Compiler et construire Apache Spark3.2.4 à partir du code source
Instructions de compilation
Pour la plupart des utilisateurs, l'utilisation de la version précompilée officielle de Spark est suffisante pour les besoins quotidiens. Il est uniquement nécessaire de recompiler Spark dans des scénarios et des exigences spécifiques.
Les scénarios de compilation du code source Spark sont les suivants :
1. Exigences personnalisées :
Si vous avez besoin de personnaliser Spark en fonction de besoins commerciaux spécifiques, tels que l'ajout de règles d'optimisation personnalisées, l'amélioration de la prise en charge des sources de données ou l'optimisation pour un matériel spécifique, la recompilation de Spark répondra à vos besoins et permettra dans la version personnalisée de Spark d'appliquer ces personnalisations.
2. Nouvelles fonctionnalités et améliorations :
Si vous souhaitez utiliser la dernière version de Spark pour profiter des avantages des nouvelles fonctionnalités et améliorations, mais que la version officielle pré-compilée ne contient pas ces contenus, recompilez Spark pour utiliser la dernière version et obtenir ces nouvelles fonctionnalités.
3. Optimisation pour un environnement spécifique :
Différents matériels, systèmes d'exploitation et configurations peuvent nécessiter différents paramètres d'optimisation et adaptations. Si vous avez des exigences matérielles ou environnementales spécifiques et que vous souhaitez optimiser en profondeur Spark pour tirer pleinement parti de ses performances, vous pouvez recompiler Spark pour effectuer une configuration de compilation et des ajustements de paramètres pertinents.
4. Débogage et développement :
Si vous êtes un développeur Spark ou souhaitez participer à la contribution de la communauté Spark, recompilez Spark pour obtenir le code source, les outils de construction et l'environnement de développement pour le débogage, la modification et le travail de développement.
Compiler Apache Spark
télécharger le code source
Téléchargez le code source :https://spark.apache.org/news/index.html
Construire la référence de la documentation :https://spark.apache.org/docs/latest/building-spark.html
Préparation de l'environnement de construction
构建Apache Spark环境要求:
1. Pour construire Apache Spark basé sur Maven, Maven3.8.6 et Java 8 sont requis.
2.Spark nécessite la version Scala 2.12/2.13. Notez que la prise en charge de Scala2.11 a été supprimée dans Spark3.0.0.
3. Il est recommandé de définir l'utilisation de la mémoire de Maven
Ouvrez un terminal de ligne de commande ou une console et définissez la variable d'environnement MAVEN_OPTS :
Système d'exploitation Linux :
export MAVEN_OPTS="-Xss64m -Xmx2g -XX:ReservedCodeCacheSize=1g"
Système d'exploitation Windows :
set MAVEN_OPTS="-Xss64m -Xmx2g -XX:ReservedCodeCacheSize=1g"
Avis:
Cela définira la variable d'environnement MAVEN_OPTS dans la session en cours, si vous fermez le terminal ou la console, le paramètre sera perdu. Lors de l'exécution de la commande Maven, elle appliquera automatiquement ces paramètres.
Si vous souhaitez définir de manière permanente la variable d'environnement MAVEN_OPTS, vous pouvez ajouter la commande ci-dessus au fichier de configuration de votre système d'exploitation (tel que .bashrc ou .bash_profile).
Construire avec Maven local
Spark est livré avec une installation Maven autonome qui télécharge et configure automatiquement toutes les exigences de construction nécessaires (par exemple, Maven, Scala) lors de la construction du code source.
Ouvrez spark-3.2.4\dev\make-distribution.shle fichier et configurez manuellement pour construire à l'aide de Mavn local
#MVN="$SPARK_HOME/build/mvn"
MVN=/d/Development/Maven/bin/mvn
Changer la version de Scala
Il est possible de construire sur une version Spark en utilisant une version Scala spécifiée, par exemple en utilisant Scala2.13
Avis:
Cette étape est facultative et peut être sélectionnée en fonction de scénarios spécifiques. Par exemple, Spark est utilisé comme moteur d'exécution de Hive et Hive utilise Scala version 2.13. Pour des raisons de compatibilité, la version Scala2.13 doit également être utilisée ici.
./dev/change-scala-version.sh 2.12
Télécharger le package Jar
1. Utilisez l'outil de développement IDEA pour ouvrir le projet, et le JAR lié au projet sera téléchargé automatiquement.
2. Utilisez la commande mvn clean packageou mvn dependency:resolveMaven pour analyser les dépendances correspondant au fichier pom.xml du projet et téléchargez les fichiers JAR requis dans l'entrepôt local.
3. Utilisez mvn dependency:purge-local-repositoryla commande Maven, qui traversera les dépendances Jar dans l'entrepôt local associé dans le projet pom.xml et supprimera toutes les dépendances téléchargées.
Créer une distribution exécutable
Description des paramètres de compilation :
--name hadoop3.1.3-without-hive: 指定生成的Spark分发包的名称。
--tgz: 指定生成的分发包的格式为tar.gz压缩文件。
-Pyarn: Maven profile配置项,用于启用YARN支持。YARN是Apache Hadoop的资源管理器,用于在集群上分配和管理资源。
-Phadoop-provided: Maven profile配置项,用于指定使用外部提供的Hadoop依赖。这意味着Spark将使用系统中已安装的Hadoop而不是内置的Hadoop。
-Dhadoop.version=3.1.3: 指定所使用的Hadoop版本。
-Phive: Maven profile配置项,用于启用Hive支持。Hive是建立在Hadoop之上的数据仓库基础设施,它提供了类似于SQL的查询语言(HiveQL)来查询和分析存储在 Hadoop 分布式文件系统中的数据。
-Phive-thriftserver: Maven profile配置项,用于启用Hive Thrift服务器支持。Hive Thrift服务器允许通过Thrift 口访问Hive 的功能,从而可以通过远程客户端连接到Hive并执行查询操作。
-Dscala.version=2.12.17 是一个用于编译 Spark 时指定 Scala 版本的参数。
Commande de génération :
./dev/make-distribution.sh --name hadoop3.1.3-without-hive --tgz -Pyarn -Phadoop-provided -Dhadoop.version=3.1.3
exception de construction
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:4.3.0:compile (scala-compile-first) on project spark-tags_2.12: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:4.3.0:compile failed: An API incompatibility was encountered while executing net.alchim31.maven:scala-maven-plugin:4.3.0:compile: java.lang.NoSuchMethodError: org.fusesource.jansi.AnsiConsole.wrapOutputStream(Ljava/io/OutputStream;)Ljava/io/OutputStream;
[ERROR] -----------------------------------------------------
[ERROR] realm = plugin>net.alchim31.maven:scala-maven-plugin:4.3.0
[ERROR] strategy = org.codehaus.plexus.classworlds.strategy.SelfFirstStrategy
[ERROR] urls[0] = file:/D:/Development/Maven/Repository/net/alchim31/maven/scala-maven-plugin/4.3.0/scala-maven-plugin-4.3.0.jar
[ERROR] urls[1] = file:/D:/Development/Maven/Repository/org/apache/maven/maven-builder-support/3.3.9/maven-builder-support-3.3.9.jar
[ERROR] urls[2] = file:/D:/Development/Maven/Repository/com/google/guava/guava/18.0/guava-18.0.jar
[ERROR] urls[3] = file:/D:/Development/Maven/Repository/org/codehaus/plexus/plexus-interpolation/1.21/plexus-interpolation-1.21.jar
[ERROR] urls[4] = file:/D:/Development/Maven/Repository/javax/enterprise/cdi-api/1.0/cdi-api-1.0.jar
raison:
Maven依赖冲突或版本不兼容引起的
solution:
更换Spark项目中使用的scala-maven-plugin插件版本,将版本由3.4.0改成4.8.0
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<!-- SPARK-36547: Please don't upgrade the version below, otherwise there will be an error on building Hadoop 2.7 package -->
<version>4.8.0</version>
</groupId>
Remarque : La version modifiée du plug-in doit être correctement ajustée en fonction de la version Maven installée jusqu'à ce qu'il n'y ait plus une telle erreur.
construire avec succès
[INFO] Replacing D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4.jar with D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4-shaded.jar
[INFO] Dependency-reduced POM written at: D:\WorkSpace\BigData\spark-3.2.4\external\avro\dependency-reduced-pom.xml
[INFO]
[INFO] --- maven-source-plugin:3.1.0:jar-no-fork (create-source-jar) @ spark-avro_2.12 ---
[INFO] Building jar: D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4-sources.jar
[INFO]
[INFO] --- maven-source-plugin:3.1.0:test-jar-no-fork (create-source-jar) @ spark-avro_2.12 ---
[INFO] Building jar: D:\WorkSpace\BigData\spark-3.2.4\external\avro\target\spark-avro_2.12-3.2.4-test-sources.jar
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Spark Project Parent POM 3.2.4:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 4.208 s]
[INFO] Spark Project Tags ................................. SUCCESS [ 27.903 s]
[INFO] Spark Project Sketch ............................... SUCCESS [ 14.615 s]
[INFO] Spark Project Local DB ............................. SUCCESS [ 11.059 s]
[INFO] Spark Project Networking ........................... SUCCESS [ 14.750 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 13.361 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 18.919 s]
[INFO] Spark Project Launcher ............................. SUCCESS [ 18.429 s]
[INFO] Spark Project Core ................................. SUCCESS [05:13 min]
[INFO] Spark Project ML Local Library ..................... SUCCESS [ 35.943 s]
[INFO] Spark Project GraphX ............................... SUCCESS [ 41.485 s]
[INFO] Spark Project Streaming ............................ SUCCESS [01:16 min]
[INFO] Spark Project Catalyst ............................. SUCCESS [03:13 min]
[INFO] Spark Project SQL .................................. SUCCESS [05:24 min]
[INFO] Spark Project ML Library ........................... SUCCESS [02:43 min]
[INFO] Spark Project Tools ................................ SUCCESS [ 9.124 s]
[INFO] Spark Project Hive ................................. SUCCESS [01:56 min]
[INFO] Spark Project REPL ................................. SUCCESS [ 27.047 s]
[INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 26.742 s]
[INFO] Spark Project YARN ................................. SUCCESS [03:02 min]
[INFO] Spark Project Assembly ............................. SUCCESS [ 2.647 s]
[INFO] Kafka 0.10+ Token Provider for Streaming ........... SUCCESS [ 26.049 s]
[INFO] Spark Integration for Kafka 0.10 ................... SUCCESS [ 45.183 s]
[INFO] Kafka 0.10+ Source for Structured Streaming ........ SUCCESS [ 54.219 s]
[INFO] Spark Project Examples ............................. SUCCESS [ 43.172 s]
[INFO] Spark Integration for Kafka 0.10 Assembly .......... SUCCESS [ 9.504 s]
[INFO] Spark Avro ......................................... SUCCESS [ 45.400 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 31:01 min
[INFO] Finished at: 2023-08-09T10:10:41+08:00
[INFO] ------------------------------------------------------------------------
+ rm -rf /d/WorkSpace/BigData/spark-3.2.4/dist
+ mkdir -p /d/WorkSpace/BigData/spark-3.2.4/dist/jars
+ echo 'Spark 3.2.4 built for Hadoop 3.1.3'
+ echo 'Build flags: -Pyarn' -Phadoop-provided -Dhadoop.version=3.1.3

exécuter un test
démarrer l'étincelle
spark-shell --master local
Exception 1 :
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/log4j/spi/Filter
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:650)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:632)
Caused by: java.lang.ClassNotFoundException: org.apache.log4j.spi.Filter
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
Modifier le fichier spark-env.sh
# jdk路径
export JAVA_HOME=/usr/local/program/jdk8
# 关联Hadoop
export HADOOP_HOME=/usr/local/program/hadoop
export HADOOP_CONF_DIR=/usr/local/program/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/program/hadoop/bin/hadoop classpath)
Exception 2 :
org.apache.spark.SparkException: Could not find spark-version-info.properties
at org.apache.spark.package$SparkBuildInfo$.<init>(package.scala:62)
at org.apache.spark.package$SparkBuildInfo$.<clinit>(package.scala)
at org.apache.spark.package$.<init>(package.scala:93)
at org.apache.spark.package$.<clinit>(package.scala)
at org.apache.spark.SparkContext.$anonfun$new$1(SparkContext.scala:193)
at org.apache.spark.internal.Logging.logInfo(Logging.scala:57)
at org.apache.spark.internal.Logging.logInfo$(Logging.scala:56)
at org.apache.spark.SparkContext.logInfo(SparkContext.scala:82)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:193)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2700)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:949)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:943)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:112)
Exécutez build/spark-build-infola commande, elle générera un spark-version-info.propertiesfichier
build/spark-build-info ./目录路径
Le contenu du fichier est le suivant :
version=
user=
revision=
branch=
date=2023-08-10T01:42:10Z
url=
spark-version-info.propertiesCopiez les fichiers générés dans spark-core_2.11-2.4.0-SNAPSHOT.jar. Placez le package JAR modifié dans spark/jarsle répertoire et remplacez le JAR d'origine
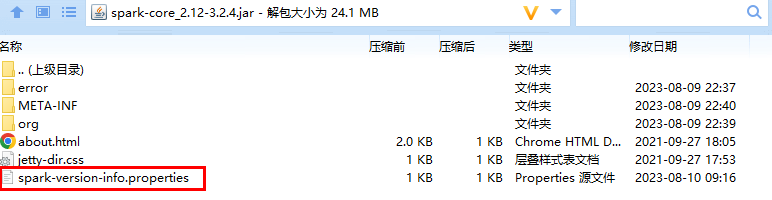
Redémarrez le Spark Shell lors de l'exécution des requêtes de base de données
Spark context Web UI available at http://node01:4040
Spark context available as 'sc' (master = local, app id = local-1691675436513).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.4
/_/
Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_371)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.sql("show databases").show
+---------+
|namespace|
+---------+
| default|
+---------+