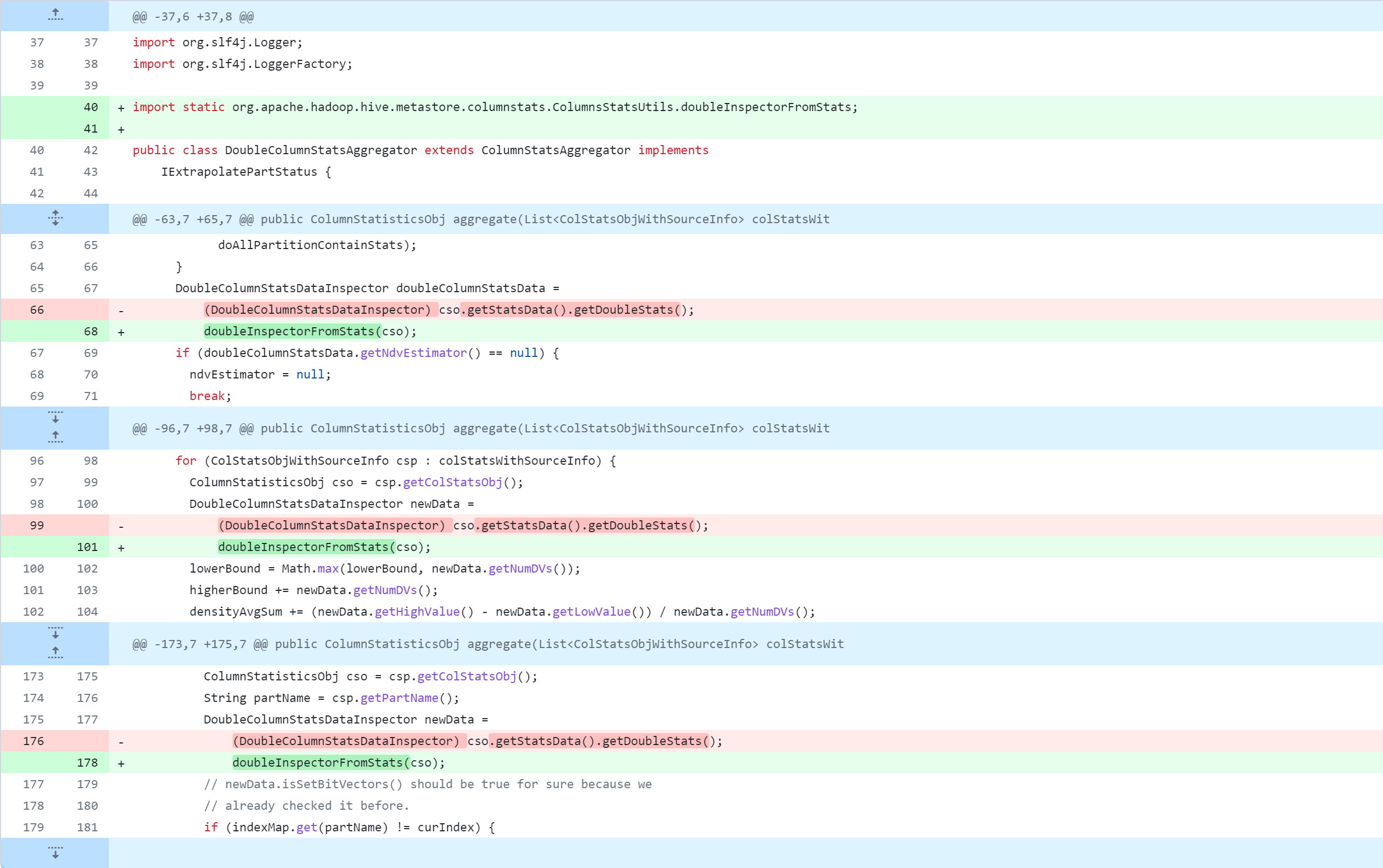
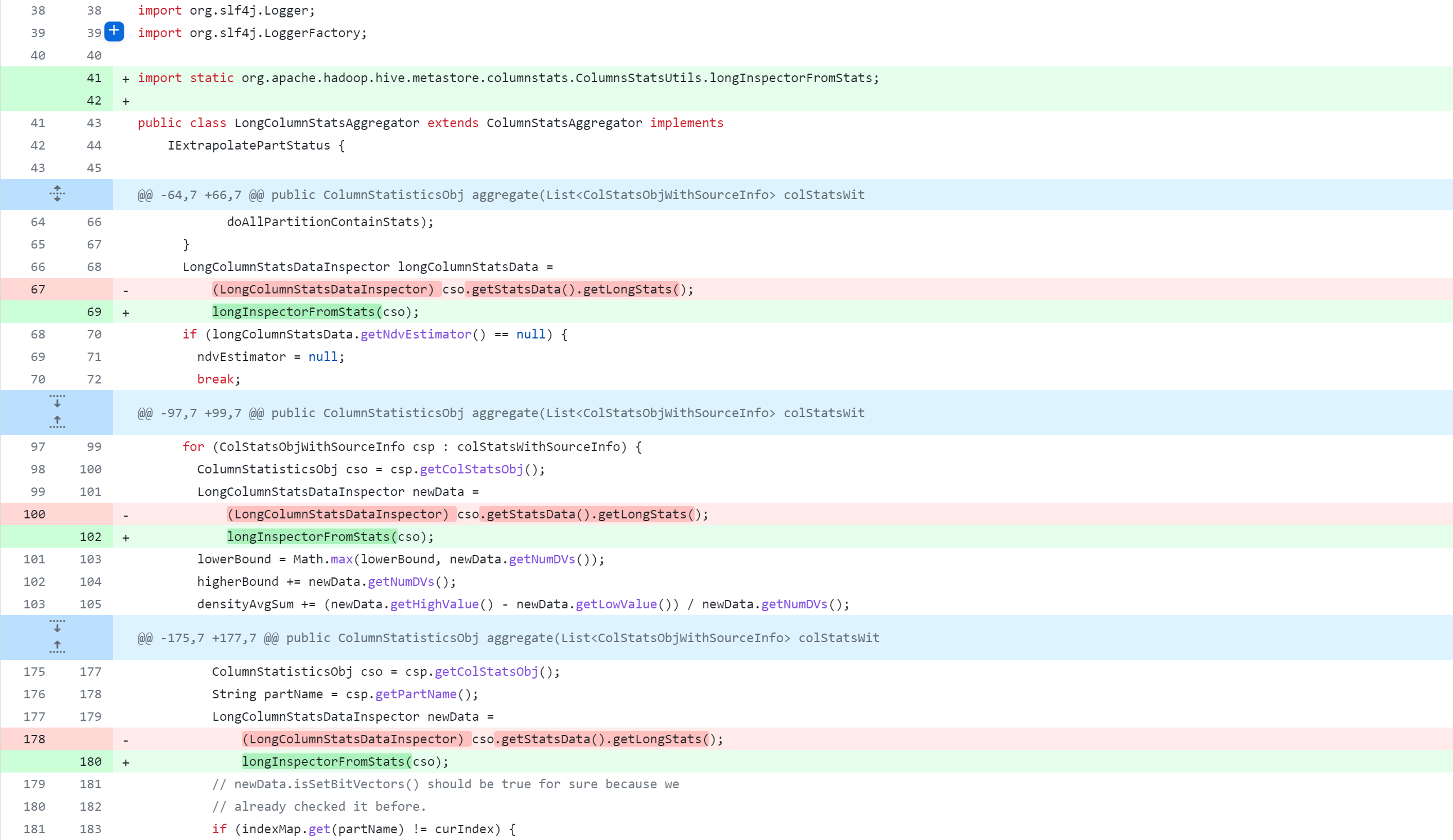
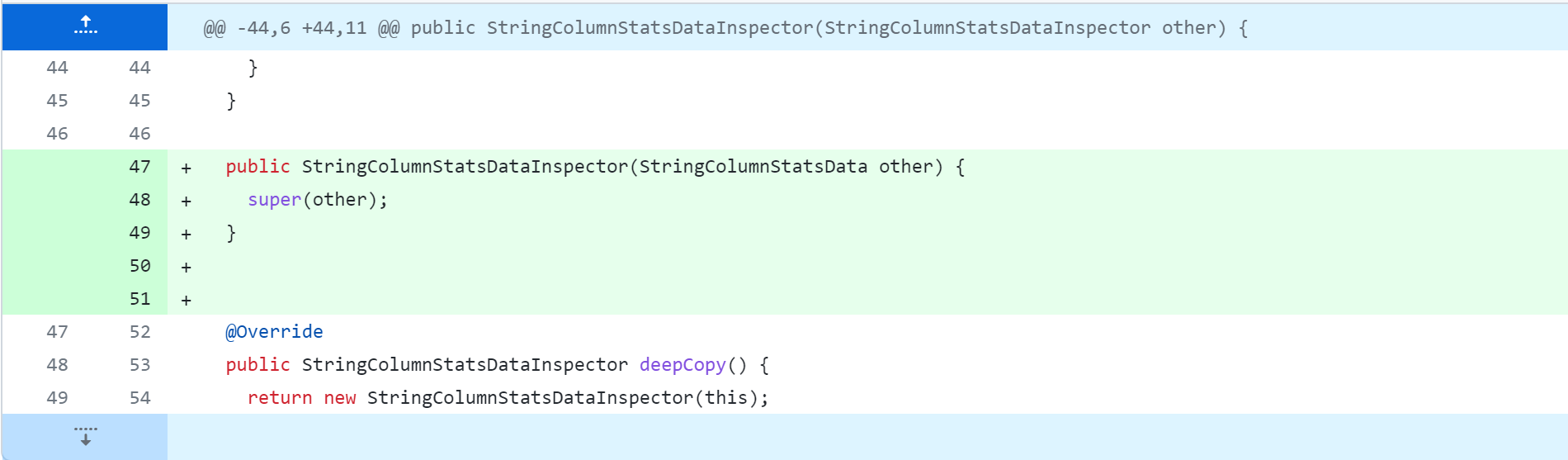
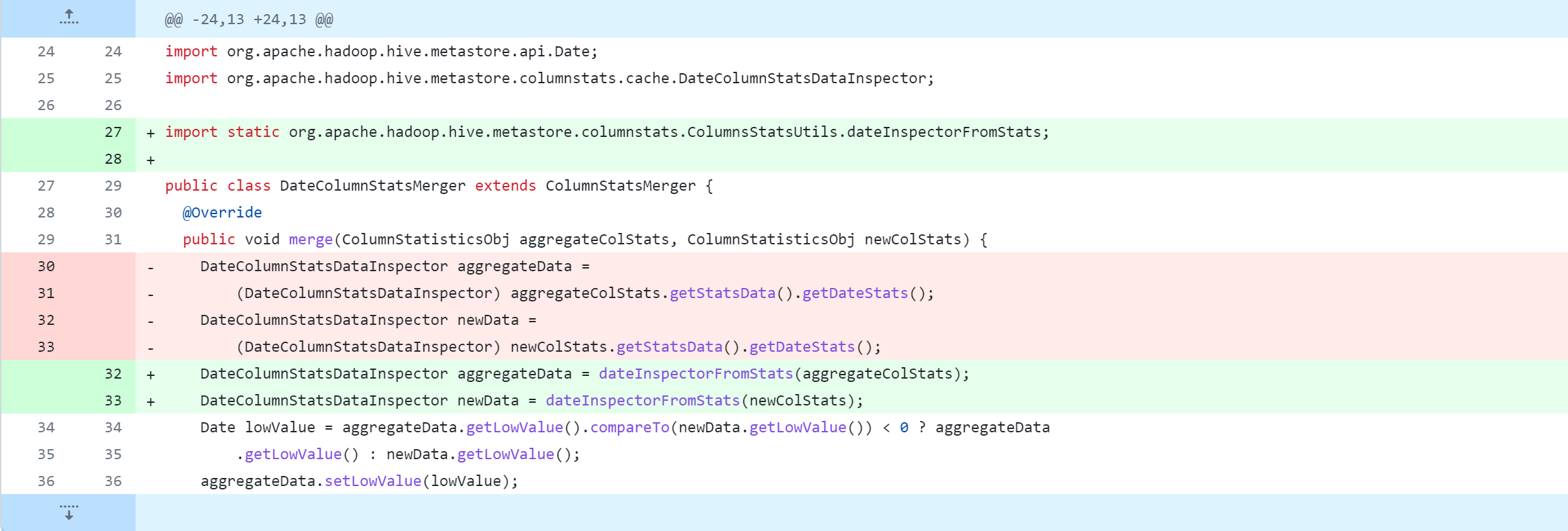
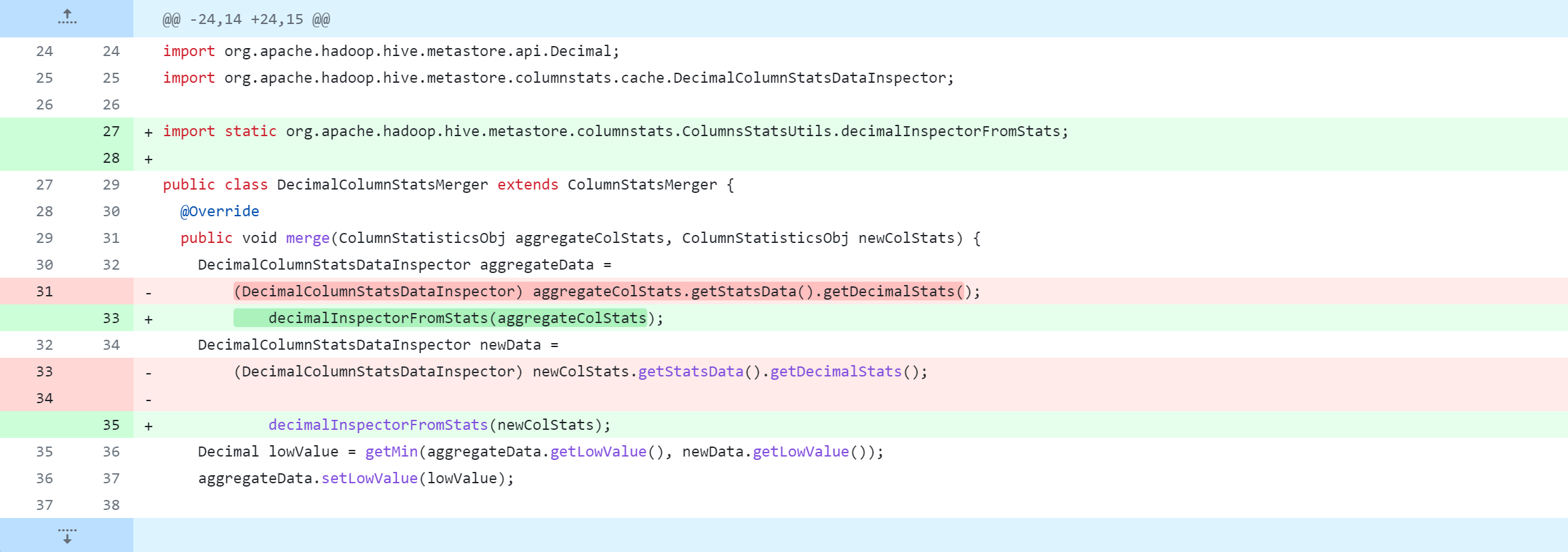
La modification du code source de Hive supprimera, modifiera et ajoutera des opérations. La figure suivante est un tableau de comparaison du contrôle de version Git, que tout le monde devrait pouvoir comprendre. Mais je m'explique :
-: supprimer cette ligne de code+: ajouter, modifier cette ligne de code

L'opération de modification du code source de la ruche est l'opération principale. Pour une modification spécifique du code source, reportez-vous à :
https://github.com/gitlbo/hive/commits/3.1.2
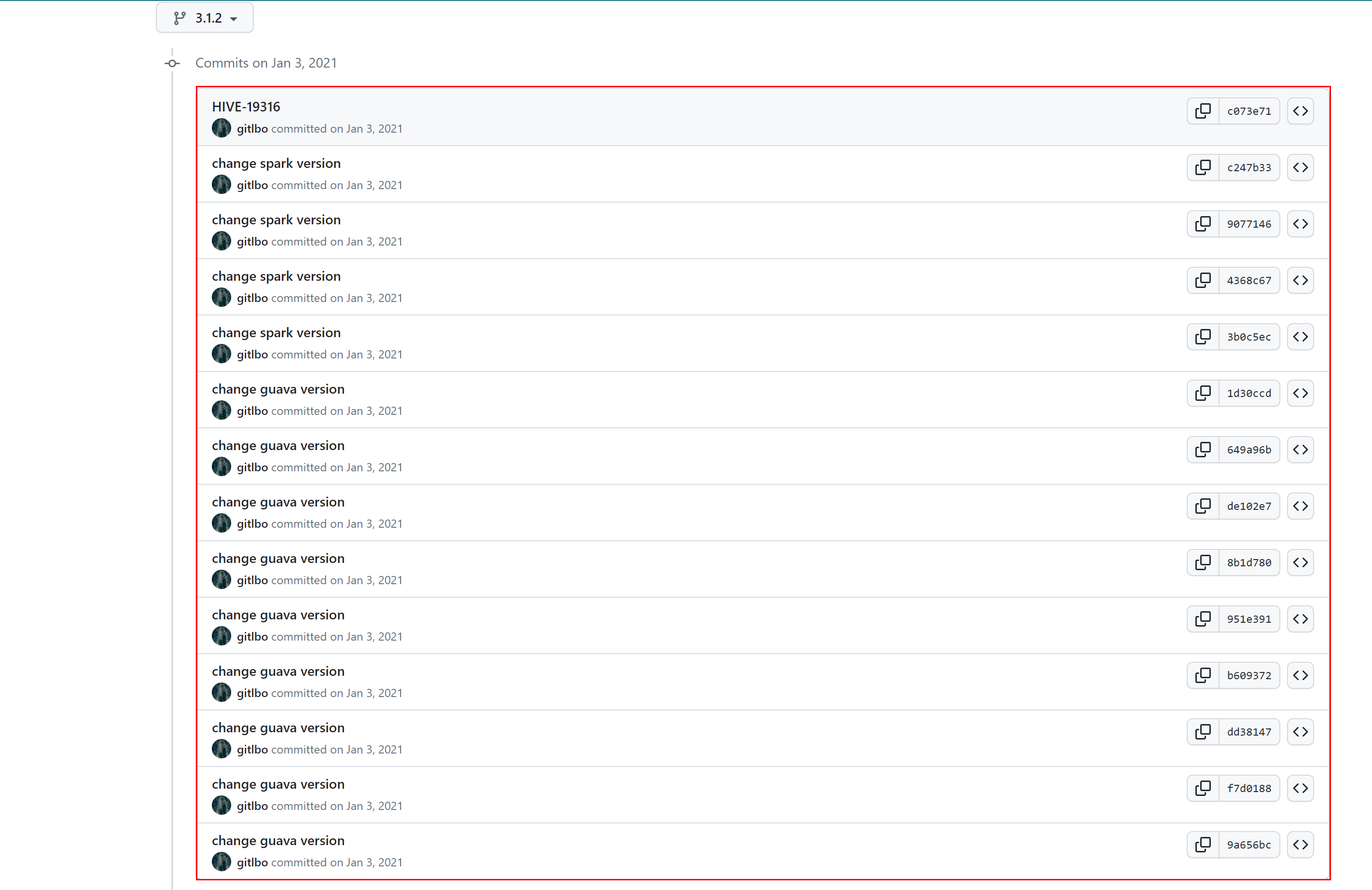
Modifier le module standalone-metastore
Référence de modification spécifique :https://github.com/gitlbo/hive/commit/c073e71ef43699b7aa68cad7c69a2e8f487089fd
Créez la classe ColumnsStatsUtils
avec le code suivant :
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hive.metastore.columnstats;
import org.apache.hadoop.hive.metastore.api.ColumnStatisticsObj;
import org.apache.hadoop.hive.metastore.columnstats.cache.DateColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.DecimalColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.DoubleColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.LongColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.StringColumnStatsDataInspector;
/**
* Utils class for columnstats package.
*/
public final class ColumnsStatsUtils {
private ColumnsStatsUtils(){
}
/**
* Convertes to DateColumnStatsDataInspector if it's a DateColumnStatsData.
* @param cso ColumnStatisticsObj
* @return DateColumnStatsDataInspector
*/
public static DateColumnStatsDataInspector dateInspectorFromStats(ColumnStatisticsObj cso) {
DateColumnStatsDataInspector dateColumnStats;
if (cso.getStatsData().getDateStats() instanceof DateColumnStatsDataInspector) {
dateColumnStats =
(DateColumnStatsDataInspector)(cso.getStatsData().getDateStats());
} else {
dateColumnStats = new DateColumnStatsDataInspector(cso.getStatsData().getDateStats());
}
return dateColumnStats;
}
/**
* Convertes to StringColumnStatsDataInspector
* if it's a StringColumnStatsData.
* @param cso ColumnStatisticsObj
* @return StringColumnStatsDataInspector
*/
public static StringColumnStatsDataInspector stringInspectorFromStats(ColumnStatisticsObj cso) {
StringColumnStatsDataInspector columnStats;
if (cso.getStatsData().getStringStats() instanceof StringColumnStatsDataInspector) {
columnStats =
(StringColumnStatsDataInspector)(cso.getStatsData().getStringStats());
} else {
columnStats = new StringColumnStatsDataInspector(cso.getStatsData().getStringStats());
}
return columnStats;
}
/**
* Convertes to LongColumnStatsDataInspector if it's a LongColumnStatsData.
* @param cso ColumnStatisticsObj
* @return LongColumnStatsDataInspector
*/
public static LongColumnStatsDataInspector longInspectorFromStats(ColumnStatisticsObj cso) {
LongColumnStatsDataInspector columnStats;
if (cso.getStatsData().getLongStats() instanceof LongColumnStatsDataInspector) {
columnStats =
(LongColumnStatsDataInspector)(cso.getStatsData().getLongStats());
} else {
columnStats = new LongColumnStatsDataInspector(cso.getStatsData().getLongStats());
}
return columnStats;
}
/**
* Convertes to DoubleColumnStatsDataInspector
* if it's a DoubleColumnStatsData.
* @param cso ColumnStatisticsObj
* @return DoubleColumnStatsDataInspector
*/
public static DoubleColumnStatsDataInspector doubleInspectorFromStats(ColumnStatisticsObj cso) {
DoubleColumnStatsDataInspector columnStats;
if (cso.getStatsData().getDoubleStats() instanceof DoubleColumnStatsDataInspector) {
columnStats =
(DoubleColumnStatsDataInspector)(cso.getStatsData().getDoubleStats());
} else {
columnStats = new DoubleColumnStatsDataInspector(cso.getStatsData().getDoubleStats());
}
return columnStats;
}
/**
* Convertes to DecimalColumnStatsDataInspector
* if it's a DecimalColumnStatsData.
* @param cso ColumnStatisticsObj
* @return DecimalColumnStatsDataInspector
*/
public static DecimalColumnStatsDataInspector decimalInspectorFromStats(ColumnStatisticsObj cso) {
DecimalColumnStatsDataInspector columnStats;
if (cso.getStatsData().getDecimalStats() instanceof DecimalColumnStatsDataInspector) {
columnStats =
(DecimalColumnStatsDataInspector)(cso.getStatsData().getDecimalStats());
} else {
columnStats = new DecimalColumnStatsDataInspector(cso.getStatsData().getDecimalStats());
}
return columnStats;
}
}
Modifiez ensuite le contenu suivant. Pour des modifications spécifiques, reportez-vous à la capture d'écran ci-dessous.
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/DateColumnStatsAggregator.java
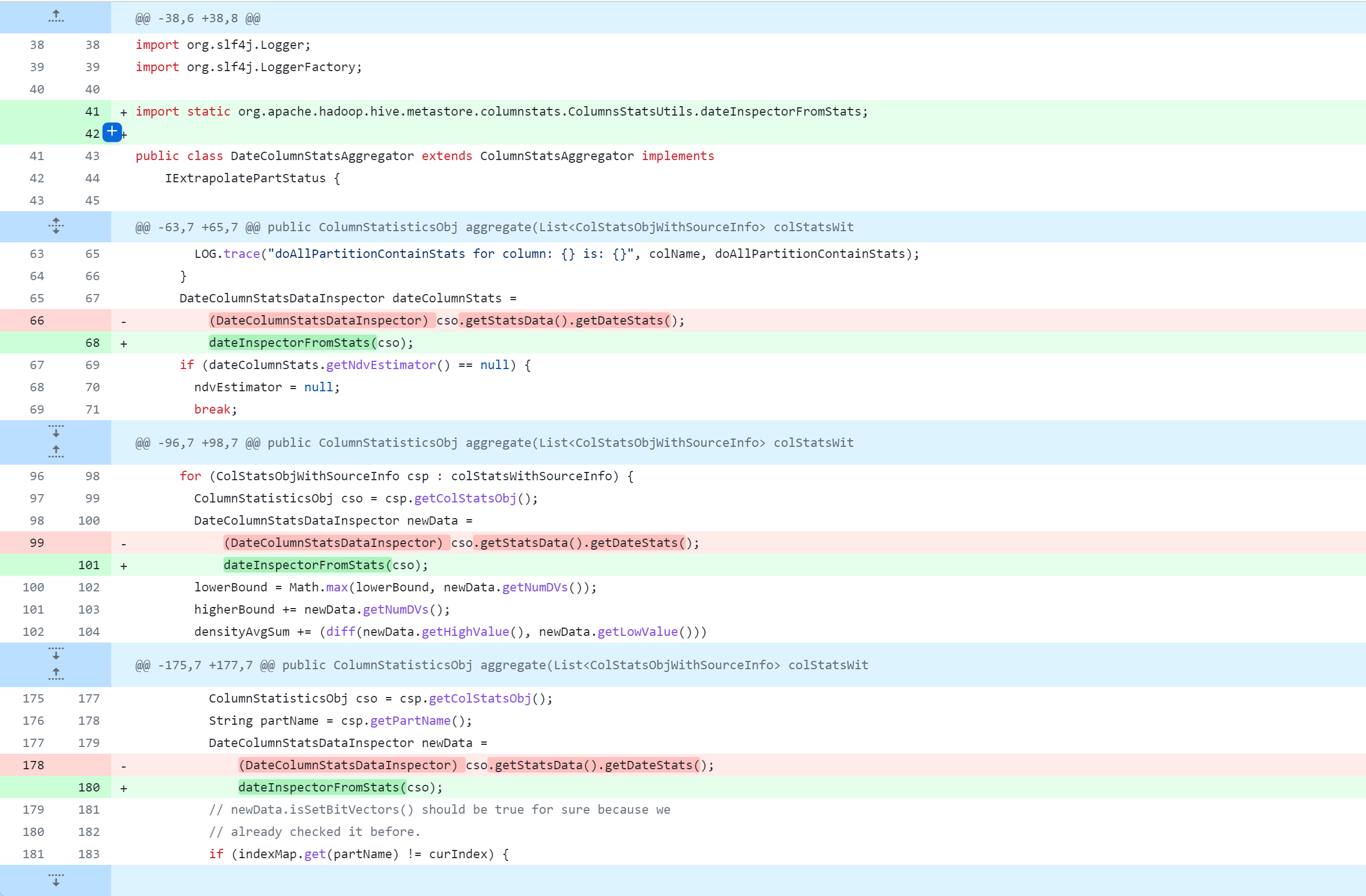
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/DecimalColumnStatsAggregator.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/DoubleColumnStatsAggregator.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/LongColumnStatsAggregator.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/StringColumnStatsAggregator.java
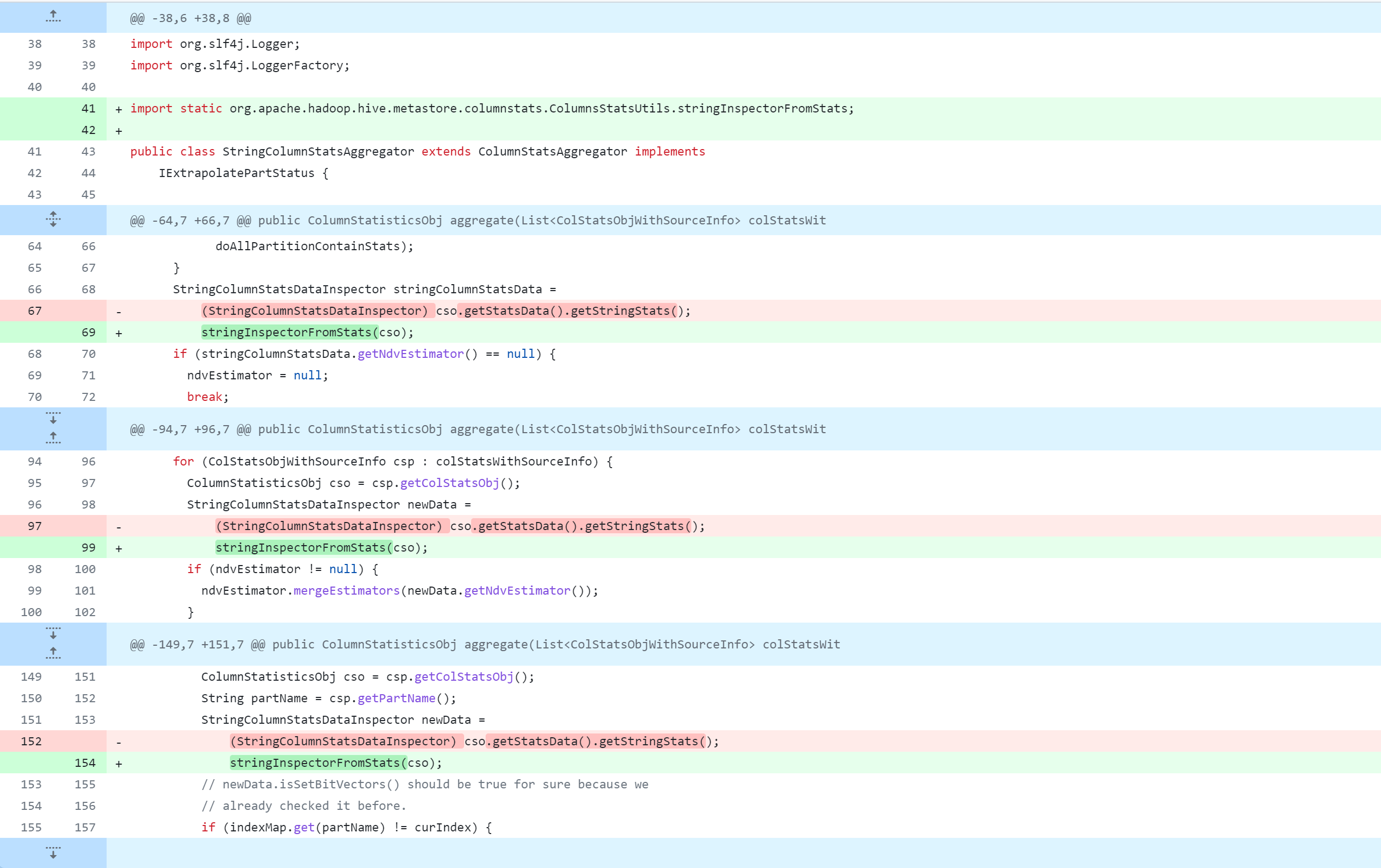
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/DateColumnStatsDataInspector.java
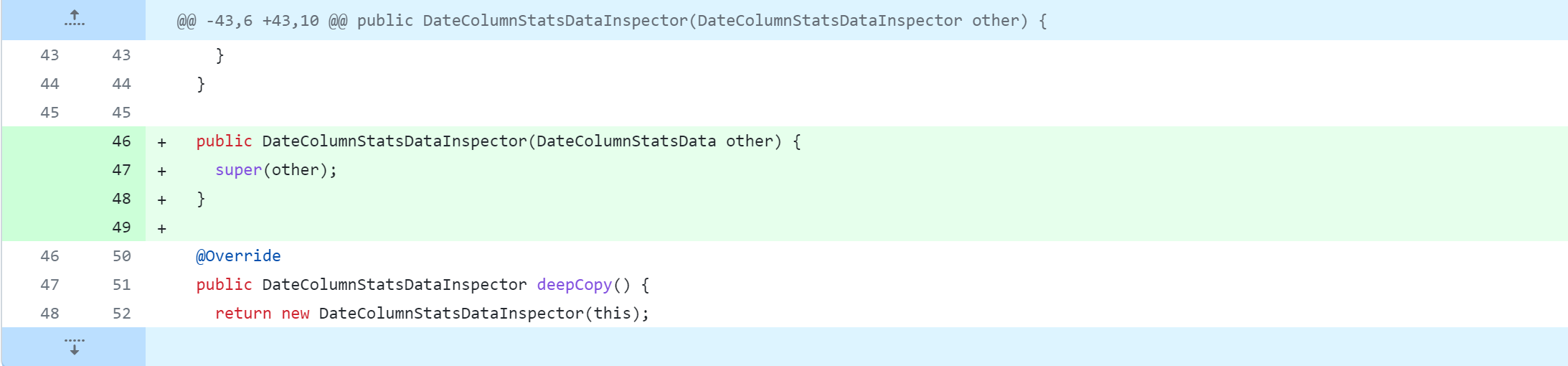
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/DecimalColumnStatsDataInspector.java
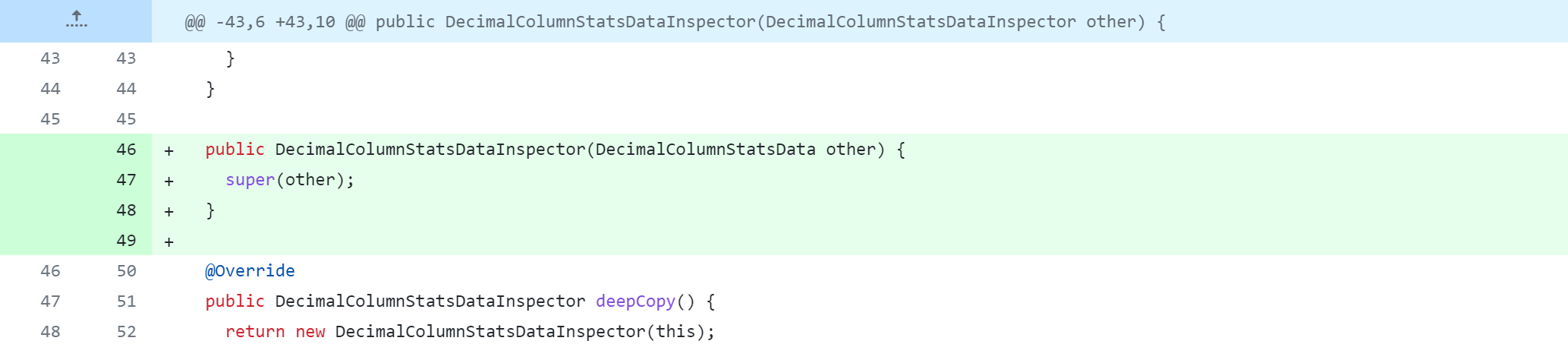
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/DoubleColumnStatsDataInspector.java
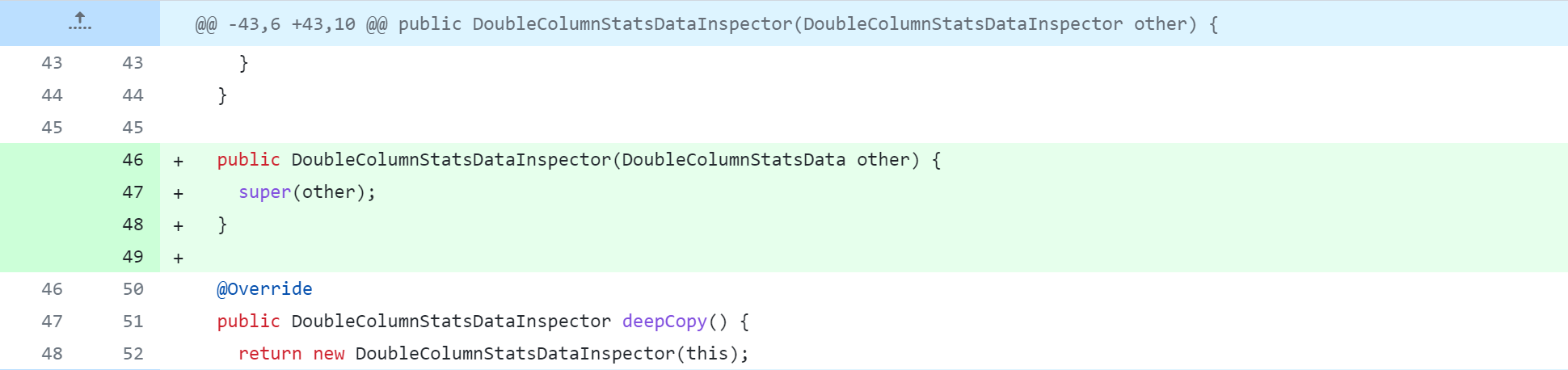
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/LongColumnStatsDataInspector.java
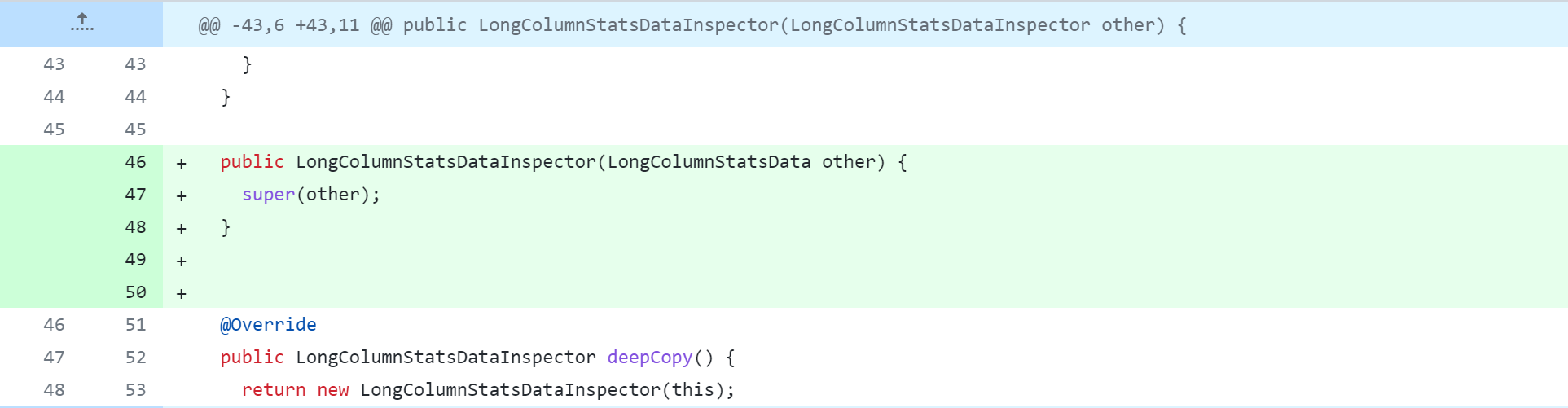
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/StringColumnStatsDataInspector.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/DateColumnStatsMerger.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/DecimalColumnStatsMerger.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/DoubleColumnStatsMerger.java
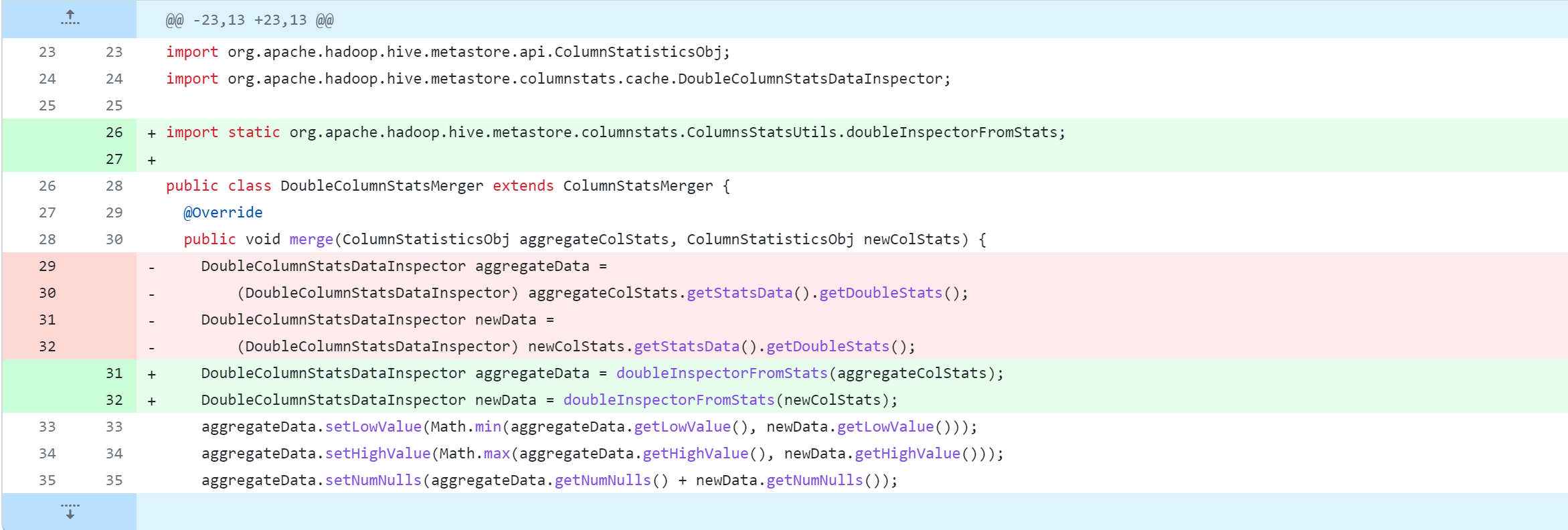
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/LongColumnStatsMerger.java

standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/StringColumnStatsMerger.java

Modifier le module ql
ql/src/test/org/apache/hadoop/hive/ql/stats/TestStatsUtils.java

ql/src/test/org/apache/hadoop/hive/ql/exec/tez/SampleTezSessionState.java
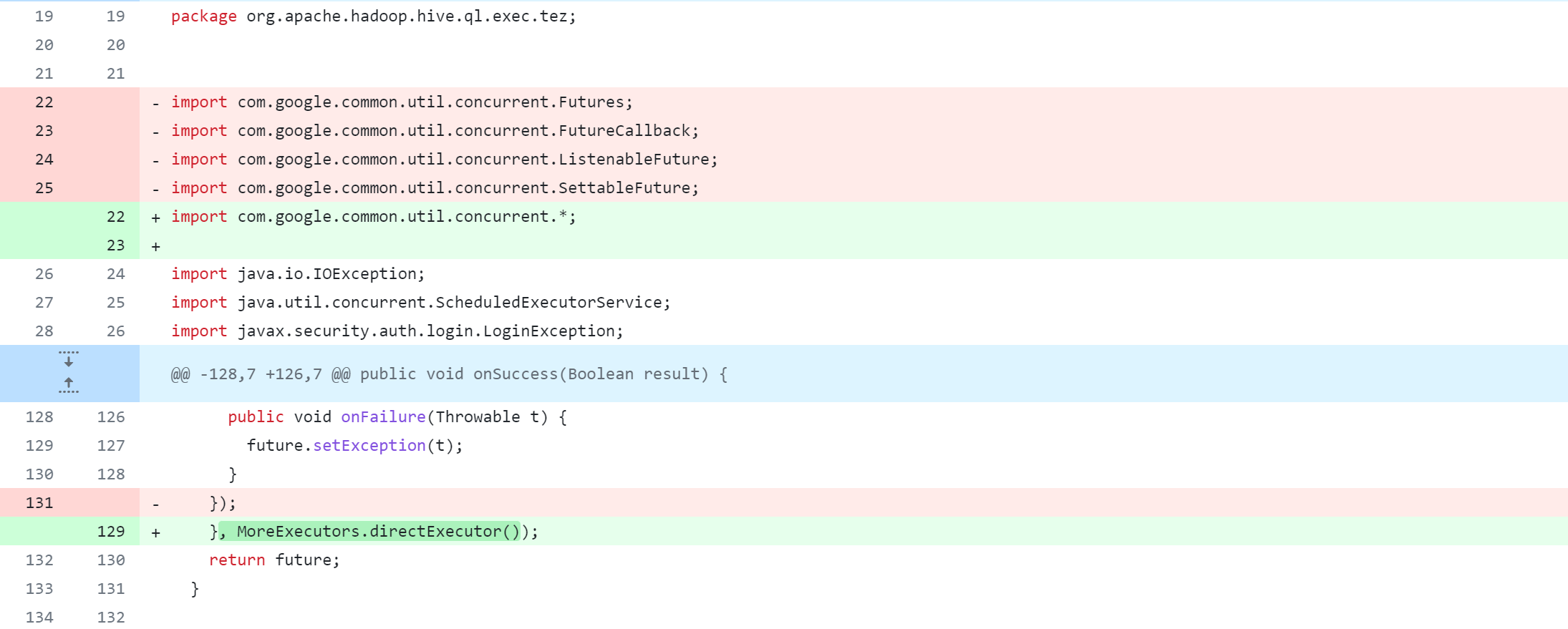
ql/src/java/org/apache/hadoop/hive/ql/exec/tez/WorkloadManager.java
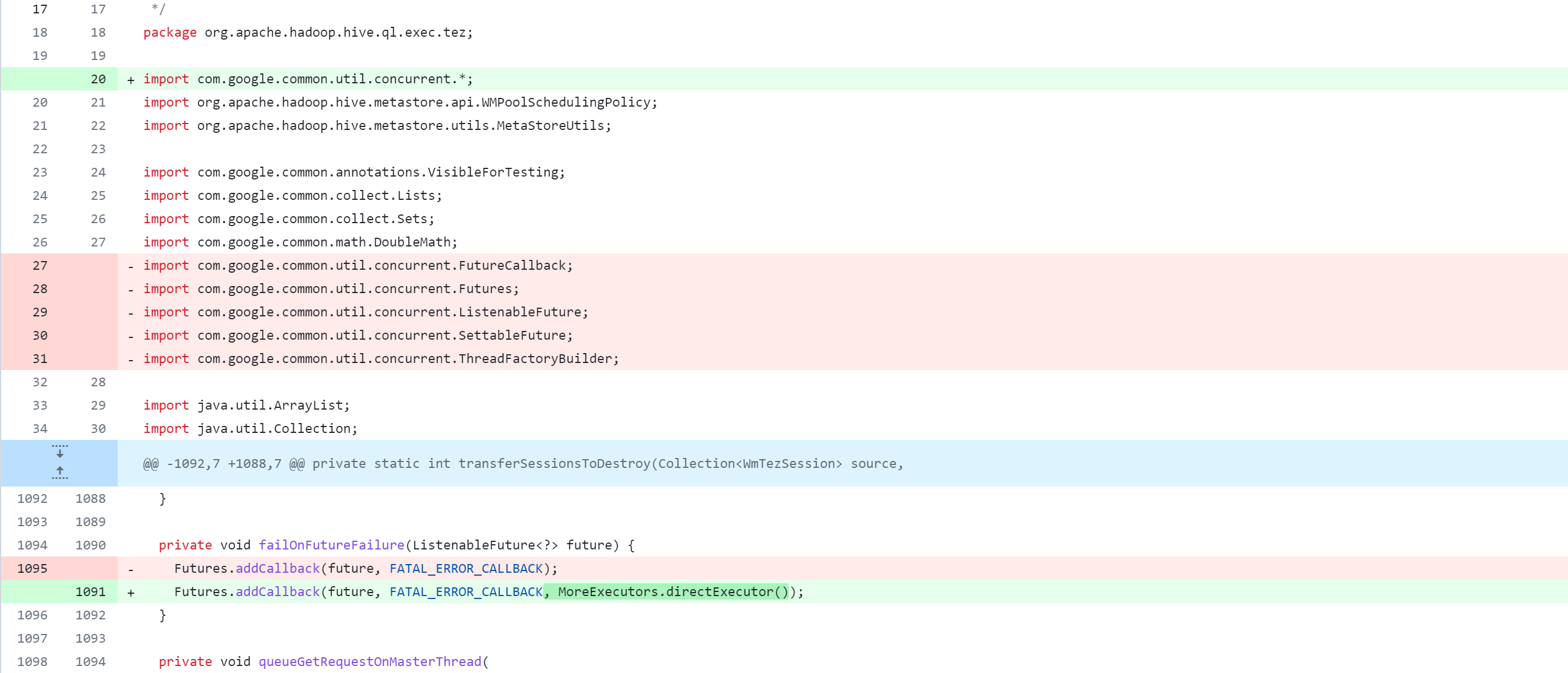

Modifier le module spark-client
spark-client/src/main/java/org/apache/hive/spark/client/metrics/ShuffleWriteMetrics.java

spark-client/src/main/java/org/apache/hive/spark/counter/SparkCounter.java
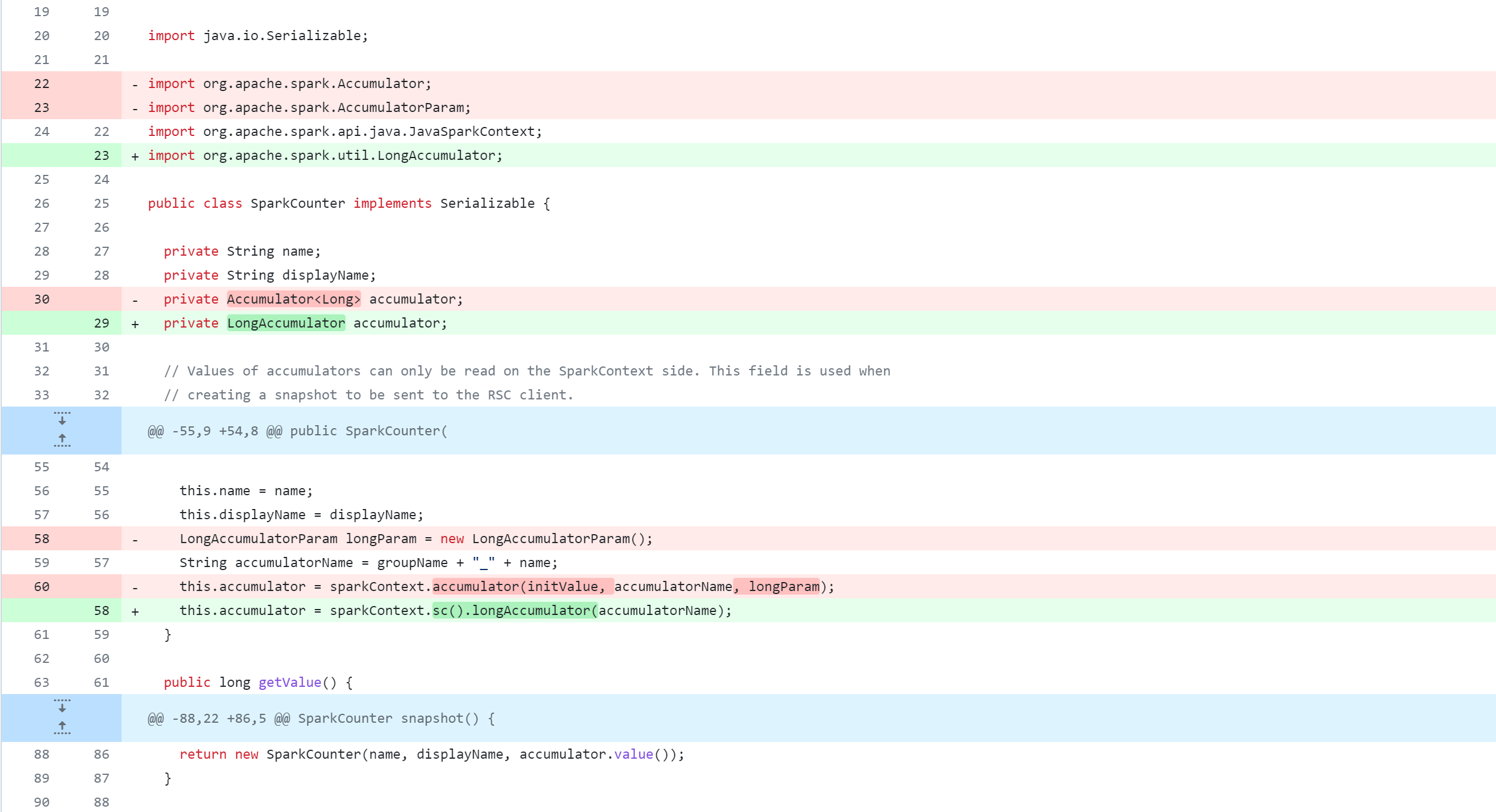
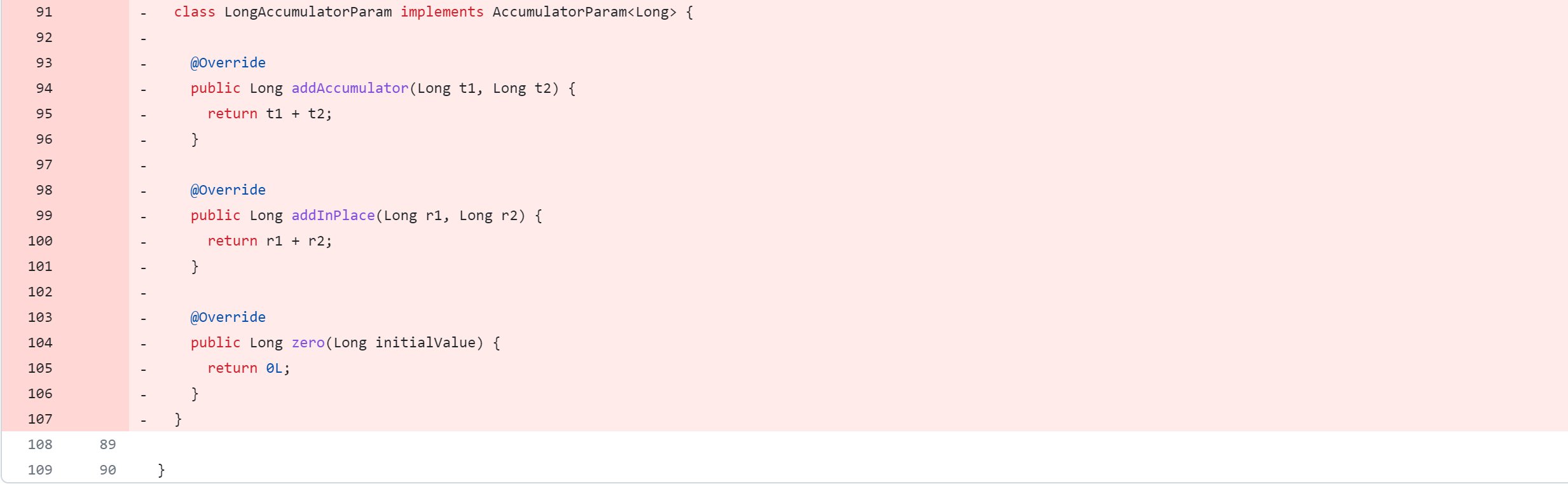
Modifier le module druid-handler
druid-handler/src/java/org/apache/hadoop/hive/druid/serde/DruidScanQueryRecordReader.java
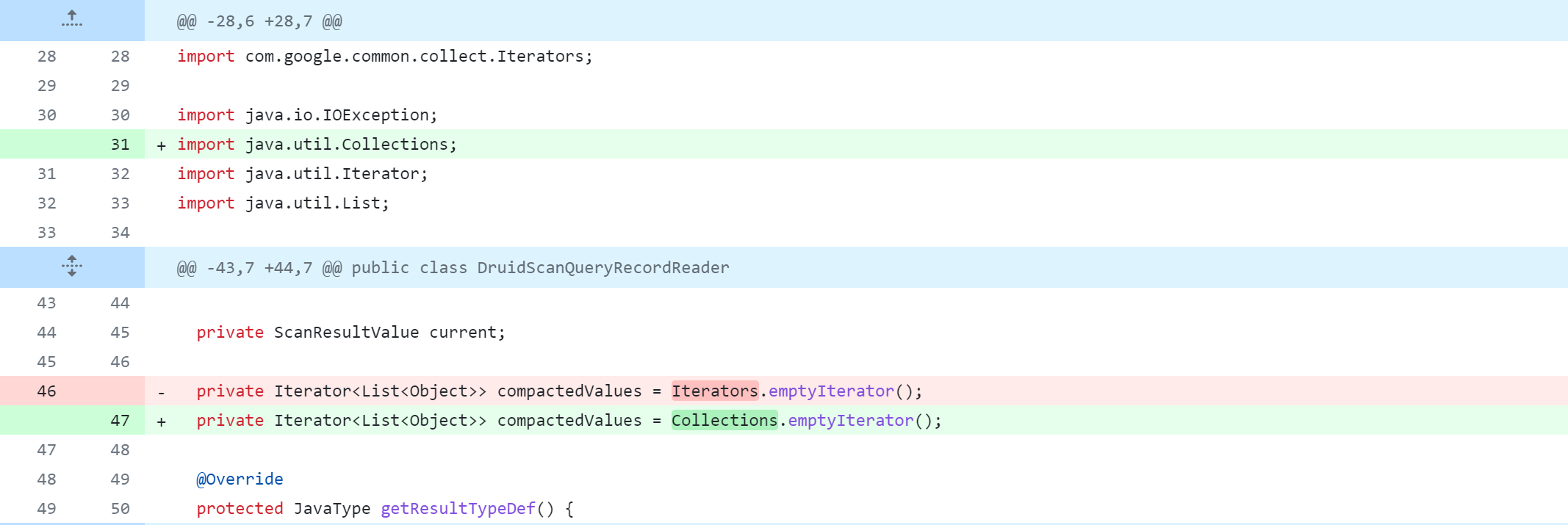
Modifier le module llap-server
llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/AMReporter.java
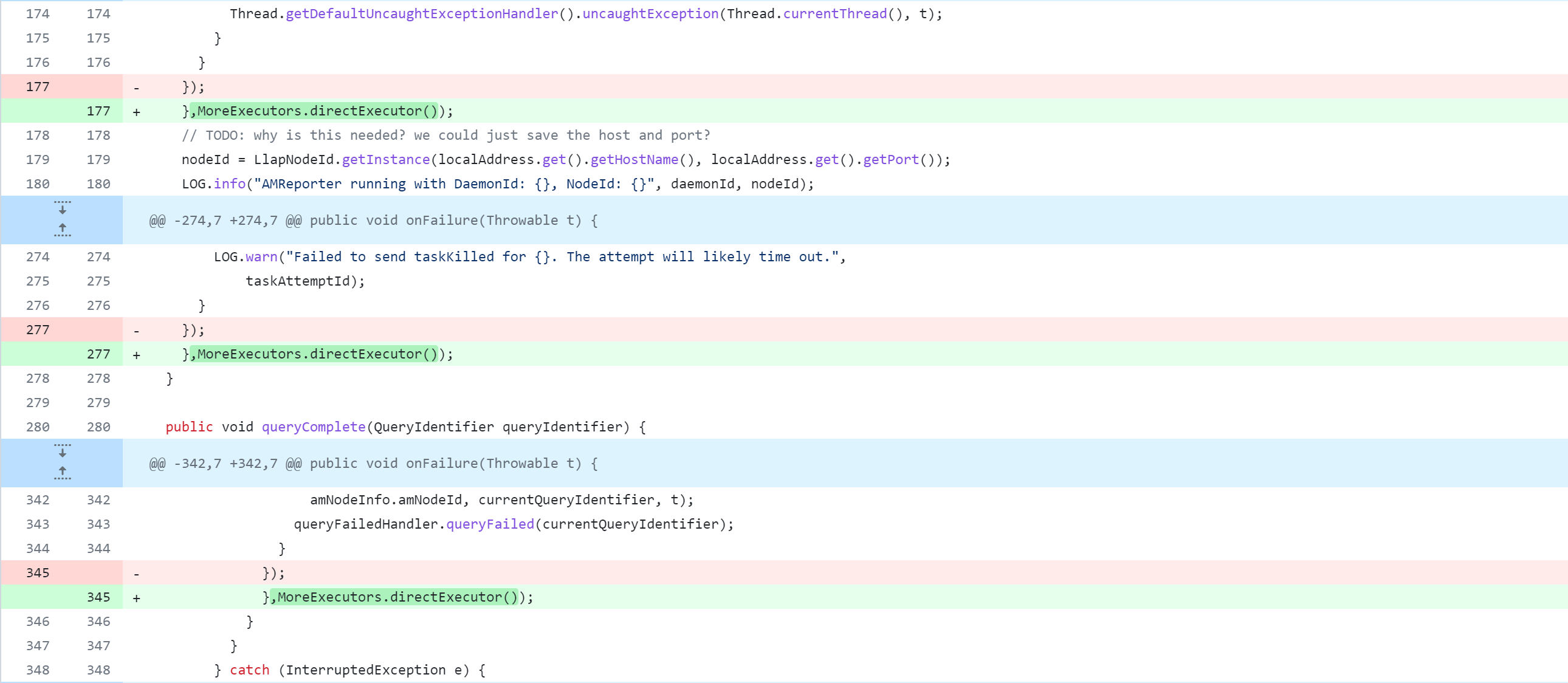
llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/LlapTaskReporter.java

llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/TaskExecutorService.java

Modifier le module llap-tez
llap-tez/src/java/org/apache/hadoop/hive/llap/tezplugins/LlapTaskSchedulerService.java
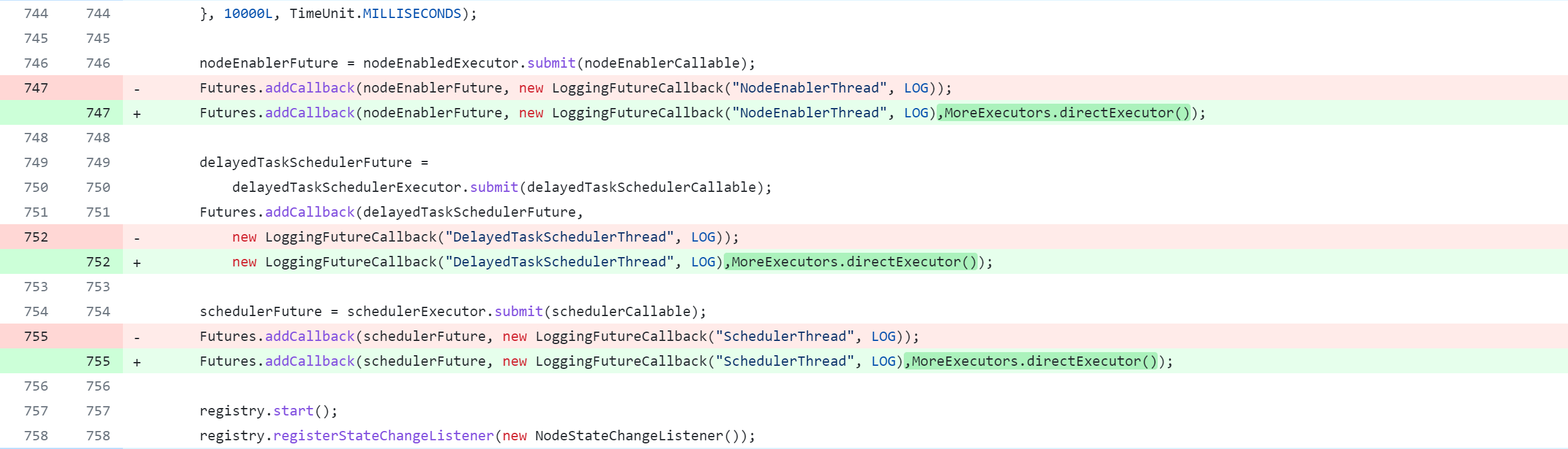
Modifier le module llap-common
llap-common/src/java/org/apache/hadoop/hive/llap/AsyncPbRpcProxy.java
Compiler et empaqueter
Après avoir modifié le code source de Hive, exécutez la commande compile and package :
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
mvn clean package -Pdist -DskipTests
Pendant le processus d'exécution de la commande de compilation et d'empaquetage, il y aura certainement divers problèmes, et ces problèmes doivent être résolus. Pour diverses exceptions rencontrées au cours du processus, veuillez vous référer à la comparaison ci-dessous 异常集合pour les résoudre.
point important
1. Parfois, le cache de l'entrepôt local peut provoquer des erreurs d'analyse des dépendances. Vous pouvez essayer de nettoyer le package maven dans le référentiel local dont dépend le projet. Cette commande nettoiera le package dans pom.xml et le téléchargera à nouveau. Exécutez la commande suivante :
mvn dependency:purge-local-repository
2. Après avoir modifié le numéro de version du fichier Pom.xml, ou changé le code, et installé Jar dans l'entrepôt local, il est recommandé de fermer IDEA et de le rouvrir pour éviter la mise en cache ou les mises à jour intempestives.
collection d'exceptions
Remarque : 以下异常均是按照编译Hive支持Spark3.4.0过程中产生的异常, et ont ensuite rétrogradé la version de Spark.
exception 1
1. Maven indiquera qu'un certain package Jar est introuvable, ne peut pas être téléchargé ou que le téléchargement du Jar prend beaucoup de temps (même si la magie est activée)
Par exemple : le référentiel maven est introuvable
hive-upgrade-acid-3.1.3.jaravecpentaho-aggdesigner-algorithm-5.1.5-jhyde_2.jar
Les exceptions spécifiques sont les suivantes, à titre indicatif uniquement :
[ERROR] Failed to execute goal on project hive-upgrade-acid: Could not resolve dependencies for project org.apache.hive:hive-upgrade-acid:jar:3.1.3: Failure to find org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde in https://maven.aliyun.com/repository/central was cached in the local repository, resolution will not be reattempted until the update interval of aliyun-central has elapsed or updates are forced -> [Help 1]
solution:
Accédez à l'entrepôt suivant pour rechercher le package Jar requis, téléchargez-le manuellement et installez-le dans l'entrepôt local
Adresse de l'entrepôt 1 : https://mvnrepository.com/
Adresse de l'entrepôt 2 : https://central.sonatype.com/
Adresse de l'entrepôt 3 :https://developer.aliyun.com/mvn/search
Installez un JAR dans l'entrepôt local, la syntaxe de l'exemple de commande :
mvn install:install-file -Dfile=<path-to-jar> -DgroupId=<group-id> -DartifactId=<artifact-id> -Dversion=<version> -Dpackaging=<packaging>
<path-to-jar>:JAR文件的路径,可以是本地文件系统的绝对路径。
<group-id>:项目组ID,通常采用反向域名格式,例如com.example。
<artifact-id>:项目的唯一标识符,通常是项目名称。
<version>:项目的版本号。
<packaging>:JAR文件的打包类型,例如jar。
mvn install:install-file -Dfile=./hive-upgrade-acid-3.1.3.jar -DgroupId=org.apache.hive -DartifactId=hive-upgrade-acid -Dversion=3.1.3 -Dpackaging=jar
mvn install:install-file -Dfile=./pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -Dversion=5.1.5-jhyde -Dpackaging=jar
mvn install:install-file -Dfile=./hive-metastore-2.3.3.jar -DgroupId=org.apache.hive -DartifactId=hive-metastore -Dversion=2.3.3 -Dpackaging=jar
mvn install:install-file -Dfile=./hive-exec-3.1.3.jar -DgroupId=org.apache.hive -DartifactId=hive-exec -Dversion=3.1.3 -Dpackaging=jar
exception 2
Incitant bashdes choses liées, mon cœur est beaucoup plus froid. En raison de l'opération sous la fenêtre, bash ne la prend pas en charge.
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:run (generate-version-annotation) on project hive-common: An Ant BuildException has occured: Execute failed: java.io.IOException: Cannot run program "bash" (in directory "C:\Users\JackChen\Desktop\apache-hive-3.1.3-src\common"): CreateProcess error=2, 系统找不到指定的文件。
[ERROR] around Ant part ...<exec failonerror="true" executable="bash">... @ 4:46 in C:\Users\JackChen\Desktop\apache-hive-3.1.3-src\common\target\antrun\build-main.xml
solution:
Normalement, en tant que développeur, vous devez avoir Git installé, et Git a une fenêtre bash, c'est-à-dire exécuter des commandes de compilation et d'empaquetage dans la fenêtre Git Bash
mvn clean package -Pdist -DskipTests
exception 3
les progrès actuels Hive Llap Serveréchouent
[INFO] Hive Llap Client ................................... SUCCESS [ 4.030 s]
[INFO] Hive Llap Tez ...................................... SUCCESS [ 4.333 s]
[INFO] Hive Spark Remote Client ........................... SUCCESS [ 5.382 s]
[INFO] Hive Query Language ................................ SUCCESS [01:28 min]
[INFO] Hive Llap Server ................................... FAILURE [ 7.180 s]
[INFO] Hive Service ....................................... SKIPPED
[INFO] Hive Accumulo Handler .............................. SKIPPED
[INFO] Hive JDBC .......................................... SKIPPED
[INFO] Hive Beeline ....................................... SKIPPED
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.6.1:compile (default-compile) on project hive-llap-server: Compilation failure
[ERROR] /C:/Users/JackChen/Desktop/apache-hive-3.1.3-src/llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/QueryTracker.java:[30,32] org.apache.logging.slf4j.Log4jMarker▒▒org.apache.logging.slf4j▒в▒▒ǹ▒▒▒▒▒; ▒▒▒▒▒ⲿ▒▒▒▒▒▒ж▒▒▒▒▒з▒▒▒
[ERROR]
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <args> -rf :hive-llap-server
public class QueryTracker extends AbstractService {
// private static final Marker QUERY_COMPLETE_MARKER = new Log4jMarker(new Log4jQueryCompleteMarker());
private static final Marker QUERY_COMPLETE_MARKER = MarkerFactory.getMarker("MY_CUSTOM_MARKER");
}
exception 4
La compilation et l'exécution du Hive HCatalog Webhcatmodule ont échoué
[INFO] Hive HCatalog ...................................... SUCCESS [ 10.947 s]
[INFO] Hive HCatalog Core ................................. SUCCESS [ 7.237 s]
[INFO] Hive HCatalog Pig Adapter .......................... SUCCESS [ 2.652 s]
[INFO] Hive HCatalog Server Extensions .................... SUCCESS [ 9.255 s]
[INFO] Hive HCatalog Webhcat Java Client .................. SUCCESS [ 2.435 s]
[INFO] Hive HCatalog Webhcat .............................. FAILURE [ 7.284 s]
[INFO] Hive HCatalog Streaming ............................ SKIPPED
[INFO] Hive HPL/SQL ....................................... SKIPPED
[INFO] Hive Streaming ..................................... SKIPPED
Exception spécifique :
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.6.1:compile (default-compile) on project hive-webhcat: Compilation failure
[ERROR] /root/apache-hive-3.1.3-src/hcatalog/webhcat/svr/src/main/java/org/apache/hive/hcatalog/templeton/Main.java:[258,31] 对于FilterHolder(java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>), 找不到合适的构造器
[ERROR] 构造器 org.eclipse.jetty.servlet.FilterHolder.FilterHolder(org.eclipse.jetty.servlet.BaseHolder.Source)不适用
[ERROR] (参数不匹配; java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>无法转换为org.eclipse.jetty.servlet.BaseHolder.Source)
[ERROR] 构造器 org.eclipse.jetty.servlet.FilterHolder.FilterHolder(java.lang.Class<? extends javax.servlet.Filter>)不适用
[ERROR] (参数不匹配; java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>无法转换为java.lang.Class<? extends javax.servlet.Filter>)
[ERROR] 构造器 org.eclipse.jetty.servlet.FilterHolder.FilterHolder(javax.servlet.Filter)不适用
[ERROR] (参数不匹配; java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>无法转换为javax.servlet.Filter)
[ERROR]
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <args> -rf :hive-webhcat
En regardant le code source, j'ai constaté qu'AuthFilter hérite d'AuthenticationFilter et que AuthenticationFilter implémente Filter.Ce message anormal ne devrait pas apparaître, j'ai donc modifié manuellement le code source et essayé de forcer la conversion, mais j'ai constaté que cela ne fonctionnait toujours pas.
public FilterHolder makeAuthFilter() throws IOException {
// FilterHolder authFilter = new FilterHolder(AuthFilter.class);
FilterHolder authFilter = new FilterHolder((Class<? extends Filter>) AuthFilter.class);
UserNameHandler.allowAnonymous(authFilter);
solution:
Compilez et empaquetez ce module séparément dans IDEA et constatez qu'il peut être construit avec succès
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 40.755 s
[INFO] Finished at: 2023-08-06T21:39:17+08:00
[INFO] ------------------------------------------------------------------------
Alors une idée est venue :
1. Étant donné que le projet utilise Maven pour l'empaquetage (exécutez le package mvn), l'exécution à nouveau de la même commande ne reconditionnera pas le projet
2. Exécutez donc d'abord cleanla commande pour le projet, puis empaquetez le module, et enfin exécutez-le directement Webhcatsans effectuer aucune opération lors de la compilation et de l'empaquetage de l'ensemble .clean mvn package -Pdist -DskipTests
Avis:后来降低了Spark版本,没有产生该问题
Compilé et empaqueté avec succès
Après plusieurs heures de résolution de problèmes et de longues compilations et empaquetages, j'ai finalement réussi et découvert à quel point cette interface est belle.
[INFO] --- maven-dependency-plugin:2.8:copy (copy) @ hive-packaging ---
[INFO] Configured Artifact: org.apache.hive:hive-jdbc:standalone:3.1.3:jar
[INFO] Copying hive-jdbc-3.1.3-standalone.jar to C:\Users\JackChen\Desktop\apache-hive-3.1.3-src\packaging\target\apache-hive-3.1.3-jdbc.jar
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Hive 3.1.3:
[INFO]
[INFO] Hive Upgrade Acid .................................. SUCCESS [ 5.264 s]
[INFO] Hive ............................................... SUCCESS [ 0.609 s]
[INFO] Hive Classifications ............................... SUCCESS [ 1.183 s]
[INFO] Hive Shims Common .................................. SUCCESS [ 2.239 s]
[INFO] Hive Shims 0.23 .................................... SUCCESS [ 2.748 s]
[INFO] Hive Shims Scheduler ............................... SUCCESS [ 2.286 s]
[INFO] Hive Shims ......................................... SUCCESS [ 1.659 s]
[INFO] Hive Common ........................................ SUCCESS [ 9.671 s]
[INFO] Hive Service RPC ................................... SUCCESS [ 6.608 s]
[INFO] Hive Serde ......................................... SUCCESS [ 6.042 s]
[INFO] Hive Standalone Metastore .......................... SUCCESS [ 42.432 s]
[INFO] Hive Metastore ..................................... SUCCESS [ 2.304 s]
[INFO] Hive Vector-Code-Gen Utilities ..................... SUCCESS [ 1.150 s]
[INFO] Hive Llap Common ................................... SUCCESS [ 3.343 s]
[INFO] Hive Llap Client ................................... SUCCESS [ 2.380 s]
[INFO] Hive Llap Tez ...................................... SUCCESS [ 2.476 s]
[INFO] Hive Spark Remote Client ........................... SUCCESS [31:34 min]
[INFO] Hive Query Language ................................ SUCCESS [01:09 min]
[INFO] Hive Llap Server ................................... SUCCESS [ 7.230 s]
[INFO] Hive Service ....................................... SUCCESS [ 28.343 s]
[INFO] Hive Accumulo Handler .............................. SUCCESS [ 6.179 s]
[INFO] Hive JDBC .......................................... SUCCESS [ 19.058 s]
[INFO] Hive Beeline ....................................... SUCCESS [ 4.078 s]
[INFO] Hive CLI ........................................... SUCCESS [ 3.436 s]
[INFO] Hive Contrib ....................................... SUCCESS [ 4.770 s]
[INFO] Hive Druid Handler ................................. SUCCESS [ 17.245 s]
[INFO] Hive HBase Handler ................................. SUCCESS [ 6.759 s]
[INFO] Hive JDBC Handler .................................. SUCCESS [ 4.202 s]
[INFO] Hive HCatalog ...................................... SUCCESS [ 1.757 s]
[INFO] Hive HCatalog Core ................................. SUCCESS [ 5.455 s]
[INFO] Hive HCatalog Pig Adapter .......................... SUCCESS [ 4.662 s]
[INFO] Hive HCatalog Server Extensions .................... SUCCESS [ 4.629 s]
[INFO] Hive HCatalog Webhcat Java Client .................. SUCCESS [ 4.652 s]
[INFO] Hive HCatalog Webhcat .............................. SUCCESS [ 8.899 s]
[INFO] Hive HCatalog Streaming ............................ SUCCESS [ 4.934 s]
[INFO] Hive HPL/SQL ....................................... SUCCESS [ 7.684 s]
[INFO] Hive Streaming ..................................... SUCCESS [ 4.049 s]
[INFO] Hive Llap External Client .......................... SUCCESS [ 3.674 s]
[INFO] Hive Shims Aggregator .............................. SUCCESS [ 0.557 s]
[INFO] Hive Kryo Registrator .............................. SUCCESS [03:17 min]
[INFO] Hive TestUtils ..................................... SUCCESS [ 1.154 s]
[INFO] Hive Packaging ..................................... SUCCESS [01:58 min]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 38:22 min (Wall Clock)
[INFO] Finished at: 2023-08-08T22:50:15+08:00
[INFO] ------------------------------------------------------------------------
Résumer
Pendant tout le processus de compilation et de packaging, il y a 2 points qui sont très importants :
1.相关Jar无法下载或者下载缓慢问题,一定要想方设法解决,因为Jar是构建的核心,缺一不可
2.Jar依赖解决了,但是任然存在可能的兼容性问题,编译问题,遇到问题一定要一一解决,解决一步走一步