import requests
from bs4 import BeautifulSoup
url = 'http://python123.io/ws/demo.html'
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
Les éléments de base de la classe 1.Beautiful soupe
| Les éléments de base | explication |
|---|---|
| Étiquette | Tag, les moyens de blocage des informations de base, respectivement <> et </> indiquent le début et la fin |
| Nom | Name tag <p> ... </ p> nom est 'p', le format suivant: <tag> .name |
| Les attributs | attributs de la balise, organisée dans le dictionnaire, le format suivant: <tag> .attrs |
| NavigableString | chaîne non attribut dans la balise, <> ... </> chaîne dans le format suivant: <tag> .string |
| Commentaire | Notez la partie de l'étiquette de la chaîne, un commentaire de type spécial |
# Tag
# 获取网页的标题
print(soup.title)
# <title>This is a python demo page</title>
# 获取html的a标签的内容
# 默认获取第一个标签
print(soup.a)
# Name
# 获取标签的名字
print('标签名字:', soup.a.name)
# Attributes
# 获取属性信息
tag = soup.a
print(tag.attrs)
# NavigableString
# 获取a标签的字符串信息
print(soup.a.string)
# Comment
new_soup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>", "html.parser")
print(new_soup.b.string)
# This is a comment
print(type(new_soup.b.string))
# <class 'bs4.element.Comment'>
print(new_soup.p.string)
# This is not a comment
print(type(new_soup.p.string))
# <class 'bs4.element.NavigableString'>
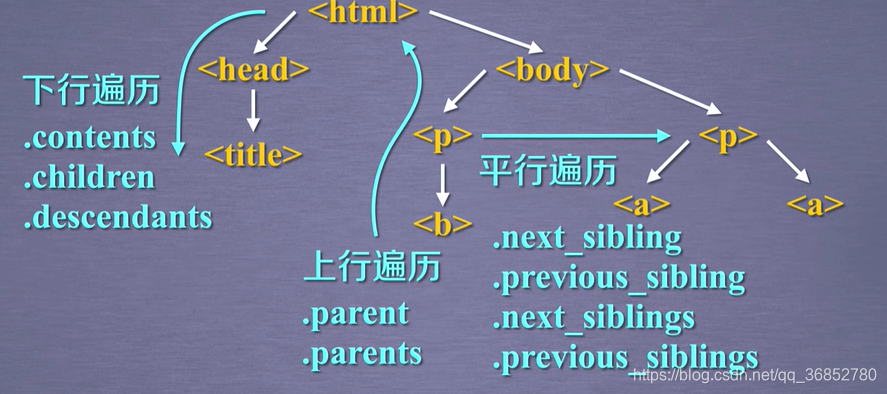
2. Le nombre d'étiquettes descendant traversal
| propriété | explication |
|---|---|
| .Contenu | Liste des nœuds enfants de la liste <tag> de tous les noeuds fils dans |
| .children | Iterator type de nœuds enfants, et .contents similaires boucle itère noeud fils |
| .descendance | Iterative type de noeud descendant, comprenant tous les noeuds descendants, une boucle à travers |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
# 获取body标签下的所有节点并存入列表中
print(soup.body.contents)
print(type(soup.body.contents))
# <class 'list'>
# 遍历儿子节点
for child in soup.body.children:
print(child)
# 遍历子孙节点
for desc in soup.body.descendants:
print(desc)
L'arbre traversant 3. Étiquette
| propriété | explication |
|---|---|
| .parent | étiquette du noeud père |
| .Parents | ancêtre itératives balises de type de noeud de boucle à travers le noeud ancêtre |
# 标签数的上行遍历
# 遍历a标签的所有父节点
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
# title的父标签
print(soup.title.parent)
4. traversal arbre tag parallèle
| propriété | explication |
|---|---|
| .next_sibling | Renvoie le nœud suivant en parallèle selon la procédure de l'étiquette de texte HTML |
| .previous_sibling | Renvoie la balise texte HTML d'un noeud parallèle selon l'ordre |
| .next_siblings | Type itératives, texte HTML retourné pour que toutes les étiquettes de noeud parallèle ultérieur |
| .previous_siblings | Type itératives, retour suite tout le texte de balises HTML noeuds parallèles, conformément à l'ordre |
# 遍历后续节点
for sibling in soup.a.next_siblings:
print(sibling)
# 遍历前续节点
for sibling in soup.a.previous_siblings:
print(sibling)
Résumé:
Procédé de bibliothèque Prettify de 5.bs4 ()
Le texte du format HTML le contenu ou une partie de l'étiquette (chaque étiquette ajoutera retour wrap)
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
print(soup.prettify())
print(soup.a.prettify())
6. Trouver la méthode
find_all(name, attrs, recursive, string, **kwargs):
Retourne un type de liste, le résultat de stockage de la recherche.
- nom: chaîne pour récupérer le nom de la balise
- attrs: valeurs d'attribut recherche de balise de chaîne de caractères, la recherche d'attributs peuvent être marqués
- récursive: Que ce soit pour récupérer tous les descendants, par défaut Vrai
- Récupération caractère chaîne <> ... </> Région de chaîne: string
import requests
import re
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
soup = BeautifulSoup(r.text, "html.parser")
# 查找所有a标签
print(soup.find_all('a'))
print(type(soup.find_all('a')))
# <class 'bs4.element.ResultSet'>
for tag in soup.find_all('a'):
print(tag.string)
# 显示a 和 b 标签
print(soup.find_all(['a', 'b']))
# 显示soup的所有标签信息
for tag in soup.find_all(True):
print(tag.name)
# 使用正则表达式来查找含有b的标签
for tag in soup.find_all(re.compile('b')):
print(tag.name)
# 查找p标签含有course的内容
print(soup.find_all('p', 'course'))
# 查找id属性为link1的内容
print(soup.find_all(id='link1'))
# 查找id属性为link的内容 没有则返回[]
print(soup.find_all(id='link'))
# 使用re模块来查找id属性包含link的内容
print(soup.find_all(id=re.compile('link')))
# 设置recursive参数为False, 这时从soup的子节点进行检索, 而不会去检索子孙节点的内容
print(soup.find_all('a', recursive=False))
# 检索字符串是否存在
print(soup.find_all(string="Basic Python"))
# 检索字符串是否含有python, 通过re
print(soup.find_all(string=re.compile('Python')))
Le Conseil:
<Tag> (...) est équivalent à <Tag> .find_all (...)
soupe (...) équivaut à soup.find_all (...)
Méthodes d'extension
| méthode | explication |
|---|---|
| <>. Find () | Rechercher et retourne seulement un résultat de type chaîne, avec des paramètres .find_all () |
| <>. Find_parents () | Recherche ancêtre noeud, retourne une liste de types, avec des paramètres .find_all () |
| <>. Find_parent () | Ancêtre noeud renvoie un résultat de type chaîne, avec des paramètres .Find () |
| <>. Find_next_siblings () | Dans la recherche ultérieure d'un noeud parallèle, retourne une liste de types, les mêmes paramètres .find_all () |
| <>. Find_next_sibling () | Dans le retour subséquent à un noeud parallèle un résultat, le type de chaîne, avec des paramètres .Find () |
| <>. Find_previous_siblings () | les noeuds de recherche de séquence en parallèle à l'avant, renvoie une liste de types, les mêmes paramètres (.find_all) |
| <>. Find_previous_sibling () | parallèle d'ordre dans le noeud avant renvoie un résultat de type chaîne, avec des paramètres .Find () |
cas reptile
