
iQiyi a construit un entrepôt de données hors ligne traditionnel basé sur Hive pour prendre en charge les décisions opérationnelles de l'entreprise, la croissance des utilisateurs, les recommandations vidéo, l'adhésion, la publicité et d'autres besoins commerciaux. Ces dernières années, les entreprises ont des exigences plus élevées en matière de données en temps réel. Nous avons introduit la technologie de lac de données basée sur Iceberg pour améliorer considérablement les performances des requêtes de données et l'efficacité globale de la circulation. Du point de vue des performances et des coûts, la migration des tables Hive existantes vers le lac de données est nécessaire. Cependant, au fil des années, des centaines de pétaoctets de données Hive ont été accumulés sur la plateforme Big Data. Comment migrer Hive vers le lac de données est devenu un défi majeur auquel nous sommes confrontés. Cet article présente la solution technique d'iQiyi pour une migration fluide du lac de données Hive vers Iceberg, aidant ainsi les entreprises à accélérer les processus de données et à améliorer leur efficacité et leurs revenus.
01
Ruche contre Iceberg
Hive est une plate-forme d'entrepôt et d'analyse de données basée sur Hadoop qui fournit un langage de type SQL pour prendre en charge le traitement et l'analyse de données complexes.
Iceberg est un format de table de données open source conçu pour fournir un stockage de table évolutif, stable et efficace pour prendre en charge les charges de travail analytiques. Iceberg offre des garanties transactionnelles et une cohérence des données similaires aux bases de données traditionnelles, et prend en charge les opérations de données complexes telles que les mises à jour, les suppressions, etc.
Le tableau 1-1 présente la comparaison entre Hive et Iceberg en termes de rapidité, de performances des requêtes, etc. :
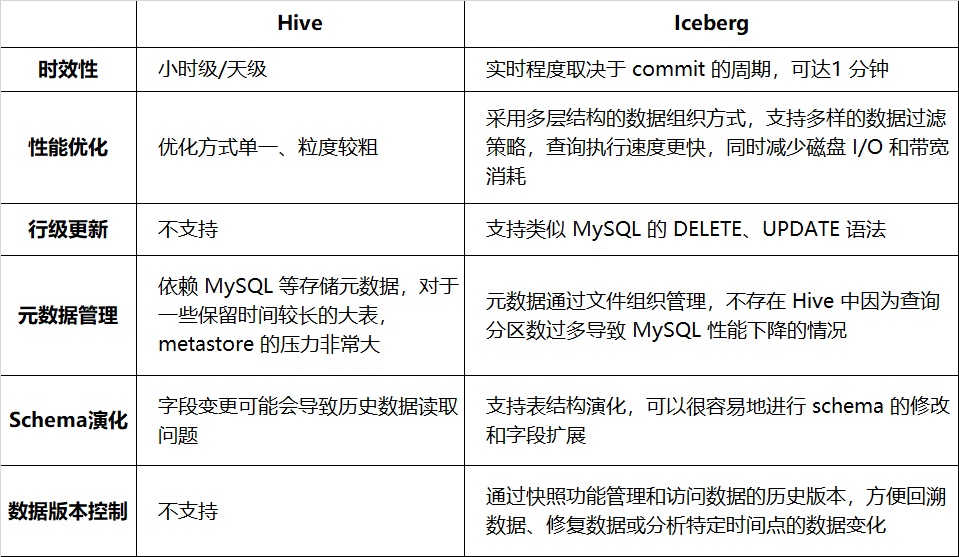
Tableau 1-1 Comparaison entre Hive et Iceberg
Le passage à Iceberg peut améliorer l'efficacité et la fiabilité du traitement des données et fournir une meilleure prise en charge des opérations de données complexes. Actuellement, il est connecté à plus d'une douzaine d'activités telles que la publicité, les adhésions, les journaux Venus et l'audit. Pour plus de détails sur la pratique Iceberg d’iQiyi, vous pouvez lire la série d’articles précédente (voir citation en fin d’article).
02
Changement fluide des données de stock de la ruche Iceberg
Iceberg présente de nombreux avantages par rapport à Hive, mais les données commerciales s'exécutent déjà dans l'environnement Hive et l'entreprise ne souhaite pas investir beaucoup de main-d'œuvre dans la modification des tâches d'inventaire. Nous avons étudié les méthodes de commutation courantes dans l'industrie [1] et avons fourni la possibilité de basculer en douceur entre Hive en libre-service et Iceberg sur la plate-forme de lac de données. Cette section décrira le plan de mise en œuvre spécifique.
1. Vérifiez la compatibilité
Avant le changement proprement dit, nous avons vérifié la compatibilité de Spark avec Hive et Iceberg.
La syntaxe de requête et d'écriture de Spark pour les tables Hive et Iceberg est fondamentalement la même. Les instructions SQL permettant d'interroger les tables Hive peuvent interroger les tables Iceberg sans modification.
Cependant, il existe de grandes différences entre Iceberg et Hive en termes de DDL, principalement dans la manière de modifier la structure des tables. Les détails sont tels que décrits dans le tableau 2-1. Il doit y avoir une correspondance biunivoque entre le schéma réel et le schéma du fichier de données, sinon cela affectera l'interrogation des données. Par conséquent, vous devez être plus prudent lors du traitement des instructions DDL. Il n'est pas recommandé de lier. de telles instructions DDL avec des tâches.
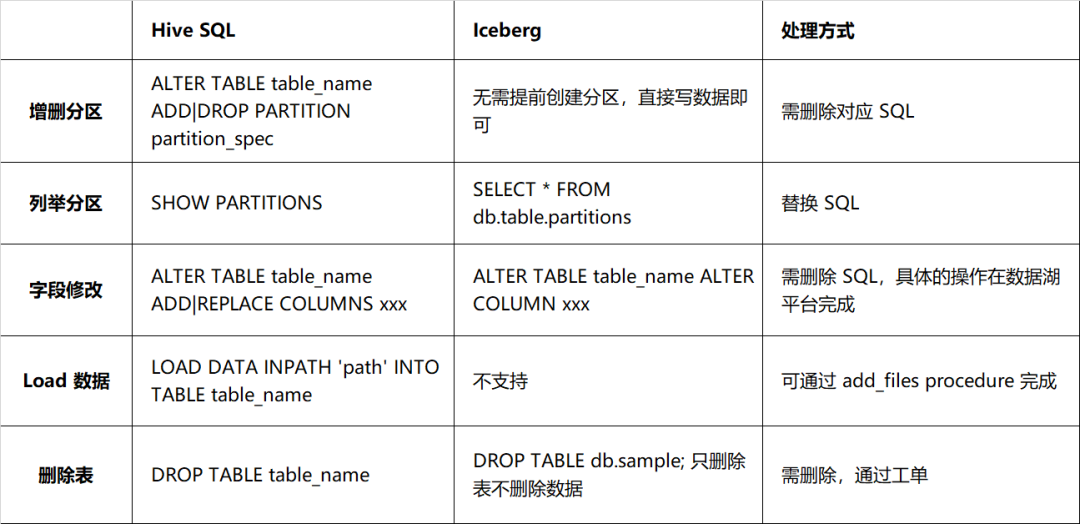
Tableau 2-1 Comparaison de compatibilité syntaxique entre Hive et Iceberg
2. Solution de changement d'industrie
2.1 Commutation professionnelle à double écriture
L'entreprise reproduit le pipeline existant pour mettre en œuvre la double écriture de Hive et Iceberg. Une fois que les anciennes et les nouvelles paires de canaux sont cohérentes, passez au canal Iceberg et déconnectez-vous du canal d'origine. Cette solution nécessite que l'entreprise investisse de la main d'œuvre dans le développement et le calcul, ce qui prend du temps et demande beaucoup de main d'œuvre.
2.2 Basculement en place, le client arrête d'écrire
Si l'entreprise est autorisée à arrêter d'écrire pendant un certain temps et à changer, les méthodes suivantes peuvent être utilisées :
-
La procédure de migration Spark est une fonction officiellement fournie par Iceberg, qui permet de basculer une table Hive vers Iceberg en place. L'exemple est le suivant :
APPEL nom_catalogue.system.migrate('db.sample'); |
Ce programme ne modifie pas les données originales, il analyse uniquement les données de la table originale puis construit les métainformations Iceberg, faisant référence au fichier original. Par conséquent, le programme de migration s'exécute très rapidement, mais les données existantes ne peuvent pas utiliser des fonctionnalités telles que les index de fichiers pour accélérer les requêtes. Si vous souhaitez également accélérer les données existantes, vous pouvez utiliser la méthode rewrite_data_files de Spark pour réécrire les données historiques.
Le programme de migration ne supprime pas la table Hive, mais la renomme en sample__BACKUP__. Le suffixe __BACKUP__ ici est codé en dur. Si vous devez revenir en arrière, vous pouvez supprimer la table Iceberg nouvellement créée et renommer la table Hive.
-
En utilisant l' instruction CTAS , l'exemple Spark est le suivant :
CREATE TABLE db.sample_iceberg UTILISER Iceberg PARTITIONNÉ PAR dt EMPLACEMENT 'qbfs://....' TBLPROPERTIES('write.target-file-size-bytes' = '512m', ...) AS SELECT * FROM db.sample; |
Une fois l'écriture terminée, le logarithme est effectué. Une fois les conditions remplies, le changement est terminé par un changement de nom.
ALTER TABLE db.sample RENAME TO db.sample_backup ; ALTER TABLE db.sample_iceberg RENAME TO db.sample; |
L'avantage du CTAS par rapport à la migration est que les données existantes sont réécrites, ce qui permet d'optimiser le partitionnement, le tri des colonnes, les formats de fichiers, les petits fichiers, etc. L’inconvénient est que s’il existe de nombreuses données existantes, la réécriture prend du temps et nécessite beaucoup de ressources.
Les deux solutions ci-dessus présentent les caractéristiques suivantes :
avantage:
La solution est simple, exécutez simplement le SQL existant
Peut être restauré, la table Hive d'origine est toujours là
défaut:
Écriture/lecteur non validé : des exceptions d'écriture ou de requête peuvent survenir après le passage à la table Iceberg
Exiger que le processus de changement arrête d'écrire est inacceptable pour certaines entreprises
3. Plan de migration en douceur d'iQiyi
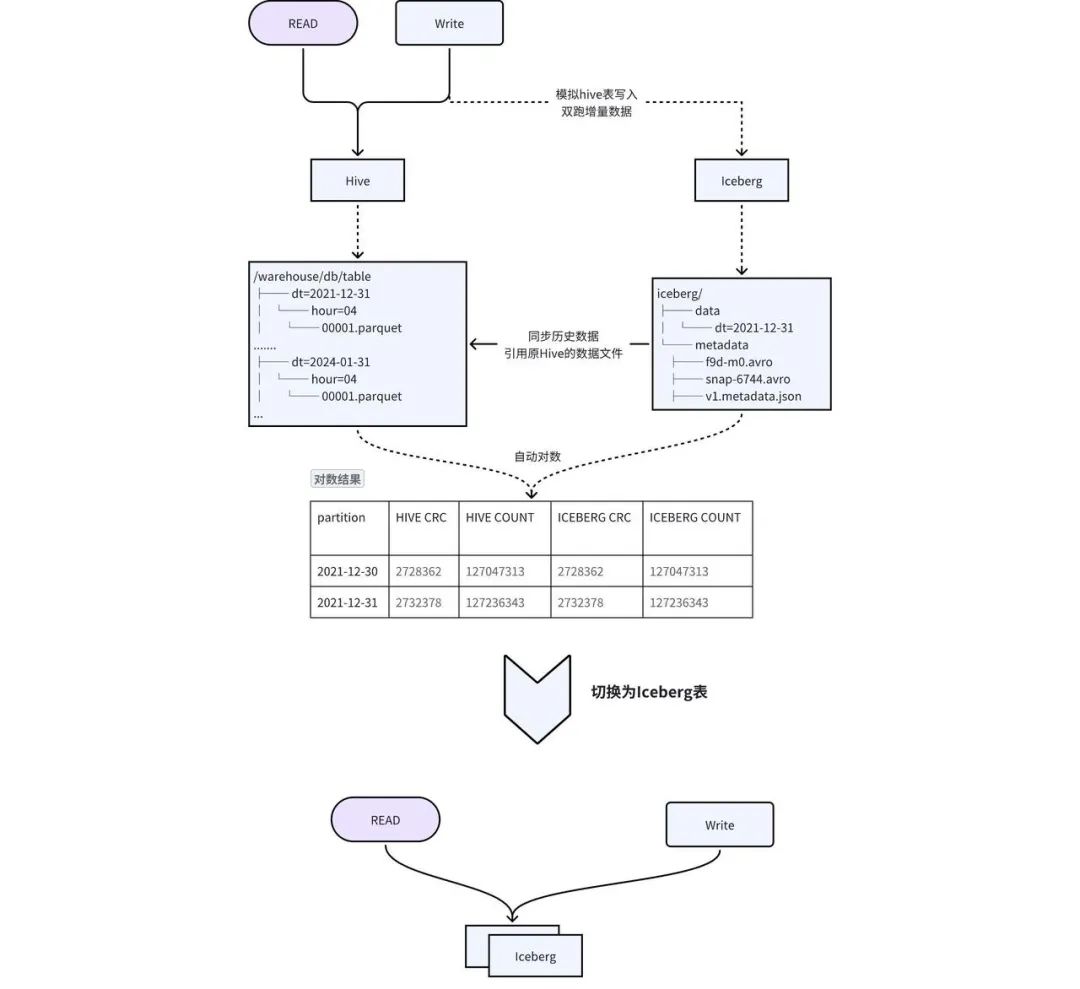
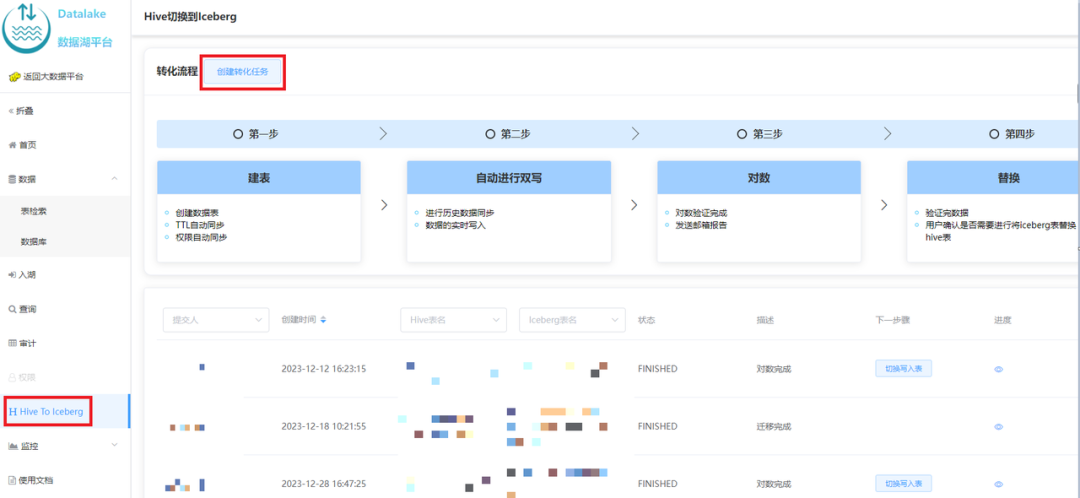
Compte tenu des inconvénients de la solution ci-dessus, nous avons conçu une solution de double écriture sur place + commutation transparente pour obtenir une migration fluide, comme le montre la figure 2-1 :
-
Création de table : créez une table Iceberg avec le même schéma que Hive, et synchronisez les méta-informations telles que le TTL et les autorisations de la table Hive avec la table Iceberg. -
Migration des données historiques vers Iceberg : les données historiques de Hive sont ajoutées à Iceberg via la procédure add_file . Cette opération construira les métadonnées d'Iceberg basées sur les données de Hive. En fait, les métadonnées d'Iceberg pointent vers les fichiers de données de Hive, réduisant ainsi la redondance des données et le temps de synchronisation des données historiques. -
Double écriture de données incrémentielles : la passerelle Pilot SQL auto-développée par iQIYI détecte les tâches d'écriture dans la table Hive, copie et écrit automatiquement du SQL et remplace la sortie par la table Iceberg pour obtenir une double écriture. -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
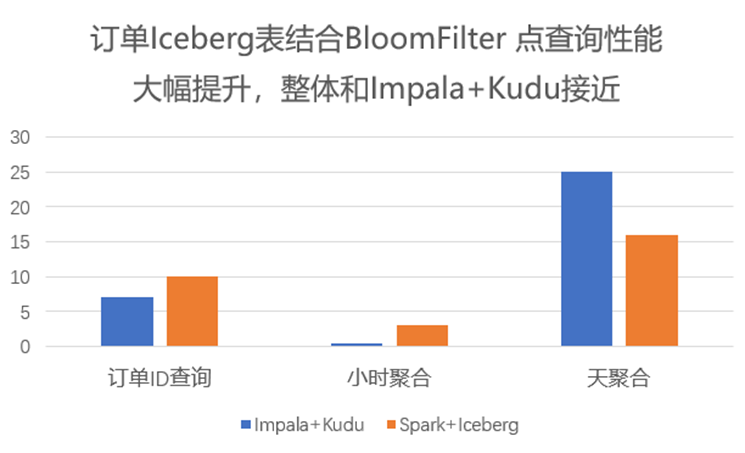
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
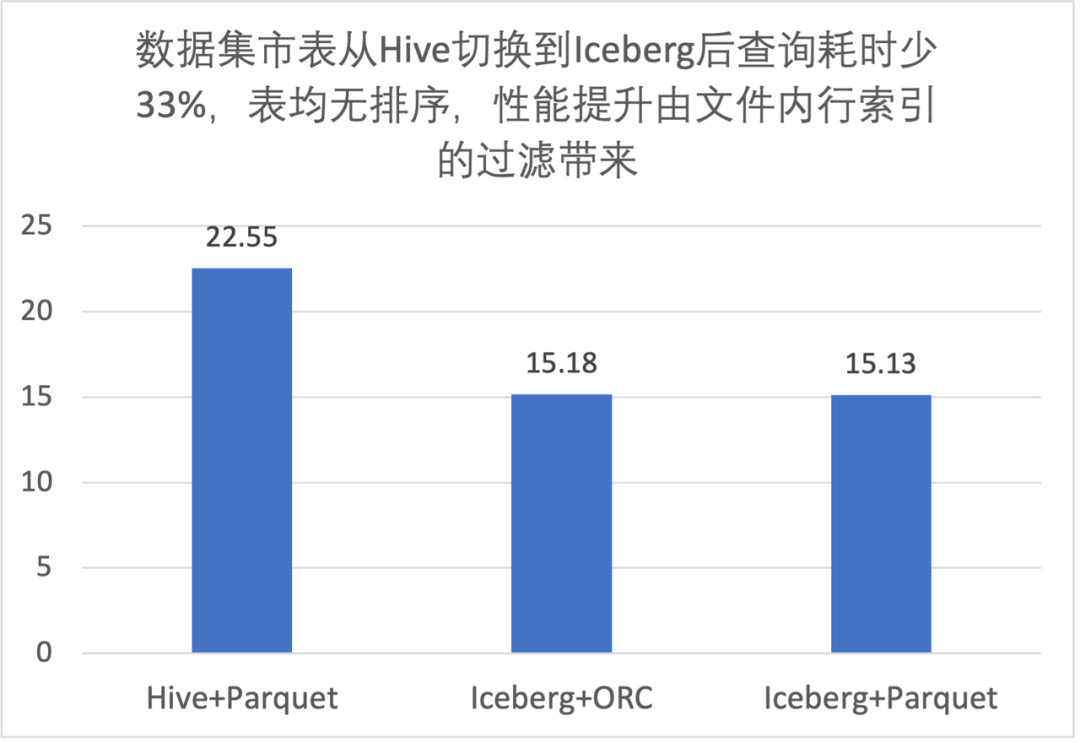
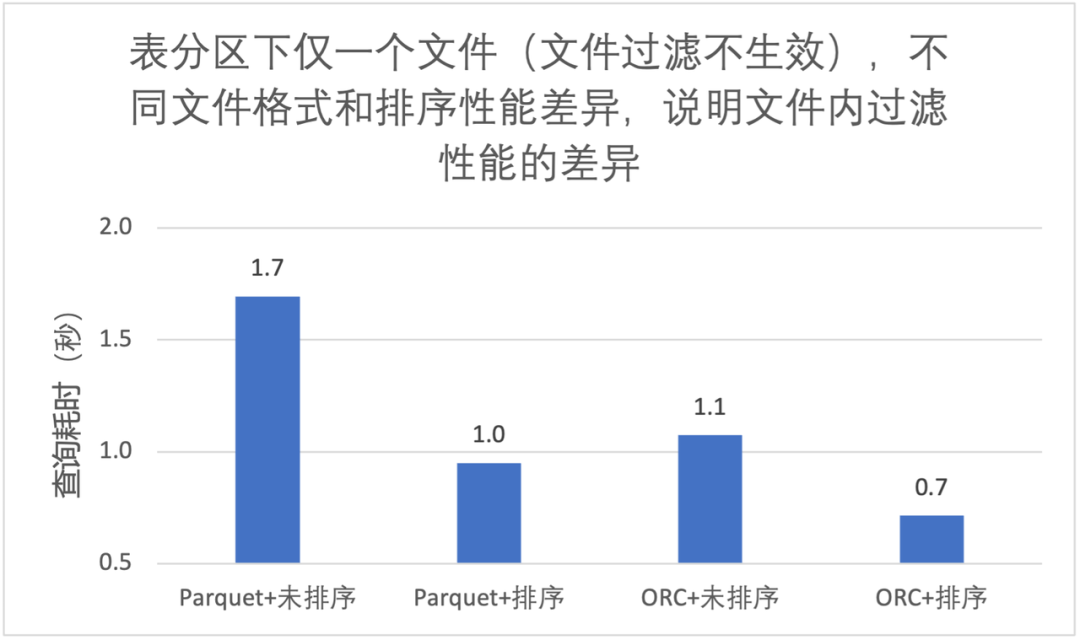
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
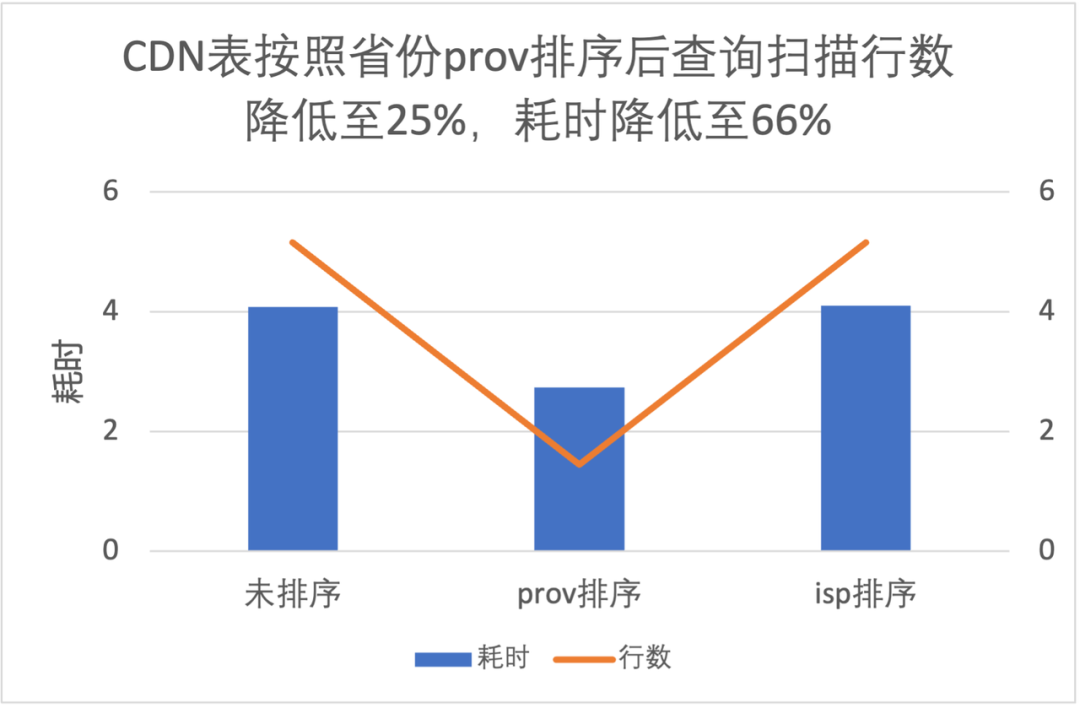
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
3.4 布隆过滤器的性能提升
3.5 Spark 和 Trino 性能比较
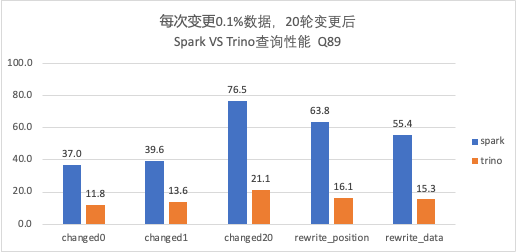
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
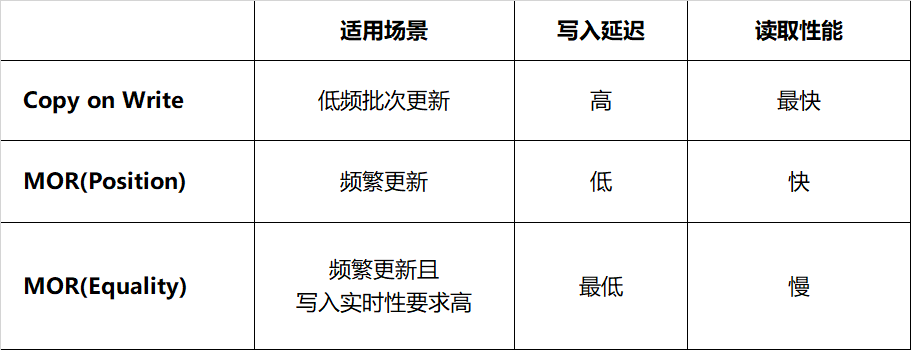 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
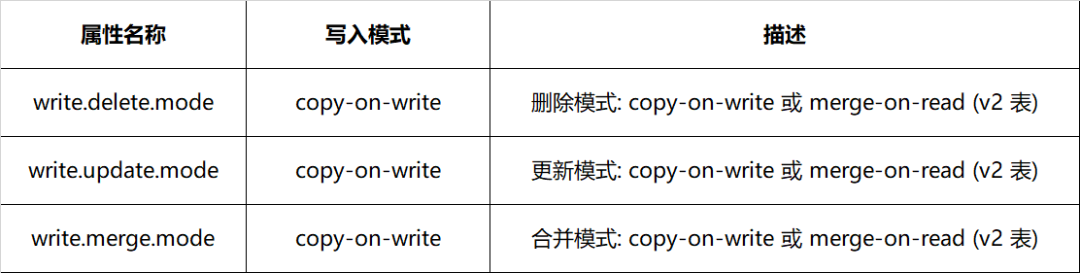 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
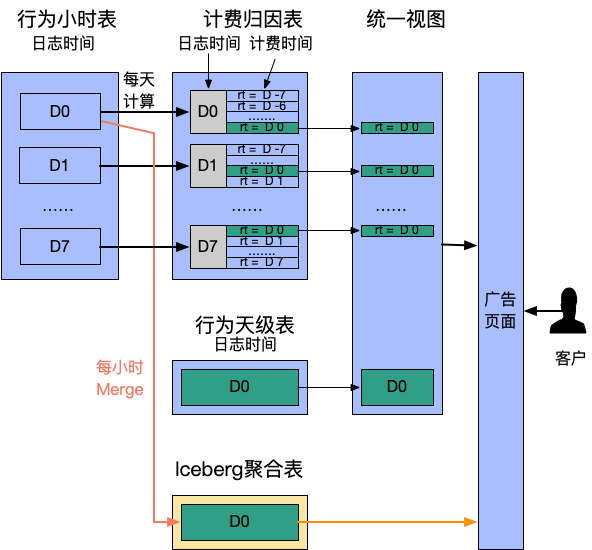
5.1 广告计费转换
-
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。