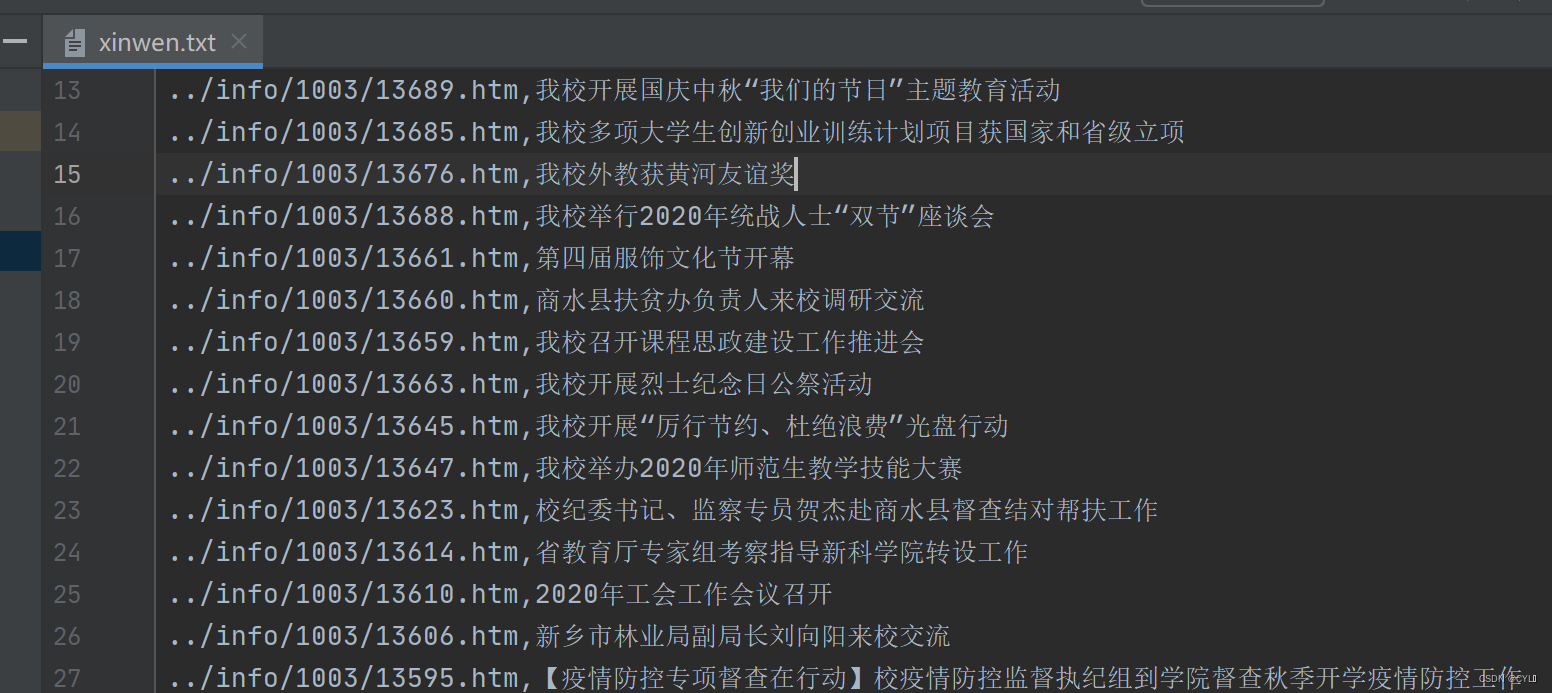
1. Télécharger
pip install bs4
2. Présentation
Beautiful Soup4, appelé bs4 en abrégé, est un analyseur HTML/XML dont la fonction principale est d'analyser et d'extraire des données HTML/XML. Il prend en charge non seulement les sélecteurs css, mais également les analyseurs HTML de la bibliothèque standard de python et le XML de lxml.
Documentation officielle : https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
3. Utilisation de base
1. Construire un objet BeautifulSoup
Méthode 1 :
import urllib.request
from bs4 import BeautifulSoup
//读取html对象
url="https://news.hist.edu.cn/kyyw/378.htm"
request=urllib.request.Request(url);
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8");
//构建BeautifulSoup对象
bs=BeautifulSoup(html,"html.parser",from_encoding='utf-8')
Méthode 2 :
from bs4 import BeautifulSoup
file = open('https://news.hist.edu.cn/kyyw/378.htm', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser") # 缩进格式
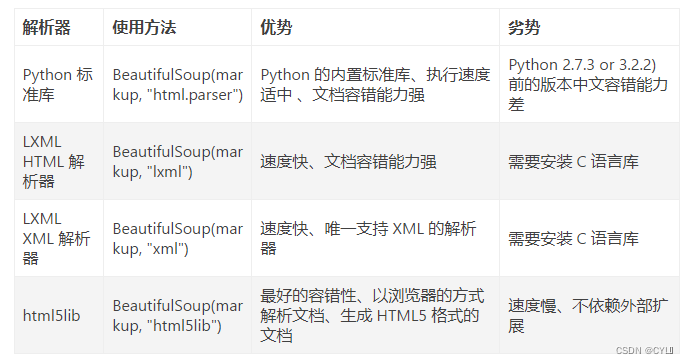
Remarque : html, analyseur signifie que l'analyseur utilisé est la bibliothèque standard Python, et les autres bibliothèques standard sont les suivantes
2. Interpréter et rechercher dans la méthode d'opération
print(bs.prettify()) # 格式化html结构
print(bs.title) # 获取title标签的名称
print(bs.title.name) # 获取title的name
print(bs.title.string) # 获取head标签的所有内容
print(bs.head)
print(bs.div) # 获取第一个div标签中的所有内容
print(bs.div["id"]) # 获取第一个div标签的id的值
print(bs.a)
find() : utilisé pour rechercher le premier nœud d'étiquette qui répond aux conditions de la requête.
méthode find_all() : recherche tous les nœuds d'étiquette qui répondent aux conditions de la requête et renvoie une liste.
print(bs.find_all("a")) # 获取所有的a标签
for item in bs.find_all("a"):
print(item.get("href")) # 获取所有的a标签,并遍历打印a标签中的href的值
for item in bs.find_all("a"):
print(item.get_text())//获取a标签文本内容
#attrs参数
print(bs.find_all(id="u1")) # 获取id="u1"的所有标签
bs.find_all(“a”,class_="app")获取所有的a标签,并且其类名为app
3. Recherche par sélecteur css
bs.select("p")#通过标签查找
bs.select(".app")#通过类名查找
bs.select("#link")#通过id名查找
bs.select('p #link')#通过组合查找
bs.select("a[href='http://baidu.com']")#通过属性查找
4. Cas
import urllib.request
from bs4 import BeautifulSoup
url="https://news.hist.edu.cn/kyyw/378.htm"
request=urllib.request.Request(url);
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8");
bs=BeautifulSoup(html,"html.parser",from_encoding='utf-8')
print(bs.prettify())#格式化html结构
# print(bs.find_all("a"))
divs=bs.find_all('div',{
'class':'sec-a'})
lis=divs[0].find_all('li')
#爬取新闻链接和新闻标题并写入xinwen.txt文档里面
with open("xinwen.txt","w") as fp:
for li in lis:
fp.write(li.find_all("a")[0].get('href')+","+li.find_all("a")[0].get('title')+"\n")