Les grands modèles de langage font progresser l’état de l’art en matière de traitement du langage naturel. Cependant, ils sont principalement conçus pour l’anglais ou un ensemble limité de langues, ce qui crée un écart important dans leur efficacité pour les langues à faibles ressources. Afin de combler cette lacune, des chercheurs de l'Université de Munich, de l'Université d'Helsinki et d'autres chercheurs ont conjointement ouvert MaLA-500, qui vise à couvrir un large éventail de 534 langues.
MaLA-500 est construit sur la base de LLaMA 2 7B, puis utilise l'ensemble de données multilingues Glot500-c pour la formation à l'expansion linguistique. Les résultats expérimentaux des chercheurs sur le SIB-200 montrent que MaLA-500 a obtenu des résultats d'apprentissage contextuel de pointe.
Glot500-c contient 534 langues, couvrant 47 langues ethniques différentes, avec un volume de données pouvant atteindre 2 000 milliards de jetons. Les chercheurs ont déclaré que la raison du choix de l'ensemble de données Glot500-c est qu'il peut considérablement étendre la couverture linguistique des modèles linguistiques existants et qu'il contient une famille de langues extrêmement riche, ce qui est d'une grande aide pour le modèle dans l'apprentissage de la grammaire et de la sémantique inhérentes. règles de la langue.
De plus, bien que la proportion de certains langages à ressources élevées soit relativement faible, le volume global de données de Glot500-c est suffisant pour former des modèles linguistiques à grande échelle. Lors du prétraitement ultérieur, un échantillonnage aléatoire pondéré a été effectué sur l'ensemble de données du corpus pour augmenter la proportion de langues à faibles ressources dans les données de formation et permettre au modèle de se concentrer davantage sur des langues spécifiques.
Basé sur LLaMA 2-7B, MaLA-500 a apporté deux innovations technologiques majeures :
- Pour améliorer le vocabulaire, les chercheurs ont formé un segmenteur de mots multilingues via l'ensemble de données Glot500-c, élargissant le vocabulaire anglais original de LLaMA 2 à 2,6 millions, améliorant considérablement la capacité du modèle à s'adapter aux langues non anglaises et à faibles ressources.

- L'amélioration du modèle utilise la technologie LoRA pour effectuer une adaptation de bas rang basée sur LLaMA 2. Seule la formation de la matrice d'adaptation et le gel des poids de base du modèle peuvent effectivement réaliser la capacité d'apprentissage continu du modèle dans de nouvelles langues tout en conservant les connaissances d'origine du modèle.
Processus de formation
En termes de formation, les chercheurs ont utilisé 24 GPU A100 N-card pour la formation et ont utilisé trois cadres d'apprentissage profond traditionnels, notamment Transformers, PEFT et DeepSpeed.
Parmi eux, DeepSpeed fournit un support pour la formation distribuée et peut réaliser le parallélisme des modèles ; PEFT implémente un réglage efficace du modèle ; Transformers fournit la mise en œuvre de fonctions de modèle, telles que la génération de texte, la compréhension rapide des mots, etc.
Afin d'améliorer l'efficacité de l'entraînement, MaLA-500 utilise également divers algorithmes d'optimisation de la mémoire et du calcul, tels que l'optimiseur redondant ZeRO, qui peut maximiser l'utilisation des ressources informatiques du GPU ; et le format numérique bfloat16 pour un entraînement de précision mixte afin d'accélérer l'entraînement. processus de formation.
En outre, les chercheurs ont également effectué un grand nombre d'optimisations sur les paramètres du modèle, en utilisant une formation SGD conventionnelle avec un taux d'apprentissage de 2e-4 et en utilisant une atténuation de poids L2 de 0,01 pour éviter que le modèle ne soit trop grand, surajusté, instable. sortie de contenu, etc. Condition.
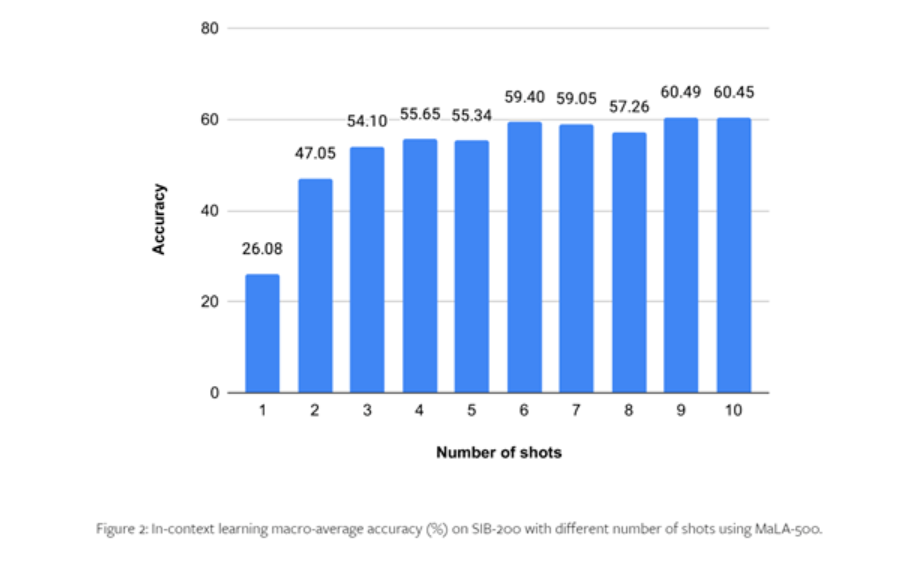
Afin de tester les performances du MaLA-500, les chercheurs ont mené des expériences complètes sur des ensembles de données tels que le SIB-200.
Les résultats montrent que par rapport au modèle LLaMA 2 original, la précision du MaLA-500 sur les tâches d'évaluation telles que la classification des sujets est augmentée de 12,16 %, ce qui montre que le multilingue du MaLA-500 est supérieur à de nombreux grands modèles de langage open source existants. .
Plus de détails peuvent être trouvés dans le document complet .